






选择题
T1-5
时间复杂度:算的是在循环体中大概的次数
树的后序遍历,左子树→右子树;转化为二叉树中,左右子树分别是左孩右兄,所以在二叉树中是根→右子树; 同理,树的右子树→根,在二叉树中是左子树→根;总结如下,树的后序是二叉树的中序遍历。
哈夫曼树当中,只有度为0和2的结点,度为0的n0节点数比n2多的,所以设叶子结点n0=n,则n+n-1=115,n=58。
平衡二叉树,删除某结点后,可能造成失衡,就要调整,再插入相同结点,则树不一定相同。
AOE关键路径:最早开始时间是到达这个工程结点的开销最长的时间,因为最早开始时间要使得所有工程都有效运行下去; 而最迟开始时间是关键路径倒推回来的最大时间。
T6-10
选择排序算法时,除了算法时空效率外,还需要考虑,数据的规模(规模过大的外部排序或归并排序或其它),数据的存储方式(顺序存储或链式存储,如堆排序只能用顺序存储),算法稳定性,数据的初始状态(是否基本有序)。
KMP单字符比较次数,最后一整个字符串比较成功时,次数只需要+1。
比较失败 i 是当前位置, j 回退到 next【i】的位置
快排趟数,处理了n遍就意味着,有n个数满足:左边各个数均比它小,右边各个数均比它大。
T11 归并段 虚段
在一般情况下,对于 k–路平衡归并来说,若 (m-1)MOD(k-1)=0,则不需要增加虚段;否则需附加 k-(m-1)MOD(k-1)-1 个虚段。

T12 冯诺依曼机
冯.诺依曼结构计算机的功能部件包括输入设备, 输出设备,存储器, 运算器和控制
器, 程序的功能都通过中央处理器 (运算器和控制器) 执行指令
指令和数据以同等地位存于存储器内, 形式上无差别, 只在程序执行时具有不同的含义
指令按地址访问, 数据由指令的地址码指出, 除立即寻址, 数据均存放在存储器内,
在程序执行前, 指令和数据需预先存放在存储器中, 中央处理器可以从存储器存取代码,
转载:https://zhuanlan.zhihu.com/p/136748306
T14 缺页
在请求分页系统中,每当要访间的页面不在内存中时, CPU 检测到异常, 便会产生缺
页中断, 请求操作系统将所缺的页调入内存.
缺页处理由缺页中断处理程序完成, 根据发生缺页故障的地址从外存读入所缺失的页, 缺页处理完成后回到发生缺页的指令继续执行,
选项 D 中描述回到发生缺页的指令的下一条指令执行, 明显错误, 所以选 D.
T15 大小端存储地址
补码操作:求和+地址有效位位置=3,注意形式地址(补码)前补位,全F
原码操作:形式补码求原码,再求和
转载:https://blog.csdn.net/weixin_44001521/article/details/103577659
T16 时钟脉冲和周期
指令周期 : 取出并执行一条指令的时间。
机器周期 : 又称CPU周期,CPU访问一次内存所花的时间较长,因此用从内存读取一条指令字的最短时间来定义。
时钟周期 :又叫节拍脉冲,这是CPU最小的时间单位,CPU的每一次活动至少需要一个时钟周期。时钟周期的倒数是时钟频率,一般以此作为CPU性能的评价指标之一。
CPU的最小生命单位就是时钟周期,而一个机器周期包括若干个时钟周期,至于指令周期,则包含了若干个机器周期。如果按粒度排序,指令周期>机器周期>时钟周期。
时钟脉冲信号的宽度称为时钟周期, 时钟周期是 CPU 工作的最小时间单位, 肘钟周期
的倒数为机器主频.
时钟脉冲信号是由机器脉冲源发出的脉冲信号经整形和分频后形成的,
时钟周期以相邻状态单元间组合逻辑电路的最大延迟为基准确定.
CPU 从内存中取出并执行一条指令所需的全部时间称为指令周期, 指令周期又由若干机器周期来表示, 一个机器周期又包含若干时钟周期.
