import nltk
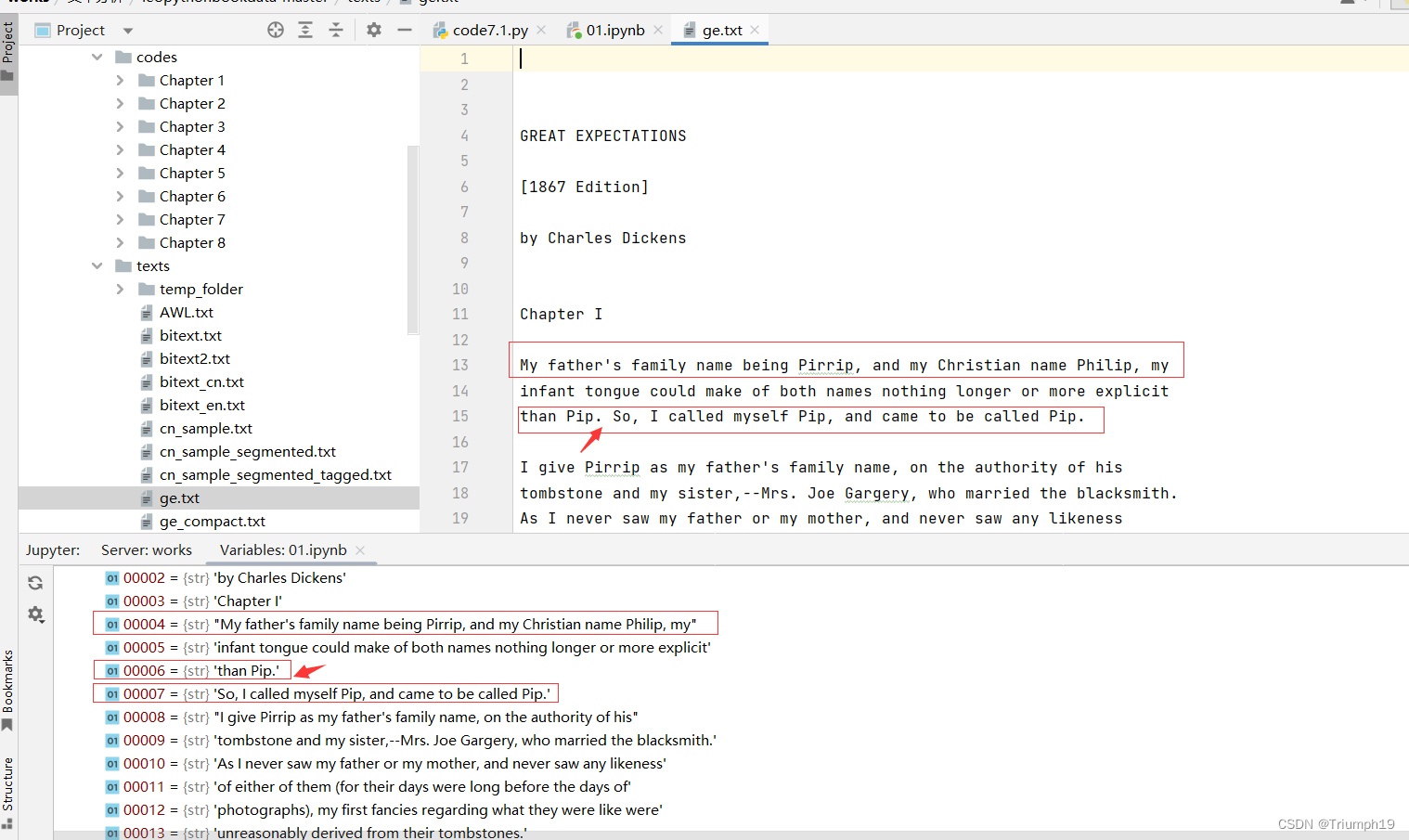
string = "My father's name being Pririp,and my Christian name Philip,my infant tongue could make of both names nothing longer or more explicit than Pip. So,I called myself Pip,and came to be called Pip."
