







文章目录
xNIDS-解释基于深度学习的网络入侵检测系统实现自动入侵响应
Abs
摘要总结:
介绍了xNIDS,是对DL-NIDS进行解释的新框架。
解释方法归纳两点:①对历史输入的近似和采样②捕捉结构化数据的特征依赖关系,以实现高保真度的解释。xNIDS也能基于解释的结果更好的生成抵御措施。并且在保真度、稀疏度、完整性和稳定性方面都优于之前的解释方法。证实了了XNIDS可以有效地生成实用的防御规则,帮助理解DL-NIDS行为,以及排除检测错误。
背景:
基于深度学习的网络入侵检测系统 DL-NIDS 展现出强大的性能并被广泛探索,但存在难以解释等一系列问题导致其无法主动响应入侵、网络运营商无法有效利用检测结果。
现有的方法在处理历史数据和对结构化数据中的特征依赖捕捉方面仍有不足,在解释DL-NIDS时表现不佳。因此提出xNIDS对上述不足进行优化,能高效的生成防御规则、辅助理解DL-NIDS的行为以及排除检测错误。
Intro
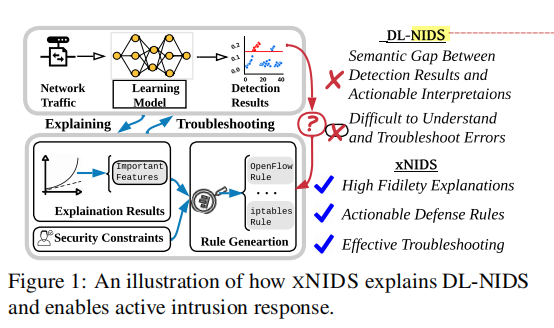
DL-NIDS的缺陷:
- 检测结果和可操作的解释之间的语义差异
- 人类难以理解并用于纠错
提出xNIDS:
- xNIDS:一种新的解释方法来专门解释DL-NIDS。通过对历史输入进行逼近和采样,并利用稀疏群套索捕获特征依赖性,我们的解释方法为DL-NIDS生成了高保真、稀疏、完整、稳定的解释结果
- 我们提出了一种防御规则生成方法来启用主动入侵响应。引入防御规则范围和安全约束,使规则准确,设计统一的规则表示,使防御规则适用于异构防御工具。
- 我们评估了我们的框架,XNIDS ,使用四种最先进的DL-NIDS,演示了其解释方法的有效性,并展示了它如何帮助理解DL-NIDS行为,排除检测错误,并启用主动响应。
Motivation and Challenges
首先介绍①为什么DL-NIDS的解释和主动响应是极其重要的。分析方面即从上图中DL-NIDS的缺陷中开始分析。
- 语义差距
语义差距总结:即DL-NIDS在检测结果和可操作的解释之间存在差异,使得即使检测出结果,也都是一些数字或标签,无法进行主动响应,管理员也无法发现其背后的原因进行处理。
- 故障排除错误
解释DL-NIDS检测的结果可以帮助排除分类错误。DL-NIDS的错误分类代价极高并且随着模型的加深会使得人类更加难以理解。解释结果减少故障排除的人力工作。
- 主动响应
主动入侵响应有助于迅速阻止或分流恶意流量。
DL-NIDS检测到广泛的攻击,需要网络运营商进行耗时的人工分析。在延迟的分析中入侵者可能已经侵入。基于DL-NIDS的检测结果和相应的解释,必须实现主动入侵响应。
②现存的方法不足以解释DL-NIDS
大部分现有的解释模型能很好的解释CNN、MLP、但是不能很好的解释RNN,都假设特征是独立的。LEMNA设计解释安全应用【机翻,个人理解是LEMNA假定临近的特征有相似的分布】,但它的假设并不是始终维持。
现有方法无法很好解释DL-NIDS的关键在于:历史输入和特征之间的依赖