T17 指令取数及执行
该指令的两个源操作数分别采用寄存器, 寄存器间接寻址方式,因此在取数阶段需要用到通用寄存器组 (GPRs) 和存储器 (Memory): 在执行阶段, 两个源操作数相加需要用
到算术逻辑单元 (ALU).
而指令译码器 (D) 用于对操作码字段进行译码, 向控制器提供特定的操作信号, 在取数及执行阶段用不到.
转载:https://blog.csdn.net/qq_40626497/article/details/105183452
T19 总线带宽 = 通道数*频率*总线宽度
由题目可知, 计算机采用 3 通道存储器总线, 存储器总线的工作频率为 1333MHz 即 1
秒内传送 1333M 次数据,总线宽度为 64位, 即单条总线工作一次可传输8 字节 (B), 因
此存储器总线的总带宽为 3x8x1333MB/s, 约为 32GB/s, 故答案选 B.
T20 磁盘存储器
磁盘存储数据之前需要格式化,将磁盘分成扇区,并写入信息,因此磁盘的格式化容量要小于非格式化的。
磁盘扇区中包含数据,地址和校验等信息。
磁盘存储器由磁盘控制器,磁盘驱动器和盘片组成。
磁盘存储器的最小读写单元是一个扇区,即磁盘按块存取。
T22 DMA方式
DMA,全称Direct Memory Access,即直接存储器访问。
DMA传输将数据从一个地址空间复制到另一个地址空间,提供在外设和存储器之间或者存储器和存储器之间的高速数据传输。当CPU初始化这个传输动作,传输动作本身是由DMA控制器来实现和完成的。DMA传输方式无需CPU直接控制传输,也没有中断处理方式那样保留现场和恢复现场过程,通过硬件为RAM和IO设备开辟一条直接传输数据的通道,使得CPU的效率大大提高。
转载:https://blog.csdn.net/zhejfl/article/details/82555634
DMA传输开始前: CPU------>DMA控制器
DMA传输结束后: DMA控制器------>CPU
T23 用户线程和内核线程
对操作系统来说,用户级线程具有不可见性,也称透明性。
内核级线程缺点,让操作系统进行线程调度,那意味着每次切换线程,就需要「陷入」内核态,而操作系统从用户态到内核态的转变是有开销的,所以说内核级线程切换的代价要比用户级线程大。还有很重要的一点——线程表是存放在操作系统固定的表格空间或者堆栈空间里,所以内核级线程的数量是有限的,扩展性比不上用户级线程。
转载:https://zhuanlan.zhihu.com/p/87272557
T25 系统调用
系统调用是内核提供给应用程序使用的功能函数,由于应用程序一般运行在 用户态,处于用户态的进程有诸多限制(如不能进行 I/O 操作),所以有些功能必须由内核代劳完成。而内核就是通过向应用层提供 系统调用,来完成一些在用户态不能完成的工作。
转载:https://blog.csdn.net/IT_Financial/article/details/105084726
