






引言:
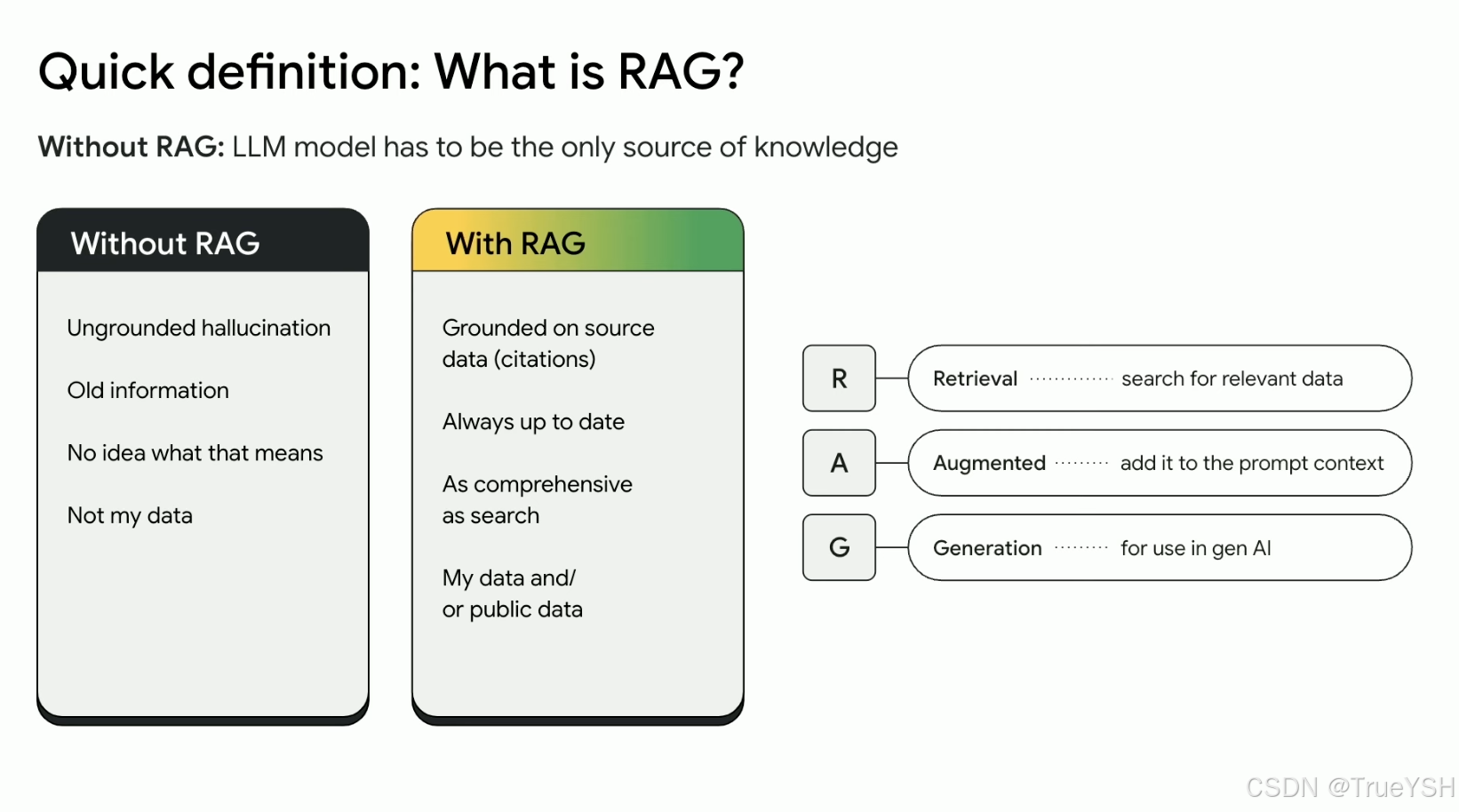
在自然语言处理技术快速发展的当下,检索增强生成(RAG, Retrieval-Augmented Generation)模型在问答系统、文档摘要等多个领域展现出显著优势。文中讲解如何通过一系列优化措施提升RAG模型的性能,特别是在文本切分、查询转写、多路召回及重排等方面的具体策略,以期为相关领域的研究和实践提供有价值的参考。
1. 文本切分优化
1.1 中英文及简繁体区分 为了提高文本向量转化的准确性,中文文本与英文文本分开处理,并进一步区分为简体字和繁体字文本。不同语言版本采用对应的预训练模型进行向量化,确保每个语种都能得到最合适的表示。
1.2 语义完整性保障
- 重叠设置:在文本切分时,引入了一定比例的重叠字数,有效降低了完整句子被拆分的风险,从而保证了语义的连贯性。
- 递归检索切分:采取递归方式逐步细化文本单位——先按段落划分,若段落过长则按句切分;句子过长时再依据标点符号进一步细分;必要时根据固定字数进行最后的切分。这种多层次的切分方法有助于保持文本结构的完整性。
1.3 标题与摘要辅助 为提升检索精度,在每个文本片段中加入对应的一级、二级甚至三级标题信息,并为其生成简短的摘要。这些附加信息不仅丰富了文本内容,还增强了检索结果的相关性。
2. 文本检索准确性提升
2.1 问题映射与相似度匹配 通过大模型生成与每个文本块关联的问题集,并将用户输入的问题与之进行相似度匹配,可以更精准地定位到相关的文本块。随后,利用大模型整理出最终答案,提升了回答的质量和准确性。
2.2 父子块分层检索 引入父块和子块的概念,首先对整个文章进行宏观分割形成若干父块,再对每个父块内部细分成多个子块。检索过程中,基于父块进行快速筛选,确定目标区域后再深入查找具体的子块。此外,给每个文本块添加主题词和上下文摘要,充实了文本信息,提高了检索效率。
3. Query转写优化
针对用户提问模糊或信息不足的情况,提出了以下几种query转写策略:
- 语义重构:使用大模型重新表述原始问题,在不改变其核心意义的前提下,尝试用不同的表达形式来增加检索成功的可能性。
- 关键词匹配:提取用户问题中的关键实体词并与检索结果中的关键词对比,从多角度挖掘潜在的相关文档。
- 上下文感知:结合对话历史,自动补充或修正用户的后续提问,例如将“天津呢?”转化为“天津的面积是多少?”。
- 任务分解:对于复合型问题,将其拆解成若干个独立的小问题分别处理,避免因复杂性导致检索失败。
- 范围扩展:当直接提问难以获得理想答案时,适当放宽查询条件,如询问“马云的教育经历”而非具体年份的学校名称,以此提高检索成功率。
4. 多路召回策略
为确保检索结果的多样性和全面性,设计了三种不同的召回路径:
- M3E模型向量化:基于m3e模型对文本片段进行向量化处理,每段文本附带主题词和上下文摘要,选取前10个最相关的文本块。
- TF-IDF特征提取:利用TF-IDF算法计算文本特征向量,同样附带额外信息并选择排名靠前的文本块。
- 父子块联合检索:优先考虑小块的精确匹配,但实际返回的是包含该小块的父块,既能保证检索精度又能提供足够的上下文支持。
5. Rerank重排优化
采用多种重排算法(如BM25、余弦相似度、欧氏距离等),综合评估候选文本块的相关性,尽量将可能包含答案的内容排在前列。特别地,MMR(Maximum Marginal Relevance)算法的应用,能够在保证多样性的同时最大化相关度,改善了检索结果的质量。