③解释DL-NIDS的挑战
- Ch1 如何考虑历史输入
现有的方法选择将具有突出贡献的特征用来解释检测结果
考虑历史输入来解释DL-NIDS的问题包含两个小点:
①Ch1:如果只考虑固定数量的历史输入,它很可能会得到退化的解释,因为不同的攻击可能依赖于不同数量的输入(例如,DDoS,OSscan),而考虑所有的历史输入也是不可行的。
②:当前输入的影响应该大于历史影响
- Ch2 如何捕获结构化数据中的复杂特征依赖关系
IG、LRP、LIME等方法认为假定输入特征之间是独立的。
SHAP认为特征组中的特征是相同权重的
LEMNA假定相邻的特征对于检测结果有相似的分布。
DL-NIDS的输入极具结构化
④生成防御规则的挑战
响应策略:需要设计合适的防御规则策略来主动响应入侵,并且Ch3 使之平衡精度和泛化,且Ch4 响应的结果可以适用于不同的防御工具。
总结:重点包括:解释方法和响应策略
Explaining Detection Results of DL-NIDS
首先介绍解释方法的目标
通过:
(1)近似历史输入来处理Ch1和Ch2;
(2)通过加权随机抽样(WRS)综合历史输入的实例;
(3)将每个输入内的特征划分为组的相关性;
(4)在组水平和特征水平上以稀疏的方式选择重要的特征。
最后,我们将上述讨论的技术集成到一个适当的解释模型中,通过近似于DL-NIDS的检测结果来得到解释结果。
目标
给定一个输入xt,我们的解释方法需要找到适当的历史输入X’t,m和一个高保真、稀疏、完整、稳定的解释结果e。
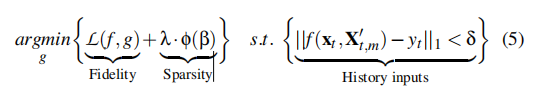
近似历史输入
DL-NIDS通常采用滑动窗口或RNN来捕获良性和异常流量的聚合信息
仅从当前输入或固定数量的历史输入中得到解释结果的是不够的,导致了低保真度的解释。并且考虑所有的历史输入是不够的。
使用两步来有效地找到少量的输入来近似相关的历史输入
第一步
if ||f(xt,Xt,l) - f(xt,Xt,k)|| < δ:
l = l / 2 #向下取整
else:
l = l * 2
此过程的两个终止要求:
偏差δ【认为是原始的检测分数】,决定了近似的精度;以及更新l的最大次数的次数(U)任何一个达到就停止重复执行
第二步
确定了l个历史输入后,通过删除一些历史记录输入,并检查检测结果是否仍然满足δ的要求选择最相关的历史记录。直观地说,在l范围内的一些历史输入可能是不相关的
我们将这一步的输出表示为X’t,m,它是Xt,l的mxd的子矩阵,’ 表示所选择的历史输入在原始时间序列中不一定是连续的。
为了删除不相关的历史记录,引入两个过滤器
- 主机过滤器:删除同一个主机的输入
- 协议过滤器:删除同一个协议的输入
我们首先将主机过滤器逐个应用于l内的主机,然后我们将协议过滤器应用于l内的协议。如果主机或协议信息不可用,则我们跳过步骤2。
围绕历史记录输入进行采样
旧的输入的影响应该减少,否则DL-NIDS可能会出现梯度爆炸和收敛不足的情况
基于LSTM系统使用遗忘门来丢弃长时间的依赖,减少老输入数据的影响。基于这种直觉,我们在历史输入附近不均匀地采样
- 我们首先为最新的历史输入分配更大的权重,以证明它们对检测结果的更显著的影响;
- 我们将合成的样本转移到WRS【 Weighted Random Sampling加权随机采样】的最新历史输入中。
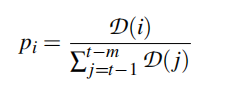
每个项被选择的概率就等于其权值的占比。D:衰减函数【decay function】,根据每个历史输入的到达顺序为该输入分配权重。典型的衰减函数包括指数、高斯和线性。最近到来的输入具有最高的权重
此外:如果历史输入和当前输入对检测结果有类似的影响,我们可以为历史输入分配恒定的权值。因此,WRS将被简化为随机抽样。
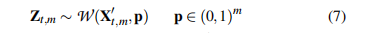
Zt,m是从删除后的X’矩阵经过WRS加权随机采样后得到合成的样本
捕捉特征之间的依赖关系
DL-NIDS通常应用基于相关性的方法(如聚类)或领域知识来处理结构化数据的特征依赖性,以获得更好的检测性能。
为了获取结构化数据内部特征的依赖关系:
① 首先根据特征的相关性将特征分成几组
② 我们对特征群应用一个稀疏群套索来实现稀疏解释。【a sparse group
lasso 】
Feature Groups.:DL-NIDS使用的数据的格式:结构化且有严格的格式,
例如Kitsune使用来自IP头的数十个特性作为输入;
其中,TCP.srcport是TCP的一个子特性,这意味着如果TCP.srcport特性是有效的,那么TCP特性也应该是有效的。
同时,UDP是TCP的一个互斥特性,这意味着如果UDP特性是有效的,那么TCP特性就应该是无效的。

1Aq:xt是一个指示函数,用来指示xt中的特征是否属于组别xq t
需要M个指示函数来将xt分成M个组别,并且每个特征只能属于一个组
为了确定指示函数,我们考虑了三种情况:
① 目标DL-NIDS所使用的分组策略是可用的,这通常是由领域知识决定的。我们在xNIDS中使用相同的策略
② 包含相关历史样本的数据集是可用的,但目标DL-NIDS使用的分组策略尚不清楚。然后用聚类方法计算特征之间的相关性,创建指示函数。
③ 分组策略和数据集不可用,XNIDS被迫将每个组的大小设置为1。因此,稀疏群套索将被简化为套索。【这部分知识不太了解】
我们将xt和X’t的组总数,m表示为Q = M×(1+m)。
每一个历史记录分为M类?X’t,m中有m个历史记录,xt算一个,一共Mx(m + 1)类
Sparse Group Lasso.
为了得到稀疏的解释,需要最小化φ(e),也就是从输入中选择最相关的特征作为解释结果,而省略那些对检测结果没有显著影响的特征。
稀疏组套索是一种回归方法,允许预定义的特征组一起选择或退出模型,其中特定组的所有特征要么包括要么被排除。
它具有群体级和特征级稀疏性的期望效果
因此为满足稀疏性要求,xNIDS使用Sparse Group Lasso来解释DL-NIDS
稀疏组套索允许我们在预测相应的检测结果时找到重要的解释因子,其中每个解释因子可能由输入中的一组特征组成。
同时,稀疏群套索帮助我们在组级和特征水平上实现稀疏效果。我们对回归问题的建模如下
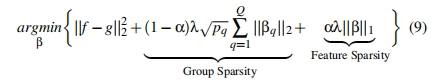
其中βq是一个向量,包含第q组特征的系数;pq是第q组的大小;β=(β1……βQ);和α∈[0,1]是套索和组套索惩罚的凸组合。为了实现组级的稀疏性,我们最小化∑||βq||2,即通过使||βq||2 = 0来排除更多的组。为了实现特性级的稀疏性,我们最小化了||β||1,并通过制作||βi ||1 = 0来排除更多的特性
模型开发
结合上述方法:
- 使用近似历史输入中的方式,来逼近合适的历史输入。
- 结合衰减函数和随机权重抽样,调整历史输入的抽样策略。
- 使用线性分量近似于DL-NIDS的局部决策边界。
具体来说,这里的关键思想是利用一个局部线性模型来近似yt = f(xt ,Xt,k)周围的单个决策边界。近似过程描述如下:
其中f(·)为非线性DL-NIDS,g(·)为局部近似方法,ε为近似与真实检测结果之间的一个小偏差。在特征组的指导下,我们将g(·)转换为以下方程:
其中,第一个组件用于当前输入,而第二个组件用于历史输入。x q i是输入xi的第q个组,βi,q包含x q i的相应系数。M是一个输入中的特征组的数量。M是历史输入的数量。最后,通过取Equ(10)作为种子输入,根据我们的Equ(9)不均匀样品策略创建n个合成样品。,我们将我们的解释模型形式化为以下回归问题:
其中,zt和Zt,m分别为当前输入xt和历史输入X‘t,m的合成样本。y是一个向量,包含n个检测结果。β T q包含第q组特征的系数。Q是各组的总数。pq是第q组的大小,λ是一个调优参数。α∈[0,1]是套索[76]和群套索的凸面组合[8]
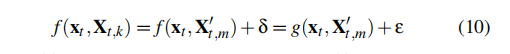
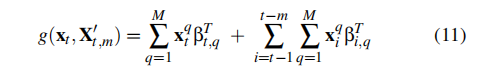
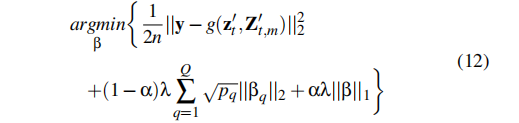
Generating Defense Rules
在提取了DL-NIDS用于做出特定决策的重要特征后,XNIDS基于这些特征生成防御规则。图中显示了XNIDS如何生成防御规则的详细示例

