







目录
2/24 正确认识chatGPT
常见误解
- 给出的回答不是已经准备好的(罐头回应×)
- 不是网络上搜索得出的答案(甚至有很多幻想出来的答案)
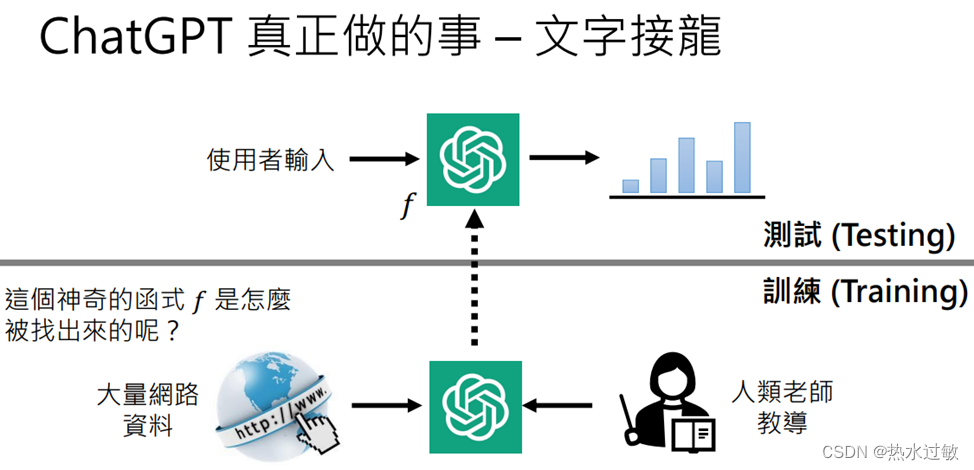
预训练
- chatGPT:chat Generative Pre-trained TRansformer
- 关键技术:Pre-train(预训练)=Self supervised Leaarning(自督导式学习)【Foundation Model基石模型】
- GTP-3的训练数据大小:570GB

ChatGPT带来的研究问题
- 如何精准提出需求?
目前使用的方法:Prompting
创新点:有没有比人工尝试更加系统性的方法? - 如何更正错误?
目前没有较好的解决方法
创新点:新研究题目Neural Editing - 侦测AI生成的物件
- 泄露秘密、隐私信息
创新点:新的研究题目:Machine Unlearning
文字冒险游戏
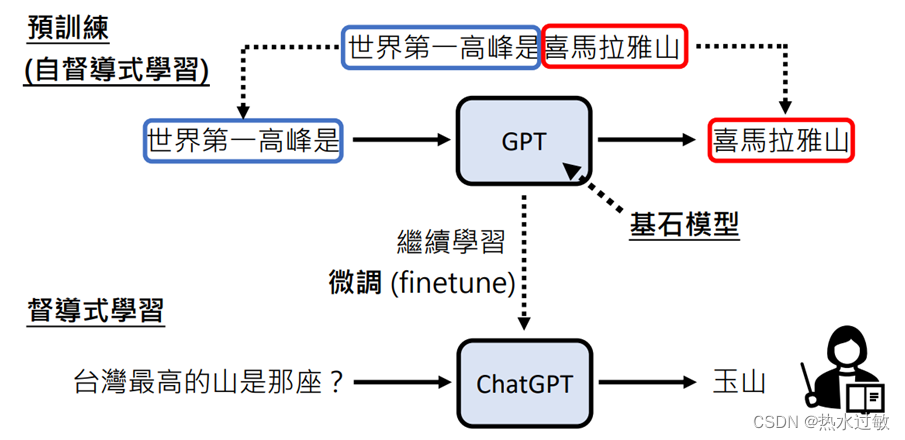
chatGPT(可能)是怎么练成的
-
chatGPT的“兄弟”:InstructGPT,论文地址:https://arxiv.org/abs/2203.02155
-
chatGPT学习四阶段
-
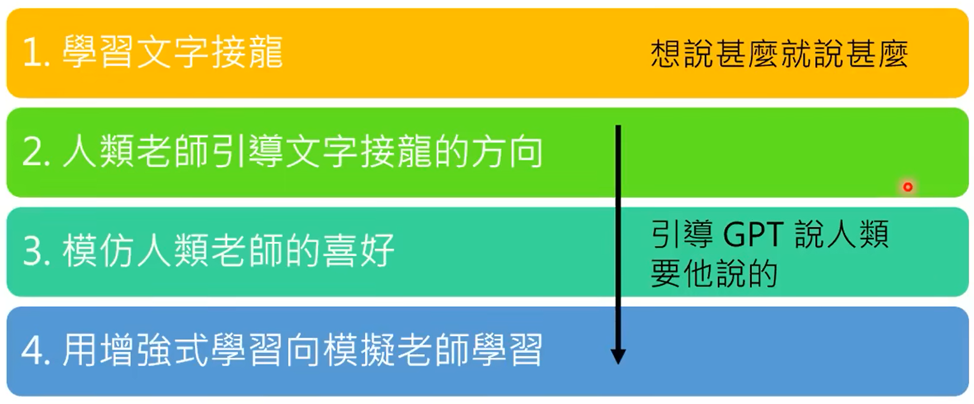
学习文字接龙
不需要人工标注,在网络上收集语句,对输入句子(字)后面可以接的字进行概率统计,每次输出高概率的字(每一次输出都不同) -
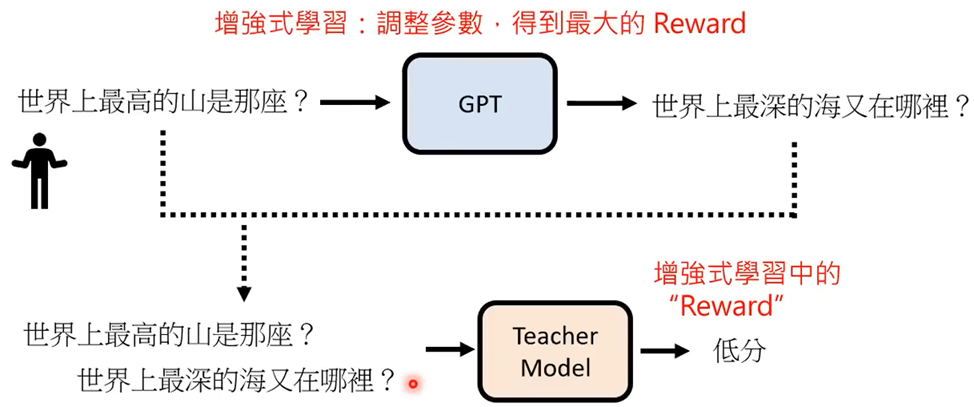
人类老师引导文字接龙方向
人来思考问题,并人工提供答案(不需要很多,目的只是为了让GPT知道人们希望得到的答案) -
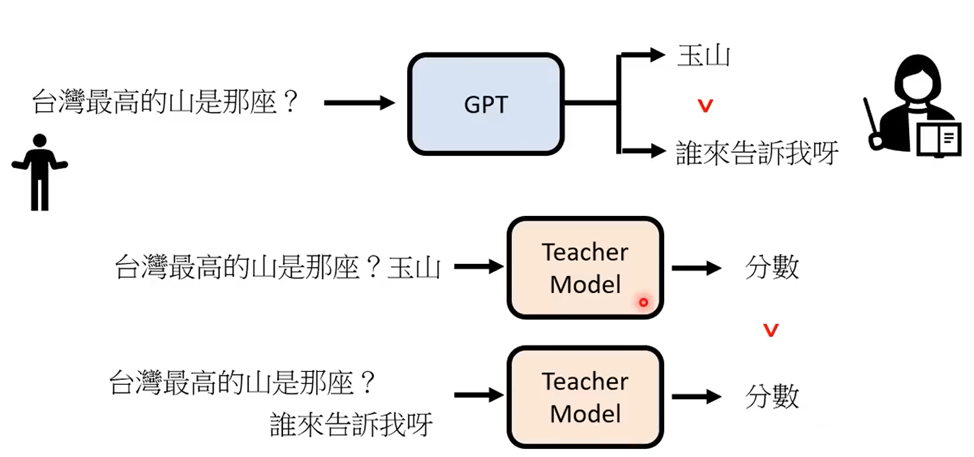
模仿人类老师的喜好
训练Teacher Model让希望输出的答案的“分数”大于其他输出
-
用增强式学习向模拟老师学习

