







基于区域提名的方法
RCNN
以下是R-CNN的主要步骤:
-
区域提名:通过Selective Search从原始图片提取2000个左右区域候选框;
-
区域大小归一化:把所有侯选框缩放成固定大小(原文采用227×227);
-
特征提取:通过CNN网络,提取特征;
-
分类与回归:在特征层的基础上添加两个全连接层,再用SVM分类来做识别,用线性回归来微调边框位置与大小,其中每个类别单独训练一个边框回归器。
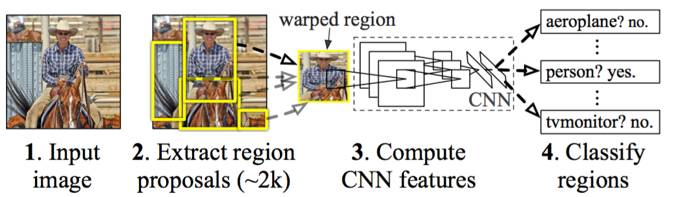
事实上,R-CNN有很多缺点: -
重复计算:R-CNN虽然不再是穷举,但依然有两千个左右的候选框,这些候选框都需要进行CNN操作,计算量依然很大,其中有不少其实是重复计算;
-
SVM模型:而且还是线性模型,在标注数据不缺的时候显然不是最好的选择;
-
训练测试分为多步:区域提名、特征提取、分类、回归都是断开的训练的过程,中间数据还需要单独保存;
-
训练的空间和时间代价很高:卷积出来的特征需要先存在硬盘上,这些特征需要几百G的存储空间;
-
慢:前面的缺点最终导致R-CNN出奇的慢,GPU上处理一张图片需要13秒,CPU上则需要53秒[2]。
SPP-net
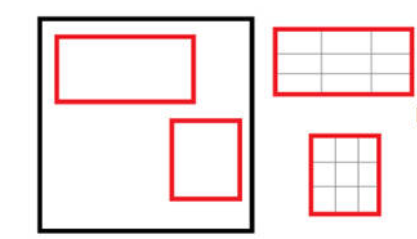
SPP-net[4,19]是MSRA何恺明等人提出的,其主要思想是去掉了原始图像上的crop/warp等操作,换成了在卷积特征上的空间金字塔池化层(Spatial Pyramid Pooling,SPP)为何要引入SPP层 ,主要原因是CNN的全连接层要求输入图片是大小一致的,而实际中的输入图片往往大小不一,如果直接缩放到同一尺寸,很可能有的物体会充满整个图片,而有的物体可能只能占到图片的一角。传统的解决方案是进行不同位置的裁剪,但是这些裁剪技术都可能会导致一些问题出现,比如图7中的crop会导致物体不全,warp导致物体被拉伸后形变严重,SPP就是为了解决这种问题的。