举一个例子说明了XNIDS如何生成防御规则。关键思想是
①通过分析解释结果来确定防御规则的范围,
②修改拦截策略的操作,
③通过具有重要特征值的相应实体来生成统一的防御规则。
最后,XNIDS自动将统一防御规则转换为可操作的防御规则(例如,OpenFlow规则和等规则)。
xNIDS解决ch3:
- (一)界定防御规则范围,限定适用规则的范围;
- (二)分析解释,确定规则范围;
- (三)考虑通过安全约束,提高防御规则的适应性。
XNIDS还通过定义统一的防御规则表示来抽象不同的防御工具中的规则操作来解决Ch4。
防御规则范围Defense Rule Scope
为了平衡精度和泛化【ch3提出的问题】,我们引入了防御规则的范围来限制一个规则应该适用的地方。
精度度量要求防御规则只影响恶意流量,而保持良性流量的完整
泛化度量要求防御规则应该提醒攻击中涉及的所有恶意流量
Defining Rule Scopes.
定义为三种层次
- Per-flow Scope
只能影响从特定的流中产生的网络数据包。例如,用于终止TCP连接的防御规则被认为是per-flow防御规则
- Per-host Scope
每个主机的防御规则可以阻止来自同一主机的多个流。例如,用于阻止机器人的防御规则被认为是每个主机的防御规则
- Multi-hosts Scope
多主机防御规则可以阻止来自多个主机的多个流。例如,一个用于阻止来自一组主机(例如,僵尸网络)的SYN请求的防御规则被认为是一个多主机防御规则
Analyzing Explanation Results.
我们通过分析相应的解释来确定一个防御规则的适当范围。如表2所示,我们将统计信息定义为S,它包含五个字段: IP_pool、IP_n、MAC_n、Port_n和Protocol_n。统计信息对于生成实际的防御规则至关重要。如果它不可用,XNIDS就不会生成防御规则。
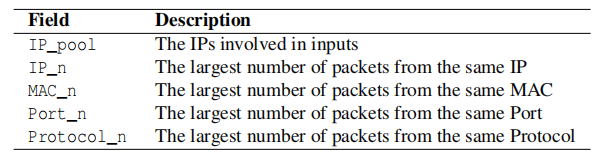
| Field | Description |
|---|---|
| IP_pool | 输入中包含IPs |
| IP_n | 从同一个IP收到的最大的分组数量 |
| MAC_n | 从同一个MAC地址收到的最大的分组数量 |
| Port_n | 从同一个端口收到的最大分组数量 |
| Protocol_n | 从同一个协议收到的最大分组数量 |
我们通过检查统计信息(S)中哪个字段的值最大,来确定每个主机和多主机的作用域。例如,如果Protocol_n或Port_n的值最大,则表示异常流量属于同一个协议但不是同一个主机。换句话说,多个主机可能参与了这次攻击。因此属于multi-hosts scope 范围
否则,如果异常流量来自同一主机,则相应的防御规则应该具有per-host 或per-flow的范围
在这种情况下,如果重要特性包含多个协议或端口,这意味着主机使用multiple protocols 启动攻击,防御规则具有per-host的作用域,或者防御规则具有per-flow范围
安全性约束 Security Constraint
网络环境往往因站点而异,网络运营商往往对其网络环境有模糊的安全要求。根据安全约束条件动态调整防御规则是很重要的。
为了使得防御规则适应不同的网络环境,我们引入了对网络运营商进行可配置的安全约束。我们设计了两种机制,白名单和块策略,以确保网络可用性和保持适当的块率。
Whitelist: 来自白名单关键服务的网络流量将不会受到任何其他防御规则的影响。
Block Strategy: 该机制是网络运营商与XNIDS之间的交互通道。网络操作员可以根据自己的需求和知识,为统一的防御规则生成过程选择合适的块策略。
- passive block 【被动拦截】
XNIDS只生成阻止恶意流的防御规则。这一策略的目标是尽量减少防御规则的影响;
- assertive block【信任拦截】
网络运营商倾向于信任相应的DL-NIDS和XNIDS生成的规则;
- aggressive block 【侵略拦截】
XNIDS倾向于通过直接阻止主机来阻止恶意活动。此策略的目标是从网络环境中快速消除恶意主机
统一防御规则 Unified Defense Rule
为了支持使用不同规则语法的各种防御工具,我们引入了一个统一的防御规则表示,它作为解释和可操作性防御策略之间的桥梁
每个统一的防御规则包括四个主要组成部分:
<entity, action, priority, timeout>
它描述了基于一组网络属性对网络流量的一个子集执行的操作
-
entity 是一个目标(例如,connection),其中应用防御行动
-
action 是对entity的所有网络流量执行的特定防御操作。
-
timeout 是专门用于控制一个防御规则的有效时间。
-
priority 如果一个网络流量实例匹配多个统一的防御规则,则只应用最高优先级的规则。默认情况下,由增量顺序决定,可以明确指定操作顺序,从一组统一的防御规则中解决潜在的冲突。
统一规则表示的语法见附录B。

