导言
神经网络是深度学习基础,BP算法是神经网络训练中最基础的算法。因此,对神经网络结构和BP算法进行梳理是理解深度学习的有效方法。参考资料UFLDL,BP推导,神经网络教材。
神经网络结构
典型网络为浅层网络,一般2~4层。其结构如下图所示:
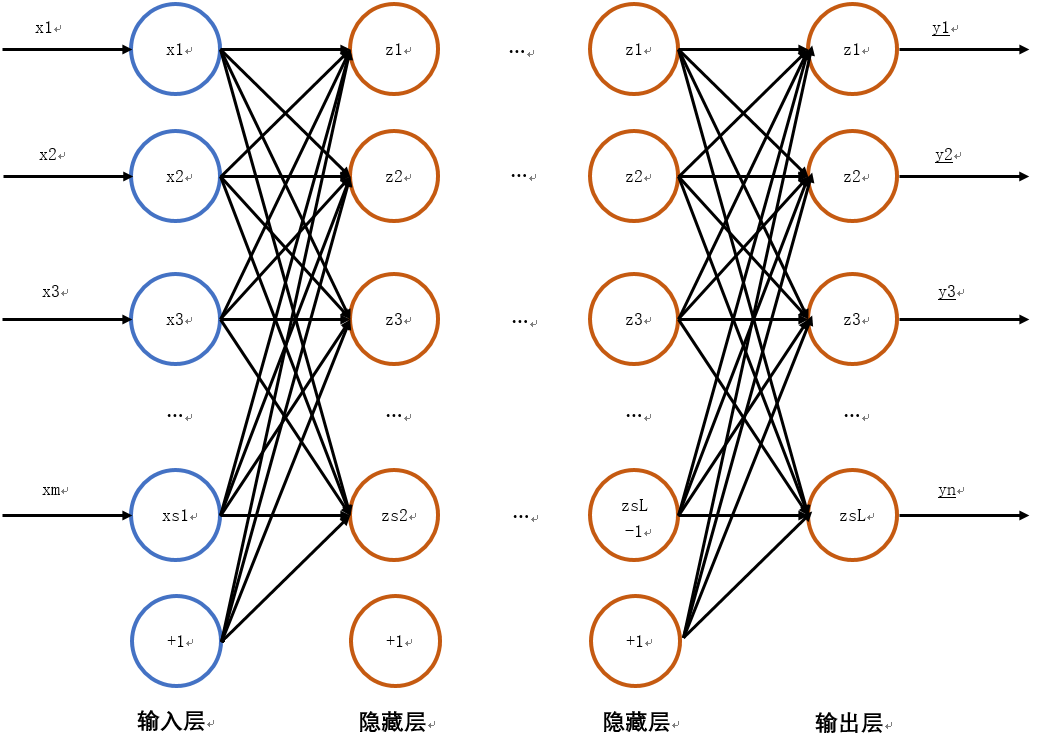
假设神经网络有L层,第
1
层为输入层,最后一层(第L层)为输出层,中间
2,3,……L−1
为隐层。每层有
Sl,l=1,2,......L
个节点,
+1
节点用来表示偏置(bias);
b(l)i
表示第
l
层的+1节点与第
l+1
层的第
i
个节点连接上的权(偏置)。每一层的节点与上一层连接(不一定全连接),连接权重W(l)ij表示层
l
上的节点j同层
l+1
的节点
i
之间的权重。训练集包含K组输入和输出样本,
{(x1→,y1→),(x2→,y2→),…,(xK→,yK→)}
。其中
(xk→,yk→),k=1,2,3,…,K
为向量组:
xk→={x1,x2,…,xi,…,xm}
yk→={y1,y2,…,yj,…,yn}
用
z
表示对上一层输出的权重和汇集结果,由网络结构可以知输入层到第一个隐层:
z(2)1z(2)2z(2)3…z(2)S2=W(1)11∗x1+W(1)12∗x2+⋯+W(1)1m∗xm+b(1)1=W(1)21∗x1+W(1)22∗x2+⋯+W(1)2m∗xm+b(1)2=W(1)31∗x1+W(1)32∗x2+⋯+W(1)3m∗xm+b(1)3=…=W(1)S21∗x1+W(1)S22∗x2+⋯+W(1)S2m∗xm+b(1)S2
在之后各层的算法类似,只是将输入换做层
l
的输出即可。我们用
h表示加权和
z
经过非线性激活函数得到输出
h(l)i=f(z(l)i),f为sigmoid函数或者tanh(双正切)函数。
z(l+1)1z(l+1)2z(l+1)3…z(l+1)Sl+1=W(l)11∗h(l)1+W(l)12∗h(l)2+⋯+W(l)1Sl∗h(l)Sl+b(l)1=W(l)21∗h(l)1+W(l)22∗h(l)2+⋯+W(l)2Sl∗h(l)Sl+b(l)2=W(l)31∗h(l)1+W(l)32∗h(l)2+⋯+W(l)3Sl∗h(l)Sl+b(l)3=…=W(l)Sl+11∗h(l)1+W(l)Sl+12∗h(l)2+⋯+W(l)Sl+1Sl∗h(l)Sl+b(l)Sl+1(1)
我们令
h(1)i=xi,i=1,2,…,S1
;
h(L)i=f(z(L)i)
就可以将所有的层统一成如下形式:
h(l+1)1h(l+1)2h(l+1)3…h(l+1)Sl+1=f(W(l)11∗h(l)1+W(l)12∗h(l)2+⋯+W(l)1Sl∗h(l)Sl+b(l)1)=f(W(l)21∗h(l)1+W(l)22∗h(l)2+⋯+W(l)2Sl∗h(l)Sl+b(l)2)=f(W(l)31∗h(l)1+W(l)32∗h(l)2+⋯+W(l)3Sl∗h(l)Sl+b(l)3)=…=f(W(l)Sl+11∗h(l)1+W(l)Sl+12∗h(l)2+⋯+W(l)Sl+1Sl∗h(l)Sl+b(l)Sl+1)(2)