6. 其他优化措施
- 专用词向量模型:尽管自定义训练的词向量模型效果有限,推荐根据特定领域的需求调整现有模型参数,或者直接选用经过充分验证的高质量预训练模型(如m3e)。
- 向量检索改进:除了传统的夹角余弦相似度外,建议采用MMR等更先进的检索算法,以获得更加准确且多样化的检索结果。
应用实例:构建智能法律咨询系统
为了更好地理解如何应用上述优化策略,这里做了一个具体的例子——构建智能法律咨询系统。
技术选型与架构设计
技术栈:
- 模型选择:使用预训练的RAG模型作为核心组件,结合领域专用的法律大模型(如LegalBERT)来提升专业领域的理解能力。
- 检索引擎:采用高效的向量检索库(如FAISS、Annoy)以加速相似度计算。
- 后端框架:基于Flask/Django搭建RESTful API服务,前端采用React/Vue等现代前端框架实现用户界面。
架构图:
[用户界面] --> [API网关] --> [RAG模型] --> [向量数据库] --> [法律文档库]
文本切分优化代码示例
import re
from langdetect import detect
from transformers import AutoTokenizer
# 初始化tokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
def split_text(text, overlap=0.1):
"""递归文本切分函数"""
sentences = re.split(r'(?<=[。!?])', text) # 按照中文句号、感叹号、问号分割
if len(sentences) > 1:
return sentences
elif len(text) > 500: # 如果单句长度超过500字符,则按逗号进一步分割
sub_sentences = re.split(r',', text)
return sub_sentences
else:
return [text]
def recursive_split(text, overlap=0.1):
"""递归文本切分"""
chunks = []
sentences = split_text(text)
for i in range(0, len(sentences), max(1, int(len(sentences) * (1 - overlap)))):
chunk = ''.join(sentences[i:i + max(1, int(len(sentences) * (1 - overlap)))])
if len(chunk) > 100: # 如果单块长度超过100字符,则进一步分割
chunks.extend(recursive_split(chunk, overlap))
else:
chunks.append(chunk)
return chunks
# 示例使用
example_text = "这是一段较长的中文文本,包含了多个句子。每个句子都由不同的标点符号分隔。"
chunks = recursive_split(example_text)
print(chunks)Query转写优化代码示例
from transformers import pipeline
# 初始化query转写pipeline
query_rewriter = pipeline('text2text-generation', model='t5-small')
