






周末在看华为昇腾芯片的介绍资料,汇总学习记录如下,感兴趣的话可以参考下:
【华为昇腾的发展情况】
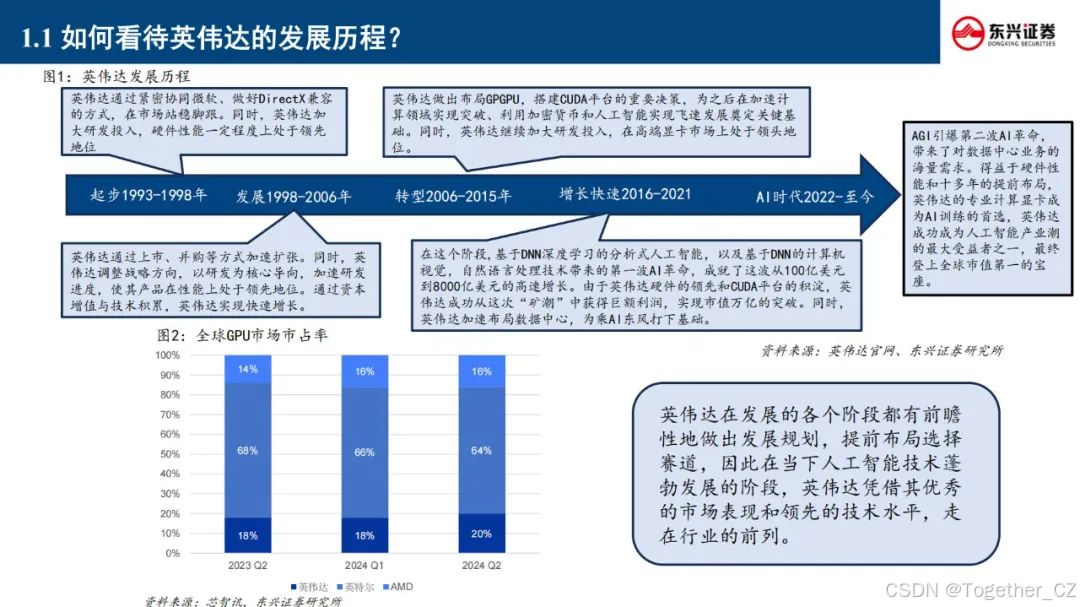
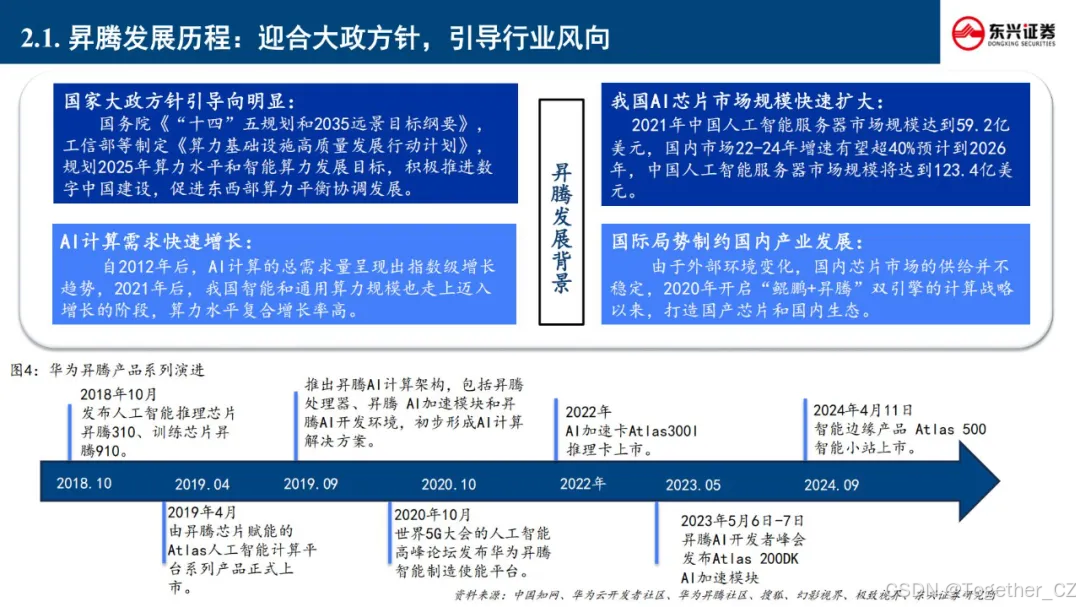
华为昇腾深度融入"新基建"与"东数西算"战略布局,以自主可控为原则推动AI计算国产化进程。2018年发布首代昇腾310边缘AI芯片及全场景AI计算框架MindSpore,标志着我国在AI基础架构领域实现关键突破。
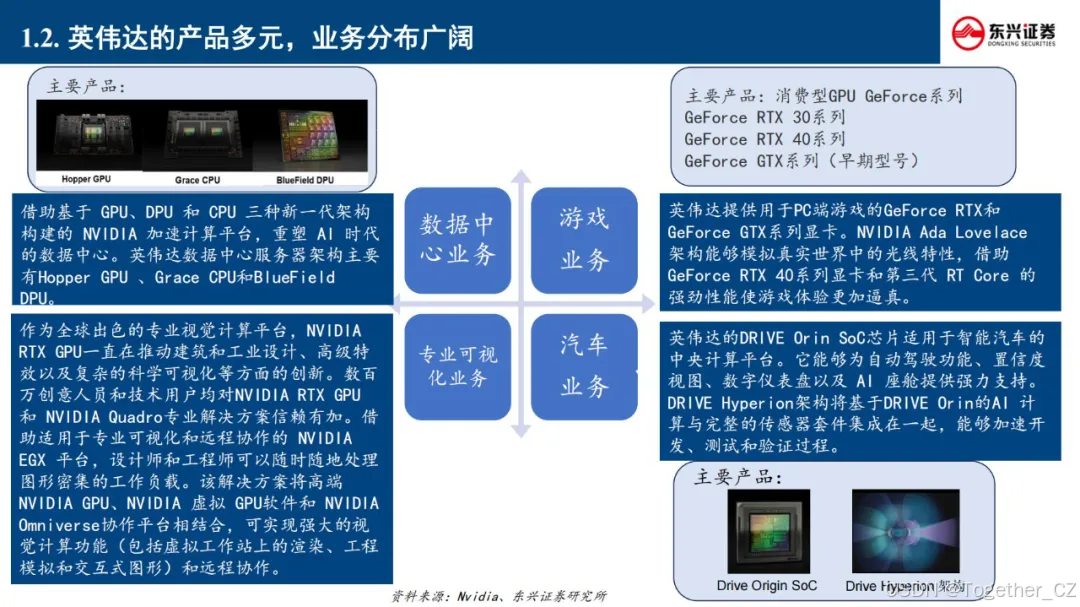
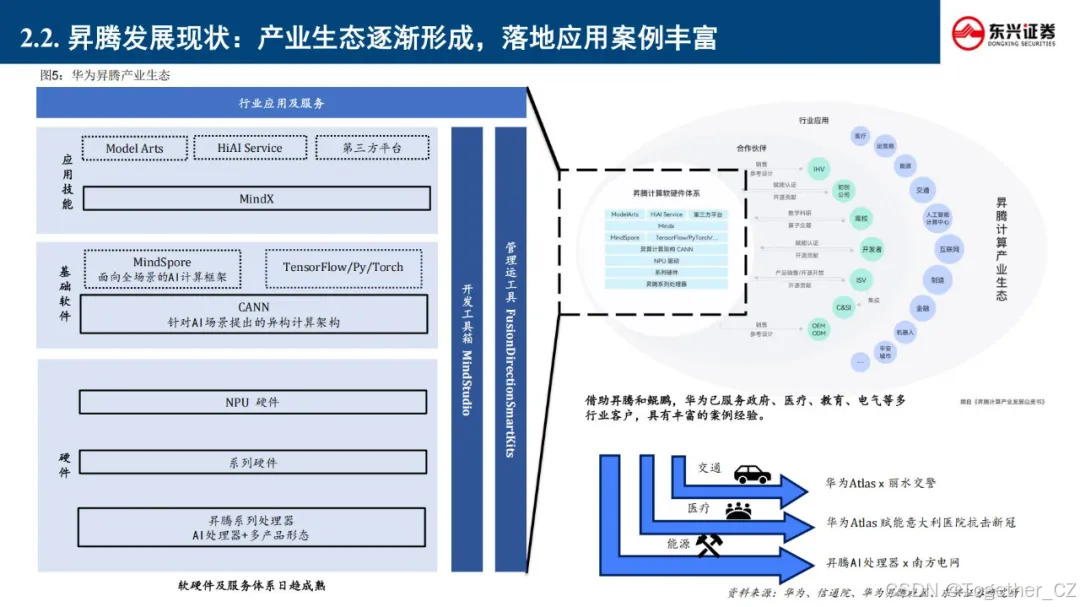
通过持续迭代创新,昇腾系列已形成涵盖昇腾910训练芯片、Atlas计算硬件集群、昇思MindSpore 2.0框架的技术矩阵。其创新的达芬奇架构实现FP16算力密度超越行业平均水平30%,配合异构计算架构CANN 6.0,构建起从模型开发(MindStudio)到部署运维(ModelArts)的全栈式AI解决方案。
【昇腾芯片优势】
昇腾AI处理器作为高度集成的系统级芯片(SoC),专为多模态数据处理优化设计,其创新性达芬奇架构(Da Vinci Architecture)通过三维立方体计算单元实现指令级并行优化。以昇腾310为例,该芯片集成双AI Core计算集群,每个Core内置32个AI计算单元(CUBE Core),支持FP16/INT8混合精度计算,峰值算力达16TOPS@FP16,功耗仅8W,完美适配边缘侧设备的能效要求。