总结
-
Predicting Pokémon CP
- 背景:预测宝可梦升级后的CP值(战斗力)
- Regression使用实例:Stock Market Forecast、Self-driving Car、Recommendation
Step1:Model
f(宝可梦(x))=升级后的CP值(y)
Step2:Goodness of Function
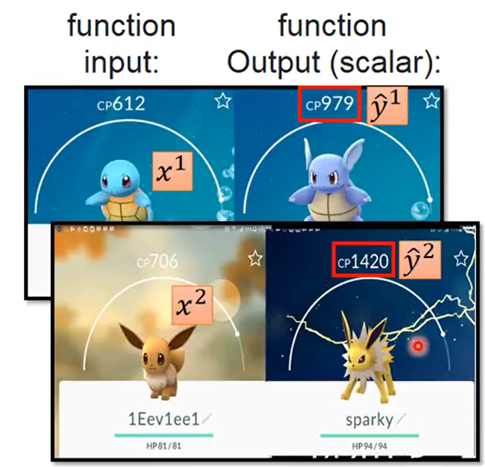
p.s. y1 head:“戴帽子”表示正确输出值
收集十组数据(10 pokemons)作为Training Data(后面会用另外的十组作为Testing Data)

设置Loss function L,目的:用来评估function的优劣(越大越差)

Step3:Best Function
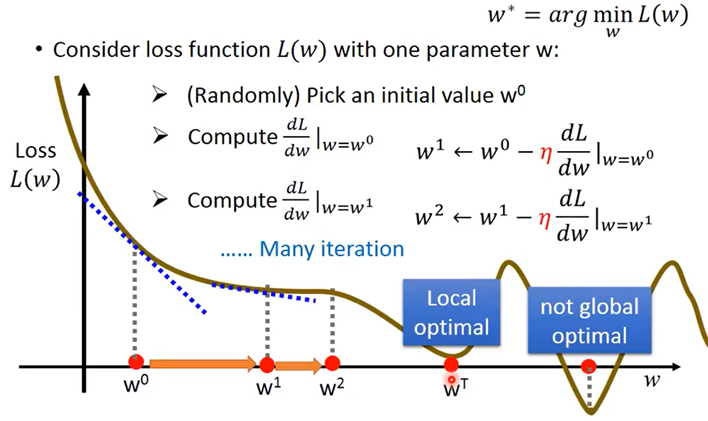
使用Gradient Descent寻找最优解(Loss函数的最小值)
当只有一个参数时
注意:
- 寻找最小值,当导数为负时应增大w值(向右走),故为减号
- η:learning rate学习率,手调
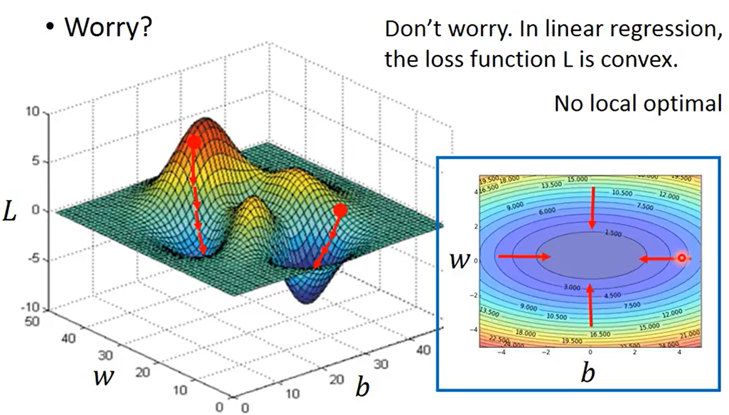
- 可能调入局部最优解,而非全局最优解
两个参数时–>求偏微分

