







 本文是RNN教程的最后一部分,主要介绍LSTM和GRU神经网络。LSTM通过门控机制解决梯度消失问题,而GRU是其简化版。在许多任务中,LSTM和GRU表现相当,但GRU参数更少,可能训练更快。文中还介绍了如何在Python中实现GRU,并探讨了性能优化技巧,包括批量处理和使用Keras等深度学习库。
本文是RNN教程的最后一部分,主要介绍LSTM和GRU神经网络。LSTM通过门控机制解决梯度消失问题,而GRU是其简化版。在许多任务中,LSTM和GRU表现相当,但GRU参数更少,可能训练更快。文中还介绍了如何在Python中实现GRU,并探讨了性能优化技巧,包括批量处理和使用Keras等深度学习库。
本文翻译自
代码在Github上
这是Part4 ,RNN教程的最后一部分;
在这一部分,主要学习LSTM神经网络和GRU。LSTM在1997年首次提出,几乎是最流行的用于自然语言处理的深度学习模型。GRUs在2014年首次提出,是LSTMs的简单变体。让我们关注LSTMs,再看看GRUs有什么不同。
LSTM NETWORKS
前面提到,梯度消失问题能够阻止标准RNNs学习长距离的依赖关系。LSTMs通过门控机制来克服梯度消失。为了理解其中的含义,让我们看看LSTM是如何计算隐含层状态St.
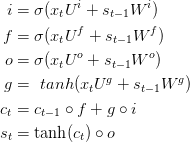
这些等式看起来相当的复杂,但是比更不像想象中的那么难。首先,注意LSTM层仅仅是计算隐含层状态的另一种方法;之前我们使用
LSTM单元做了同样的事情,只是方式不同。理解下面的图是关键;你可以把LSTM单元当作黑箱来对待,根据当前的输入和之前的隐含层状态,计算下一个隐含层状态;
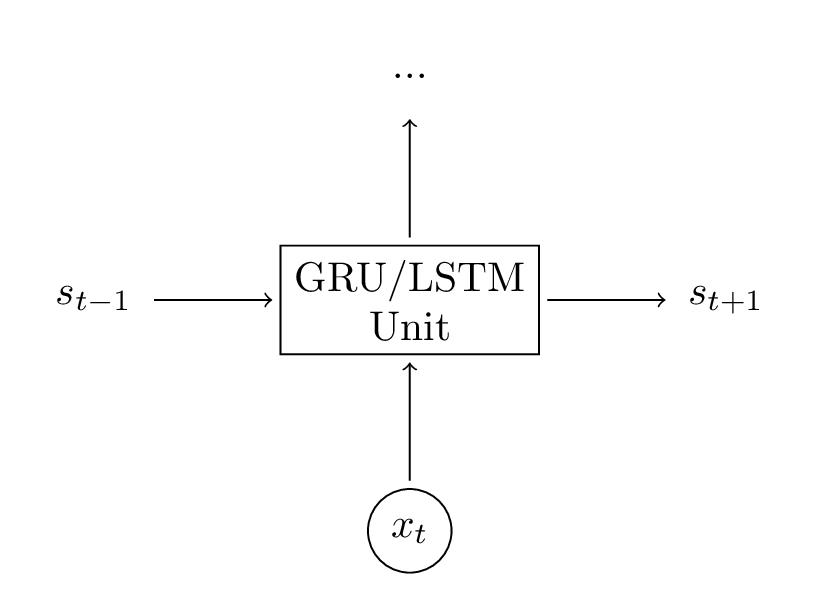
让我们有个直觉的感受:LSTM 是如何计算隐含层状态的;相关博客
这里做简单的解释,读上述博客能够更深入的理解和好的可视化。但是,总结如下:
尤其是,在基本的LSTM框架下存在一些变体。一个通常的做法是构建窥视孔链接,它允许门不仅仅依赖于之前的隐含层状态St-1,而且依赖于先前的内部状态Ct-1,在门等式上添加一个新项;这里有很多变体,https://arxiv.org/pdf/1503.04069.pdf“>这篇文章评价了不同的LASTM架构;
GRUS
GRU层背后的思想和LSTM层背后的思想相似,等式如下:
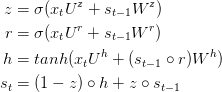
GRU有两个门,一个重置门r和一个更新门,直观的,重置门决定了如何把新的输入与之前的记忆相结合,更新门决定多少先前的记忆起作用。如果我们把所有reset设置为全1,更新门设置为全0,又达到了普通RNN的形式;使用一个门机制学习长距离依赖的基本思想与LSTM相同,但是有如下不同点:
GRU有两个门 ,LSTM有三个门;
GRU不能处理
输入和遗忘门能够被更新门z耦合,重置门r能够直接应用于之前的隐含状态。因此,重置门的职责在LSTM中被拆分为r和z;
计算输出时不应用第二非线性函数;
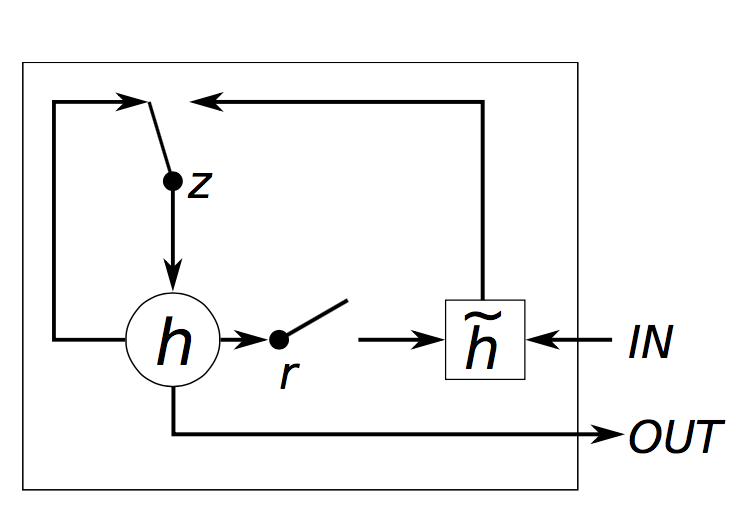
GRU VS LSTM
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









