







transforms的使用
transforms就像一个工具箱,是一个.py文件,主要用到里面的一些类,可以将特定格式的图片进行转化。
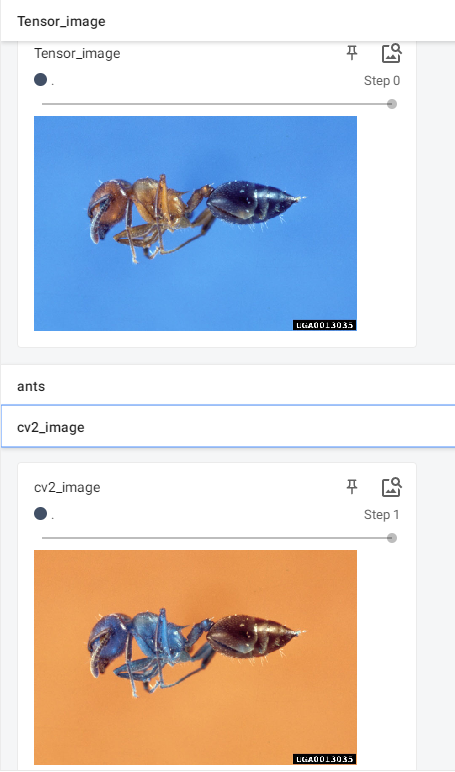
在之前的笔记中,用SummaryWriter.add_image()读取图片的类型为numpy.ndarray型,这次用tensor(torch.Tensor)型。
tensor数据类型,包装了神经网络中的一些参数。
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
import cv2
img_path = "data/train/ants_image/0013035.jpg" # 图片的相对路径
img_PIL = Image.open(img_path) # PIL格式图片,按RGB读取
writer = SummaryWriter("logs")
# 创建对象,即SummaryWriter的实例化,会生成事件文件,参数"logs"为保存的文件夹名
tensor_trans = transforms.ToTensor()
# transforms是一个python文件,里面有ToTensor类,此处创建其对象
img_tensor = tensor_trans.__call__(img_PIL)
# 使用ToTensor的__call__方法,将PIL格式的图片转化为tensor格式
img_cv = cv2.imread(img_path) # 使用opencv读图片,格式为numpy.ndarray型,按BGR读取
writer.add_image("Tensor_image", img_tensor)
# 用add_image方法生成图片,可用tensorboard查看,在终端输入tensorboard --logdir=logs,点击网址查看
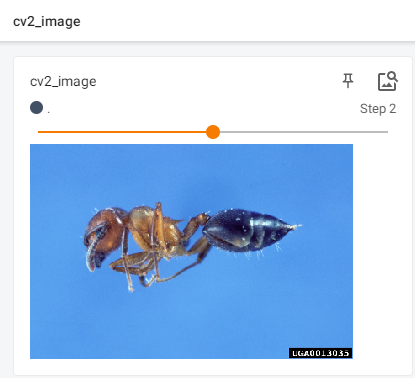
writer.add_image("cv2_image", img_cv, 1, dataformats="HWC")
# 查看用cv2和PIL打开的图片有何不同
writer.close() # 需要关闭,否则无法查看图片

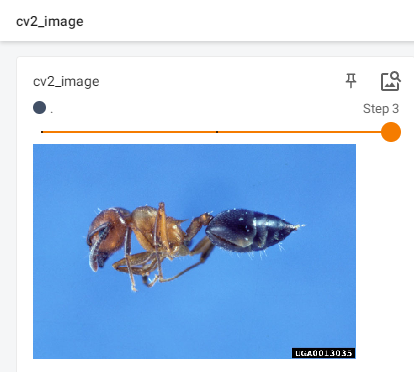
cv读取图片时图像通道的顺序是BGR,PIL是RGB,颜色不一样,需要转化,方法如下:
# 方法一
img_cv = img_cv[:, :, ::-1] # 图像的通道转换成RGB
# 方法二
img_cv = cv2.cvtColor(img_cv, cv2.COLOR_BGR2RGB) # 图像的通道转换成RGB参考:
此时再次在TensorBoard中查看图片,发现颜色已经转化。
发现查看图片可以用如下方法:
from PIL import Image
image_path = "data/train/ants_image/6743948_2b8c096dda.jpg"
img = Image.open(image_path)
img.show()参考:
常见的transforms中的类
totensor,normalize,resize,compose,randomcrop,下面是完整代码。
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
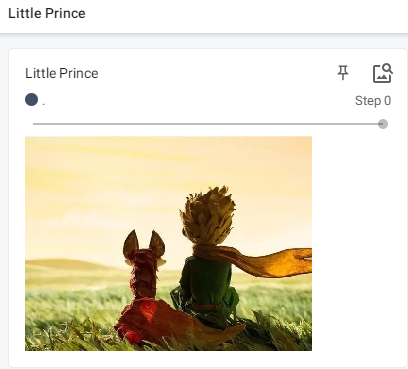