SPP-net的网络结构如图8所示,实质是最后一层卷积层后加了一个SPP层,将维度不一的卷积特征转换为维度一致的全连接输入。

如上图所示,当我们输入一张图片的时候,我们利用不同大小的刻度,对一张图片进行了划分。上面示意图中,利用了三种不同大小的刻度,对一张输入的图片进行了划分,最后总共可以得到16+4+1=21个块,我们即将从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。
- 第一张图片,我们把一张完整的图片,分成了16个块,也就是每个块的大小就是(w/4,h/4);
- 第二张图片,划分了4个块,每个块的大小就是(w/2,h/2);
- 第三张图片,把一整张图片作为了一个块,也就是块的大小为(w,h)
空间金字塔最大池化的过程,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出神经元。最后把一张任意大小的图片转换成了一个固定大小的21维特征(当然你可以设计其它维数的输出,增加金字塔的层数,或者改变划分网格的大小)。
SPP-net做目标检测的主要步骤为:
-
区域提名:用Selective Search从原图中生成2000个左右的候选窗口;
-
区域大小缩放:SPP-net不再做区域大小归一化,而是缩放到min(w, h)=s,即统一长宽的最短边长度,s选自{480,576,688,864,1200}中的一个,选择的标准是使得缩放后的候选框大小与224×224最接近;
-
特征提取:利用SPP-net网络结构提取特征;
-
分类与回归:类似R-CNN,利用SVM基于上面的特征训练分类器模型,用边框回归来微调候选框的位置。
SPP-net解决了R-CNN区域提名时crop/warp带来的偏差问题,提出了SPP层,使得输入的候选框可大可小,但其他方面依然和R-CNN一样,因而依然存在不少问题,这就有了后面的Fast R-CNN。
Fast R-CNN
相对于R-CNN与SPP-net,Fast R-cnn的主要亮点有:Fast R-CNN将借助多任务损失函数,将物体识别和位置修正合成到一个网络中,不再对网络进行分步训练,不需要大量内存来存储训练过程中特征的数据。
Fast R-CNN是要解决R-CNN和SPP-net两千个左右候选框带来的重复计算问题,其主要思想为:
-
使用一个简化的SPP层 —— RoI(Region of Interesting) Pooling层,操作与SPP类似;
-
训练和测试是不再分多步:不再需要额外的硬盘来存储中间层的特征,梯度能够通过RoI Pooling层直接传播;此外,分类和回归用Multi-task的方式一起进行;
-
SVD:使用SVD分解全连接层的参数矩阵,压缩为两个规模小很多的全连接层。
在Fast R-CNN中,作者提出了一个叫做ROI Pooling的网络层,这个网络层可以把不同大小的输入映射到一个固定尺度的特征向量。ROI Pooling层将每个候选区域均匀分成M×N块,对每块进行max pooling。将特征图上大小不一的候选区域转变为大小统一的数据,送入下一层。这样虽然输入的图片尺寸不同,得到的feature map(特征图)尺寸也不同,但是可以加入这个神奇的ROI Pooling层,对每个region都提取一个固定维度的特征表示,就可再通过正常的softmax进行类型识别。
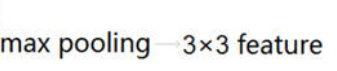
Fast R-CNN的主要步骤如下: -
特征提取:以整张图片为输入利用CNN得到图片的特征层;
-
区域提名:通过Selective Search等方法从原始图片提取区域候选框,并把这些候选框一一投影到最后的特征层;
-
区域归一化:针对特征层上的每个区域候选框进行RoI Pooling操作,得到固定大小的特征表示;
-
分类与回归:然后再通过两个全连接层,分别用softmax多分类做目标识别,用回归模型进行边框位置与大小微调。
端到端的方法
yolo v1
- YOLO V1最核心的思想就是把图片分成S x S个网格(grid cell),然后每个网格负责检测“一个”框和类别,最后通过概率和NMS过滤,得到最终的结果。
- S=7,因为网格的数目需要跟最后的特征图尺寸一一对应,最后的特征图大小为 7 x 7,所以网格的数目也就是 S x S = 7 x 7。以预测的特征图大小为 7 x 7,有49个向量,每个向量都要去预测“框”和“类别”,那么训练的时候,我们需要为每个向量分配类别以及是否需要负责预测框,如何分配,我们需要把49个点映射回原图,正好形成7 x 7个网格,然后根据每个网格跟Ground Truth之间的关系,来做后续分配
- 如何选择Grid Cell预测框?
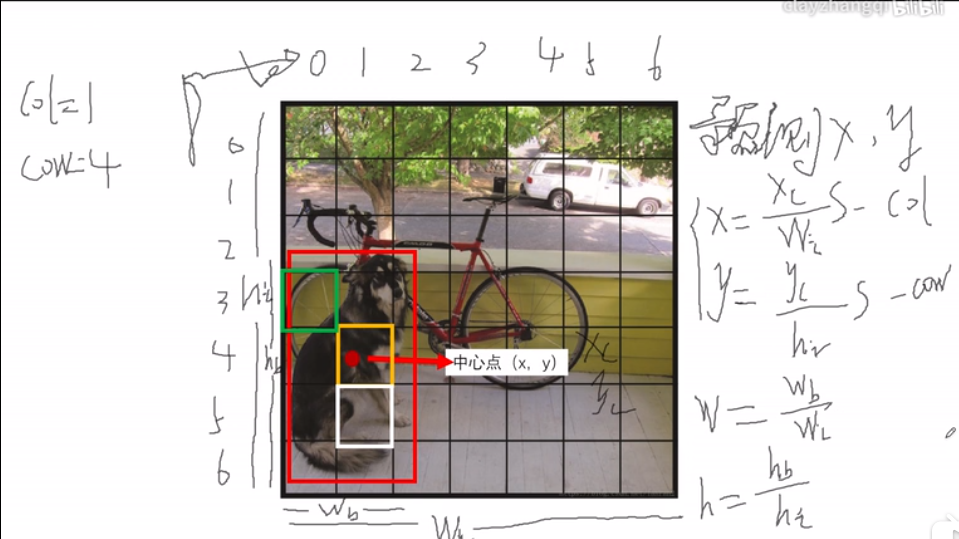
- 我们知道每个Grid Cell会对应一组向量,用来预测,那么选择哪个Grid Cell来预测框呢?通俗一些,就是哪些Grid Cell是正例,哪些是负例。,物体的“中心”落在哪个Grid Cell中,哪个Grid Cell就负责训练这个Ground Truth。
- 下面张图,中心点被标出来了,其中“橘黄Grid Cell”包括了Ground Truth中心点,那么它就是所谓的正例,那么“绿Grid Cell”和“白Grid Cell”的标签(Label)是什么呢?这里就是与RPN最大的不同之处了,这里有且只有一个Grid Cell是正例,其余的就算与Ground Truth IOU很大,也是负例,所以“绿Grid Cell”和“白Grid Cell”Label为负,所以也就不用负责训练框了。

