






Qwen-VL 是阿里巴巴在多模态学习领域提出的一种新型模型。它具有处理视觉和语言信息的能力,旨在增强计算机对图像和文本的理解与生成能力。今天正好空闲了就把Qwen-VL的论文拿过来打算整体读下,本文主要是自己的论文阅读笔记,感兴趣的话可以参考一下,如果想要阅读原英文论文的话,地址在这里,如下所示:

摘要
在这项工作中,我们介绍了Qwen-VL系列,这是一组大规模的视觉语言模型(LVLMs),旨在感知和理解文本和图像。从Qwen-LM作为基础开始,我们通过精心设计的(i)视觉接收器、(ii)输入输出接口、(iii)3阶段训练管道和(iv)多语言多模态清洗语料库赋予其视觉能力。除了传统的图像描述和问答之外,我们通过对齐图像-标题-框元组实现了Qwen-VL的定位和文本阅读能力。由此产生的模型,包括Qwen-VL和Qwen-VL-Chat,在广泛的视觉中心基准测试(例如,图像描述、问答、视觉定位)和不同设置(例如,零样本、少样本)下,在类似模型规模的通用模型中创下了新纪录。此外,在实际对话基准测试中,我们经过指令微调的Qwen-VL-Chat也展示了优于现有视觉语言聊天机器人的优势。所有模型均公开以促进未来研究。
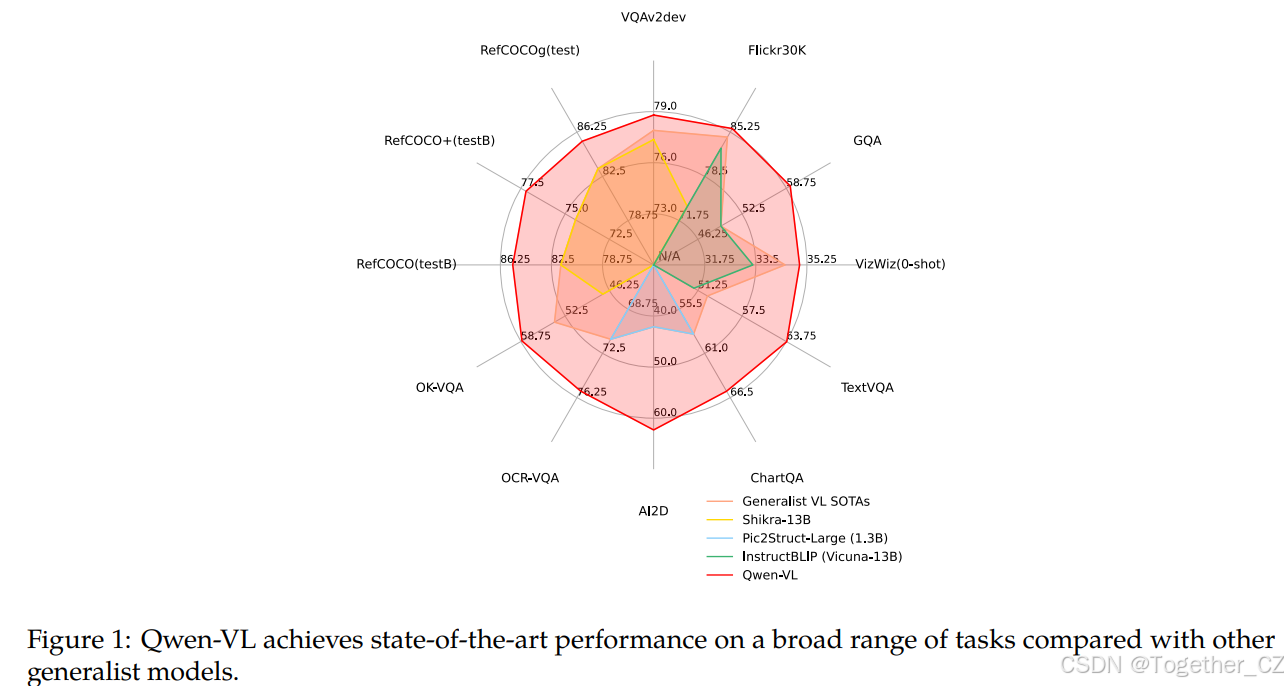
图1:Qwen-VL在广泛的基准测试中与其他通用模型相比达到了最先进的性能。
1 引言
最近,大型语言模型(LLMs)(Brown et al., 2020; OpenAI, 2023; Anil et al., 2023; Gao et al., 2023; Owen, 2023)因其强大的文本生成和理解能力而引起了广泛关注。这些模型可以通过指令微调进一步对齐用户意图,展示出强大的交互能力和作为智能助手提高生产力的潜力。然而,原生大型语言模型仅存在于纯文本世界中,缺乏处理其他常见模态(如图像、语音和视频)的能力,这极大地限制了它们的应用范围。受此启发,一组大规模视觉语言模型(LVLMs)(Alayrac et al., 2022; Chen et al., 2022; Li et al., 2023c; Dai et al., 2023; Huang et al., 2023; Peng et al., 2023; Zhu et al., 2023; Liu et al., 2023; Ye et al., 2023a,b; Chen et al., 2023a; Li et al., 2023a; Zhang et al., 2023; Sun et al., 2023; OpenAI, 2023)被开发出来,以增强大型语言模型感知和理解视觉信号的能力。这些大规模视觉语言模型在解决现实世界的视觉中心问题方面展示了有希望的潜力。

图2:我们Qwen-VL-Chat生成的一些定性示例。Qwen-VL-Chat支持多图像输入、多轮对话、多语言对话、文本阅读、定位、细粒度识别和理解能力。
尽管已经进行了大量工作来探索LVLMs的局限性和潜力,但当前的开源LVLMs总是受到训练和优化的不足,因此远远落后于专有模型(Chen et al., 2022, 2023b; OpenAI, 2023),这阻碍了LVLMs在开源社区中的进一步探索和应用。此外,由于现实世界的视觉场景非常复杂,细粒度的视觉理解对于LVLMs有效准确地辅助人们至关重要。但只有少数尝试朝着这个方向进行(Peng et al., 2023; Chen et al., 2023a),大多数开源LVLMs仍然以粗粒度的方式感知图像,缺乏执行细粒度感知(如对象定位或文本阅读)的能力。
在这篇论文中,我们探索了一条出路,并介绍了开源Qwen家族的最新成员:Qwen-VL系列。Qwen-VLs是一系列高性能且多功能的基础视觉语言模型,基于Qwen-7B(Qwen, 2023)语言模型。我们通过引入新的视觉接收器(包括语言对齐的视觉编码器和位置感知适配器)赋予LLM基础视觉能力。整体模型架构以及输入输出接口非常简洁,我们详细设计了一个3阶段训练管道,以在大量图像文本语料库上优化整个模型。