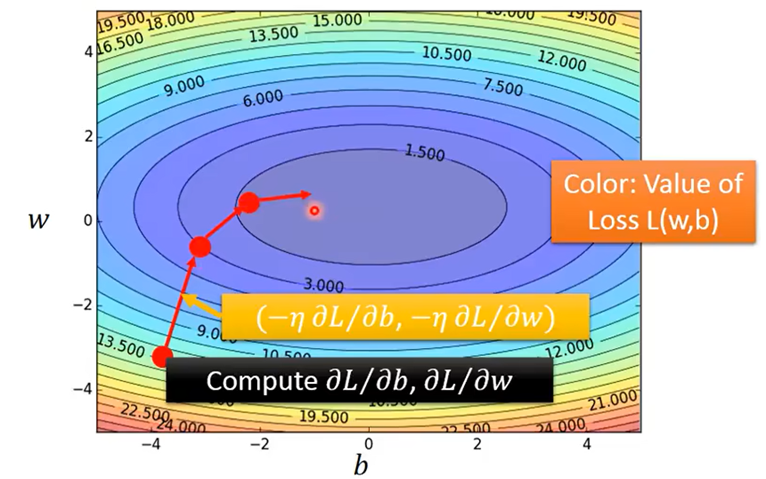
梯度下降的方法要考虑掉入局部解的情况,但本次的问题不用担心
求偏微分的公式如下:
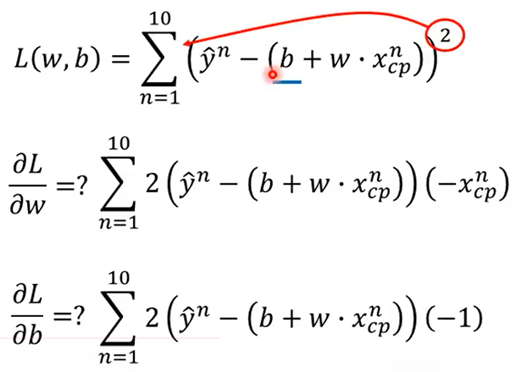 开始求解(通过比较Loss值,寻找最优的Model)
开始求解(通过比较Loss值,寻找最优的Model)
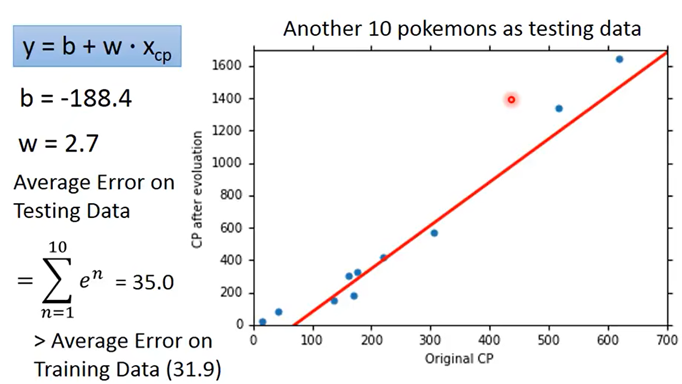
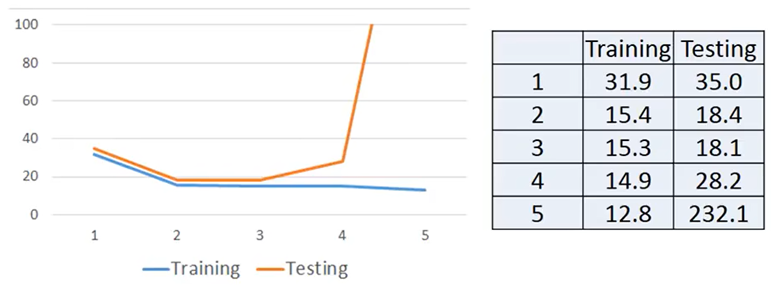
分别计算training data和testing data的average error
一次函数拟合:training error=31.9,testing error=35
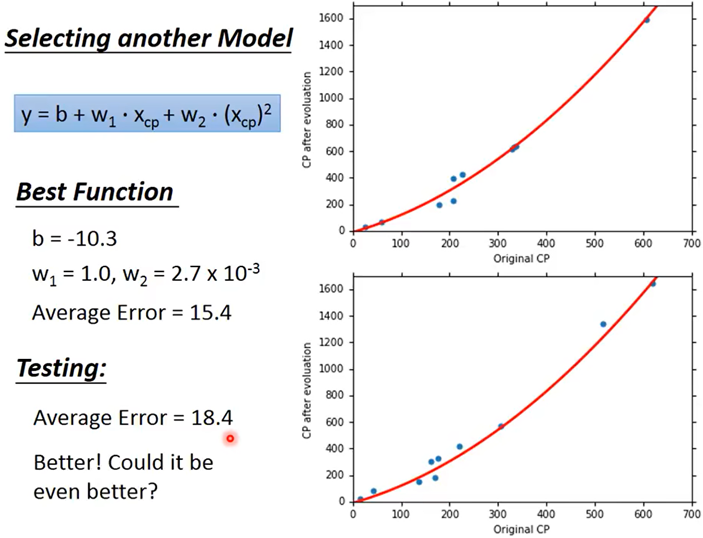
二次函数拟合:training error=15.4,testing error=18.4
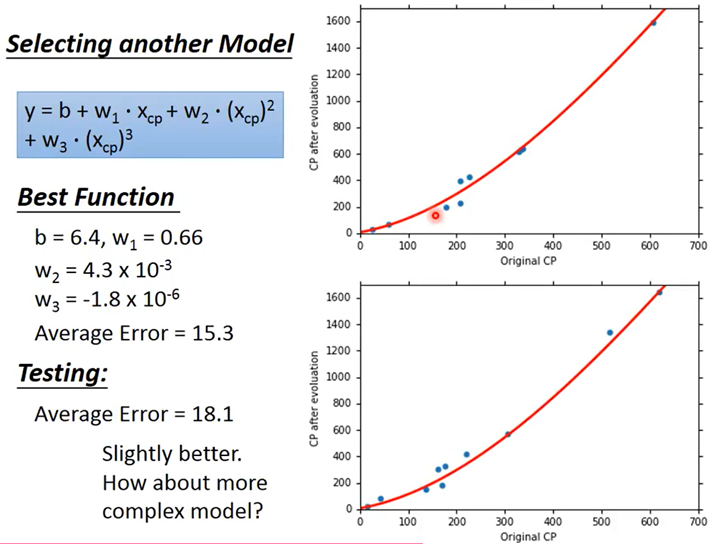
三次函数拟合:training error=15.3,testing error=18.1
四次函数拟合:training error=14.9,testing error=28.8