- 选好了Grid Cell,下一步计算x,y, w, h(用来预测和训练
- 根据原文我们可以确定几点,第一:x,y指的是中心点,是物体框的中心点,不是Grid Cell的中心点;第二,w,h指的是物体框的宽高;第三,x, y, w, h都在0-1之间。我们在训练的时候,Loss Function计算的预测值与实际值的L2-Loss,预测值是通过网络,隐藏在30维向量中了(7 x 7 x 30)
- 计算过程如下图所示, x,y最后的值是相对Grid Cell的偏移,但是是相对于Grid Cell的中心点还是左上角点的偏移
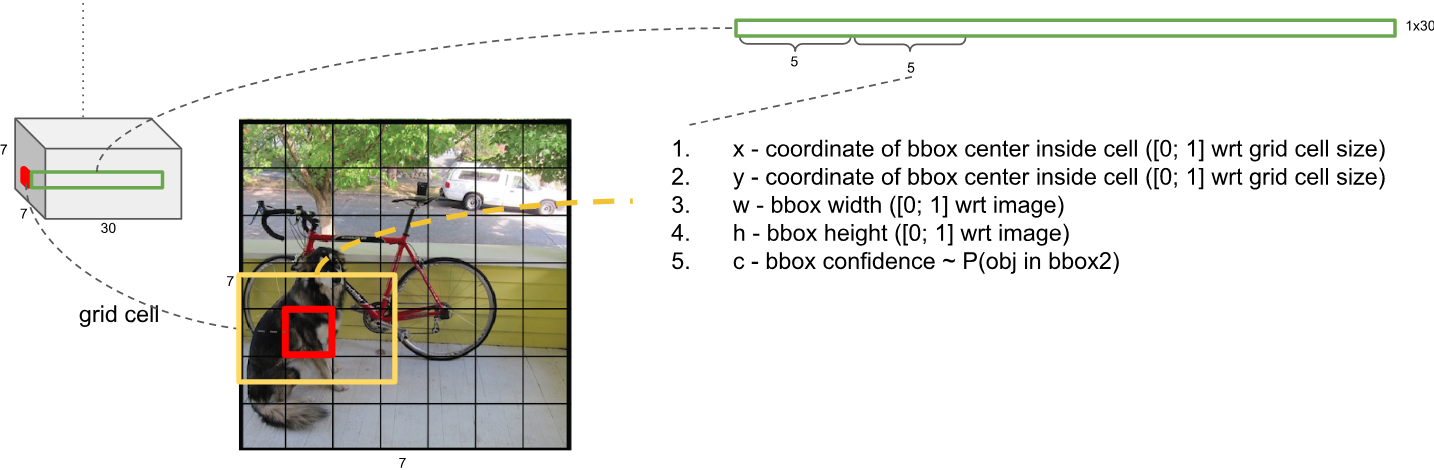
- 最后输出的30维向量,代表什么
- 一共预测98个框,那么我们可以算出30维向量中是包含了2个框的信息,也就是两组(x, y, w, h)。由于是在Pascal VOC上训练的,所以还有20个类别信息,这样组合发现只有28个值,。。。难道大家就没有疑问,YOLO V1是如何区分背景的么?YOLO V1不仅预测了框的x, y, w, h,还预测了框的分数,用来判断是不是框,所以30维向量向量包括2组( x, y, w, h, score) + 20个类别概率。
- 框的分数是怎么算的
- YOLO V1计算了一个所谓的IOU分数,IOU指的是预测的框与实际框的IOU,这样在训练的时候,我们需要实时的计算这个IOU,作为输入到Loss Function中的“目标”,与预测的IOU分数做IOU误差Loss,举个例子,第一次迭代,网络会输出一个预测框P1,对应的真实框为G,程序会计算P1和G的IOU,然后继续做Loss。也是说yolo回归预测了box的IOU值。

- YOLO V1计算了一个所谓的IOU分数,IOU指的是预测的框与实际框的IOU,这样在训练的时候,我们需要实时的计算这个IOU,作为输入到Loss Function中的“目标”,与预测的IOU分数做IOU误差Loss,举个例子,第一次迭代,网络会输出一个预测框P1,对应的真实框为G,程序会计算P1和G的IOU,然后继续做Loss。也是说yolo回归预测了box的IOU值。
- 为什么每个输出有两个框,实际却只负责一个框
其中,绿色的框P1与白色的框P2是网络预测的框,而红色的框G是真实值,YOLO V1会计算P1与G的IOU1,以及P2与G的IOU2,然后比较哪个IOU大,比如IOU2更大,那么P2的信息会输入到Loss Function中,P1被忽略掉??并不是100%被忽略,如果IOU1小于一个阈值,会作为负例,压向0值。















 5433
5433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