我们的预训练检查点,称为Qwen-VL,能够感知和理解视觉输入,根据给定的提示生成所需的响应,并完成各种视觉语言任务,如图像描述、问答、面向文本的问答和视觉定位。Qwen-VL-Chat是基于Qwen-VL的指令微调视觉语言聊天机器人。如图2所示,Qwen-VL-Chat能够与用户交互并根据用户的意图感知输入图像。
具体来说,Qwen-VL系列模型的特点包括:
-
领先性能:Qwen-VLs在与类似规模的同行相比,在广泛的视觉中心理解基准测试中实现了顶级准确性。此外,Qwen-VL的惊人性能不仅涵盖了传统的基准测试(例如,描述、问答、定位),还包括一些最近引入的对话基准测试。
-
多语言:与Qwen-LM类似,Qwen-VLs在多语言图像文本数据上进行训练,其中相当一部分语料库是英语和中文。通过这种方式,Qwen-VLs自然支持英语、中文和多语言指令。
-
多图像:在训练阶段,我们允许任意交错的图像文本数据作为Qwen-VL的输入。这一特性使得我们的Qwen-Chat-VL能够在给出多张图像时比较、理解和分析上下文。
-
细粒度视觉理解:由于我们在训练中使用了更高分辨率的输入尺寸和细粒度语料库,Qwen-VLs展示了高度竞争的细粒度视觉理解能力。与现有的视觉语言通用模型相比,我们的Qwen-VLs在定位、文本阅读、面向文本的问答和细粒度对话性能方面表现更好。
2 方法
模型架构
Qwen-VL的整体网络架构由三个组件组成,模型参数的详细信息如表1所示:
表1:Qwen-VL模型参数的详细信息
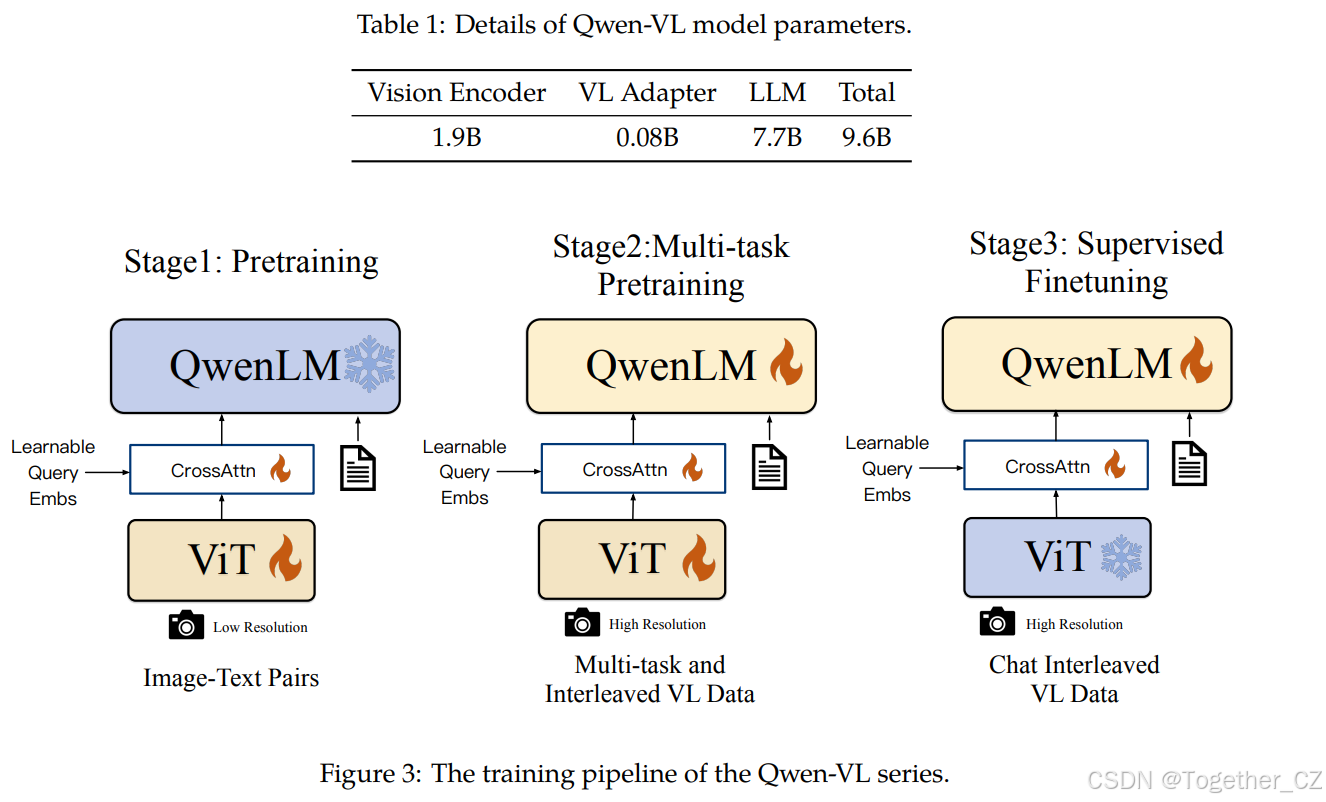
图3:Qwen-VL系列的训练流程
大型语言模型: Qwen-VL采用大型语言模型作为其基础组件。该模型从Qwen-7B(Qwen, 2023)的预训练权重进行初始化。
视觉编码器: Qwen-VL的视觉编码器使用Vision Transformer(ViT)(Dosovitskiy et al., 2021)架构,从Openclip的ViT-bigG(Ilharco et al., 2021)的预训练权重进行初始化。在训练和推理过程中,输入图像被调整到特定分辨率。视觉编码器通过将图像分割成步长为14的块来处理图像,生成一组图像特征。
位置感知的视觉语言适配器: 为了缓解长图像特征序列带来的效率问题,Qwen-VL引入了一个视觉语言适配器来压缩图像特征。该适配器包含一个随机初始化的单层交叉注意力模块。该模块使用一组可训练向量(嵌入)作为查询向量,视觉编码器的图像特征作为键进行交叉注意力操作。此机制将视觉特征序列压缩到固定长度256。关于查询数量的消融研究见附录E.2。此外,考虑到位置信息对细粒度图像理解的重要性,二维绝对位置编码被纳入交叉注意力机制的查询-键对中,以减轻压缩过程中潜在的位置细节损失。压缩后的长度为256的图像特征序列随后被输入到大型语言模型中。
输入和输出
图像输入: 图像通过视觉编码器和适配器处理,生成固定长度的图像特征序列。为了区分图像特征输入和文本特征输入,两个特殊标记(和)分别附加在图像特征序列的开头和结尾,表示图像内容的开始和结束。
边界框输入和输出: 为了增强模型对细粒度视觉理解和定位的能力,Qwen-VL的训练涉及区域描述、问题和检测形式的数据。与涉及图像文本描述或问题的传统任务不同,此任务需要模型准确理解和生成指定格式的区域描述。对于任何给定的边界框,应用归一化过程(范围为[0, 1000))并转换为指定字符串格式:“(X_topleft,Y_topleft),(X_bottomright,Y_bottomright)”。该字符串被标记化为文本,不需要额外的位置词汇表。为了区分检测字符串和常规文本字符串,在边界框字符串的开头和结尾添加两个特殊标记(和)。此外,为了适当关联边界框与其相应的描述性词语或句子,引入另一组特殊标记(和),标记边界框引用的内容。
3 训练
如图3所示,Qwen-VL模型的训练过程包括三个阶段:两个预训练阶段和一个最终的指令微调训练阶段。
预训练
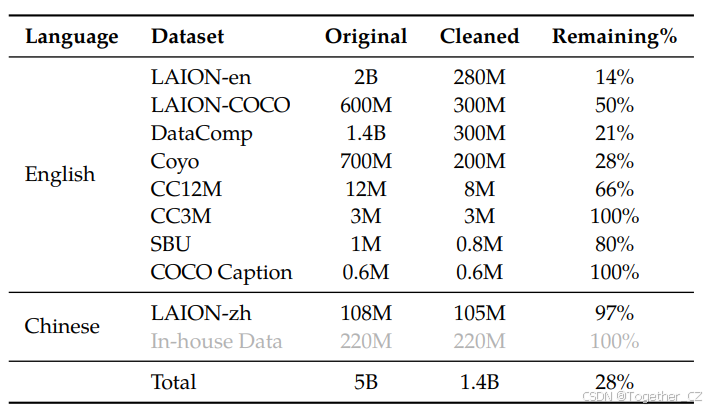
在第一阶段预训练中,我们主要利用大规模、弱标记的网络爬取的图像文本对数据集。我们的预训练数据集由几个公开可访问的来源和一些内部数据组成。我们努力清理数据集中的一些模式。如表2总结,原始数据集包含总共50亿个图像文本对,清理后剩下14亿个数据,其中77.3%是英语(文本)数据,22.7%是中文(文本)数据。