昇腾在 2024 年继续升级产品和生态体系,包括发布 CANN 8.0 和 MindSpore2.4 版本,同时推动全国多个算力中心的适配工作。 2025 年 2 月 1 日,硅基流动与华为云携手宣布联合首发,并正式上线基于华为云昇腾云服务的 DeepSeek R1/V3 推理 服务。






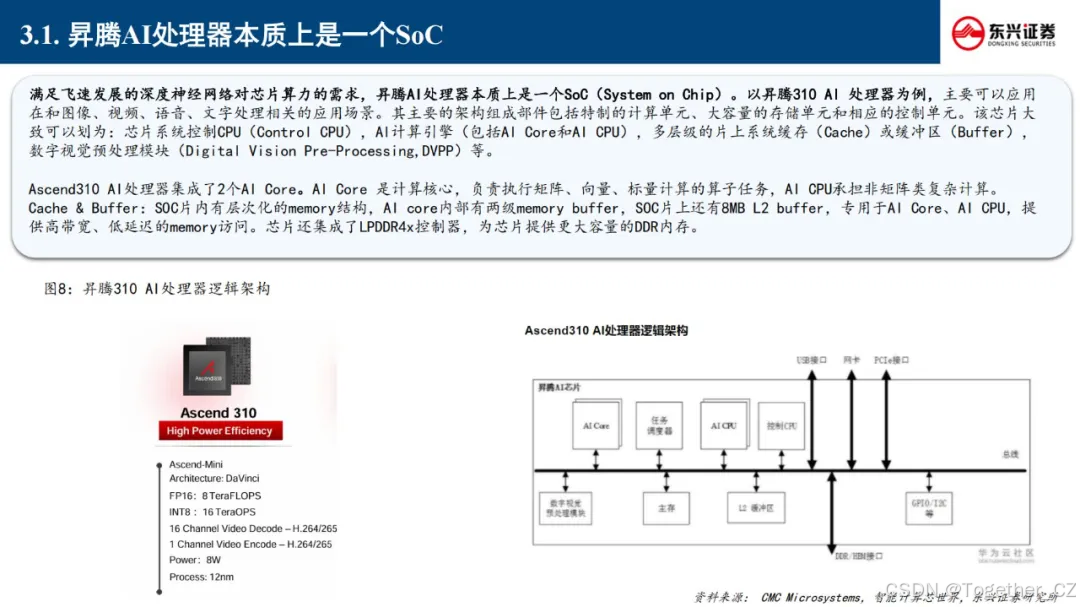
SoC(System on Chip,系统级芯片)是一种高度集成的半导体芯片,它将多个电子系统的功能集成到一个单一的芯片中。以下是关于SoC的详细介绍:
定义
SoC是将整个应用电子系统全部集成在一个芯片中的技术。它不仅包括处理器(如CPU、GPU等),还集成了存储器(如RAM、ROM)、外围设备(如ADC、GPIO、I/O控制器)以及其他子系统(如无线模块、图形处理单元等),所有这些功能都集成在一个单一的硅片上。
特点
-
集成度高:将计算、存储和外围设备集成在单一芯片上,减少了外部组件的数量。
-
高效性:在同一芯片上集成多个系统,SoC可以大幅提升数据传输效率和系统性能。
-
小尺寸、低功耗:集成设计不仅可以减少PCB板的面积,还可以降低功耗,这对便携设备非常关键。
-
定制和适应性:SoC模型可以根据特定需求进行定制,允许设计师选择并整合特定应用所需的部件。
-
低延迟:SoC设计减少了数据传输距离,从而降低了部件之间的延迟并提高了整体系统响应速度。
-
减少互连复杂性:将部件整合到一个芯片上简化了互连结构,减少了设计和管理通信路径的复杂性。
作用
-
数据处理与计算:SoC芯片具有强大的数据处理能力,可以快速处理来自传感器的海量数据,为各种应用提供决策支持。
-
图像和视觉处理:许多SoC芯片包含专门的图形处理单元(GPU),用于处理图像,支持物体识别、车道保持等功能。
-
人工智能与机器学习:SoC芯片通常包含AI处理器或神经网络处理器,用于执行机器学习算法,支持复杂的任务。