上述公式中
l=1,2,…,L−1
,每一层的输出值也可以写为向量形式:
h(l)→={h(l)1,h(l)2,…,h(l)Sl}
则公式(2)改写为矩阵向量形式,该公式用于前向传播:
z(l+1)→h(l+1)→=W(l)h(l)→+b(l)→=f(z(l+1)→)
其中,每个节点有如下形式:
z(l+1)ih(l+1)i=∑j=1SlW(l)ijh(l)j+b(l)i=f(z(l+1)i)
神经网络激活函数
激活函数是非线性函数,常用的有两种:sigmoid函数和tanh函数,其导数形式简单。
sigmoid:f(x)tanh:f(x)=11+e−x=1−e−x1+e−x
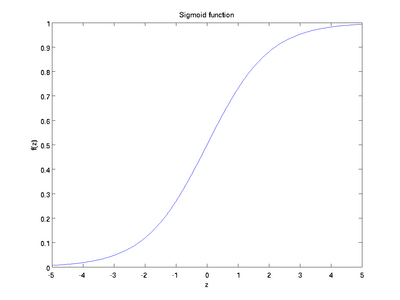
sigmod
函数的图像如下图所示,它的变化范围为(0, 1),其导数为
f'=f(1−f)
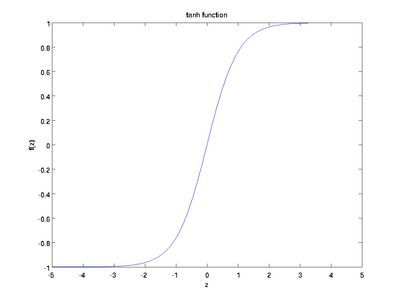
 tanh
tanh
函数的图像如下图所示,它的变化范围为(-1, 1),其导数为
f'=1−f2
BP算法推导
训练的损失函数采用的是均方差最小化为指标,因此其损失函数为:
J(W,d;x,y)=12||hWb(x)−y||2
真正训练时往往采用分批次(in batches)学习(批量随机梯度下降法),假设样本集中每次取
T
个样本进行训练,则整体的损失函数为:
J(W,b)=[1T∑t=1TJ(W,b;xt,yt)]+λ2∑l=1L−1∑j=1Sl∑i=1Sl+1(W(l)ij)2=[1T∑t=1B(12||hWb(xt)−yt||2)]+λ2∑l=1L−1∑j=1Sl∑i=1Sl+1(W(l)ij)2
以上公式中J(W,b)的第一项是均方差项(
T
个样本的均值);第二项是一个规则化项(也叫权重衰减项 weight decay),其目的是减小权重的幅度,防止过度拟合。
梯度更新规则
随机梯度下降法每次迭代将对权重和偏置进行更新,更新规则如下:
W(l)ijb(l)i=W(l)ij−α∂∂W(l)ijJ(W,b)=b(l)i−α∂∂b(l)iJ(W,b)
其中
α
为学习率(learning rate),关键步骤是计算偏导数。我们对
W(l)ij
和
b(l)i
计算偏导数如下:
∂∂W(l)ijJ(W,b)∂∂b(l)iJ(W,b)=⎡⎣1T∑t=1T∂∂W(l)ijJ(W,b;xt,yt)⎤⎦+λW(l)ij=⎡⎣1T∑t=1T∂∂b(l)iJ(W,b;xt,yt)⎤⎦
由上式可知,需要求单个样本的偏导数,带入求批量的偏导,然后使用更新公式进行权重的更新,下面求单个样本的偏导:
样本向量
x(t)→
输入经过前向传播传到输出层,得到输出向量,其每个节点的计算如式(3)所示
h(L)→=hWb→(xt)={h(L)1,h(L)2,…,h(L)SL},其中SL=n
为输出层节点个数
h(L)i=f(z(L)(i))=f(W(L−1)i1∗h(L−1)1+W(L−1)i2∗h(L−1)2+⋯+W(L−1)iSL−1∗h(L−1)SL−1+b(L−1)i)(3)=f⎛⎝∑j=1SL−1WL−1ij∗hL−1j+b(L−1)i⎞⎠