五次函数拟合:training error=12.8,testing error=232.1
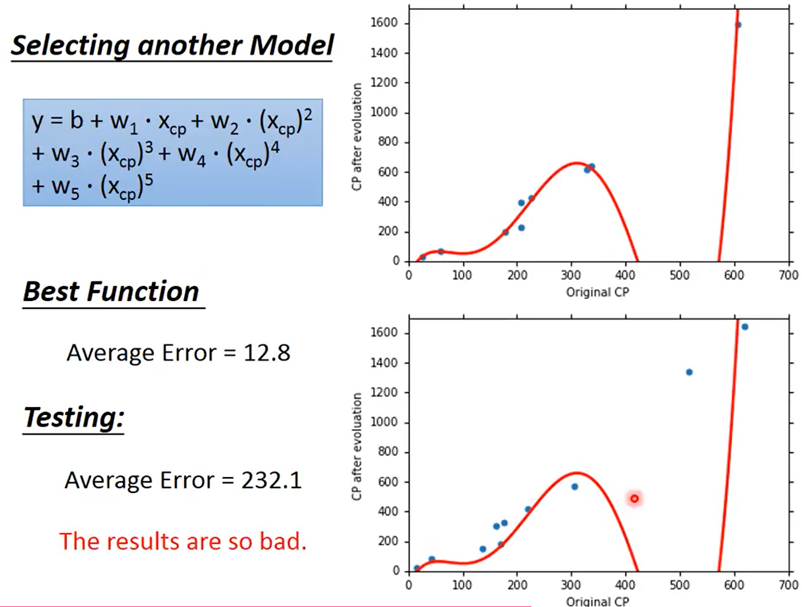
综上:越复杂的Model并不能得出更好的表现,这种现象称为Overfitting,所以在选择Model时并非越复杂越好,而是要选择合适的。
上述只收集了十组数据,当收集更多的数据,会发现预测CP值不能只根据进化前的CP值,而和Pokemon的物种有很大的关系(乐
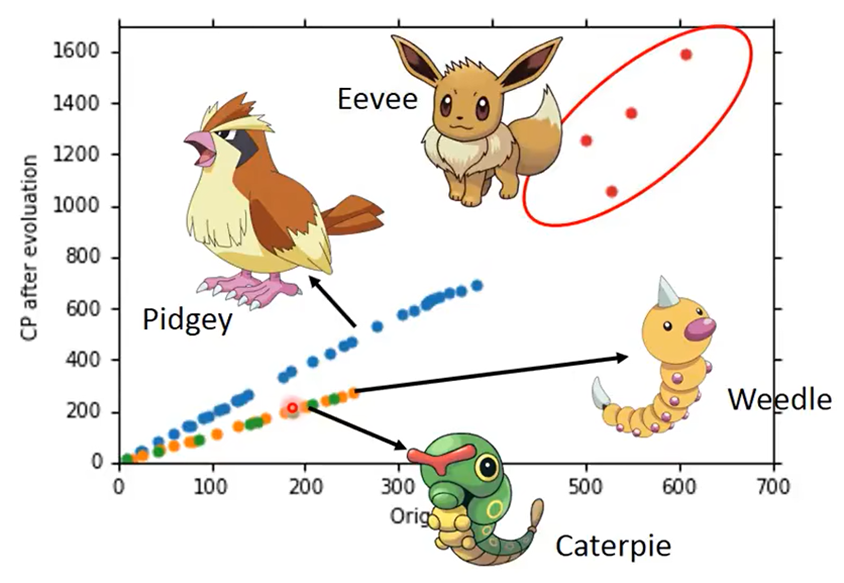
返回step1,重新设计model
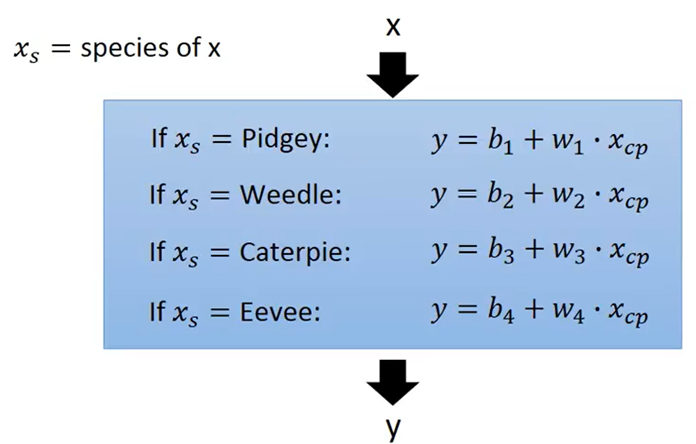
表示为Linear model