表2:Qwen-VL预训练数据的详细信息。LAION-en和LAION-zh是LAION-5B的英语和中文子集(Schuhmann et al., 2022a)。LAION-COCO(Schuhmann et al., 2022b)是从LAION-en生成的合成数据集。DataComp(Gadre et al., 2023)和Coyo(Byeon et al., 2022)是图像文本对的集合。CC12M(Changpinyo et al., 2021)、CC3M(Sharma et al., 2018)、SBU(Ordonez et al., 2011)和COCO Caption(Chen et al., 2015)是学术描述数据集。
我们在这个阶段冻结大型语言模型,仅优化视觉编码器和视觉语言适配器。输入图像被调整为224×224。训练目标是使文本标记的交叉熵最小化。最大学习率为2e-4,训练过程使用30720的图像文本对批次大小,整个第一阶段预训练持续50,000步,消耗大约15亿个图像文本样本。更多超参数详见附录C,该阶段的收敛曲线如图6所示。
多任务预训练
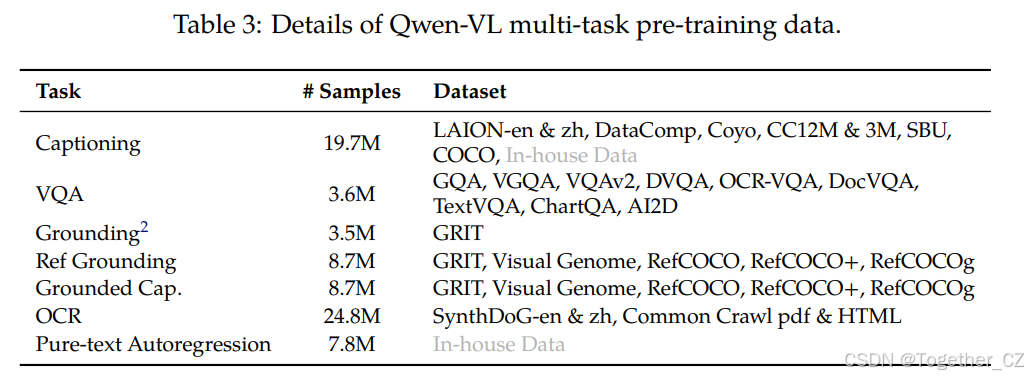
在第二阶段多任务预训练中,我们引入了高质量和细粒度的视觉语言注释数据,输入分辨率更大,图像文本数据交错。如表3总结,我们在7个任务上同时训练Qwen-VL。对于文本生成,我们使用内部收集的语料库来保持LLM的能力。描述数据与表2相同,只是样本少得多,不包括LAION-COCO。我们使用公开可用的数据混合用于VQA任务,包括GQA(Hudson and Manning, 2019)、VGQA(Krishna et al., 2017)、VQAv2(Goyal et al., 2017)、DVQA(Kafle et al., 2018)、OCR-VQA(Mishra et al., 2019)和DocVQA(Mathew et al., 2021)。我们按照Kosmos-2使用GRIT(Peng et al., 2023)数据集进行定位任务,并进行了一些修改。对于引用定位和接地描述对偶任务,我们从GRIT(Peng et al., 2023)、Visual Genome(Krishna et al., 2017)、RefCOCO(Kazemzadeh et al., 2014)、RefCOCO+和RefCOCOg(Mao et al., 2016)构建训练样本。为了改进面向文本的任务,我们从Common Crawl收集pdf和HTML格式数据,并按照Kim et al.(2022)生成英语和中文语言的合成OCR数据,背景为自然风景。最后,我们简单地将相同任务数据打包成长度为2048的序列,构建交错图像文本数据。
表3:Qwen-VL多任务预训练数据的详细信息。
我们将视觉编码器的输入分辨率从224×224增加到448×448,减少了图像下采样引起的信息损失。此外,我们在附录E.3中对高分辨率视觉Transformer的窗口注意力和全局注意力进行了消融。我们解锁了大型语言模型并训练整个模型。训练目标与预训练阶段相同。
监督微调
在这个阶段,我们通过指令微调对Qwen-VL预训练模型进行微调,以增强其指令跟随和对话能力,从而得到交互式的Qwen-VL-Chat模型。多模态指令微调数据主要来自通过LLM自指令生成的描述数据或对话数据,这些数据通常仅涉及单图像对话和推理,并限于图像内容理解。我们通过手动注释、模型生成和策略拼接构建了额外的对话数据集,将定位和多图像理解能力纳入Qwen-VL模型。我们确认模型有效地将这些能力转移到更广泛的语言和问题类型中。此外,我们在训练过程中混合多模态和纯文本对话数据,以确保模型在对话能力上的通用性。指令微调数据量为350k。在这个阶段,我们冻结视觉编码器并优化语言模型和适配器模块。我们在附录B.2中展示了该阶段的数据格式。
4 评估
在本节中,我们对各种多模态任务进行了整体评估,以全面评估我们模型的视觉理解能力。在以下内容中,Qwen-VL表示多任务训练后的模型,Qwen-VL-Chat表示监督微调(SFT)阶段后的模型。