对于输出层
L
,每个节点h(L)i与样本t的标签之第
i
个分量yti进行比较。带入单个样本的损失函数中得:
J(W,d;xt,yt)=12||hWb→(xt)−yt→||2=12∑i=1SL(h(L)i−yti)2=12∑i=1SL(f(z(L)(i))−yti)2=12∑i=1SL⎛⎝f⎛⎝∑j=1SL−1WL−1ij∗hL−1j+b(L−1)i⎞⎠−yti⎞⎠2(4)
- 对网络的输出层
L
,根据链式求导法则,对公式(4)求偏导,得到公式(5)
∂∂W(L−1)ijJ(W,b;xt,yt)=12∗2∗(f(z(L)(i))−yti)∗∂f(z(L)(i))∂W(L−1)ij=(f(z(L)(i))−yti)∗f′(u)|u=z(L)(i)∗∂z(L)(i)∂W(L−1)ij=(f(z(L)(i))−yti)∗f′(u)|u=z(L)(i)∗hL−1j=(h(L)i−yti)∗f′(u)|u=z(L)(i)∗hL−1j(5)
∂∂b(L−1)iJ(W,b;xt,yt)=12∗2∗(f(z(L)(i))−yti)∗∂f(z(L)(i))∂b(L−1)i=(f(z(L)(i))−yti)∗f′(u)|u=z(L)(i)∗∂z(L)(i)∂b(L−1)i=(f(z(L)(i))−yti)∗f′(u)|u=z(L)(i)∗1=(h(L)i−yti)∗f′(u)|u=z(L)(i)(6)
令
δLi=(h(L)i−yti)∗f′(u)|u=z(L)(i)
表示第
L
层中节点
i的残差,则公式(5)(6)可以写做:
∂∂W(L−1)ijJ(W,b;xt,yt)∂∂b(L−1)iJ(W,b;xt,yt)=δLi∗hL−1j=δLi
4. 对于隐藏层
L−1
,根据前向传播法则展开至
W(L−2)ij
同样按链式法则求导,可得式(7),(8)
12||hWb→(xt)−yt→||2=12∑k=1SL(h(L)k−ytk)2=12∑k=1SL(f(z(L)(k))−ytk)2=12∑k=1SL⎛⎝f⎛⎝∑i=1SL−1W(L−1)ki∗h(L−1)i+b(L−1)k⎞⎠−ytk⎞⎠2=12∑k=1SL⎛⎝f⎛⎝∑i=1SL−1W(L−1)ki∗f(z(L−1)i)+b(L−1)k⎞⎠−ytk⎞⎠2=12∑k=1SL⎛⎝f⎛⎝∑i=1SL−1W(L−1)ki∗f⎛⎝∑j=1SL−2W(L−2)ij∗h(L−2)j+b(L−2)i⎞⎠+b(L−1)k⎞⎠−ytk⎞⎠2
∂J(W,b;xt,yt)∂W(L−2)ij=∂∂W(L−2)ij(12||hWb→(xt)−yt→||2)=∂∂W(L−2)ij⎛⎝12∑k=1SL(h(L)k−ytk)2⎞⎠=∂∂W(L−2)ij⎛⎝12∑k=1SL(f(z(L)(k))−ytk)2⎞⎠=∑k=1SL(h(L)k−ytk)∗f′(u)|u=z(L)(k)∗∂(z(L)(k))∂W(L−2)ij=∑k=1SLδLk∗∂∂W(L−2)ij⎛⎝∑i=1SL−1W(L−1)ki∗h(L−1