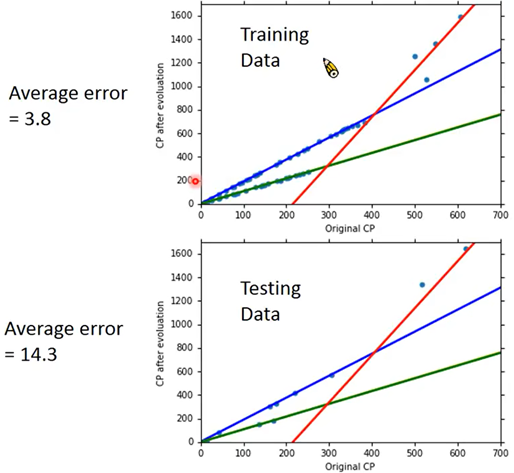
按照种类分别用一次函数拟合:training error=3.8,testing error=14.3
其余还可以考虑的影响参数:weight、height、HP……
考虑一个“最复杂的model”
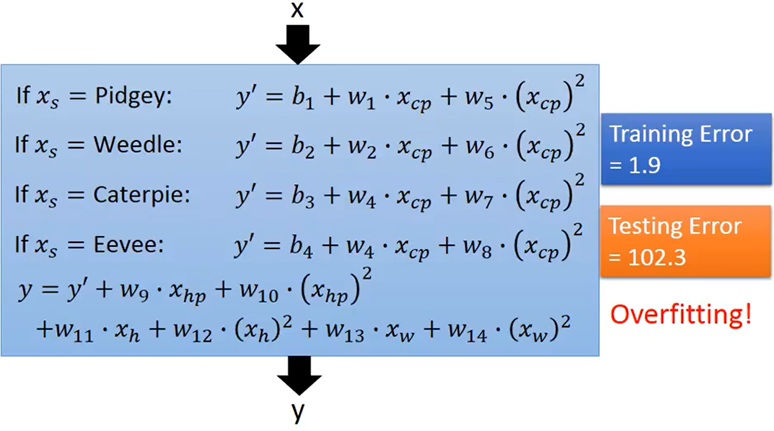
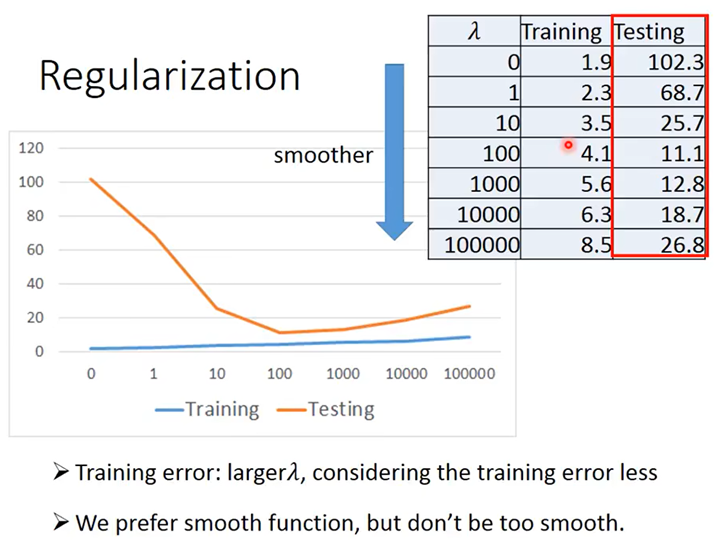
training error=1.9,testing error=102.3
结果显示Overfitting,但我们不同意这个结果,于是我们重新定义Loss函数!
返回step2,使用Regularization,使Loss函数更加平滑(对输入不敏感)
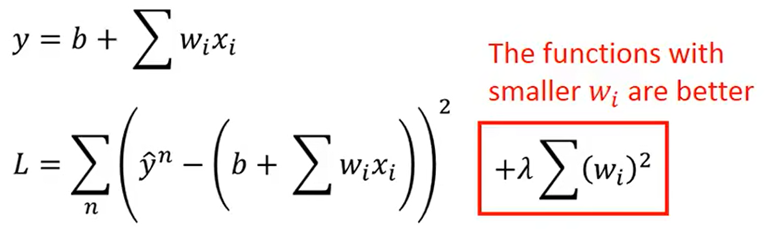
注意:不考虑b(bias);λ:手调
Pokemon classification
- 常见classification应用:credit scoring、medical diagnosis、handwritten character recognition、face recognition
- 背景:宝可梦属性分类(简单化问题:分类水系与一般系)
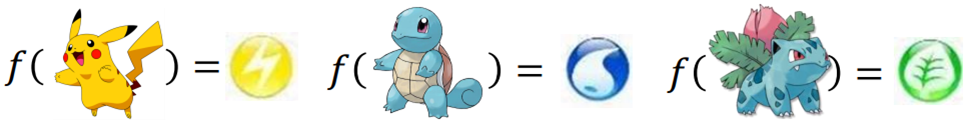
将宝可梦“数字化”,可以包括:total、HP、Attack、Defense、SP Atk、SP Def、Speed……的数值
如何分类?
法一:二分法,将其化为regression问题
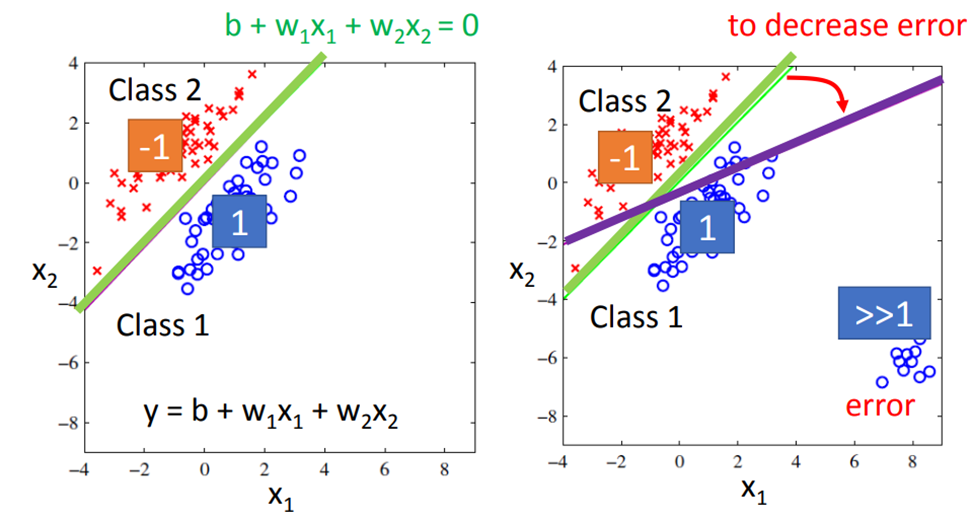
法二:一种理想的方法

