







达芬奇架构是基于AI计算功能设计的,并基于高性能3D Cube计算引擎,极大地提高了计算能力和功耗比。
根据达芬奇架构,进行了以下优化:
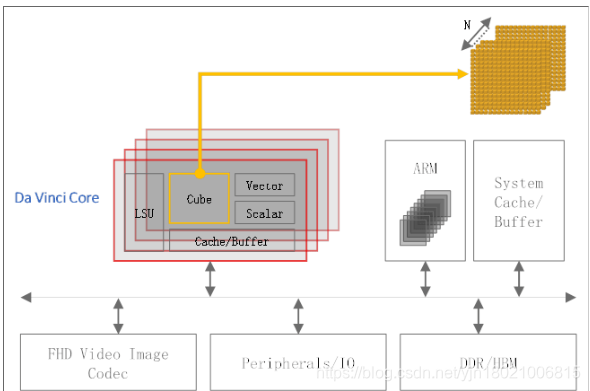
多核堆栈用于并行计算能力扩展
通过设计片上存储器 on-chip memory(高速缓存/缓冲区Cache/Buffer)以缩短Cube操作和存储距离,减少了对DDR的访问,并减轻了冯·诺依曼的瓶颈问题。
在计算和外部存储之间设计了高带宽片外存储器(HBM),以克服计算资源共享存储器的访问速度限制。
为了支持大规模的云侧神经网络训练,设计了超高频段网状网络(LSU),以互连多个多维数据集扩展芯片。
总而言之,达芬奇体系结构具有以下三个features:
**
1. Unified Architecture
支持从tens of milliwatts to hundreds of watts 的全场景AI系列芯片。
2. Scalable Computing
- 每个AI内核可以在一个时钟周期内完成4096个MAC操作。
- 灵活的多核堆栈,可扩展的多维数据集:16 x 16 x N,N = 16/8/4/2/1
- 在训练和推理方案中支持多种混合精度(int8 / int32 / FP16 / FP32)和数据精度要求。
- 集成张量,矢量和标量计算单位。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5537
5537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