操作系统不同,底层逻辑,实现方式均不同,为应用程序提供的系统调用接口肯定不相同。
T26 文件系统管理空闲磁盘块的数据结构
传统的文件系统管理空闲磁盘的方法包括空闲表法, 空闲链表法, 位图法和成组链接法
文件分配表 (FAT) 的表项与物理磁盘块一一对应, 并且可以用一个特殊的数字-1表示文件的最后一块, 用-2表示这个磁盘块是空闲的(当然, 规定用-3.-4 来表示也是可行的). 因此 FAT 不仅记录了文件中各个块的先后链接关系, 同时还标记了空闲的磁盘块, 操作系统可以通过 FAT 对文件存储空间进行管理
索引结点是操作系统为了实现文件名与文件信息分开而设计的数据结构, 存储了文件描述信息, 索引结点属于文件目录管理部分的内容,
T28 分段存储管理系统
- 共享是以信息的逻辑单位为基础的。页是存储信息的物理单位,段却是信息的逻辑单位。
转载:https://blog.csdn.net/qq_28602957/article/details/53637103
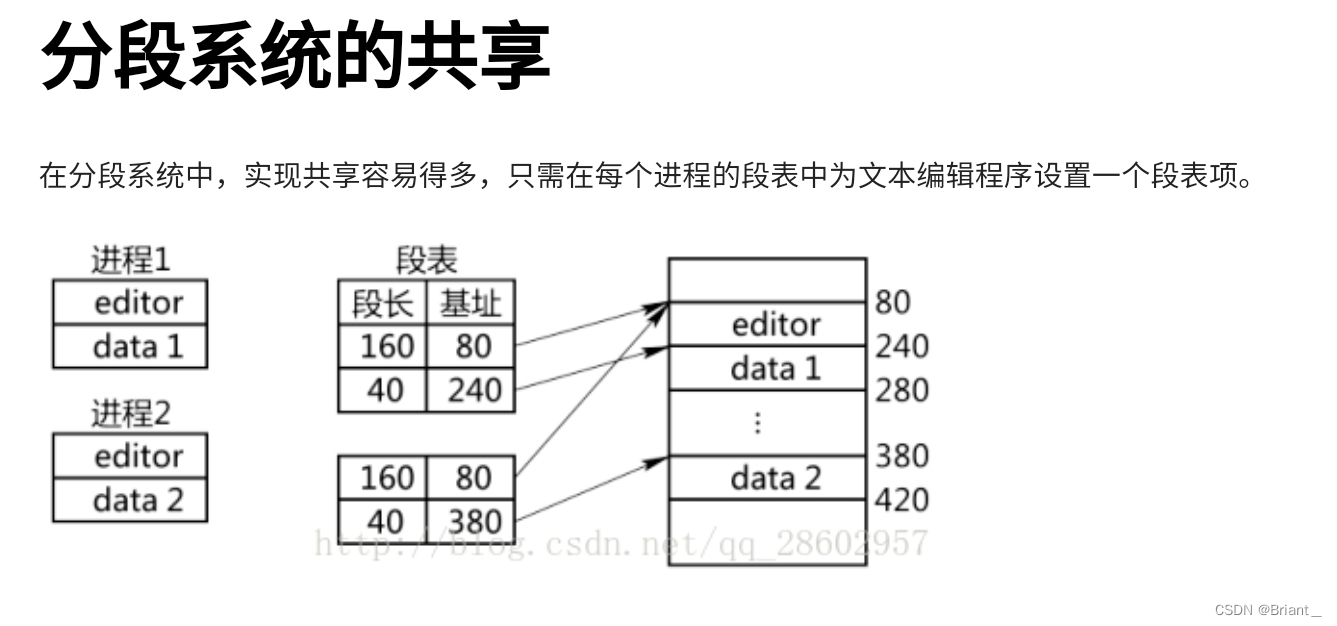 段的共享是通过两个作业的段表中相应表项指向被共享的段的同一物理副本实现的,因此在内存中仅保存一份段S的内容。
段的共享是通过两个作业的段表中相应表项指向被共享的段的同一物理副本实现的,因此在内存中仅保存一份段S的内容。
段 S 对于进程 P1,P2来说, 使用位置可能不同, 所以在不同进程中的逻辑段号可能不同, 段表项存放的是段的物理地址 (包括段始址和段长度), 对于共享段 S 来说物理地址唯一,
为了保证进程可以顺利使用段 S, 段 S 必须确保在没有任何进程使用它 (可在段表项中设置共享进程计数) 后才能被删除,
T32 内部碎片和外部碎片
内部碎片就是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间;
内部碎片是处于区域内部或页面内部的存储块。占有这些区域或页面的进程并不使用这个存储块。而在进程占有这块存储块时,系统无法利用它。直到进程释放它,或进程结束时,系统才有可能利用这个存储块。
外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。
外部碎片是出于任何已分配区域或页面外部的空闲存储块。这些存储块的总和可以满足当前申请的长度要求,但是由于它们的地址不连续或其他原因,使得系统无法满足当前申请。
TIPS:内碎片可以理解为占着茅坑不拉S,外碎片可以理解为茅坑虽然是空着的,但是太小了,有些大胖子进不去
转载:https://blog.csdn.net/haiross/article/details/38704945
最佳适应算法总是匹配与当前大小要求最接近的空闲分区, 但是大多数情況下空闲分区的大小不可能完全和当前要求的大小相等, 几乎每次分配内存都会产生很小的难以利用的内存块,所以最佳适应算法最容易产生最多的内存碎片, 选项 C 正确.
