







 本文介绍了scikit-learn,一个强大的Python机器学习库,涵盖了丰富的算法、数据预处理、模型评估和调优等内容。文章指导读者如何根据问题特性选择合适的算法,并通过PCA降维示例展示了其使用方法。
本文介绍了scikit-learn,一个强大的Python机器学习库,涵盖了丰富的算法、数据预处理、模型评估和调优等内容。文章指导读者如何根据问题特性选择合适的算法,并通过PCA降维示例展示了其使用方法。
scikit-learn官方文档:文档
本博客源码:gitlab
一站式AI框架——scikit-learn
scikit-learn是一个用于机器学习的Python库,提供了丰富的工具和算法,用于数据预处理、特征选择、模型建立、模型评估和模型部署等机器学习任务。它是开源的,易于使用且广泛应用于学术界和工业界。
- 下面是scikit-learn的一些主要特点和功能:

-
丰富的机器学习算法: scikit-learn提供了多种经典的监督学习和无监督学习算法,包括线性回归、逻辑回归、决策树、支持向量机、随机森林、聚类、降维等。这些算法都具有高效的实现和良好的性能。
-
一致的API: scikit-learn的API设计简单一致,易于使用和学习。它提供了一致的估计器(Estimator)接口,包括fit()用于训练模型,predict()用于进行预测,以及score()用于评估模型性能等方法。
-
数据预处理: scikit-learn提供了各种数据预处理工具,用于数据清洗、特征缩放、特征提取和特征选择等。例如,可以使用StandardScaler对特征进行标准化,使用MinMaxScaler进行特征缩放,使用PCA进行主成分分析等。
-
特征选择: scikit-learn包含了多种特征选择方法,可以帮助从原始数据中选择最具信息量的特征子集。这些方法包括基于统计测试的方法、基于模型的方法和基于迭代的方法等。
-
模型评估: scikit-learn提供了多种模型评估方法,可以帮助评估模型的性能和泛化能力。例如,可以使用交叉验证方法进行模型评估,使用不同的评估指标如准确率、精确率、召回率和F1值等进行模型性能评估。
-
模型选择和调优: scikit-learn提供了模型选择和调优的工具,包括网格搜索(GridSearchCV)和随机搜索(RandomizedSearchCV)等。这些工具可以帮助自动化地选择最佳模型参数组合,以提高模型性能。
-
整合其他库: scikit-learn可以与其他Python库进行无缝整合,例如NumPy和Pandas,方便进行数据处理和分析。
scikit-learn是一个功能强大、易于使用的机器学习库,提供了丰富的工具和算法,可以帮助开发者快速构建和部署机器学习模型。无论是在学术研究还是实际应用中,scikit-learn都是一个非常有价值的工具。
scikit-learn支持丰富的AI算法

如何选择一个合适的算法?
根据问题类型、数据集大小、数据特征、数据标记、模型解释性和性能评估等因素,选择适合的scikit-learn算法。
面对如此多的可用的机器学习算法,如何针对具体的问题选择合适的算法是非常重要的,下面提供了选择算法的思路:

使用示例
在使用前,请确保框架已经安装好了
# 安装
pip install scikit-learn
# 可视化工具也安装一下
pip install matplotlib
- 示例:以下是使用scikit-learn进行降维的一个完整的代码示例,使用的降维方法是主成分分析(PCA)
-
在这个示例中,首先使用load_iris函数加载了鸢尾花数据集。然后,我们将数据集中的特征存储在X中,将目标变量存储在y中。
-
接下来,我们创建了一个PCA对象,并通过设置n_components参数为2,指定降维后的维度为2。
-
然后,我们使用fit_transform方法在训练数据上进行PCA降维,将原始数据X转换为降维后的数据X_reduced。
-
最后,我们使用散点图将降维后的数据可视化,其中x轴表示第一主成分(PC1),y轴表示第二主成分(PC2)。不同类别的样本使用不同的颜色进行标记。
-
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建PCA对象,并指定降维后的维度
pca = PCA(n_components=2)
# 在训练数据上进行PCA降维
X_reduced = pca.fit_transform(X)
# 可视化降维后的数据
plt.scatter(X_reduced[:, 0], X_reduced[:, 1], c=y, cmap='viridis')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.title('PCA on Iris dataset')
plt.show()
- 运行结果:
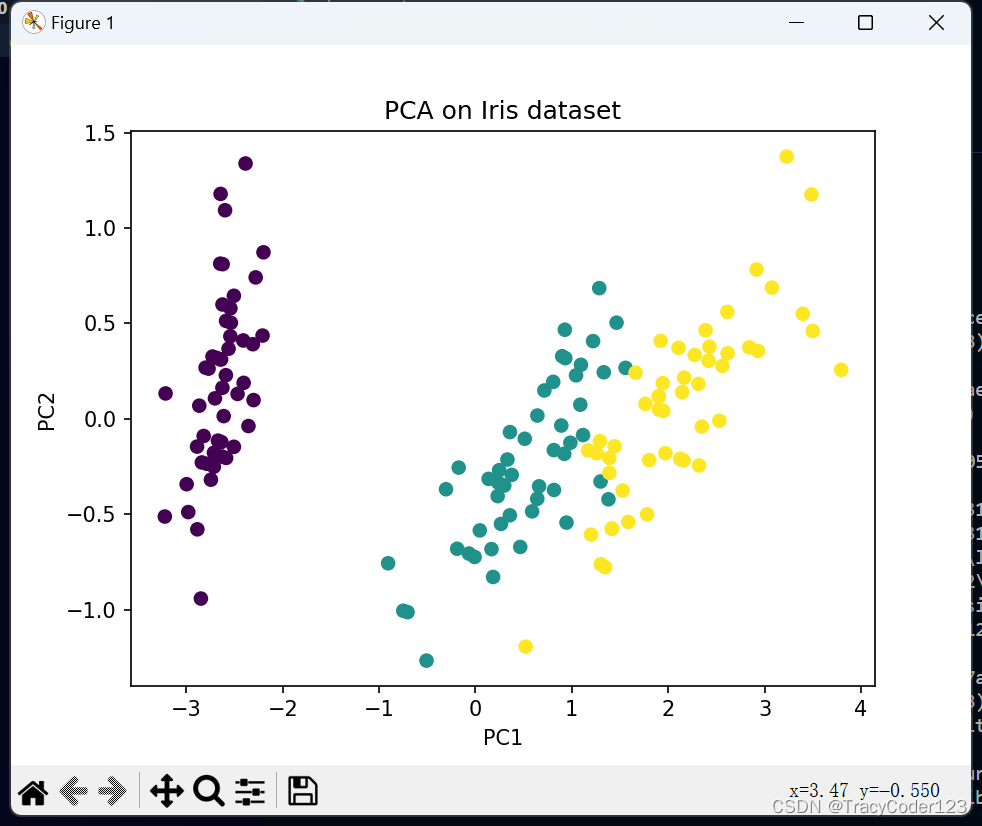
是不是非常简单?



















 938
938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