Entity:
统一防御规则可以定义各种各样的实体:网络流、连接、IP地址、网络前缀和第二层MAC地址。统一规则通过8个元组指定这些实体,并支持将通配符作为元组元素。
Action:
统一防御规则使用了一个原语操作列表,以指定如何操作相应的网络流量。
最直观的action:Drop和Allow。用于对来自匹配实体的数据包强制执行显式访问控制。
Modify旨在更改来自特定实体的数据包的属性(例如,dest IP)
Whitelist是一种使一个实体不受任何其他防御规则影响的预防性方法。这是一种确保目标网络可用性的预防措施。
Generating Unified Defense Rule.【生成统一防御规则】:
为了生成防御规则,我们需要通过根据denfense role scope 内和security constraint 的重要特征填充匹配的字段来创建entity
为了将denfense role scope与defense action 联系起来,我们定义了两个基本操作: drop_flow 和drop_host.
对Per-flow规则,拦截恶意流量通过drop_host操作;对于multi-host 规则,拦截恶意流量通过递归执行drop_flow操作。
对于使用不同的拦截策略,我们分别修改了操作。对于passive block【被动拦截】将drop_host操作改为drop_flow操作。
对于aggressive block 将drop_flow操作改为drop_host操作。
对于assertive block 维持原有操作。
最后,我们可以基于该操作创建一个entity。
例如,当使用drop_flow操作生成multi-host 规则时,我们需要递归地创建flow entity。为了防止规则冲突,我们将priority 设置为一个增量数字。timeout 参数可针对不同的部署环境进行配置。
实施和实验设置 Implementation and Experiment Setup
XNIDS Implementation.:
在XNIDS中有三组可配置的超参数。
为了近似历史输入,在步骤1中,我们设置了搜索终止条件δ=1e−2,更新时间为10。【见前文近似历史输入处】
对于历史输入周围的采样,我们将衰减函数设置为高斯分布【见前文围绕历史记录输入进行采样】
为了获取特征依赖性,我们遵循目标DL-NIDS的组策略,为稀疏组套索设置混合参数α = 0.05和调优参数λ = 0.2【见前文捕捉特征之间的依赖关系】
我们使用Python包asgl 实现了XNIDS,并使用网格搜索来调优参数,以提高性能并测试参数的敏感性。
Target DL-NIDS.
我们使用四个最先进的DL-NIDS作为目标系统: Kitsune [46]及其已发布的数据集;ODDS [33]与CIC-DoS 2017数据集[20,35];以及RNN-IDS [82]和AE-IDS [64]与NSL-KDD数据集[49]。对于划分训练和测试数据的策略,我们遵循这些论文中的原始设置
Comparison Baselines.
我们比较了XNIDS与五种最先进的解释方法: LIME、SHAP、LEMNA、IG和LRP。详情见附录C.2。
Actionable Rule Generation:
XNIDS可以将统一的防御规则转换为具体的防御规则,然后通过以下步骤部署到不同的防御工具上
- 基于对象防御工具的特定语法创建一个可操作的防御规则模板。
- 可操作的防御规则模板中的相关字段用统一防御规则中的适当值填充
- 生成的防御规则可以自动或手动部署到相应的防御工具上
Evaluation 评估
我们首先考虑到[27,55]使用的一般标准和[79]中引入的安全相关标准,从保真度、稀疏度、完整性和稳定性等方面来评估XNIDS的解释成分。
Evaluation of Explanation 评估解释
首先将重要性得分向量β缩放到范围[0,1]。然后,我们根据重要性分数对这些特征进行排序。较大的重要性评分βi表明了特征xi的高相关性。
Fidelity【保真度】
这个实验评估了解释方法捕获对特定检测结果的重要特征的真实程度。
使用DAk(x,f) = f(x | modify(k))
modify(k)有两种情况
- 对于异常样本,modify (k)使k个重要特征失效为零;
- 对于良性样本,使用相同的操作,不足以评价的良性样本的保真度
这一发现实际上与[79]中“将良性特征设置为零通常不会影响预测”的说法相一致
为了有效地评价良性样本的描述性准确性,我们遵循[27]中提出的保真度测试方法,稍微改变[79]的度量,用最近异常样本中的相应特征替换良性样本的顶部k特征。
我们发现,解释方法如果能够准确地选择良性样本的良性特征,用相应的异常特征替换这些特征,可能会导致误分类。
然后,我们将这些样本输入DL-NIDS,并计算整个数据集上的平均描述精度(ADA)。如果所选的重要特征与检测结果相关,我们期望ADA从保真度测试中显著下降
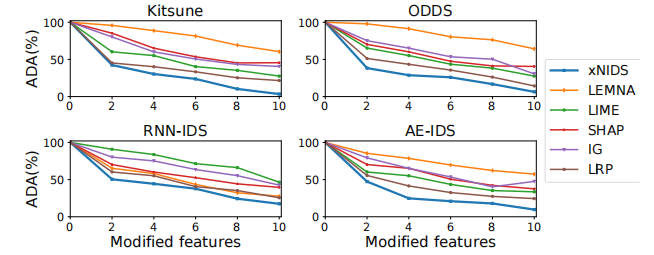
如图3所示,与基线方法相比,XNIDS在保真度测试中ADA下降最大。
这一显著的减少证实了XNIDS所选择的特征与检测结果高度相关。
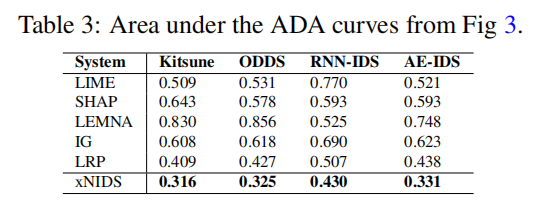
然后,我们使用表3来总结图3中的ADA曲线的曲线下面积。我们观察到XNIDS在AUC方面优于基线方法。
直观地说,在选择相关特征时,XNIDS通过稀疏组套索捕获特征依赖性,而基线方法忽略它们。综上所述,本实验证实了XNIDS在选择重要特征方面可以产生更可靠的解释结果。
为了证明我们采用DA来评估针对良性样本的解释方法的保真度
我们比较了这两种操作的异常率: 1)将良性特征设置为零;2)用异常特征替换良性特征。
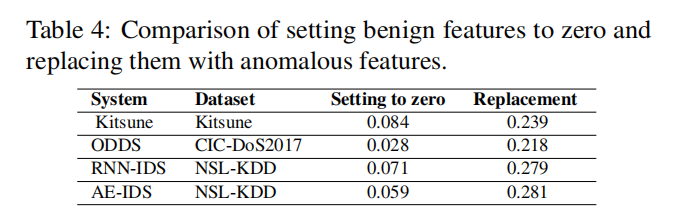
我们观察到,将良性特征设置为零的最高异常率约为0.084,而用异常特征替换良性特征的最低异常率为0.218。平均而言,通过用异常特征替换良性特征,我们可以将所有数据集上的异常率显著提高至少4倍。
Sparsity 稀疏度
期望的解释方法能选择有限数量的特征作为解释结果,因为这样会更方便网络运营商进行入侵分析和防御
为了评估稀疏性,我们遵循[79]中引入的在零附近的质量(MAZ)标准。
由于重要分数β=(βi,…βd¯)T被缩放到范围[0,1],我们首先将β拟合到一个半归一化的直方图h,然后我们通过β∈[0,1]的MAZ(β)计算MAZ
我们在图4中表示了MAZ曲线。我们还计算了曲线下面积(AUC),并显示了表5中的信息。如果解释方法可以给大多数特征赋值为零并实现稀疏解释,那么我们预计MAZ曲线将有一个接近零的陡坡和一个较大的AUC
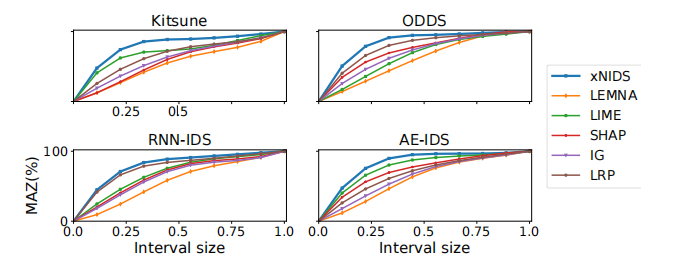
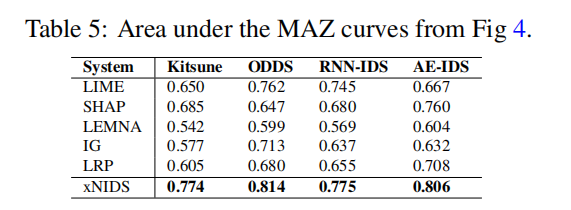
如图4所示,我们观察到XNIDS具有最陡的斜率,这意味着XNIDS将大部分重要分数分配接近于零
同样,我们观察到XNIDS在表5中具有最大的AUC,这证实了XNIDS在稀疏性标准方面优于基线方法
LEMNA在稀疏性测试中表现最差。这背后的原因是LEMNA假设相邻的特征对检测结果有相似的贡献,而这并不适用于DL-NIDS。
相比之下,XNIDS采用稀疏组套索技术,在组级和特征级上均实现了稀疏效应,适用于解释DL-NIDS。
**Completeness **完整性
如果它能为所有可能的输入样本创建适当的结果,那么一个解释就很完整了。
我们首先遵循Warnecke等人. [79]的定义来评估关于单个输入xt的解释的完整性。然后,我们扩展了完整性标准来评估关于历史输入的解释的完整性(xt−1,…,xt−k)。
Warnecke等人[79]认为,必须合成一部分(5%)检测到的相反类样品,以达到完整性。
我们将良性样本表示为xb =(x1 b ,…,xdb)T,将恶意样本表示为xm =(x1m ,…,xdm)T。他们还认为,围绕着恶意样本合成良性样本很容易。
通过简单地将良性特征设置为零(xib = 0)来围绕良性样本合成恶意样本是具有挑战性的,这通常不能翻转检测结果。
解决这个问题,当围绕良性特征进行采样时,我们不是总是将特征设置为零,而是用恶意特征替换其中的一部分(xib = xim)。实验表明,通过用这些恶意特征替换良性特征,我们可以有效地满足5%的要求。
在评估考虑历史输入的完整性时,我们观察到,在某些情况下,当前的输入值xt包含了解释所需的所有信息。
例如,数据包在UDP流中看起来类似。因此,有可能从当前的输入中得到非衰退的解释。然而如果我们忽略历史输入,我们很可能会得到其他情况的衰退解释。例如,在操作系统扫描的整个过程中涉及到各种协议,但当前的输入只包含一个协议。因此,我们可能无法将其他协议标记为相关的协议。我们还观察到,为异常样本创建非衰退的解释更为关键。从网络运营商的角度来看,我们只需要防止异常,同时保持良性的完整。直观地说,我们通过计算异常样本的百分比来衡量历史输入的完整性,这些异常样本包含足够的信息来进行非衰退解释.。
下图:关于历史记录输入的剩余样本