T36 信道的传播时延和帧的传输时延
为了确保发送站在发送数据的同时能检测到可能存在的冲突, 需要在发送完帧之前就能收到自己发送出去的数据, 帧的传输时延至少要两倍于信号在总线中的传播时延, 所以 CSMA/CD总线网中的所有数据帧都必须要大于一个最小帧长, 这个最小帧长=总线传播时延x数据传输速率x2. 已知最小帧长为 128B, 数据传输速率为 100Mbps = 12.5MB/s, 计算得单向传播延时为128B/(12.5MB/S*2) - 5.12x106s, 即 5.12HS.
简单理解:为了使得帧发送完就能接收到已经通过信道来回的数据,传输时延>两倍的传播时延。传输时延=帧长/速率,传播时延=信道长度/信道传输率,此题只需要求出传输时延再/2,可得传播时延。
T37 最小子网可分配IP

T38 拥塞控制,慢开始,快恢复,快重传
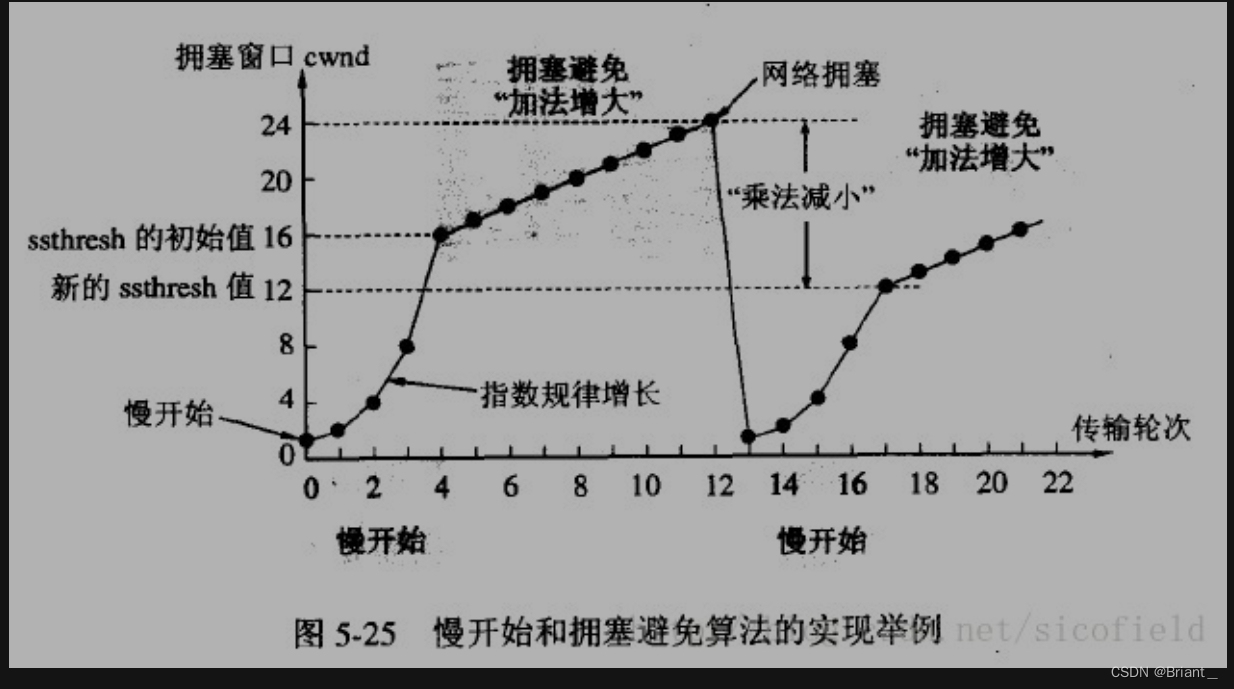
发送方维持一个叫做拥塞窗口cwnd(congestion window)的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。
