










论文地址:https://arxiv.org/pdf/2005.03492.pdf
这是来自华南理工2020年的一篇survey,主要讨论的是场景文本识别(scene text recognition,STR)领域的现状与一些发展方向。
文中提到了他们建立的一个资源库,里面有数据集、现有算法等丰富资源,值得一看:GitHub - HCIILAB/Scene-Text-Recognition
在自然场景中识别文本,也称为场景文本识别,通常被认为是OCR的一种特殊形式,即基于相机的OCR。使得STR仍然具有挑战性的因素:
- 复杂的背景及与文本类似的背景
- 不规则的字体、大小与方向
- 因噪声干扰而失真,例如照明不均匀,分辨率低和运动模糊。
- 随机捕捉的文本难以识别字符和预测文本字符串
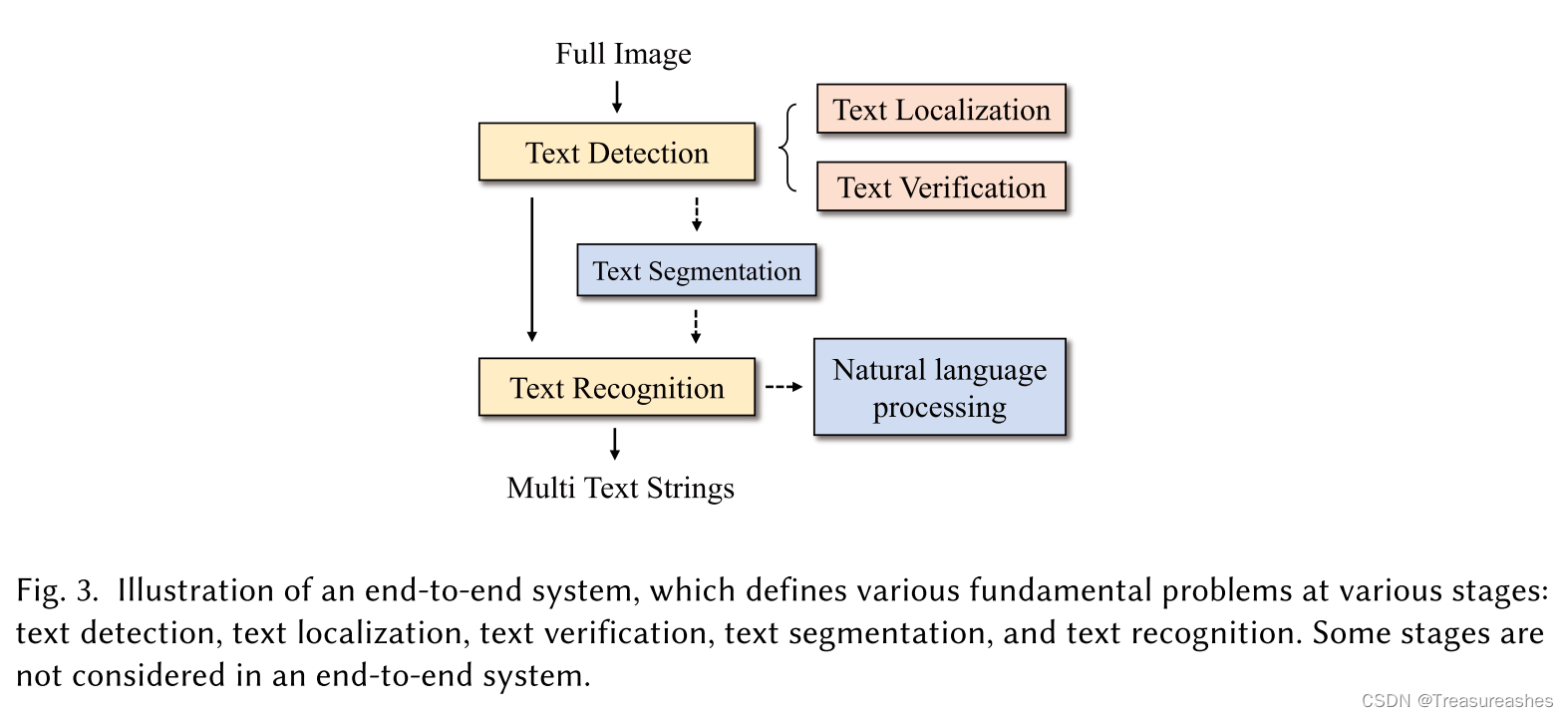
STR的基本问题
除了文本定位、文本验证、文本检测、文本分割、文本识别这些问题,值的一提的是端到端系统的构建。不同于将文本检测与文本识别视为两个子问题,在端到端系统中,这两个问题可以通过共享信息来进行联合的优化。
STR的一些特殊问题
- 脚本识别(Script identification):预测给定文本的脚本,多用于多语言系统,有助于选择正确的语言模型。 脚本识别可以解释为图像分类问题,通常设计区别性表示,例如中级特征(mid-level features),卷积特征(convolutional features)和笔触表征(stroke-parts representations)。
- 文本增强(Text enhancement):文本增强可以提高文本的分辨率,消除文本的变形或消除背景,从而降低了文字识别难度。典型的文本增强算法:反卷积(deconvolution),基于学习的方法(learning-based methods)和稀疏重构(sparse reconstruction)。
- 文本跟踪(Text tracking):为了保持视频中相邻帧之间文本位置和跟踪文本的完整性。 与图像中的静态文本不同,用于移动文本的跟踪算法必须在像素级别或子像素级别标识精确的文本区域,因为错误的跟踪可能会将文本与其背景或噪声文本混合在一起。 时空分析(Spatial-temporal analysis)通常用于视频中的文本跟踪。