我们可以观察到,至少有26%的异常样本没有包含足够的信息来进行非退化的解释。由于基线方法忽略了历史记录输入,因此它们很可能会对涉及到各种数量的输入的攻击生成退化的解释结果。相比之下,XNIDS可以动态地近似历史输入,并且在完整性方面优于现有的方法
Stability 稳定性
根据[79]中的定义,我们进一步评估了解释结果的稳定性。
所需的解释方法应该在多个测试中对相同的样本产生相似的结果。由于IG和LRP是确定性的,因此IG和LRP对相同样本的解释结果在多个测试中没有差异。因此,我们关注基于扰动的方法LIME、SHAP、LEMNA和XNIDS的稳定性。
为了检验解释的稳定性,我们计算了相同输入的解释结果的前K个特征的交集大小。一个稳定的解释方法的稳定性得分应该接近于1。
方法就是看n次实验的得分向量βi,他们的最前的k个特征的交集取平均,若完全相交则为1,说明每次的特征选取相同,具有稳定性
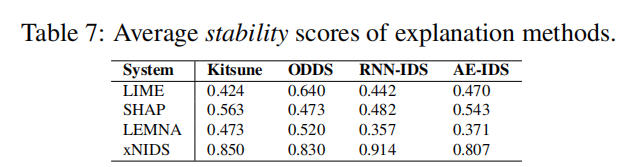
XNIDS可以通过以下方法生成更稳定的解释: (1)利用特征组更可靠地合成样本;(2)通过给最新的输入分配更高的概率来集中样本。
超参数灵敏度和调参
Sensitivity and Tuning of Hyper-Parameters
如果δ太小,而更新时间(U)太大,则XNIDS将变得不足,因为搜索空间将呈指数级增长。
通过将更新时间设置为10,我们可以在实验中能够近似地接近历史输入(高达1024)
我们将主机和协议过滤器应用于Kitsune和ODDS,同时跳过RNN-IDS和AE-IDS的步骤2,因为主机或协议信息不可用。对于历史输入周围的采样,我们发现高斯分布对所有的实验都很有效。
为了捕获特征依赖性,我们遵循与目标DL-NIDS相同的组策略,这提高了XNIDS的性能。
对于稀疏群套索,我们设置的λ越大,解释就越稀疏。在特征数量不断增加且分组信息无法利用的情况下,XNIDS的稀疏群套索分量将简化为套索。
解释评价总结 Summary of Explanation Evaluation