-
网络连接与通信:SoC芯片支持多种通信协议,包括Wi-Fi、蓝牙、5G等,确保设备与外部环境的稳定通信。
-
安全与加密:SoC芯片通常包含硬件级别的安全功能,如加密引擎和安全存储,用于保护数据隐私。
应用领域
-
智能手机和平板电脑:SoC提供了强大的计算和图形处理能力,支持高清显示屏和复杂的用户界面。
-
汽车电子:SoC芯片是自动驾驶系统的核心,负责处理传感器数据,进行环境感知和决策制定。
-
物联网设备:SoC的低功耗和高集成度使其成为物联网设备的理想选择。
-
智能家居设备:SoC可以集成多种功能,支持设备的智能化操作。
SoC技术的发展趋势包括多核心处理器、异构计算、更高的集成度,以及对人工智能和机器学习算法的支持。
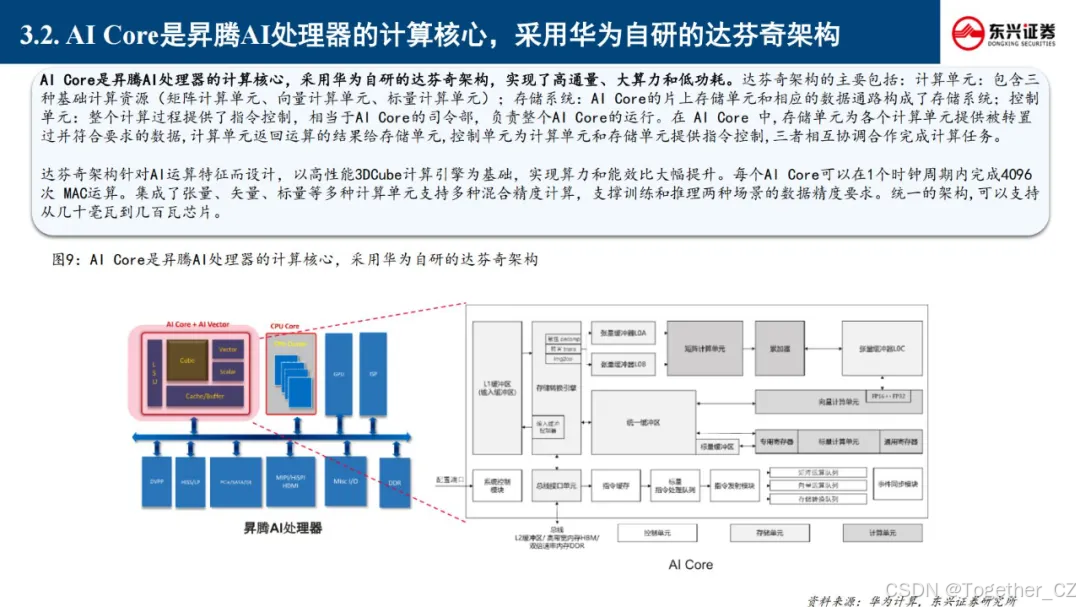
华为昇腾芯片的达芬奇架构
定义与设计理念
达芬奇架构是华为自研的面向AI神经网络卷积计算设计的架构,专门针对深度学习算法中的矩阵运算进行加速。它属于特定域架构(Domain Specific Architecture,DSA),旨在适应特定领域中的常见应用和算法。
架构组成
达芬奇架构的核心是AI Core,其计算能力主要由以下三个单元提供:
-
矩阵计算单元(Cube Unit):这是达芬奇架构的核心计算模块,专为矩阵乘法设计,能够高效处理深度学习中的卷积运算。通过一条指令,矩阵计算单元可以完成两个16×16矩阵的相乘运算,即16³=4096次乘加运算,支持FP16的运算精度。
-
向量计算单元(Vector Unit):用于处理向量相关的计算,支持FP16和FP32的计算精度。
-
标量计算单元(Scalar Unit):负责标量计算,支持多种精度的计算。