def rewrite_query(query):
"""语义重构用户问题"""
rewritten_queries = query_rewriter(f"paraphrase: {query}", max_length=50, num_return_sequences=3)
return [q['generated_text'] for q in rewritten_queries]
# 示例使用
user_query = "北京面积多大?"
rewritten_queries = rewrite_query(user_query)
print(rewritten_queries)多路召回策略代码示例
from sentence_transformers import SentenceTransformer, util
# 初始化向量模型
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
def retrieve_texts(query, texts, top_k=10):
"""基于M3E模型的文本召回"""
embeddings = model.encode(texts, convert_to_tensor=True)
query_embedding = model.encode(query, convert_to_tensor=True)
hits = util.semantic_search(query_embedding, embeddings, top_k=top_k)
return [texts[hits[0][i]['corpus_id']] for i in range(top_k)]
# 示例使用
documents = ["法律条款A", "法律条款B", "法律条款C"]
retrieved_texts = retrieve_texts("合同纠纷解决办法", documents)
print(retrieved_texts)总结:
通过详细的实施步骤和代码示例,可以在构建智能法律咨询系统的过程中有效地应用RAG优化与知识库增强策略。这种方法提升了系统的性能和用户体验,确保其在法律领域的专业性和可靠性。当前的方法也存在一些局限性。例如,虽然多语言支持有所改善,但在处理非常见语言或方言时仍面临挑战。此外,隐私保护机制依赖于加密技术和权限管理,但在面对高级攻击手段时可能存在风险。
Author:余胜辉
参考文献:
Landmark Embedding: A Chunking-Free Embedding Method For Retrieval Augmented Long-Context Large Language Models
http://arxiv.org/abs/2402.11573?spm=5176.28103460.0.0.297c5d2784qgNw&file=2402.11573
Grounding Language Model with Chunking-Free In-Context Retrieval
https://arxiv.org/abs/2402.09760?spm=5176.28103460.0.0.297c5d2784qgNw&file=2402.09760

















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