我们根据每种评价标准的三个分数对每种方法进行排序
我们观察到DL-NIDS在所有标准中的排名都高于LIME、SHAP和LEMNA。对于IG和LRP,XNIDS在保真度、稀疏性和完整性方面有更高的排名,在稳定性方面有类似的性能。总的来说,XNIDS具有最好的性能,因为它考虑了历史输入和特性依赖性。
Evaluation of Rule Generation 评估规则生成
我们评估了XNIDS中规则生成机制关于所支持的防御工具、所覆盖的攻击和延迟的实用性、准确性和效率。
在这个实验中,我们同时使用了Kitsune数据集和CIC-DoS2017数据集,因为NSL-KDD数据集没有足够的流量信息来生成规则。
支持防御工具
与现有的专注于特定防御工具的工作不同,统一的防御规则可以支持各种网络防御工具。本实验提出了由统一防御规则所适应其固有规则的不同防御工具。如表9所示,统一防御规则完全可以转移到OpenFlow中,这意味着我们可以将所有生成的统一防御规则转换为OpenFlow规则。同时,统一防御规则部分可转移到 iptables,、Pfsense和Squid。当使用iptables、Pfsense和Squid时,我们不能设置自定义的优先级或超时。

Covered Attacks覆盖的攻击
为了证明统一防御规则能够准确地防御各种各样的网络攻击,我们给出了三个关于防御规则范围的代表性例子。
- Per-flow
我们以SYN DoS为例,演示一个统一的防御规则如何阻止恶意流。一种简单的方法是阻止来自恶意主机的单向流。为了减少影响,统一防御规则将TCP.flag指定为SYN。

- Per-host
我们以操作系统扫描为例,演示了统一防御规则如何阻止恶意主机。统一防御规则将尽可能长时间地通过IP或MAC地址阻止受感染的设备

- Multiple-hosts
我们使用简单服务发现协议(SSDP)放大为例,以演示统一防御规则如何阻止来自多个主机的恶意流。统一防御规则将阻止目标端口为1900的所有网络流量,同时允许良性主机使用此服务。
默认情况下,多主机作用域规则会递归地阻止来自恶意主机的SSDP流。但是,另一种方法是关闭SSDP端口,同时允许良性主机使用此服务。