- 自然语言处理(NLP):探索如何使用计算机来理解和操纵自然语言文本或语音。 基于文本的应用非常广泛,包括机器翻译(machine translation),自动摘要(automatic summarization),问题解答(question answering)和关系提取(relationship extraction)。
基于深度学习的文本识别方法

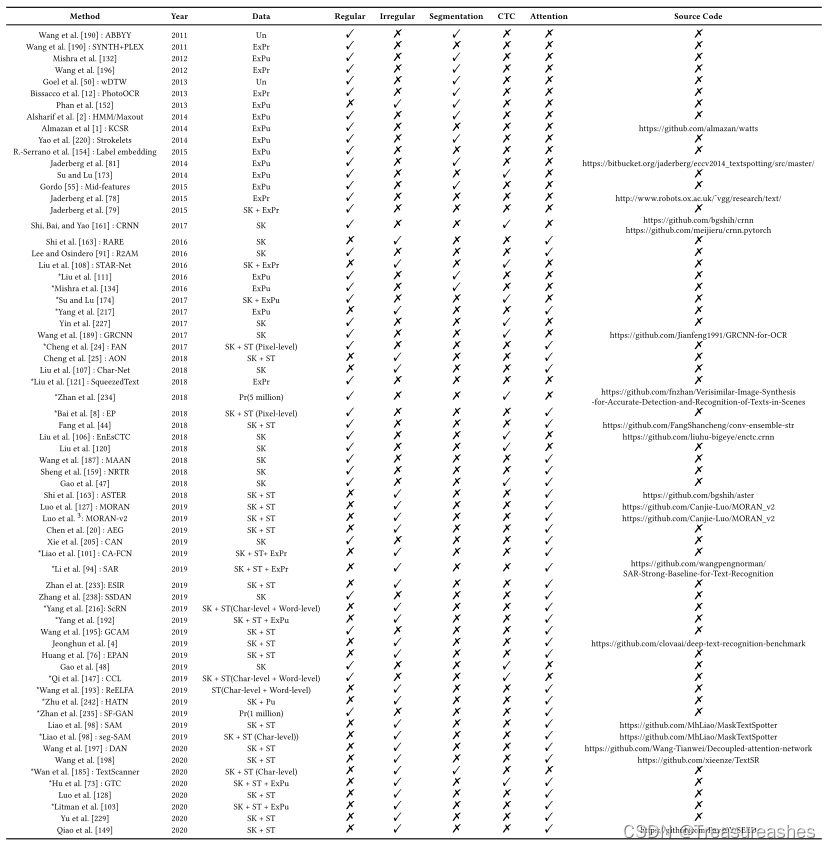
Cropped场景文本识别
基于分割的方法
通常包括图像预处理,字符分割和字符识别这三个步骤。 尝试从输入文本实例图像中定位每个字符的位置,应用字符分类器识别每个字符,然后将字符分组到文本行中以获得最终识别结果。主要可分为基于词库(lexicon)的方法与基于无词库的方法。词库的大小会直接决定检索的时间。
现存的问题:i)字符检测/分割的质量会限制识别性能。 ii)无法对上下文信息进行建模,会导致词级别(word-level)的结果不佳。
基于无分割的方法(Segmentation-Free Methods)
着重于通过编码器-解码器框架将整个文本实例图像直接映射到目标字符串序列,从而避免了字符分割。包含图像预处理,特征表示,序列建模和预测的四个阶段。
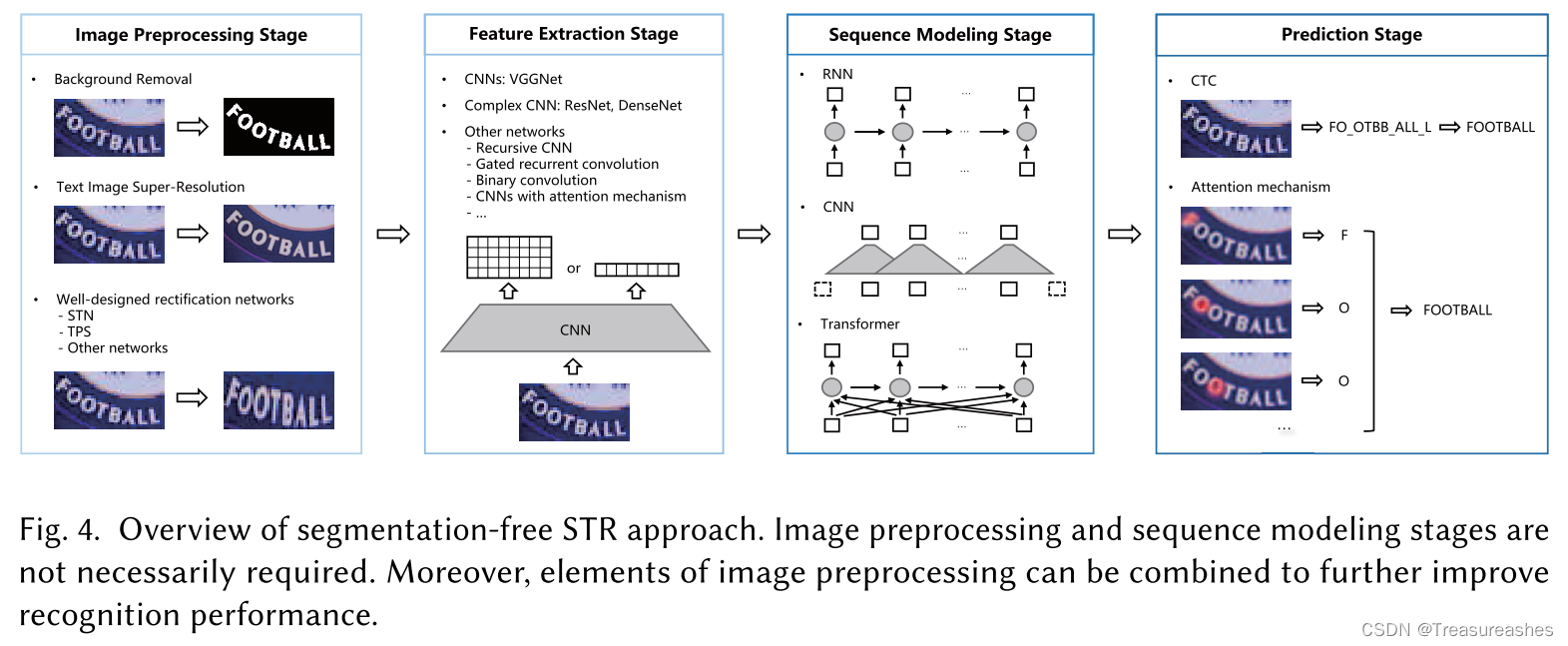
- Image Preprocessing Stage 图像预处理阶段:包括但不限于下述类型,各种方法可以组合使用。
- 背景去除:将文本从背景中分离出来,例如传统的二值化方法(binarization methods)(在文档图像上效果好)、生成对抗网络(GANs)。
- 文本图像超分辨率(Text Image Super-Resolution,TextSR):输出与给定的低分辨率图像一致的合理的高分辨率图像。可以将TextSR方法与识别任务相结合。