# 载入和定义分词器(sentence splitter) sent_tokenizer
sent_tokenizer = nltk.load('tokenizers/punkt/english.pickle')
# 利用分词器中的sent_tokenizer.tokenize()函数来分句
sents = sent_tokenizer.tokenize(string)
sents
打印的结果如下:
["My father's family name being Pirrip, and my Christian name Philip, my infant tongue could make of both names nothing longer or more explicit than Pip.", 'So, I called myself Pip, and came to be called Pip.']
#%%
import nltk
string = "My father's name being Pririp,and my Christian name Philip,my infant tongue could make of both names nothing longer or more explicit than Pip. So,I called myself Pip,and came to be called Pip."
# 载入和定义分词器(sentence splitter) sent_tokenizer
string_tokenized = nltk.word_tokenize(string)
string_tokenized
# 下面对分词后列表中的字符串进行分词处理
# 结果存储到all_words 列表中
all_words =[]for sent in all_sentences:
sent_tokenized = nltk.word_tokenize(sent)for word in sent_tokenized:
all_words.append(word.lower()) #word.lower是将所有单词都用小写模式
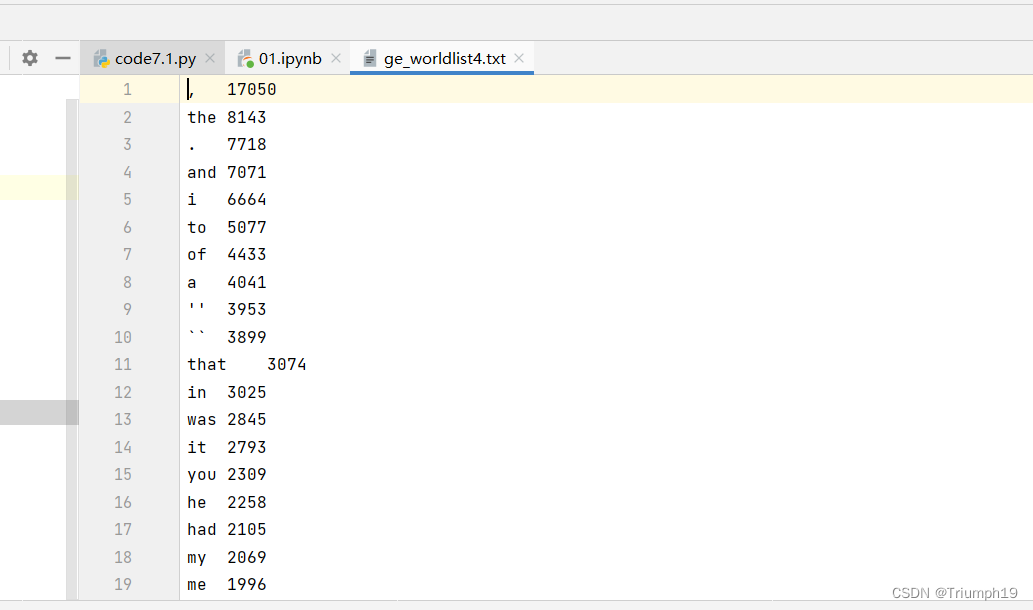
(3)词频统计
# 下面对分词后列表中的字符串进行词频统计
# 结果存储在wordlist_freq字典中
wordlist_freq ={}for word in all_words:'''
下面的if——else语句的功能是:判断这个word是否在字典中,如果word已经是字典的一个key值,那么
就将这个key值对应的values值增加1;如果word不是字典的一个key值,那么就将这个word作为新的
一个key值,并将对应的values赋值为1'''
if word in wordlist_freq.keys():
wordlist_freq[word]+=1else:
wordlist_freq[word]=1
# 下面对词频字典按词频逆序排序
# 结果储存到pairs_reversed列表中
pairs_reversed =[]for p in wordlist_freq.items():
pairs_reversed.append([p[1],p[0]])
pairs_reversed_sorted =sorted(pairs_reversed,reverse=True)
# 将逆序词频表写入到file_out中
for p in pairs_reversed_sorted:
file_out.write(p[1]+'\t'+str(p[0])+'\n') #对于逆序表中的每一个列表,p[1]是字符串,p[0]是数字
file_in.close()
file_out.close()
























 640
640











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