法三:Generative Model生成模型
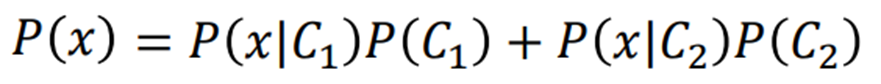
Training data:ID<400的宝可梦,水系79只,一般系61只
画出水系宝可梦defense(防御力)与SP defense(特殊防御力)的分布图
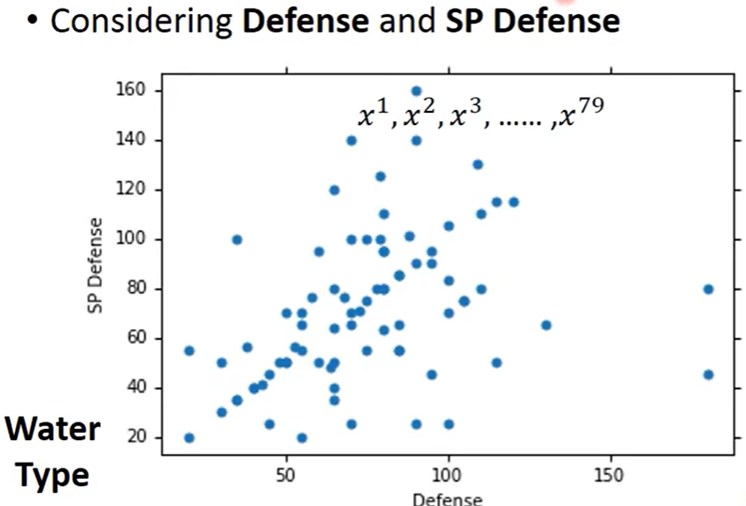
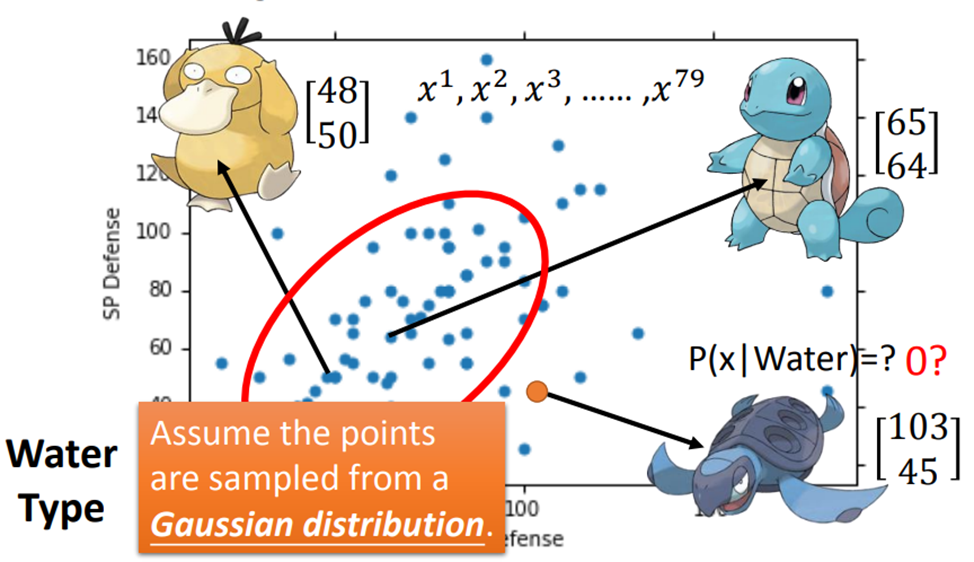
水系这79个点的Defense 和 SP Defense形成一个高斯分布
Gaussian Distribution高斯分布
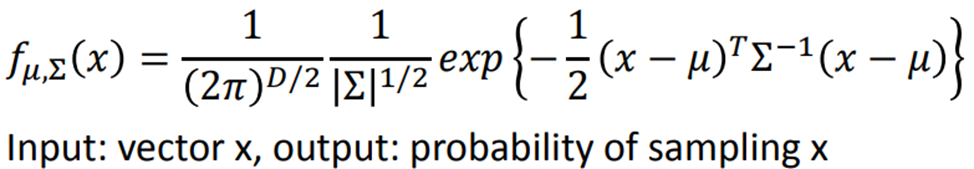
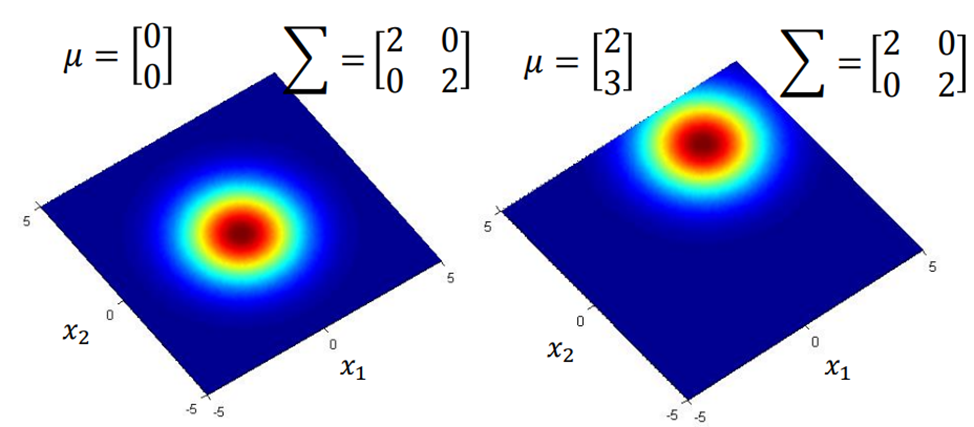
相同的μ,不同matrix:机率分布最高点不同,分布离散程度相同
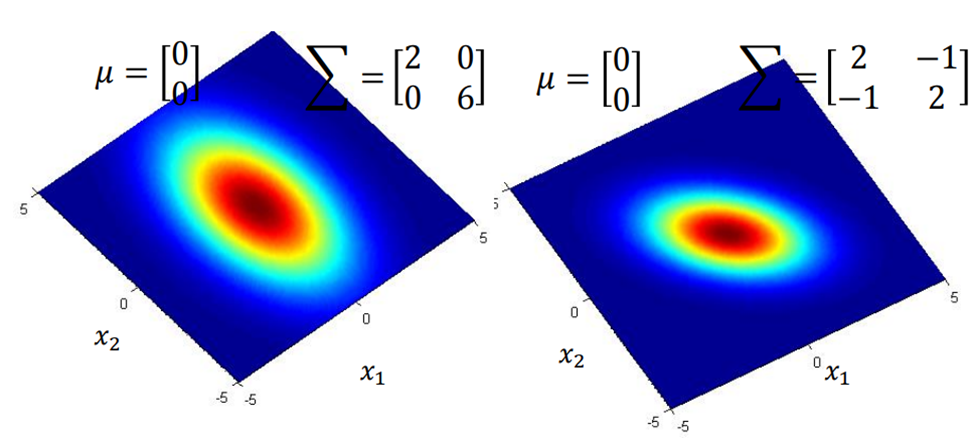
相同的matrix,不同μ:机率分布最高点相同,分布离散程度不同
如何寻找μ与matrix(Σ)?
使用Maximum Likelihood
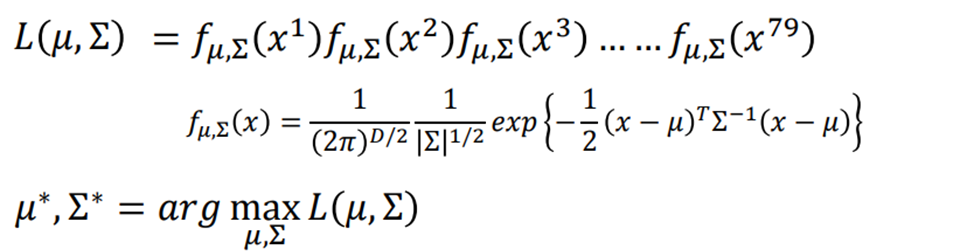
μ与Σ:最有可能产生79(61)个点函数的参数
计算公式如下
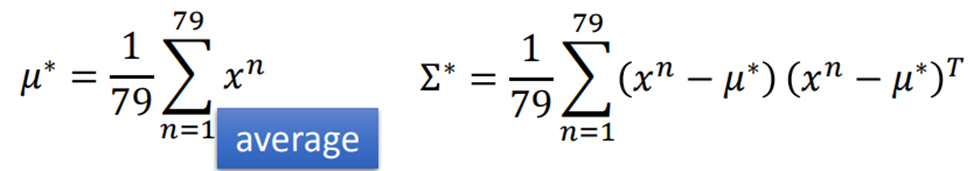
将水系分布与普通系分布带入公式
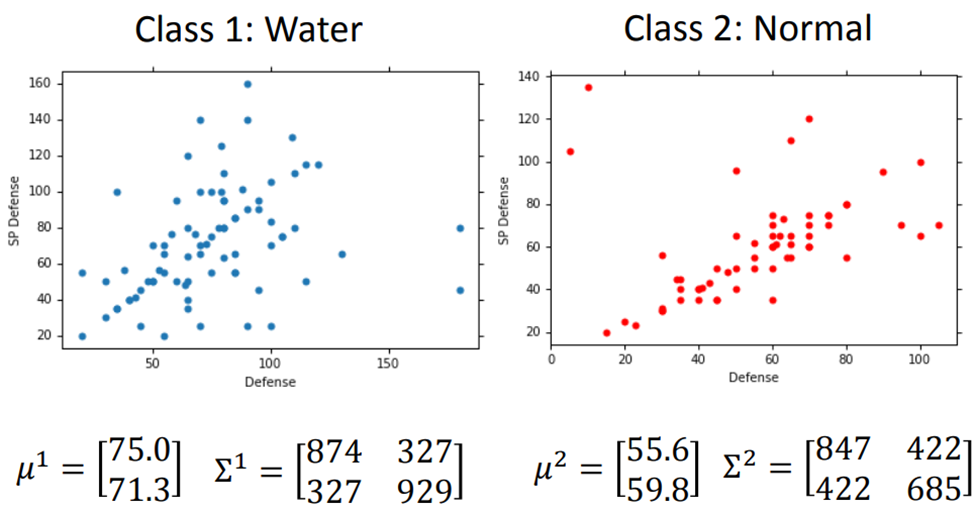
对每个点进行计算
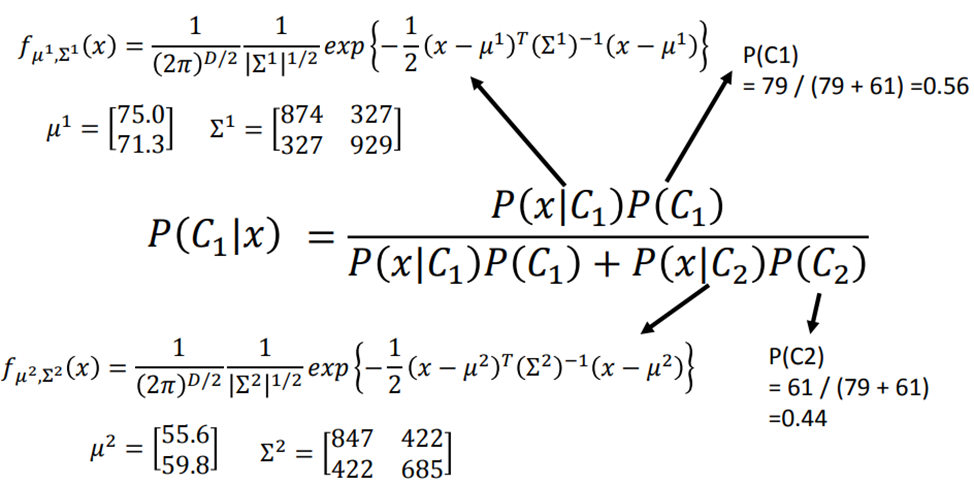
并设定分类标准
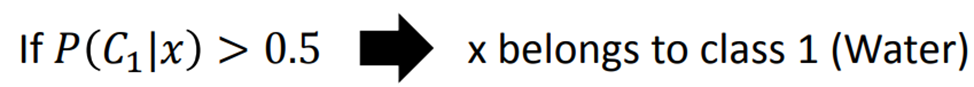
划分结果如下
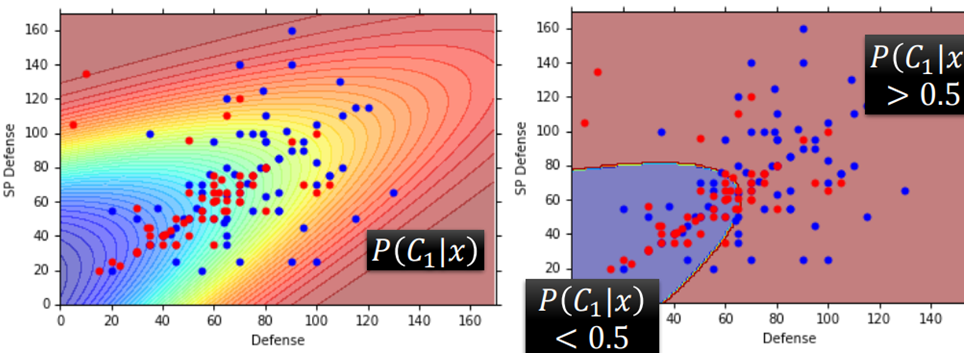
将结果应用到testing data,只有47%的正确率
如果使用全部的7个feature(从二维到7维),也依旧只有54%的正确率
结果不好,修正模型!
两组分布使用同样的matrix不同的μ(目的:减少参数)