- 整流(Rectification):对输入的文本实例图像进行规范化处理,消除失真并减少不规则文本识别的难度 ,例如 spatial transformer network(STN)、Thin-Plate-Spline (TPS)、multi-object rectification network等。为了处理各种畸变,复杂的整流模块是必需的。 但是,此模块太复杂会影响识别算法的速度和内存消耗,应根据需求选择最佳的权衡。 此外,随着不规则文本检测(irregular text detection)的发展,值得重新考虑STR系统是否需要这个模块。
- Feature Representation Stage 特征表示阶段:将输入文本实例图像映射到反映与字符识别相关的属性表征上,同时抑制字体,颜色,大小和背景等不相关的特征。
- 定向梯度直方图(the histogram of oriented gradients,HOG)
- CNN(VGGNet 、ResNet、DenseNet 、Recursive CNN 等)
- 背景去除(background removal)与简单特征提取器(simple feature extractors)的组合
- Sequence Modeling Stage 序列建模阶段序:在一系列字符中捕获上下文信息以供下一阶段预测每个字符,比独立处理每个符号更加稳定和有用。
- RNN-based,例如多双向长期短期记忆(Multiple bidirectional long short term memory, BiLSTM)或LSTM
- 滑动窗口
- CNNs 或 Transformer
- Prediction Stage 预测阶段:从输入文本实例图像的识别特征中估计目标字符串序列。
- 基于Connectionist Temporal Classification(CTC)的方法
- 基于attention机制的方法
- 其它探索及潜在方法:同时应用CTC和注意力机制、聚合交叉熵函数(aggregation cross-entropy function);将场景和合成图像特征与加权动态时间规整(weighted dynamic time warping,wDTW)方法进行匹配;将识别和检索的任务解释为最近邻问题,将单词图像和文本字符串都嵌入到一个公共的向量子空间或欧氏空间中;将STR建模为多分类问题,并设计CNN分类器或将CNN与CRFgraphical模型相结合。