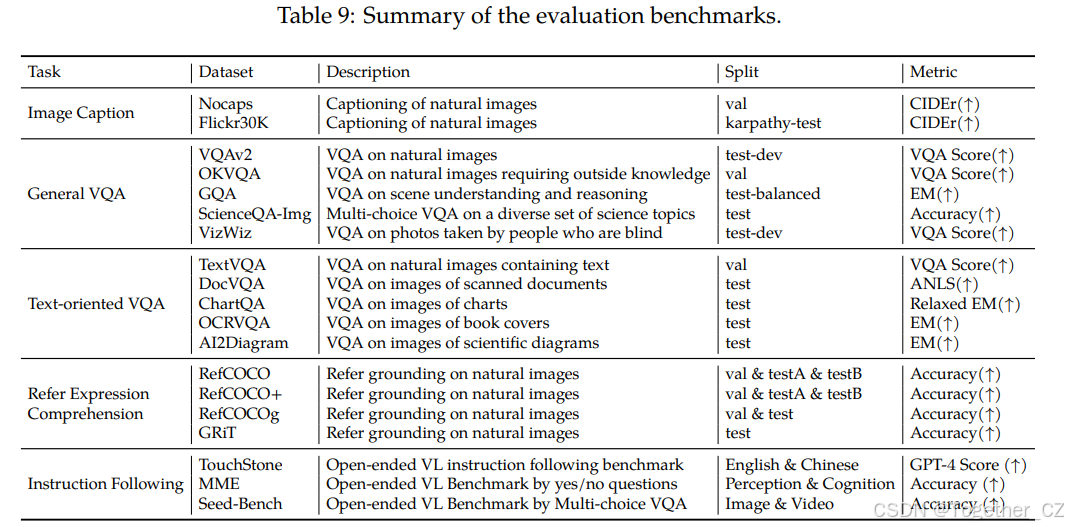
表9提供了所用评估基准的详细总结和相应指标。
表4:图像描述和一般视觉问答的结果。
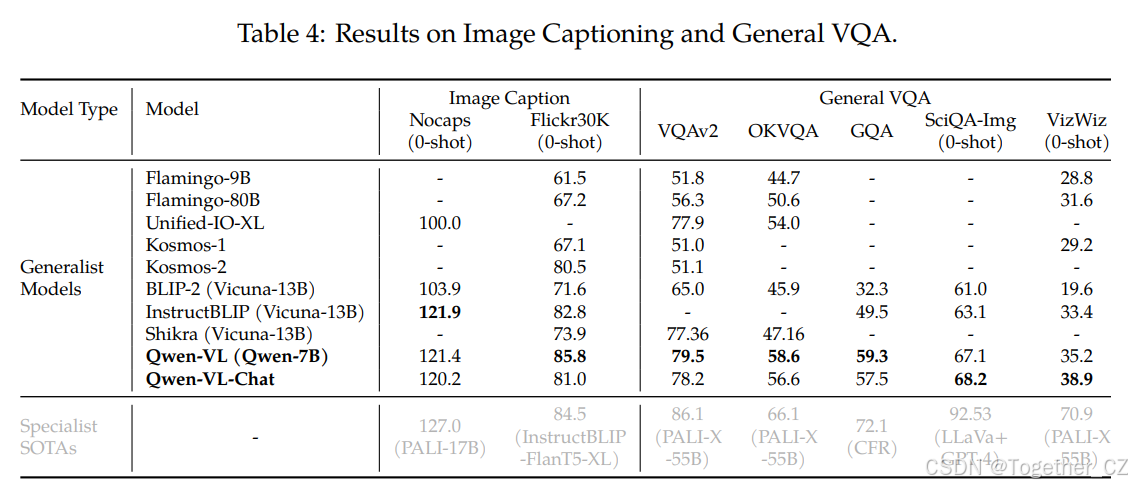
图像描述和一般视觉问答
图像描述和一般视觉问答(VQA)是视觉语言模型的两个传统任务。具体来说,图像描述要求模型为给定图像生成描述,一般VQA要求模型为给定图像问题对生成答案。
对于图像描述任务,我们选择NoCaps(Agrawal et al., 2019)和Flickr30K(Young et al., 2014)作为基准,并报告CIDEr分数(Vedantam et al., 2015)作为指标。我们使用贪婪搜索进行描述生成,提示为“Descripe the image in English:”。
对于一般VQA,我们使用五个基准,包括VQAv2(Goyal et al., 2017)、OKVQA(Marino et al., 2019)、GQA(Hudson and Manning, 2019)、ScienceQA(图像集)(Lu et al., 2022b)和VizWiz VQA(Gurari et al., 2018)。对于VQAv2、OKVQA、GQA和VizWiz VQA,我们使用贪婪解码策略进行开放式答案生成,提示为“(question) Answer:”,模型输出空间没有任何约束。然而,对于ScienceQA,我们将模型的输出限制为可能的选项(而不是开放式),选择置信度最高的选项作为模型的预测,并报告Top-1准确率。
图像描述和一般VQA任务的总体性能如表4所示。如结果所示,我们的Qwen-VL和Qwen-VL-Chat在两个任务上均明显优于之前的通用模型。具体来说,在零样本图像描述任务中,Qwen-VL在Flickr30K karpathy-test分割上达到了最先进的性能(即85.8 CIDEr分数),甚至超过了参数多得多的之前的通用模型(例如,Flamingo-80B有80亿参数)。
在一般VQA基准测试中,我们的模型也表现出明显的优势。在VQAv2、OKVQA和GQA基准测试中,Qwen-VL分别达到了79.5、58.6和59.3的准确率,显著超过了最近提出的LVLMs。值得注意的是,Qwen-VL在ScienceQA和VizWiz数据集上也展示了强大的零样本性能。
面向文本的视觉问答
面向文本的视觉理解在现实场景中具有广泛的应用前景。我们在几个基准测试上评估了我们模型面向文本的视觉问答能力,包括TextVQA(Sidorov et al., 2020)、DocVQA(Mathew et al., 2021)、ChartQA(Masry et al., 2022)、AI2Diagram(Kembhavi et al., 2016)和OCR-VQA(Mishra et al., 2019)。结果如表5所示。与之前的通用模型和最近的LVLMs相比,我们的模型在大多数基准测试上表现更好,通常有较大的优势。
引用表达理解
我们通过在一系列引用表达理解基准测试上进行评估,展示了我们模型的细粒度图像理解和定位能力,例如RefCOCO(Kazemzadeh et al., 2014)、RefCOCOg(Mao et al., 2016)、RefCOCO+(Mao et al., 2016)和GRIT(Gupta et al., 2022)。具体来说,引用表达理解任务要求模型根据描述定位目标对象。结果如表6所示。与之前的通用模型或最近的LVLMs相比,我们的模型在所有基准测试上均获得了顶级结果。
表5:面向文本的视觉问答的结果。
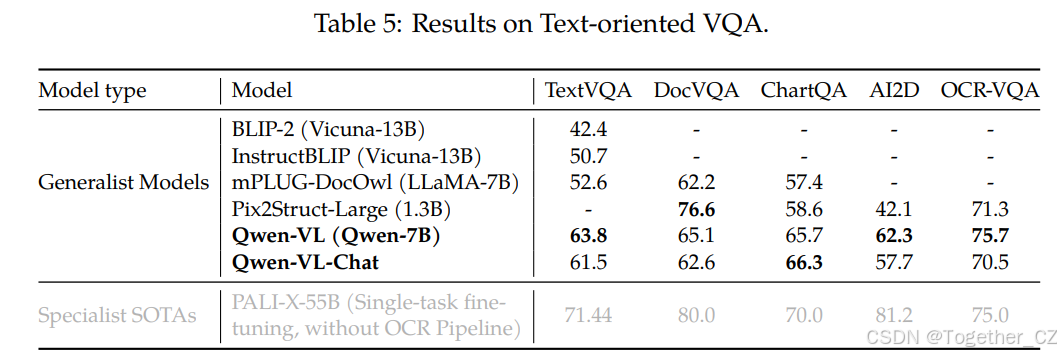
表6:引用表达理解任务的结果。
视觉语言任务的少样本学习