继续画出图像,得出一条线性边界
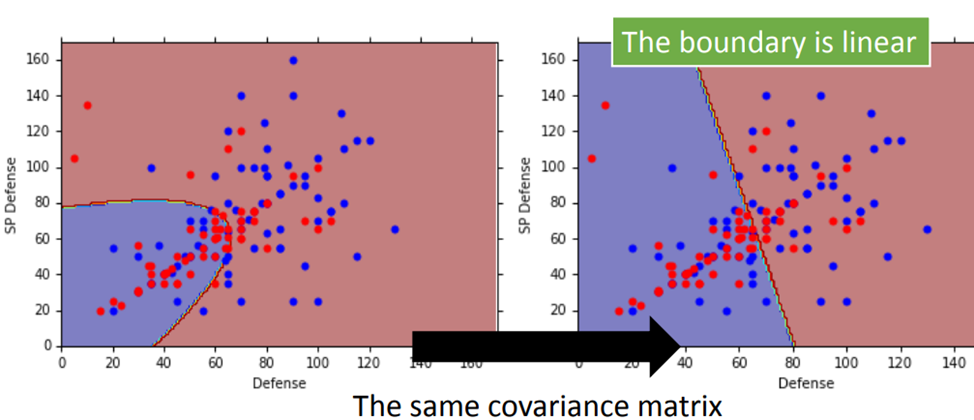
当考虑全部7个features,正确率上升至73%
回顾General Model