img = Image.open("images/小王子.png")
print(img)
# ToTensor
trans_tensor = transforms.ToTensor() # ToTensor实例化
# 转化为tensor格式图片。输入参数,自动调用__call__方法,把PIL格式图片变成tensor格式
img_tensor = trans_tensor(img)
writer.add_image("Little Prince", img_tensor) # 可用tensorboard对tensor类型的图片进行查看
# Normalize
# 查看img_tensor中第[0][0][0]处的数据
print(img_tensor[0][0][0])
# Normalize的实例化,输入了两个参数,均值mean = [1, 2, 4], 标准差std = [2, 5, 6]
trans_norm = transforms.Normalize([1, 2, 4], [2, 5, 6])
# ``output[channel] = (input[channel] - mean[channel]) / std[channel]``
img_norm = trans_norm(img_tensor)
# 查看经过标准化之后img_norm中第[0][0][0]处的数据
print(img_norm[0][0][0])
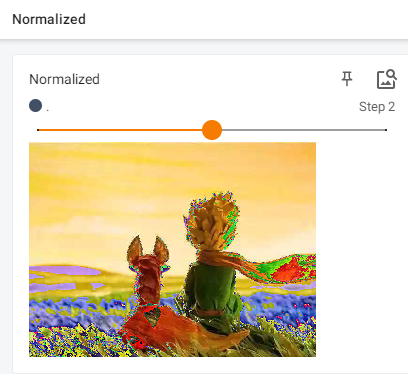
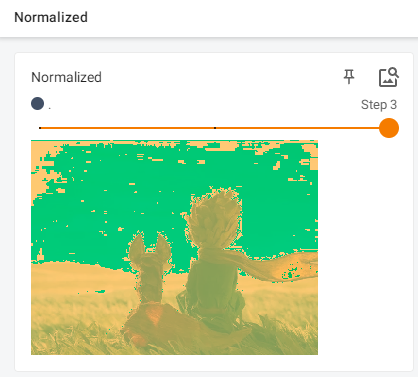
# 修改上面参数中的均值和标准差序列,查看输出图片结果,这里修改add_image的global_step,查看三步
writer.add_image("Normalized", img_norm, 3)
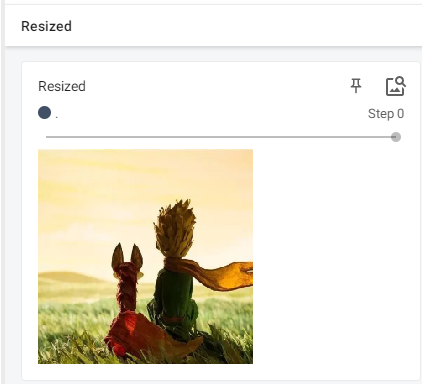
# Resize
print(img.size)
trans_Resize = transforms.Resize((512, 512)) # 实例化,创建对象,输入其中的初始化参数为sequence类
# img(PIL类) -> resize -> img_resize(PIL类)
img_resize = trans_Resize(img)
# img_resize(PIL类) -> ToTensor -> img_resize(tensor类)
img_resize = trans_tensor(img_resize)
writer.add_image("Resized", img_resize, 0)
print(img_resize.size)
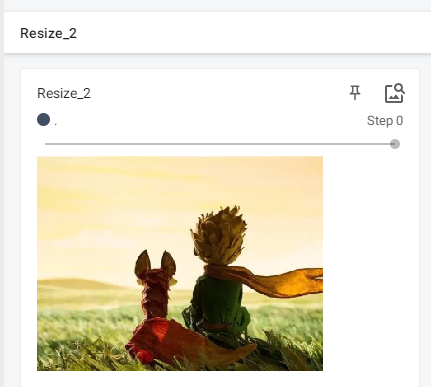
# Compose -resize -2 第二种方法
# 实例化,创建对象,输入的初始化参数是int类,不改变H和W的比例关系,只改变最小边到目标的size
trans_Resize_2 = transforms.Resize(521)
# 使用Compose类,将多个transforms合并,参数是由多个transform对象组合成的列表
trans_Compose = transforms.Compose([trans_Resize_2, trans_tensor])
# 直接进行两步操作,resize和图片格式转化为tensor
img_resize_2 = trans_Compose(img)
writer.add_image("Resize_2", img_resize_2, 0)