Latency 延迟
本实验分别评估了解释检测结果和可操作规则生成的延迟。在制定防御规则时,其中一个担忧是它生效的速度有多快。因此,我们应该尽可能地减少解释和规则生成的延迟。
Explanation Latency.:
超过90%的解释延迟低于600 ms。这个延迟由解释方法的速度和目标DL-NIDS决定的
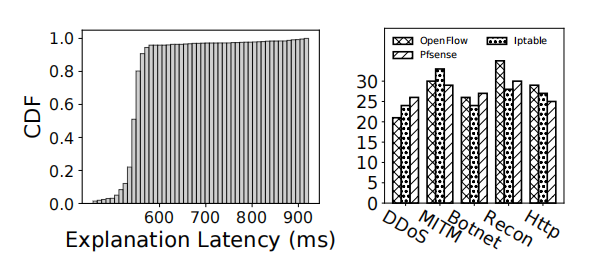
左图显示了解释的延迟时间【 CDF 累积分布函数】。
右侧的图显示了关于防御工具的规则生成时间(ms)。Recon、MITM和HTTP分别代表 Reconnaissance、Man in the Middle和HTTP Flood。
Rule Generation Latency.
不同的防御工具因规则生成时间而异。最大延迟(35 ms)是侦察攻击的openFlow规则。平均延迟约为25 ms。
Comparison with Existing Work 与现有工作的对比
为了更好地演示XNIDS的规则生成组件的好处,我们在表中提供了FIRMA [54]和XNIDS的比较

XNIDS可以支持更多的防御工具,并生成具有不同范围的防御规则。相比之下,FIRMA只支持两个防御工具,并生成每个主机的规则。此外,FIRMA需要对签名生成进行离线分析,而XNIDS可以直接根据DL-NIDS检测结果的解释生成规则
6.3 故障排除和主动响应 Troubleshooting and Active Responses
本实验演示了XNIDS如何帮助网络运营商理解DL-NIDS行为,排除检测错误,并通过案例研究实现主动响应。
6.3.1 Understanding DL-NIDS Behaviors
Reasons for Anomalies【异常的原因】:
我们使用操作系统来扫描和HTTP泛洪作为示例来演示DL-NIDS如何检测异常。
给出的解释: xNIDS认为LLMNR、NBNS和SSDP是重要的特征
网络运营商的理解:这个结果与众所周知的对操作系统扫描攻击的描述相匹配,即攻击者利用各种协议来扫描网络,以寻找可能的漏洞。
给出的解释:解释: xNIDS将HTTP Referer确定为最重要的特性。
网络运营商的理解:该结果与本实验中HTTP泛洪攻击的过程相吻合。攻击者使用Botnet通过同一超链接(引用器)发送大量的HTTP GET请求,以淹没受害者服务器。


Reasons for FN and FP.
通过对解释结果的分析,我们确定了导致假阴性的两个原因: (1)不适当的参数,如阈值;(2)设计不足,如关注标题信息。
我们还确定了三种类型的假阳性: (1)受感染的良性、来自受感染主机的良性流量被误检测为异常;(2)紊乱的良性、紊乱的来自良性主机的流量被误检测为异常;(3)看不见的良性、看不见的良性流量被误检测为异常,这是DL-NIDS最常见的错误。
6.3.2 Troubleshooting Detection Errors 故障排除检测错误
通过分析DL-NIDS背后的检测逻辑,我们现在提出了修补DL-NIDS的方法,以减少检测错误。为了修补被感染的良性流量或主机,我们利用防御规则生成程序来最小化检测错误的成本。
例如,我们使用【passive block】被动拦截策略来生成【per-flow scope】规则来阻止恶意的TCP.SYN流量精确,而保持良性的UDP流不变。
这种方法的优点是,我们不需要重新训练DL-NIDS,同时减少在运行时的错误。
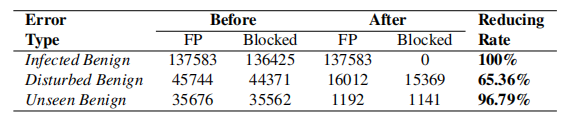
在故障排除前后的检测错误。假阳性表示被检测到为异常的良性样本的数量。Blocked表示被防御规则删除的良性样本的数量。
为了修复良性样本错误紊乱,我们需要故意干扰流量,使DL-NIDS更加健壮。对于看不见的良性样本,我们可以用增强数据对DL-NIDS再训练后降低FPR。
对于受感染的良性错误,XNIDS可以减少检测错误100%,具体来说,XNIDS只阻塞SYN DoS流,而良性UDP流不受UDP影响。
对于紊乱的良性错误和看不见的良性错误,XNIDS可分别降低检测错误65.36%和96.79%。
我们观察到,干扰良性是最具挑战性的FP减少,这与直观的知识相一致,因为它模拟一个不稳定的网络环境是困难的。
6.3.3 Active Responses 主动响应
我们展示了三种情况下XNIDS的拦截率,并将其与基线方法FIRMA进行了比较。
在图6中,在故障排除前,aggressive block(图6 ©)具有最高的拦截率(平均。97.34%)为恶意流量,而许多良性流量也被阻塞。
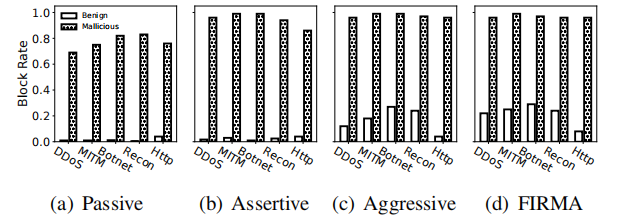
图6:在故障排除之前,XNIDS关于不同场景和FIRMA的流量阻塞率。
因为受感染的主机可能同时发送良性的和恶意的流量。因此,如果我们阻止这些主机,我们将阻止良性流量。
同时,【passive block】被动阻断(图6 (a))的良性阻断率最低。0.32%)和恶意流量(平均。74.28%),因为我们只阻止了恶意的数据流。
如果受感染的主机使用其他协议发起攻击,它们可以绕过此防御规则。
作为一种权衡,assertive block(图6 (b))具有较高的拦截率(平均。95.72%)的恶意流量和高通过率(平均。98.54%)为良性流量。
当防御规则激活时,我们测量观察窗口内的拦截率。当防御规则到期时,拦截率将为零。