我们的模型还展示了令人满意的上下文学习(即少样本学习)能力。如图4所示,Qwen-VL在OKVQA(Marino et al., 2019)、VizWiz(Gurari et al., 2018)、TextVQA(Sidorov et al., 2020)和Flickr30k(Young et al., 2014)上通过上下文少样本学习取得了更好的性能,与参数数量相似的模型(如Flamingo-9B(Alayrac et al., 2022)、OpenFlamingo-9B(Awadalla et al., 2023)和IDEFICS-9B(Laurençon et al., 2023))相比。Qwen-VL的性能甚至可以与更大的模型(如Flamingo-80B和IDEFICS-80B)相媲美。请注意,我们采用朴素的随机采样来构建少样本示例,尽管使用更复杂的少样本示例构建方法(如RICES(Yang et al., 2022b))可以取得更好的结果,但我们没有使用。
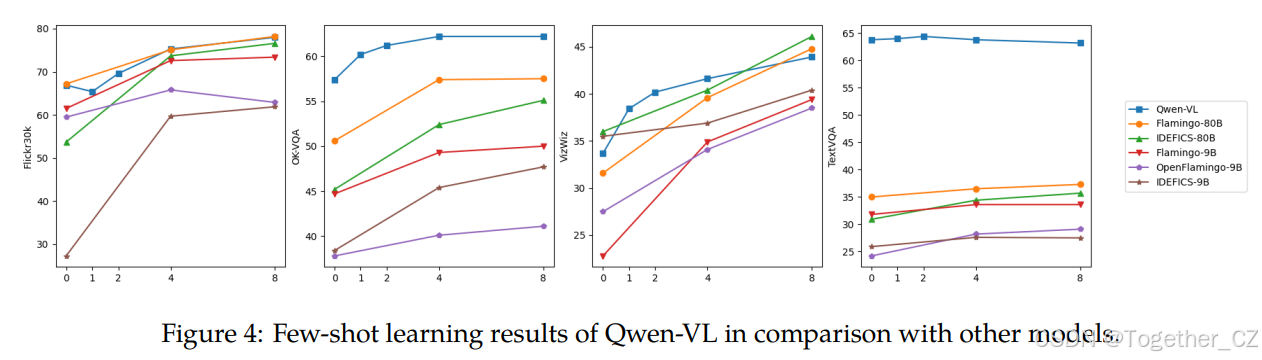
图4:Qwen-VL与其他模型相比的少样本学习结果。
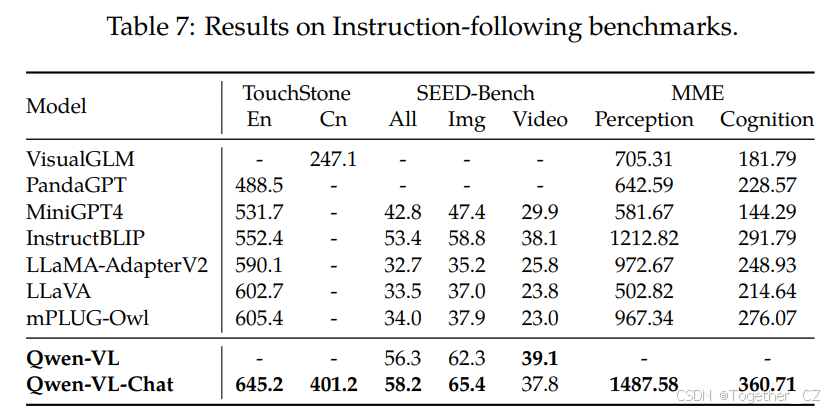
表7:指令跟随基准测试的结果
实际用户行为中的指令跟随
除了之前的传统视觉语言评估外,为了评估Qwen-VL-Chat模型在实际用户行为下的能力,我们进一步在TouchStone(Bai et al., 2023)、SEED-Bench(Li et al., 2023b)和MME(Fu et al., 2023)上进行了评估。TouchStone是一个开放式的视觉语言指令跟随基准。我们在TouchStone基准测试上比较了Qwen-VL-Chat与其他指令微调LVLMs的指令跟随能力,包括英语和中文。SEED-Bench由19K个多项选择题组成,具有准确的人类注释,用于评估多模态LLMs,涵盖12个评估维度,包括空间和时间理解。MME在总共14个子任务上测量感知和认知能力。
三个基准测试的结果如表7所示。Qwen-VL-Chat在所有三个数据集上均取得了明显的优势,表明我们的模型在理解和回答多样化的用户指令方面表现更好。在SEED-Bench中,我们发现通过简单地采样四帧,我们的模型的视觉能力可以有效地转移到视频任务中。在TouchStone的整体分数中,我们的模型与其他LVLMs相比展示了明显的优势,特别是在中文能力方面。在广泛的能力类别中,我们的模型在理解和识别方面展示了更显著的优势,特别是在文本识别和图表分析等领域。更多详细信息请参阅TouchStone数据集。
5 相关工作
近年来,研究人员对视觉语言学习(Su et al., 2019; Chen et al., 2020; Li et al., 2020; Zhang et al., 2021; Li et al., 2021a; Lin et al., 2021; Kim et al., 2021; Dou et al., 2022; Zeng et al., 2021; Li et al., 2022, 2023c),特别是多任务通用模型的发展(Hu and Singh, 2021; Singh et al., 2022; Zhu et al., 2022; Yu et al., 2022; Wang et al., 2022a; Lu et al., 2022a; Bai et al., 2022)表现出极大的兴趣。CoCa(Yu et al., 2022)提出了一种编码器-解码器结构,同时解决图像文本检索和视觉语言生成任务。OFA(Wang et al., 2022a)通过定制的任务指令将特定的视觉语言任务转换为序列到序列任务。Unified I/O(Lu et al., 2022a)进一步将更多任务(如分割和深度估计)引入统一框架。另一类研究集中在构建视觉语言表示模型(Radford et al., 2021; Jia et al., 2021; Zhai et al., 2022; Yuan et al., 2021; Yang et al., 2022a)。CLIP(Radford et al., 2021)利用对比学习和大量数据在语义空间中对齐图像和语言,从而在广泛的下游任务中展现出强大的泛化能力。BEIT-3(Wang et al., 2022b)采用混合专家(MOE)结构和统一的掩码标记预测目标,在各种视觉语言任务上取得了最先进的结果。除了视觉语言学习外,ImageBind(Girdhar et al., 2023)和ONE-PEACE(Wang et al., 2023)还将更多模态(如语音)对齐到统一的语义空间中,从而创建了更通用的表示模型。