此外,达芬奇架构还包括控制单元和存储单元。控制单元负责指挥和协调AI Core的整体运行模式,配置参数和实现功耗控制等。存储单元为各个计算单元提供转置过并符合要求的数据,计算单元返回运算的结果给存储单元。
优势与特点
-
高算力与低功耗:达芬奇架构通过优化矩阵计算单元,实现了高通量、大算力和低功耗。例如,昇腾910的半精度(FP16)算力达到256 TeraFLOPS,整数精度(INT8)算力为512 TeraOPS,而其设计功耗仅为350W。
-
全场景支持:达芬奇架构能够覆盖从几十毫瓦到几百瓦的芯片,支持从低端到高端的全场景应用,包括终端、边缘计算和云计算。
-
统一性与灵活性:达芬奇架构的统一性体现在多个应用场景的良好适配上,一次开发可支持多场景部署、迁移和协同。同时,架构支持多种精度的计算,增加了计算的灵活度。
AI Core
定义与功能
AI Core是昇腾AI处理器的核心计算单元,采用达芬奇架构设计,专门用于执行深度学习算法中的计算密集型任务。它通过特别设计的架构和电路,实现了高通量、大算力和低功耗。
计算能力
AI Core的算力主要由矩阵计算单元、向量计算单元和标量计算单元提供。矩阵计算单元能够高效处理矩阵乘法,向量计算单元适合处理激活函数等特殊计算,标量计算单元则用于标量相关的计算。
应用场景
AI Core广泛应用于昇腾系列芯片中,支持多种计算模式和混合精度计算。昇腾310适用于边缘计算和端侧应用,具有较低的功耗和足够的计算能力;昇腾910则面向云端,为深度学习的训练算法提供强大算力。
通过达芬奇架构和AI Core的设计,华为昇腾芯片在AI计算领域展现了强大的竞争力,为深度学习模型的高效执行提供了有力支持。
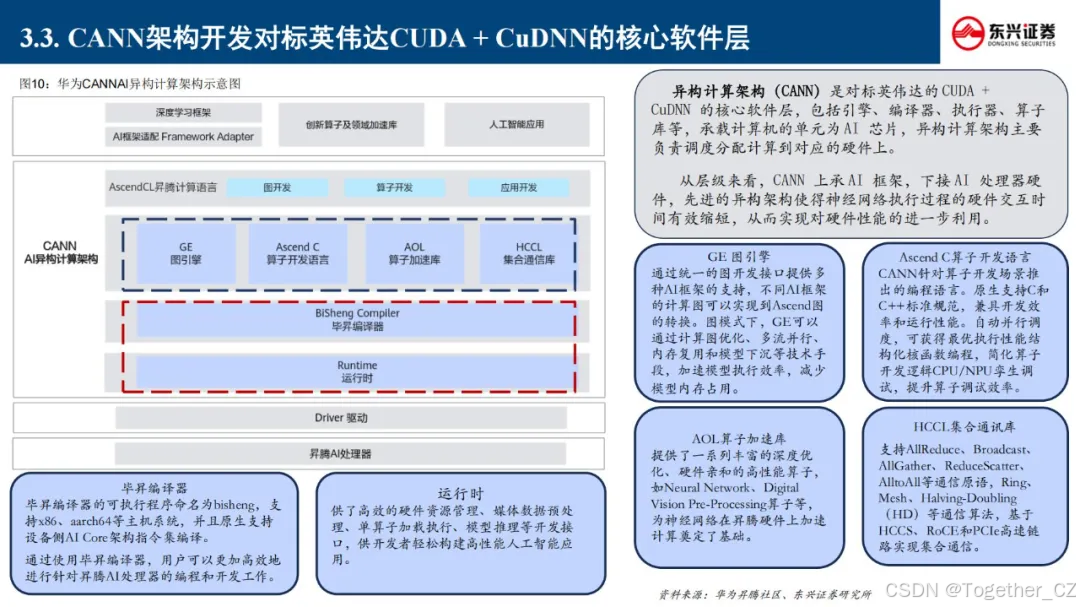