为了防止cwnd增长过大引起网络拥塞,还需设置一个慢开始门限ssthresh状态变量。ssthresh的用法如下:
当cwnd<ssthresh时,使用慢开始算法。
当cwnd>ssthresh时,改用拥塞避免算法。
当cwnd=ssthresh时,慢开始与拥塞避免算法任意。
无论是在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞:
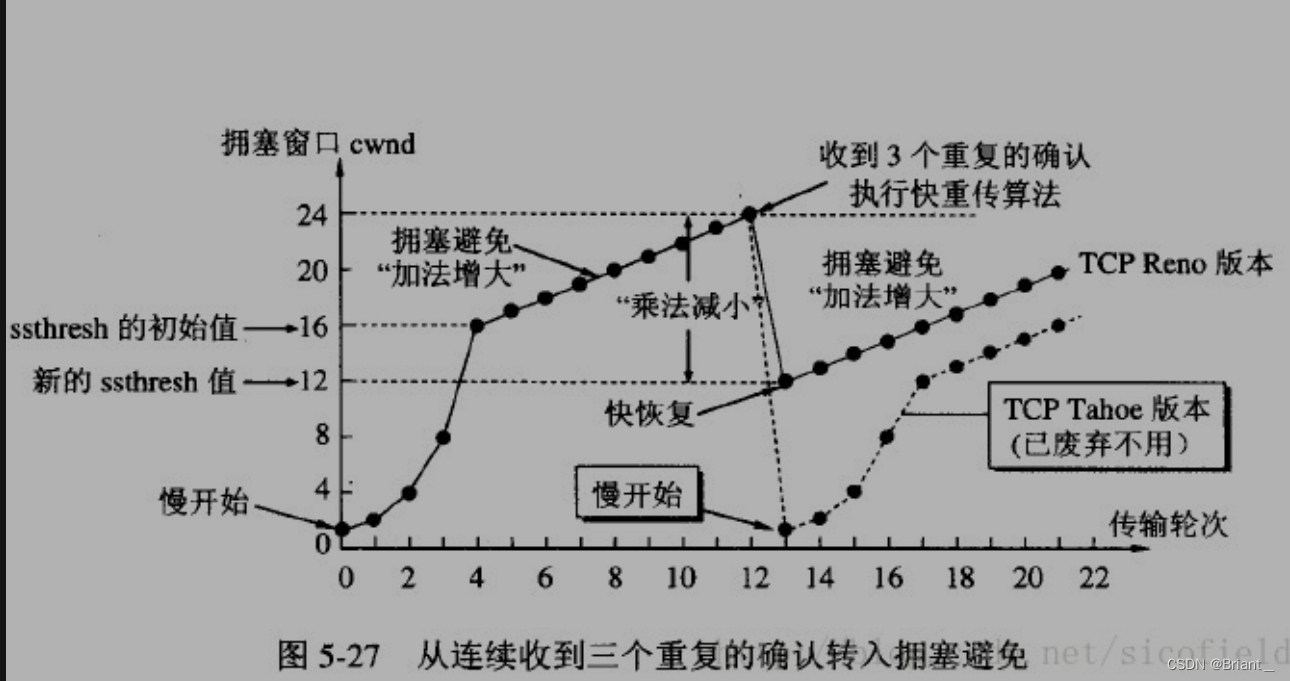
快重传算法规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段,而不必继续等待设置的重传计时器时间到期。
快重传配合使用的还有快恢复算法,有以下两个要点:
①当发送方连续收到三个重复确认时,就执行“乘法减小”算法,把ssthresh门限减半。但是接下去并不执行慢开始算法。