尽管取得了显著进展,之前的视觉语言模型仍存在几个局限性,如指令跟随中的鲁棒性差、在未见任务中的泛化能力有限以及缺乏上下文能力。随着大型语言模型(LLMs)(Brown et al., 2020; OpenAI, 2023; Anil et al., 2023; Gao et al., 2023; Owen, 2023)的快速发展,研究人员开始基于LLMs构建更强大的大型视觉语言模型(LVLMs)(Alayrac et al., 2022; Chen et al., 2022; Li et al., 2023c; Dai et al., 2023; Huang et al., 2023; Peng et al., 2023; Zhu et al., 2023; Liu et al., 2023; Ye et al., 2023a,b; Chen et al., 2023a; Li et al., 2023a; Zhang et al., 2023; Sun et al., 2023)。BLIP-2(Li et al., 2023c)提出了Q-Former,以对齐冻结的视觉基础模型和LLMs。同时,LLaVA(Liu et al., 2023)和MiniGPT4(Zhu et al., 2023)引入了视觉指令微调,以增强LVLMs的指令跟随能力。此外,mPLUG-DocOwl(Ye et al., 2023a)通过引入数字文档数据,将文档理解能力纳入LVLMs。Kosmos-2(Peng et al., 2023)、Shikra(Chen et al., 2023a)和BuboGPT(Zhao et al., 2023)进一步增强了LVLMs的视觉定位能力,实现了区域描述和定位。在这项工作中,我们将图像描述、视觉问答、OCR、文档理解和视觉定位能力集成到Qwen-VL中。由此产生的模型在这些多样化的任务上表现出色。
6 结论和未来工作
我们发布了Qwen-VL系列,这是一组旨在促进多模态研究的大规模多语言视觉语言模型。Qwen-VL在各种基准测试中优于类似模型,支持多语言对话、多图像交错对话、中文定位和细粒度识别。展望未来,我们致力于在几个关键维度上进一步增强Qwen-VL的能力:
-
将Qwen-VL与更多模态(如语音和视频)集成。
-
通过扩大模型规模、训练数据和更高分辨率来增强Qwen-VL,使其能够处理多模态数据中更复杂和精细的关系。
-
扩展Qwen-VL在多模态生成方面的能力,特别是在生成高保真图像和流畅语音方面。
附录
数据集详细信息
图像文本对
我们使用网络爬取的图像文本对数据集进行预训练,包括LAION-en(Schuhmann et al., 2022a)、LAION-zh(Schuhmann et al., 2022a)、LAION-COCO(Schuhmann et al., 2022b)、DataComp(Gadre et al., 2023)和Coyo(Byeon et al., 2022)。我们通过以下步骤清理这些噪声数据:
-
移除图像宽高比过大的图像文本对
-
移除图像过小的图像文本对
-
移除CLIP分数过低的图像文本对(特定数据集)
-
移除文本包含非英语或非中文字符的图像文本对
-
移除文本包含表情符号的图像文本对
-
移除文本长度过短或过长的图像文本对
-
清理文本的HTML标记部分
-
清理具有某些不规则模式的文本
对于学术描述数据集,我们移除文本包含CC12M(Changpinyo et al., 2021)和SBU(Ordonez et al., 2011)中特殊标记的图像文本对。如果同一图像匹配多个文本,我们选择最长的文本。
VQA
对于VQAv2(Goyal et al., 2017)数据集,我们选择置信度最高的答案注释。对于其他VQA数据集,我们没有做任何特殊处理。
定位