)i+b(L−1)k⎞⎠(7)=∑k=1SLδLk∗W(L−1)ki∗∂(h(L−1)i)∂W(L−2)ij=∑k=1SLδLk∗W(L−1)ki∗∂∂W(L−2)ijf(z(L−1)i)=∑k=1SLδLk∗W(L−1)ki∗∂∂W(L−2)ijf⎛⎝∑j=1SL−2W(L−2)ij∗h(L−2)j+b(L−2)i⎞⎠=∑k=1SLδLk∗W(L−1)ki∗f′(v)|v=z(L−1)i∗h(L−2)j
∂J(W,b;xt,yt)∂b(L−2)i=∂∂b(L−2)i(12||hWb→(xt)−yt→||2)=∂∂b(L−2)i⎛⎝12∑k=1SL(h(L)k−ytk)2⎞⎠=∂∂b(L−2)i⎛⎝12∑k=1SL(f(z(L)(k))−ytk)2⎞⎠=∑k=1SL(h(L)k−ytk)∗f′(u)|u=z(L)(k)∗∂(z(L)(k))∂b(L−2)i=∑k=1SLδLk∗∂∂b(L−2)i⎛⎝∑i=1SL−1W(L−1)ki∗h(L−1)i+b(L−1)k⎞⎠=∑k=1SLδLk∗W(L−1)ki∗∂(h(L−1)i)∂b(L−2)i=∑k=1SLδLk∗W(L−1)ki∗∂∂b(L−2)if(z(L−1)i)=∑k=1SLδLk∗W(L−1)ki∗∂∂b(L−2)if⎛⎝∑j=1SL−2W(L−2)ij∗h(L−2)j+b(L−2)i⎞⎠=∑k=1SLδLk∗W(L−1)ki∗f′(v)|v=z(L−1)i∗1(8)
令:
δ(L−1)i=∑k=1SLδLk∗W(L−1)ki∗f′(v)|v=z(l)i
可以看出残差
δ(L−1)i
相当于残差
δLk
反向传播一层后乘以非线性激活函数在
L−1
层该节点的导数值,故(7)(8)式可改写为:
∂J(W,b;xt,yt)∂W(L−2)ij∂J(W,b;xt,yt)∂b(L−2)i=δ(L−1)i∗h(L−2)j=δ(L−1)i
- 同理可得其他隐层的递推公式,对任意隐层
l=1,2,3,…,L−1
,单样本损失函数对权重和偏置的偏导的计算公式如(9),其中残差从输出层反向传播到层
l
:
∂J(W,b;xt,yt)∂W(l)ij∂J(W,b;xt,yt)∂b(l)i=δ(l+1)i∗h(l)j=δ(l+1)i(9)
其中:
δ(l)i=∑k=1Sl+1δl+1k∗W(l)ki∗f′(v)|v=z(l)i
BP算法的批量更新步骤如下:
- 对所有的层
1≤l≤L−1
,
∇W(l)
与
∇b(l)
初始化为0,用以记录批量累计误差;
- for t = 1: T
每个样本正向计算各层输出
使用反向传播算法,计算各层神经元权值和偏置的梯度矩阵
∇W(l)(t)
与
∇b(l)(t)
累积误差:
∇W(l)∇b(l)+=∇W(l)(t)+=∇b(l)(t)
end for - 更新权重与偏置
W(l)b(l)=W(l)+1T∇W(l)+λW(l)=b(l)+1T∇b(l)


























 2332
2332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