图七: 故障排除后的XNIDS的流量阻塞率。
经过故障排除后,良性流量的阻塞率显著降低。具体来说,是passive场景中的良性流量拦截率和assertive 场景(Fig. 7 (b)) 小于 0*.*04%
aggressive场景最高的良性流量拦截率0.2%,仍然相对较高。
因此,我们建议不要使用aggressive的策略,除非有强烈的网络攻击
与XNIDS比较,我们观察到FIRMA在故障排除前与aggressive block具有相似的性能,这是XNIDS最坏的情况,如图6 (d).所示
这一结果与直觉相吻合,即我们可能会通过简单地阻塞主机来增加假阳性率,这可能会不适当地阻塞良性流量,或者更糟糕的是,阻塞良性主机。本实验还证明了直接基于检测结果进行响应是代价昂贵和危险的。
相比之下,XNIDS可以通过考虑规则的范围和安全约束来生成更准确的防御规则。
为了进一步提高主动入侵响应的有效性,我们使用了白名单机制,以避免改变关键服务。我们可以解释良性样本来生成允许的规则,以避免阻塞良性样本。
7 Discussion
Robustness
最近,现有的研究表明,深度学习模型及其耦合解释模型容易受到对抗攻击
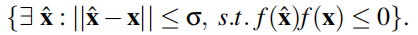
我们基于现有的文献来评估XNIDS的稳健性。我们创建了三种实际的基于流量的对抗性示例[29],每种类型有200个样本,总共有600个样本,以测试XNIDS是否能够抵抗对抗性攻击
我们假设攻击者对目标系统的知识有限,只能基于领域知识估计和设计代理模型。
我们的初步实验表明,这三种基于流量的对抗性样本的规避率分别为33%、49%和53%。
因此,通过考虑历史输入,XNIDS对那些对抗性攻击是相对健壮的
为了提高XNIDS的鲁棒性,我们简要讨论了基于现有文献的潜在的解决方案,因为对于如何保护解释方法免受对抗性攻击知之甚少。
Zhang等人[86]认为,为了减轻这些对抗性攻击,我们需要提高目标深度学习模型及其耦合解释模型的鲁棒性。
我们想(1)提高DL-NIDS的鲁棒性通过应用生成对抗网络(GAN)创建一个大数据集对抗训练考虑准确性和鲁棒性之间的权衡
(2)通过一系列解释器提高XNIDS的健壮性。
Adaptability
XNIDS通过将网络管理员配置的安全约束合并到防御规则生成过程中来解决适应性问题。然而,能够自主适应动态环境的全自动系统更为可取。为了进一步解决这一问题,我们计划在XNIDS中采用强化学习(RL)[48,75]的概念,使其能够适应不同的网络环境。
Global Explanation
XNIDS和最先进的解释方法[18,27,55]可以通过生成一个重要度评分向量来局部解释DL-NIDS的检测结果,这仍然是相对较低的水平。与此同时,对具有更有意义的高级特征的人类可理解的解释还有额外的需求。
我们计划在模块化级上研究全局模型可解释性的概念。通过全局解释,我们可以研究特征的高级相关性,并检查DL-NIDS是否被学习到的伪影所误导。
8 Other Related Work
由于我们在第2节讨论了大部分相关工作,我们在这里简要讨论其他相关工作。
Explainable Machine Learning
CADE [81]为安全应用程序介绍了一种基于距离的解释方法。不幸的是,虽然它很适合用于恶意软件检测,但当应用于DL-NIDS时,它的保真度极低(1.41%)。DeepAID [28]是一种基于反向传播的白盒解释方法,主要关注DL-NIDS的神经网络组件,同时忽略了Kitsune的特征提取器(FE)和特征映射器(FM)。此外,通过假设每个特征都是独立的,在进行DL-NIDS解释时,DeepAID不足以捕获结构化数据的特征依赖性。
Active Intrusion Responses
研究人员试图使用基于签名或基于规范的NIDS [52,69]来启用主动的入侵响应。例如,Amann等人[3]引入了一个框架,它允许在Bro [52]之上进行主动入侵响应,并通过OpenFlow [44]评估其功能。Xing等人设计了一个原型,用Snort [69]分析网络流量,并利用OpenFlow进行预防。Zhang等人[85]提出了一种通过可编程开关来减轻DDoS攻击的系统。据我们所知,XNIDS是第一个通过解释DL-NIDS来实现主动入侵响应的工作。
9 Conclusion
在本文中,我们提出了XNIDS,一个新的框架,它解释了DL-NIDS的检测结果,并生成了可操作的防御规则。XNIDS通过考虑历史输入和特征依赖性来解释DL-NIDS的检测结果。根据解释结果,XNIDS还可以排除检测错误,并生成关于防御规则范围和安全约束的可操作的防御规则。评价结果表明,XNIDS能够产生高保真、稀疏、完整、稳定的解释结果和可操作的防御规则。此外,我们还展示了XNIDS如何帮助理解DL-NIDS行为并排除检测错误。














 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