对于GRIT(Peng et al., 2023)数据集,我们发现许多标题中包含递归的定位框标签。我们使用贪心算法清理标题,确保每张图像包含最多的框标签且没有递归框标签。对于其他定位数据集,我们简单地将名词/短语与其相应的边界框坐标连接起来。
OCR
我们使用Synthdog(Kim et al., 2022)生成合成OCR数据集。具体来说,我们使用COCO(Lin et al., 2014)train2017和unlabeld2017数据集分割作为自然风景背景。然后我们选择了41种英文字体和11种中文字体生成文本。我们使用Synthdog中的默认超参数。我们跟踪生成文本在图像中的位置,并将其转换为四边形坐标,我们也使用这些坐标作为训练标签。可视化示例如图5第二行所示。
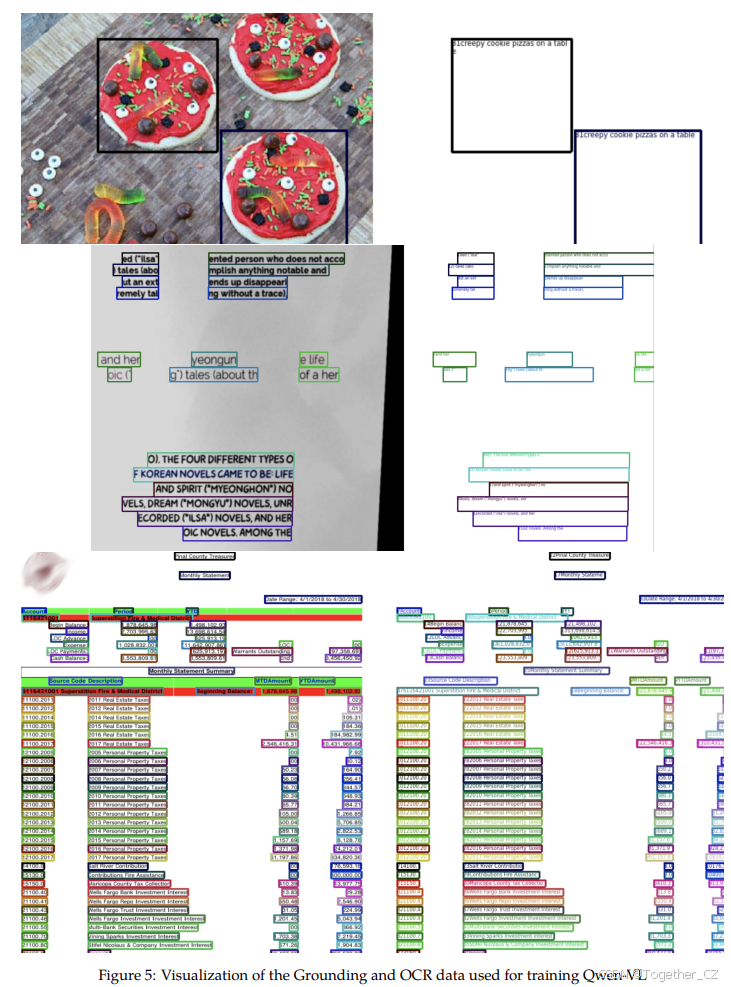
图5:用于训练Qwen-VL的定位和OCR数据的可视化
对于我们收集的所有PDF数据,我们使用PyMuPDF(Software, 2015)按照以下步骤预处理数据,以获取PDF文件中每一页的渲染结果以及所有文本注释及其边界框。
-
提取每一页的所有文本及其边界框。
-
渲染每一页并将其保存为图像文件。
-
移除过小的图像。
-
移除包含过多或过少字符的图像。
-
移除包含“Latin Extended-A”和“Latin Extended-B”块中Unicode字符的图像。
-
移除包含“Private Use Area (PUA)”块中Unicode字符的图像。
对于我们收集的所有HTML网页,我们使用Puppeteer(Google, 2023)以类似的方式预处理数据,以渲染这些HTML页面并获取地面真值注释。我们按照以下步骤预处理数据。
-
提取每一页的所有文本。
-
渲染每一页并将其保存为图像文件。
-
移除过小的图像。
-
移除包含过多或过少字符的图像。
-
移除包含“Private Use Area (PUA)”块中Unicode字符的图像。
训练数据格式的详细信息
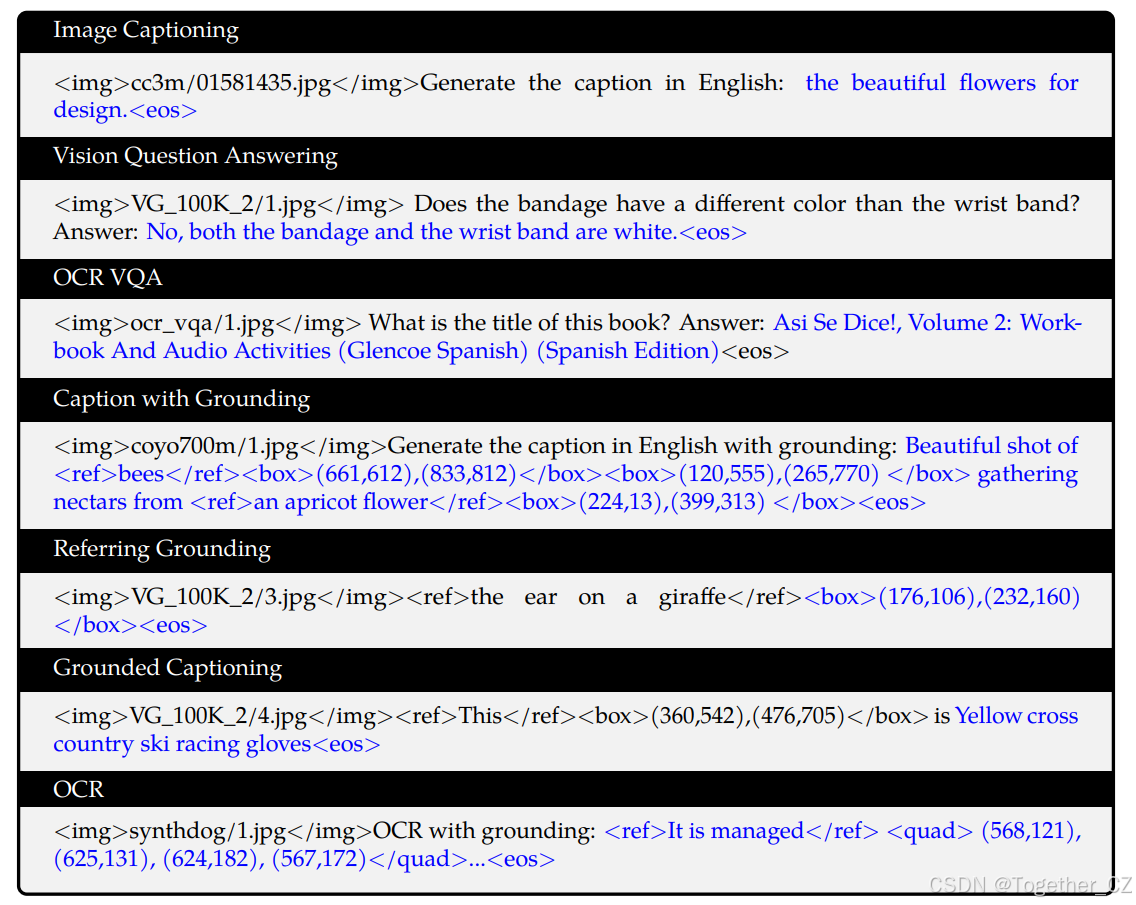
多任务预训练的数据格式
我们在Box B.1中可视化了多任务预训练的数据格式。Box包含所有7个任务,黑色文本为无损失的前缀序列,蓝色文本为带损失的地面真值标签。
监督微调的数据格式
为了更好地适应多图像对话和多图像输入,我们在不同图像前添加字符串“Picture id:”,其中_id_对应图像输入对话的顺序。在对话格式方面,我们使用ChatML(Openai)格式构建指令微调数据集,其中每个交互的陈述用两个特殊标记(<im_start>和<im_end>)标记,以方便对话终止。
在训练过程中,我们通过仅监督答案和特殊标记(示例中的蓝色部分),而不监督角色名称或问题提示,确保预测和训练分布的一致性。

超参数
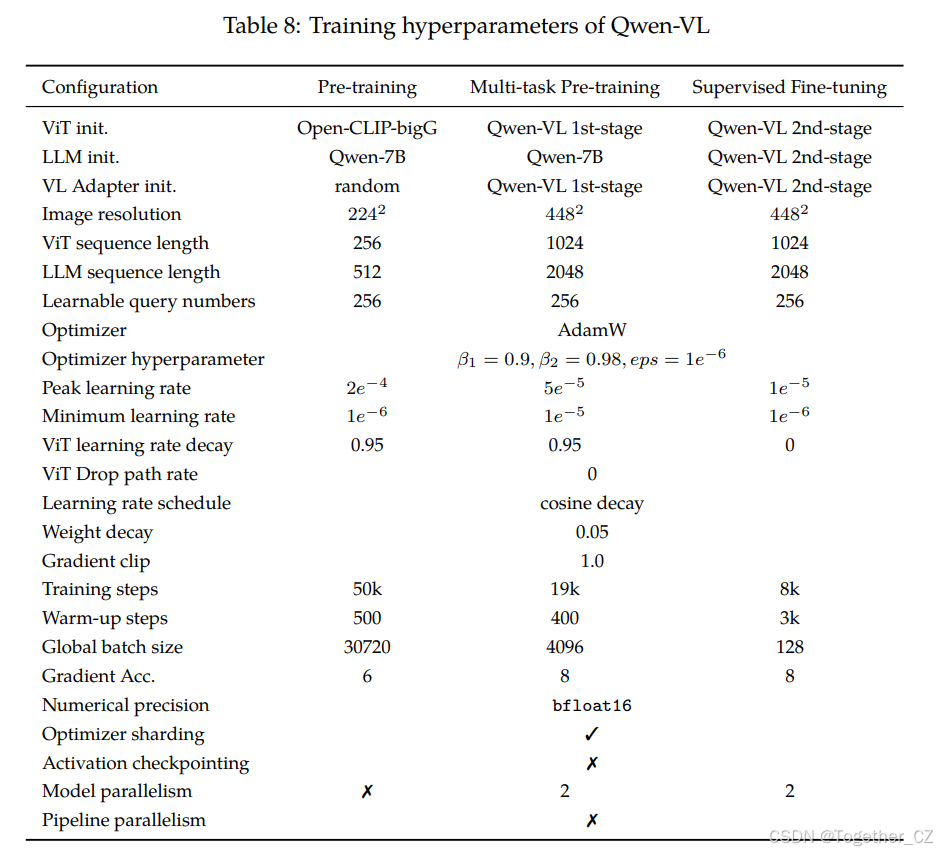
我们在表8中报告了Qwen-VL的详细训练超参数设置。
表8:Qwen-VL的训练超参数
在第一阶段预训练中,模型使用AdamW优化器进行训练,β1=0.9,β2=0.98,eps=1e-6。我们使用余弦学习率计划,最大学习率为2e-4,最小为1e-6,线性预热500步。我们使用0.05的权重衰减和1.0的梯度裁剪。对于ViT图像编码器,我们应用层级学习率衰减策略,衰减因子为0.95。训练过程使用30720的图像文本对批次大小,整个第一阶段预训练持续50,000步,消耗大约15亿个图像文本样本和5000亿个图像文本标记。
在第二阶段多任务训练中,我们将视觉编码器的输入分辨率从224×224增加到448×448,减少了图像下采样引起的信息损失。我们解锁了大型语言模型并训练整个模型。训练目标与预训练阶段相同。我们使用AdamW优化器,β1=0.9,β2=0.98,eps=1e-6。我们训练了19000步,预热400步,余弦学习率计划。具体来说,我们使用模型并行技术进行ViT和LLM。
评估基准的详细总结
我们在表9中提供了所用评估基准的详细总结和相应指标。
表9:评估基准的总结
额外实验细节
预训练阶段的收敛
在图6中,我们展示了预训练阶段(第一阶段)的收敛情况。整个模型使用BFloat16混合精度进行训练,批次大小为30720,学习率为2e-4。所有图像仅训练一次(一个epoch)。训练损失随着训练图片数量的增加稳步下降。请注意,预训练阶段(第一阶段)没有添加VQA数据,但零样本VQA分数在波动中增加。