# RandomCrops
# 实例化,类的初始化中需要输入size(sequence or int)
trans_RandomCorps = transforms.RandomCrop((150, 100))
trans_Compose_2 = transforms.Compose([trans_RandomCorps, trans_tensor])
for i in range(10):
img_crop = trans_Compose_2(img)
writer.add_image("RandomCropHW", img_crop, i)
writer.close()
ToTensor输出:
normalize输出:
resize输出:
resize_2输出:
randomcrop输出:
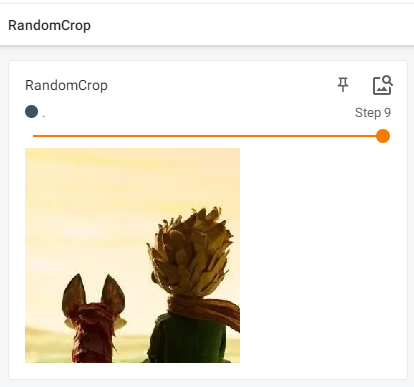
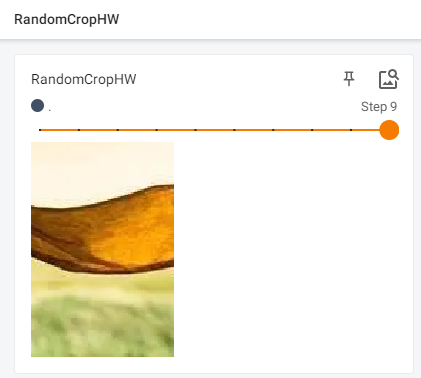
randomcropHW:
总结:
在用到类中方法的时候,关注输入输出需要什么参数、数据类型,可以在Args里面查看。
可以用print()/print(tpye())/debug查看输出是什么样的,多试。
transforms.Normalize()的使用,为上面总代码的一部分。
Pytorch图像预处理时,通常使用transforms.Normalize(mean, std)对图像按通道进行标准化,即减去均值,再除以标准差,这样做可以加快模型的收敛速度。其中参数mean和std分别表示图像每个通道的均值和标准差序列。(参考:transforms.Normalize()标准化)
from torchvision import transforms
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
img = Image.open("images/小王子.png")
print(img)
# ToTensor
trans_tensor = transforms.ToTensor()
img_tensor = trans_tensor(img)
writer.add_image("Little Prince", img_tensor)
# Normalize
print(img_tensor[0][0][0]) # 查看img_tensor中第[0][0][0]处的数据
trans_norm = transforms.Normalize([1, 2, 4], [2, 5, 6])
# 输入了两个参数,均值mean = [1, 2, 4], 标准差std = [2, 5, 6]
# ``output[channel] = (input[channel] - mean[channel]) / std[channel]``
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0]) # 查看经过标准化之后img_norm中第[0][0][0]处的数据
writer.add_image("Normalized", img_norm, 3)
# 修改上面参数中的均值和标准差序列,查看输出图片结果,这里修改add_image的global_step,查看三步
writer.close()















 1666
1666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