端到端识别系统
给定具有复杂背景的文本图像作为输入,端到端系统将所有文本区域直接转换为字符串序列。 通常,它包括文本检测,文本识别和后处理。
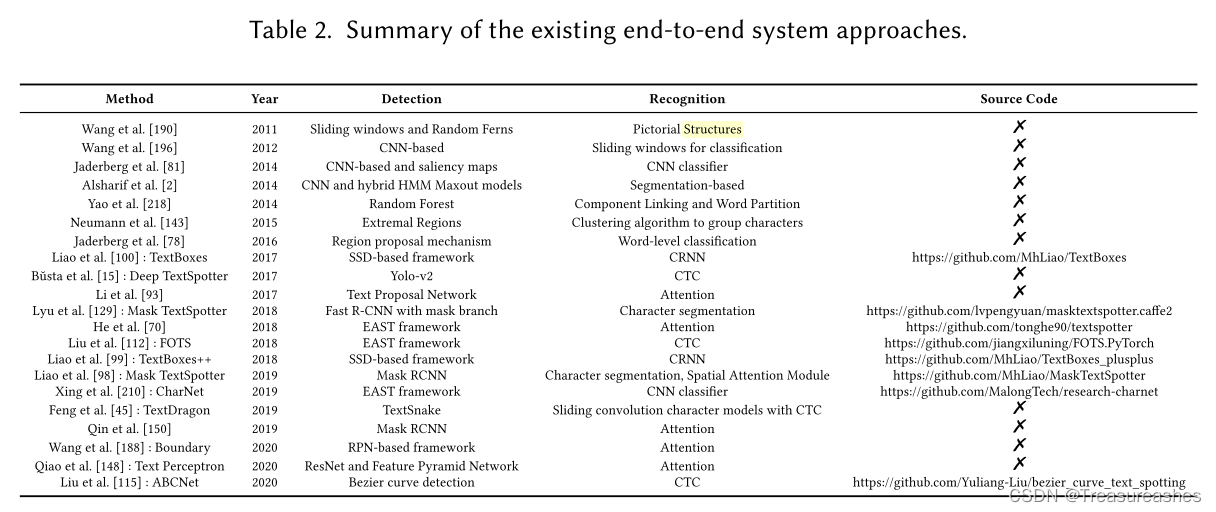
有几个因素促进了端到端系统的出现:i)错误可能以文本检测和识别的级联方式累积,这可能导致很大一部分垃圾预测,而端到端系统可以防止错误的产生以及在训练过程中积累。 ii)文本检测和识别可以共享信息,可以共同优化以提高总体性能。 iii)更易于维护和适应新的领域,而维护具有数据和模型相关性的cascaded pipeline需要大量的工程工作。 iv)具有更快的推理速度和较小的存储需求。
端到端系统存在的困难:i)如何有效地桥接并在文本检测和识别之间共享信息? ii)如何在文本检测和识别之间学习难度和收敛速度的显着差异之间取得平衡? iii)如何改善联合优化?
数据集

讨论和未来方向
- 泛化能力:应适应文本的各种输入,例如不同的大小,形状和字体样式。 此外,应该对环境干扰不敏感,并且能够处理现实世界中的复杂性。
- 评估协议:数据集,先验条件和测试环境的不一致性使得很难公平地比较reported numbers的face value。
- 数据问题:i)合成数据。ii)使用未标记的真实数据。应该重新考虑是否统一训练数据集,然后再用真实数据集进行评估。
- 场景:研究和应用之间仍然存在差距(例如,背景更加复杂,现实世界中的噪音更多),不应局限于几个标准。
- 图像预处理:例如TextSR和背景去除,可以从新的角度极大地减少STR的难度并提高性能。
- 端到端系统:性能与OCR在扫描文档中的性能相比仍然远远落后。
- 语言:大多数识别算法仅针对拉丁文字,尚未广泛研究非拉丁语的识别,例如中文场景文本。
- 安全性:大多数基于深度学习的文本识别器还是很容易受到对抗示例的攻击。
- STR +NLP:NLP和STR的组合可能是各个领域的重要趋势,例如文本VQA,文档理解和信息提取。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