华为CANN介绍
定义与架构
CANN(Compute Architecture for Neural Networks)是华为为昇腾(Ascend)系列AI处理器设计的异构计算架构,旨在加速AI模型的训练和推理。CANN通过提供统一的编程接口和优化的算子库,简化了AI应用的开发和部署。
主要特性
-
统一编程模型:CANN提供了一套统一的API,支持标准编程语言和工具,降低了开发难度。
-
多层次编程接口:包括Ascend Computing Library(ACL)和基础数学库(如BLAS),支持多种计算任务。
-
深度学习框架支持:与TensorFlow、PyTorch、MindSpore等主流框架无缝集成。
-
硬件抽象层:允许开发者无需关注底层硬件细节,便于移植和扩展。
-
优化的算子库:内置大量优化算子,如elementwise和Resize算子,提升计算效率。
-
模型转换与部署:通过ATC工具将模型转换为昇腾处理器可执行格式,并提供监控与管理工具。
英伟达CUDA生态优缺点
优点
-
成熟度高:CUDA自2006年推出以来,经过多年发展,已形成一个庞大且成熟的生态系统。
-
广泛支持:CUDA支持多种编程模型(如CUDA C/C++、cuDNN、cuBLAS等),适用于图形处理、科学计算和深度学习等多个领域。
-
开发者社区庞大:拥有超过400万开发者,丰富的学习资源和社区支持,便于开发者学习和应用。
-
硬件兼容性强:广泛应用于英伟达GPU,且通过ROCm等技术实现了对AMD GPU的部分兼容。
-
性能卓越:在多种计算任务中表现出色,经过长期优化,具有高计算效率和稳定性。
缺点
-
依赖特定硬件:主要针对英伟达GPU,对其他硬件的支持有限。
-
学习曲线陡峭:对于新手来说,CUDA的学习难度较大,需要掌握特定的编程模型和API。