视觉语言适配器中的可学习查询数量
视觉语言适配器使用交叉注意力通过一组长度为的查询向量压缩视觉特征序列。查询数量过少会导致某些视觉信息的丢失,而查询数量过多可能会导致更大的收敛难度和计算成本。
我们对视觉语言适配器中可学习查询的数量进行了消融实验。我们使用ViT-L/14作为视觉编码器,输入图像分辨率为224×224,因此ViT的输出序列长度为(224/14)2=256。如图7左侧所示,训练开始时使用的查询数量越少,初始损失越低。然而,随着收敛,过多或过少的查询会导致收敛速度减慢,如图7右侧所示。考虑到第二阶段训练(多任务预训练)应用448×448分辨率,其中ViT的输出序列长度为(448/14)2=1024。过少的查询会导致更多信息的丢失。我们最终选择在Qwen-VL中使用256个查询进行视觉语言适配器。
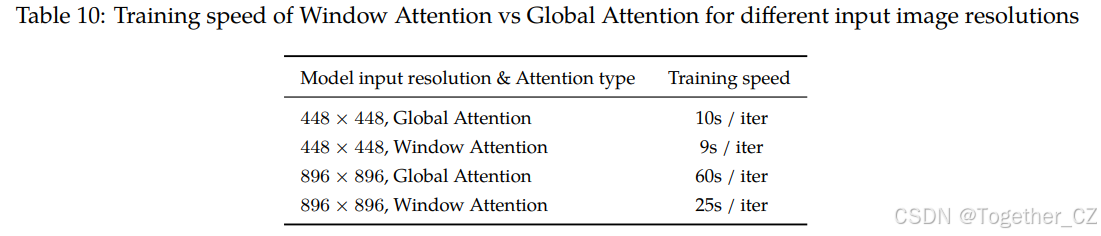
视觉Transformer的窗口注意力与全局注意力
在模型中使用高分辨率的Vision Transformer会显著增加计算成本。一种可能的解决方案是在Vision Transformer的大多数层中使用窗口注意力,即仅在224×224的窗口中执行注意力,并在ViT部分模型的少数层(例如每4层中的1层)中对全448×448或896×896图像执行注意力,以减少模型的计算成本。
为此,我们进行了消融实验,比较了使用全局注意力和窗口注意力时ViT的模型性能。我们比较了实验结果,分析了计算效率和模型收敛之间的权衡。
如图8和表10所示,使用窗口注意力而不是全局注意力时,模型的损失显著更高。两者的训练速度相似。因此,我们决定在训练Qwen-VL时使用全局注意力而不是窗口注意力进行Vision Transformer。
我们不使用896×896分辨率的窗口注意力的原因是其训练速度太慢。尽管它在5000步时达到了与448×448分辨率输入模型相似的损失值。其训练时间几乎是448×448分辨率输入模型的2.5倍。
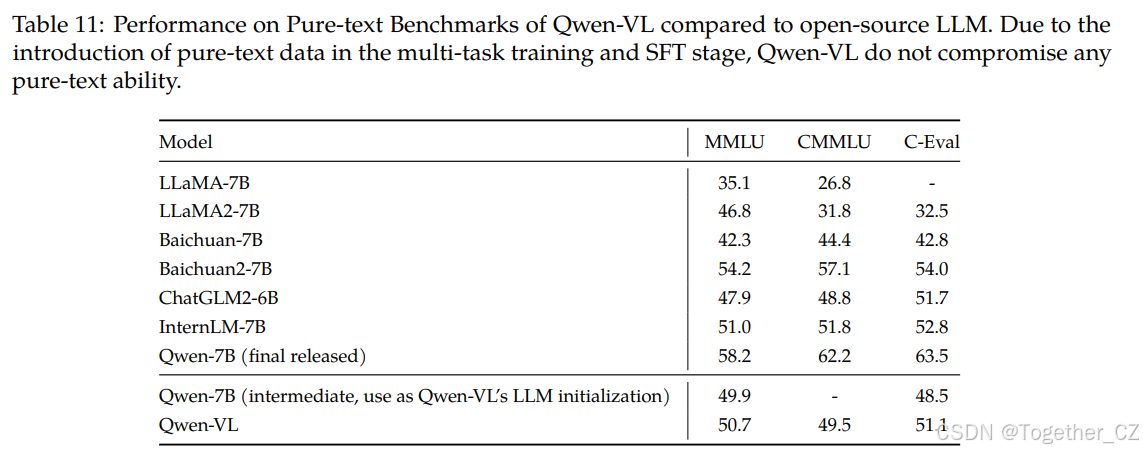
纯文本任务的性能
为了研究多模态训练对纯文本能力的影响,我们在表11中展示了Qwen-VL与开源LLM在纯文本任务上的性能比较。
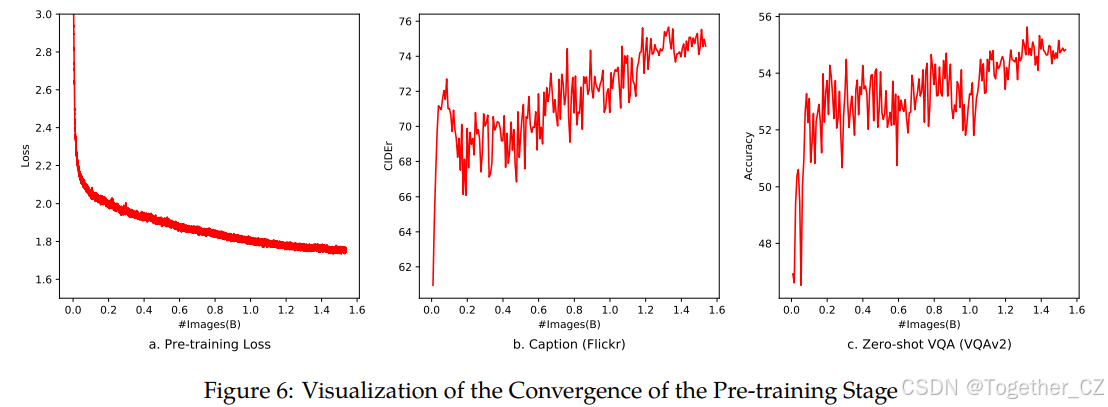
图6:预训练阶段的收敛可视化
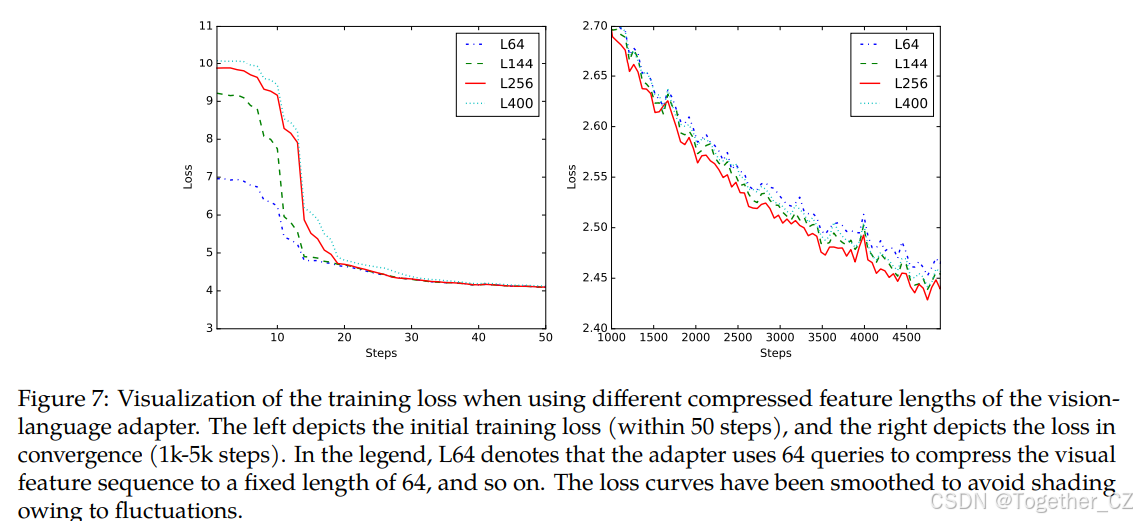
图7:使用不同压缩特征长度的视觉语言适配器的训练损失可视化。左侧描绘了初始训练损失(50步以内),右侧描绘了收敛损失(1k-5k步)。在图例中,L64表示适配器使用64个查询将视觉特征序列压缩到固定长度64,依此类推。损失曲线已平滑处理,以避免因波动引起的阴影。
表10:不同输入图像分辨率下窗口注意力和全局注意力的训练速度
Qwen-VL使用Qwen-7B的中间检查点作为LLM初始化。我们没有使用Qwen-7B的最终发布检查点的原因是Qwen-VL和Qwen-7B是在非常相似的时期开发的。由于Qwen-VL通过Qwen-7B在LLM上有一个良好的初始化,它在纯文本任务上与许多纯文本LLM相当。
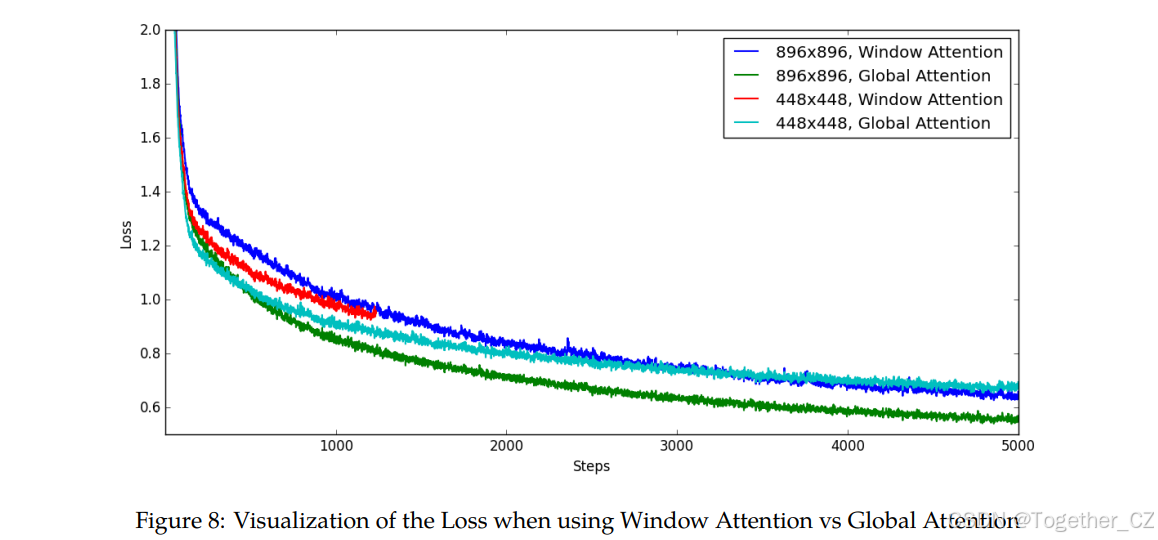
图8:使用窗口注意力和全局注意力时的损失可视化
此外,在多任务训练和SFT阶段,Qwen-VL不仅利用了视觉和语言相关的数据,还加入了纯文本数据进行训练。这样做是为了防止纯文本理解的灾难性遗忘,通过利用纯文本数据的信息。表11中的结果表明,Qwen-VL模型在纯文本能力方面没有表现出任何退化,甚至在多任务训练后展示了改进。
表11:Qwen-VL与开源LLM在纯文本基准测试上的性能比较。由于在多任务训练和SFT阶段引入了纯文本数据,Qwen-VL没有损害任何纯文本能力。



















 3219
3219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