②考虑到如果网络出现拥塞的话就不会收到好几个重复的确认,所以发送方现在认为网络可能没有出现拥塞。所以此时不执行慢开始算法,而是将cwnd设置为ssthresh的大小,然后执行拥塞避免算法。如下图:
转载:https://blog.csdn.net/sinat_21112393/article/details/50810053
TCP流量控制和拥塞控制:https://zhuanlan.zhihu.com/p/37379780
T39 三报文握手 四报文挥手
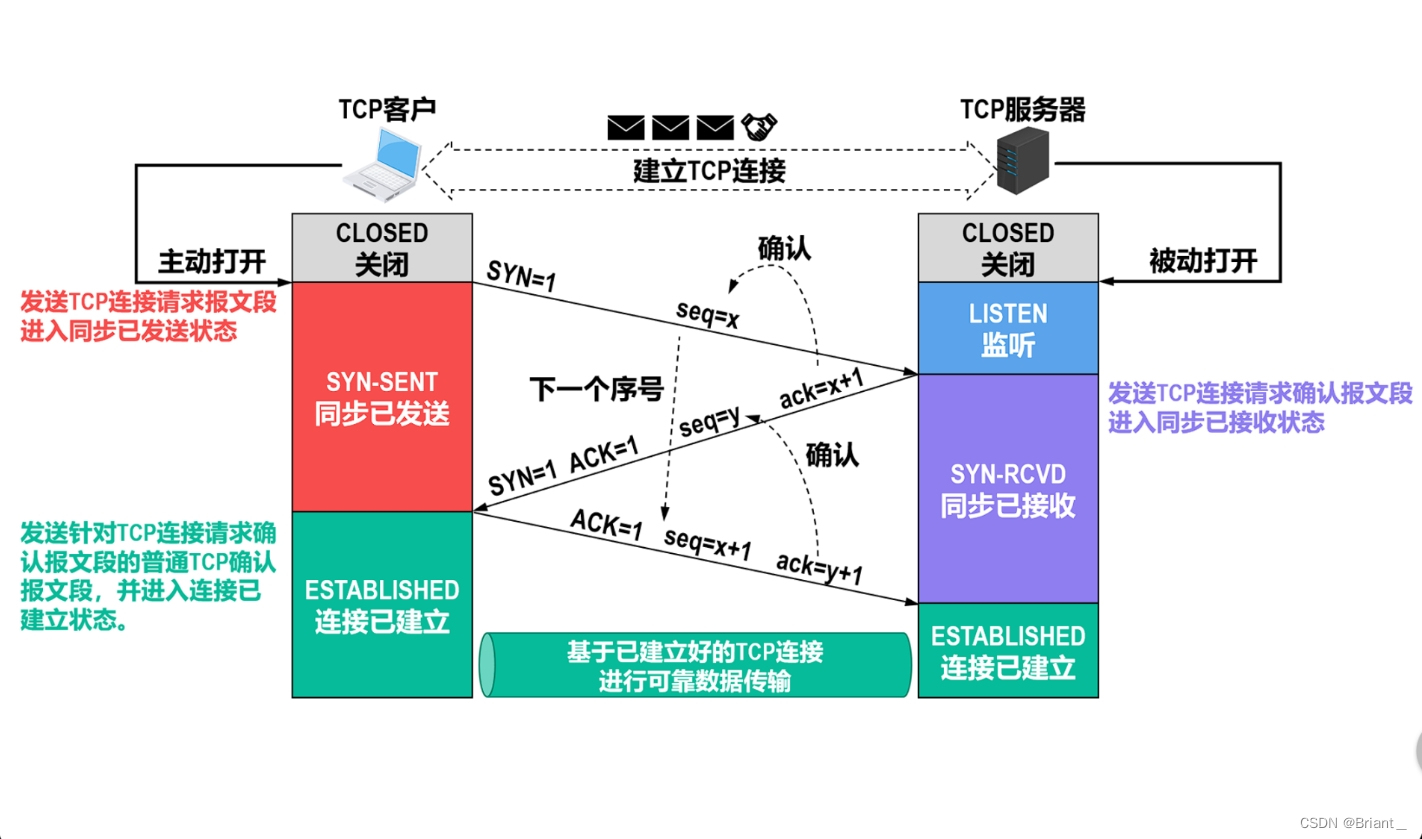
转载:https://blog.csdn.net/sunqi568/article/details/106671419
T40 P2P和C/S模型
转载:https://blog.csdn.net/qq_37474301/article/details/116997815














 2873
2873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