-
闭源限制:CUDA是英伟达的专有技术,其源代码不公开,限制了部分开发者对底层机制的探索。
华为CANN与英伟达CUDA对比分析
| 对比维度 | 华为CANN | 英伟达CUDA |
|---|---|---|
| 目标硬件 | 华为昇腾系列AI处理器 | 英伟达GPU |
| 生态系统 | 正在构建中,包括MindSpore等框架 | 成熟且庞大,涵盖大量开发者和应用 |
| 编程模型 | 提供针对昇腾处理器优化的API | 提供成熟的CUDA C/C++、cuDNN等 |
| 跨平台支持 | 努力实现跨平台支持,但主要优化昇腾硬件 | 通过ROCm实现对AMD GPU的部分支持 |
| 开发者社区 | 正在增长,但规模小于CUDA | 庞大且资源丰富 |
| 性能优化 | 在昇腾处理器上表现出色 | 在多种硬件上表现出色 |
| 适用范围 | 主要针对AI计算 | 适用于图形处理、科学计算和AI |
华为CANN和英伟达CUDA都是高性能计算和AI领域的关键技术。CANN专注于为昇腾AI处理器提供优化支持,具有强大的硬件协同优化能力,但在生态系统和开发者社区方面仍需进一步发展。CUDA则凭借其成熟的技术和广泛的生态系统,在高性能计算和AI领域占据主导地位。随着CANN的持续发展,其在AI领域的影响力有望进一步扩大。
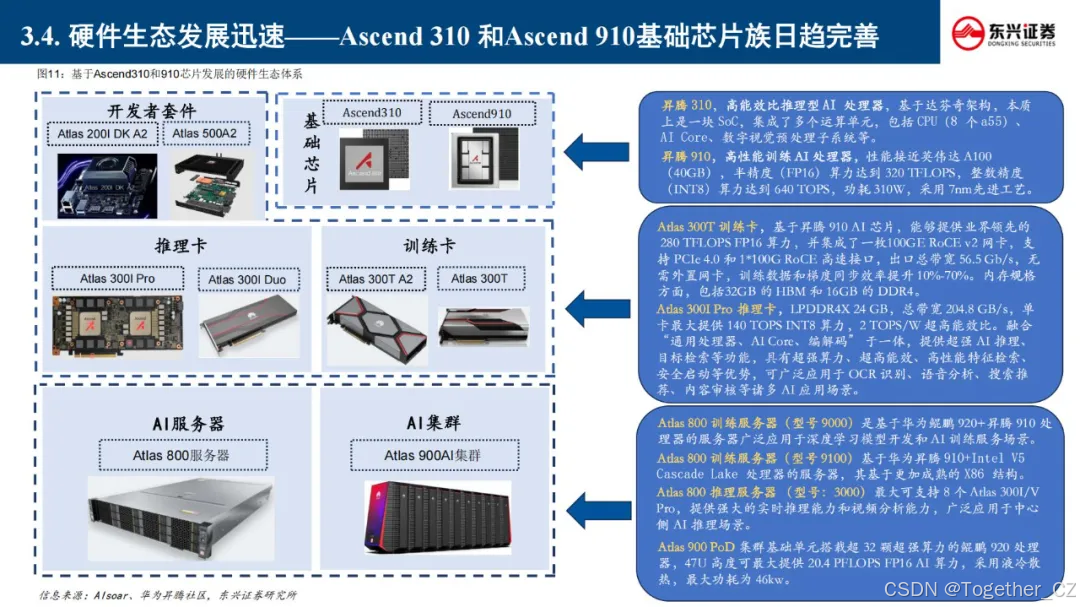
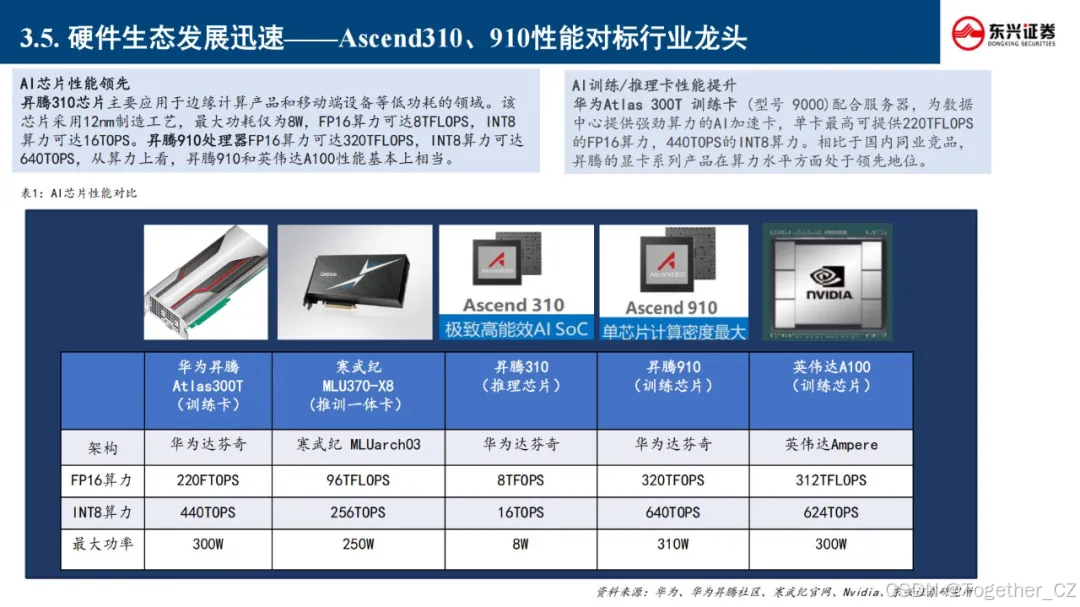

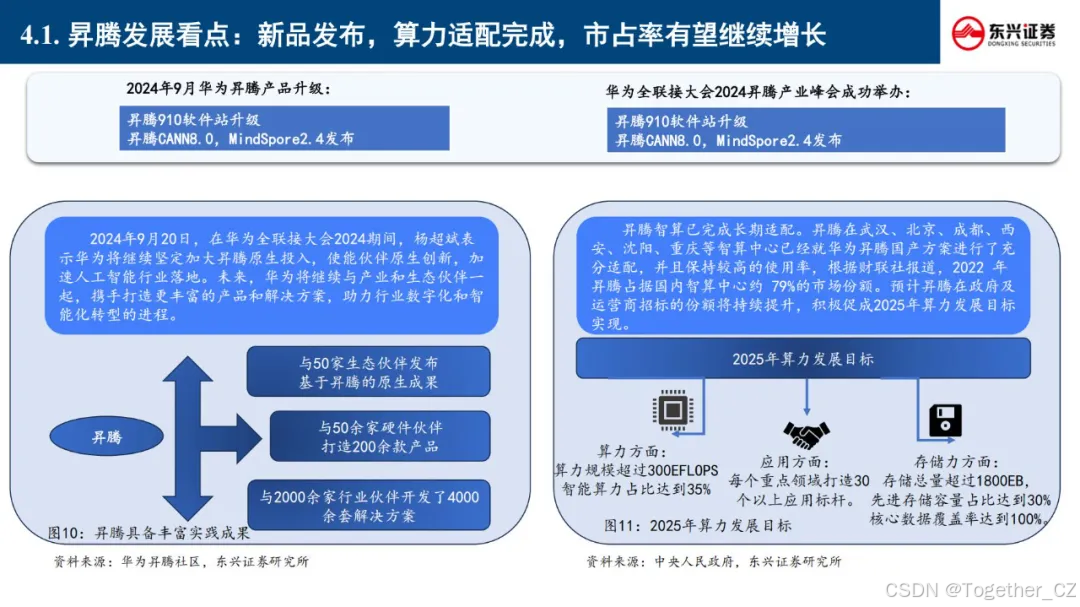


华为的一站式开发平台主要包括 MindStudio、ModelArts 和 MindSpore,它们共同构成了华为在AI开发领域的强大工具链,为开发者提供了从硬件到软件的全栈支持。