对于样本分布不一定要选择高斯分布,例如如果是二值分布,我们可以假设符合伯努利分布,具体应用中要根据样本特点具体而定。
如果我们假设所有的dimension之间是相互独立,那我们可以认为结果服从Navie Bayes Classifier(朴素贝叶斯分类器)
进一步分析如下
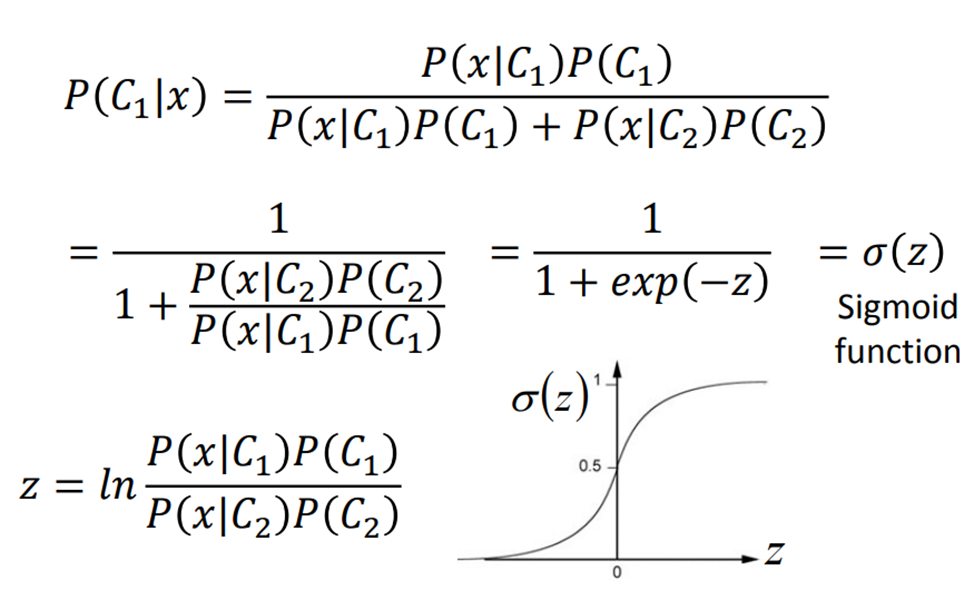
Sigmoid函数:一种激活函数,又称 Logistic函数,用于隐层神经元输出,取值范围为(0,1),可以用来做二分类。
(数学警告!)



(警告结束)

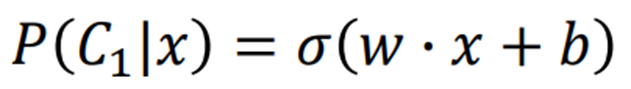
最核心的问题还是怎么去寻找合适的w和b(下一节中介绍)
Logistic Regression
如果你没有弄清楚linear regression与logistics regression的区别,以及我们现在为什么要使用logistics Regression而非linear regression,你可以去看这个:https://blog.csdn.net/Yemiekai/article/details/119081873
(其实是我自己不清楚orz,下面的图片是我根据这篇文章做的笔记,可以参考XD)
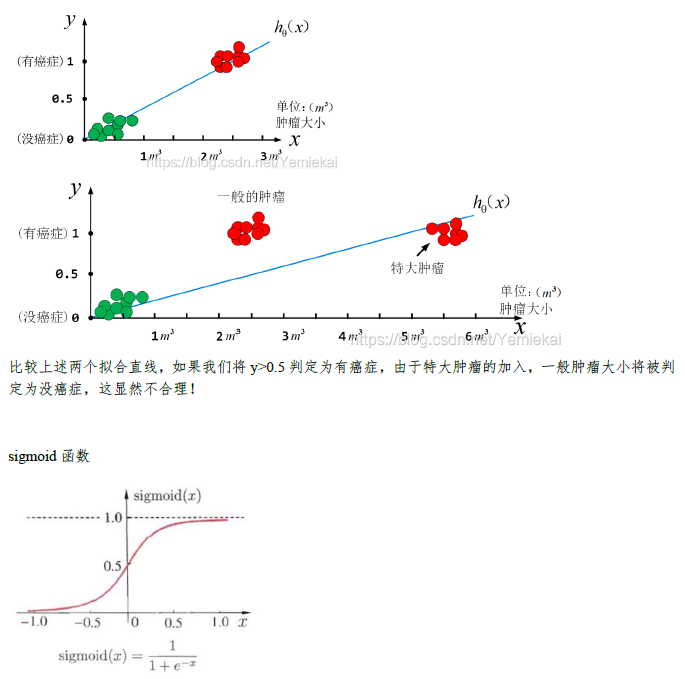
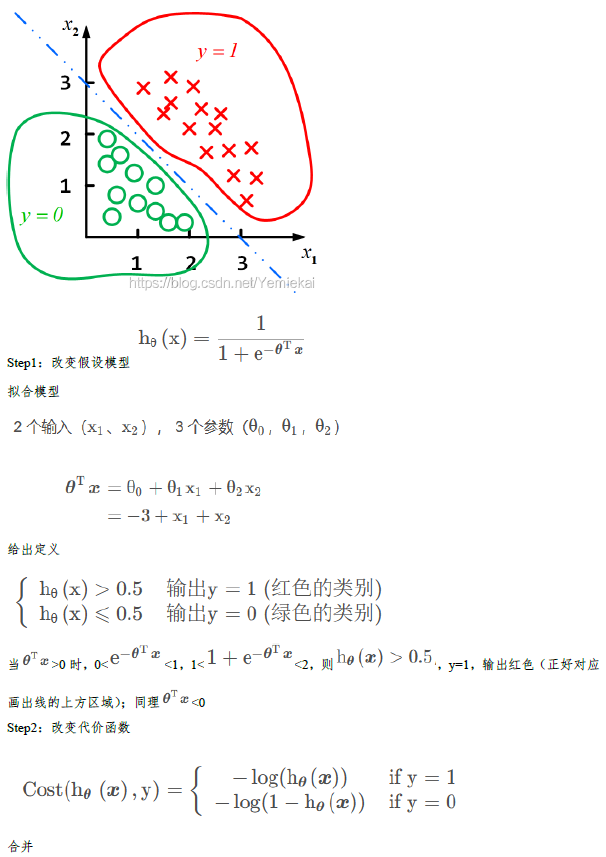

(笔记结束,让我们回到李宏毅老师的ML课程orz)














 5449
5449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