1. MindStudio
MindStudio 是华为昇腾社区提供的一款全流程开发工具链,旨在为 AI 应用开发提供全面支持。其主要功能包括:
-
算子开发:提供简化的计算和内存抽象,自动流水同步,以及更简便的调试手段,降低开发者编码成本。
-
推理开发:支持模型分析量化、模型转换、一站式调试和调优,以及应用迁移分析。
-
精度调试:提供数据 dump、溢出检测和精度比对功能,帮助用户快速定位模型精度问题。
-
性能分析:支持全流程调用的性能数据统计,生成流水 trace 图,并提供系统性能数据获取。
-
异常检测:提供内存检测和多核程序下内存问题的精准定位。
-
上板调试:使开发者能准确感知算子代码运行状态,更快发现问题。
MindStudio 通过这些功能,帮助开发者在安装部署、模型训练、模型推理、算子开发、应用开发、调试调优和应用部署全流程中一站式完成,无需切换不同的工具。
2. ModelArts
ModelArts 是华为云推出的一站式 AI 开发平台,专门设计用于简化和加速人工智能模型的开发、部署和管理。其核心优势包括:
-
端到端模型生产线:提供从模型开发、训练到推理的全套工具链,实现 DataOps、MLOps 和 DevOps 的无缝协同,显著提升开发效率。
-
高性价比 AI 算力:支持多规格、多样化的 AI 算力,满足大规模分布式训练和推理加速需求。
-
超大规模支持:能够支持万亿参数级别的模型训练,处理单作业万亿参数和百 PB 级数据的超大规模训练任务。
-
稳定可靠:具备故障容错能力,训练作业故障自动恢复,确保作业失败率低于 0.5%,支持长时间无中断的万亿参数模型训练。
此外,ModelArts 还提供以下功能特点:
-
AI 高效开发:提供监控工具,支持智能运营运维,实现 MLOps 高效迭代 AI 模型,持续提升模型精度。
-
数智融合:数据服务与 AI 开发全流程打通,对接 AI Gallery,便捷使用开源大模型等预置资产。
-
AI 高效运行:提供 AI 加速套件,支持数据、训练和推理加速,以及大规模异构集群的调度管理。
-
AI 高效迁移:提供全流程云化昇腾迁移工具链,支持用户 AI 业务全栈国产化,同时提供迁移专业服务。
3. MindSpore
MindSpore 是华为开源的全场景 AI 深度学习框架,支持云、边、端等全场景的独立以及协同的全栈解决方案。其主要特点包括:
-
开发友好:提供简洁易用的编程接口,降低开发门槛,帮助开发者快速上手。
-
运行高效:通过图算融合、分布式并行等技术,实现高效的模型训练和推理。
-
全场景部署:支持从云到端的灵活部署,满足不同场景下的应用需求。
-
企业级安全可信:提供数据加密、模型保护等功能,确保企业级应用的安全性。
MindSpore 在全球 AI 框架使用率方面处于第一梯队,根据 Omdia 的调研数据,MindSpore 在社区活跃度方面排名第四,在中国开发者心中,MindSpore 在国产框架中认知度排第一,全球框架中认知度排第三。
华为的一站式开发平台通过 MindStudio、ModelArts 和 MindSpore 提供了从硬件到软件的全栈支持,覆盖了从模型开发、训练到部署的全流程。这些工具不仅降低了开发门槛,还提高了开发效率和模型性能,为开发者提供了强大的支持。



















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











