






前言
应课程要求,需要做map-matching,现记录学习及实践过程。
主要学习了两份代码,本文重点在第二份代码上。
- 源码链接
数据介绍:腾云阁高精度车辆追踪算法大赛
原代码的计算原理是基于几何和图论的
主要是点到线段的匹配,深度优先遍历(DFS),和Dijkstra算法
原代码是在python2.7的环境下运行的,我对此进行了一些修改,在python3.8的Notebook下运行成功,并且增加了一定程度的注释,需要的可以下载 - 源码链接
基于Newson, Krumm (2009): "Hidden markov Map Matching through noise and sparseness"的隐马尔可夫模型进行地图匹配
准备工作
为了在jupyter里顺利运行代码,我们需要执行以下几个步骤。
- 安装Anaconda3
- 安装ARCGIS
(1)下载LicenseManager并打开,在ArcGIS License Server Adminstrator点击stop关闭服务后,点击OK退出
(2)打开ArcGIS 10.4.1 Crack\ArcGIS\License10.4\bin,将其中的两个破解文件复制到安装路径\ArcGIS 10.4\License 10.4\License10.4\bin中
(3)点击ArcGIS_Desktop_1041_zh_CN_151738.exe文件,安装arcgis软件,会先安装py27,再安装软件
(4)安装完成之后会有一个弹框,选择 Advanced(ArcInfo)浮动版,设置管理器为 localhost
(5)打开ArcGIS 10.4.1 Crack\ArcGIS\bin,将其中的破解文件复制到安装路径\ArcGIS 10.4\License10.4\bin中
(6) 安装完成,打开ArcGIS Administrator,显示永久表示破解版安装成功 - 配置Anaconda3
(1)将ArcGIS的目录C:\Python27\ArcGIS10.1\Lib\site-packages\Desktop10.1.pth直接拷贝到Anaconda3的目录里(C:\Users\xxx\anaconda3\Lib\site-packages)和Anaconda3的虚拟环境下(C:\Users\xxx\anaconda3\envs\py27\Lib\site-packages)
(2)打开Anaconda Prompt (anaconda3),输入以下内容,如果执行出来arcpy还是有错误,可以删除环境,重新装一遍
set CONDA_FORCE_32BIT=1 //设置环境为32位,改回64位:set CONDA_FORCE_32BIT=
conda create -n py27 python=2.7 //创建一个使用python2.7的名叫py27的环境
activate py27 //激活环境
pip install jupyter notebook //安装jupyter、numpy、networkx、gdal、matplotlib
pip install numpy
pip install networkx
conda install gdal
pip install matplotlib //如果不画图,可以不安装
pip install ipykernel //将环境写入notebook的kernel中
python -m ipykernel install --user --name py27
jupyter notebook //打开jupyter
- 执行readme的内容
(1)执行\mapmatching-master\dist\mapmatcher-1.0.win32.exe,注意选择的路径应该是ARCGIS的路径,而不是Anaconda的
(2)打开ArcCatalog,点击文件,选择连接到文件夹,连接代码文件,即可查看shp文件,右边第二个是预览,左下角可以选择图或表的形式
(3)mapMatch.pyt是原作者打包好此代码制作的工具箱,可以在ArcCatalog中使用,但是由于我并不擅长ARCGIS,所以并没追究他无法使用的原因
(4)ARCGIS的官方帮助文档,安装的同时也有Help文档,for help是英文版本,for 帮助是中文版本,善于使用搜索了解代码的含义
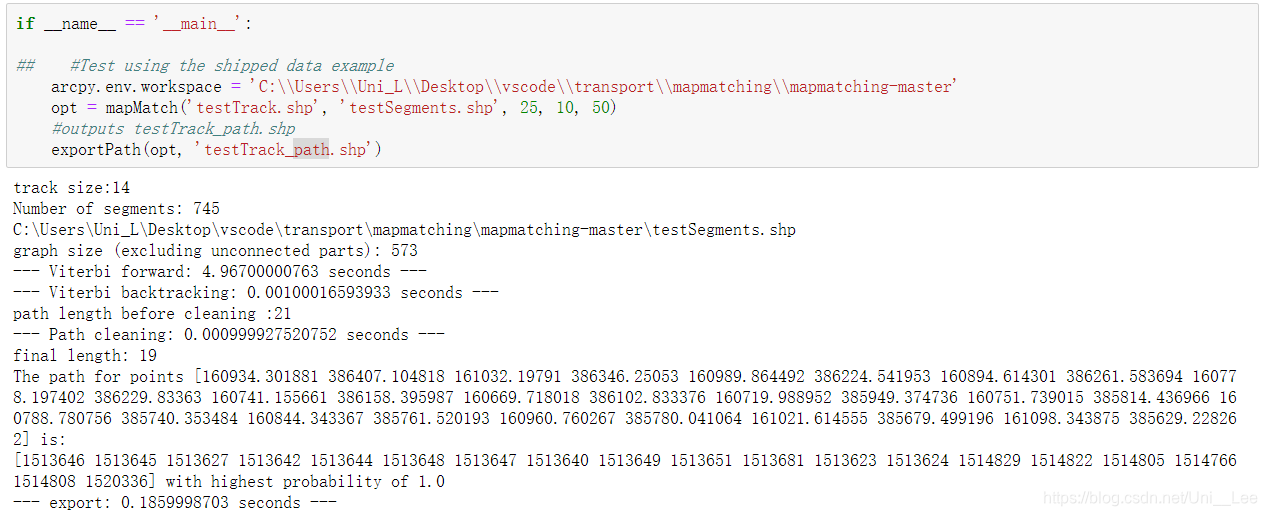
(5)正式运行代码的时候,需要修改为解压文件的路径,注意这里不能把shp文件复制到桌面上,会导致读取失败,其次需要删除解压出来的testTrack_pth文件,或者修改exportPath函数下的outname后的’_pth’为’_path’,附上运行成功的截图
//读取文件路径设置
arcpy.env.workspace = 'C:\\Users\\Uni_L\\Desktop\\mapmatching\\mapmatching-master'
//输出文件名称设置
outname = (os.path.splitext(os.path.basename(trackname))[0][:9])+'_path'
论文笔记
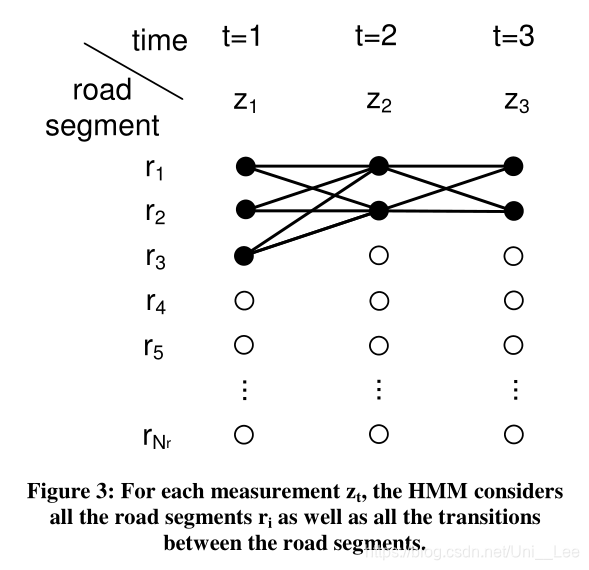
ri:road sergments,i=1,……,Nr
zt:2D latitude location measurement
P(zt|ri):measurement/emission probability
the probability that zt would be observed if the vehicle were on the road segment ri
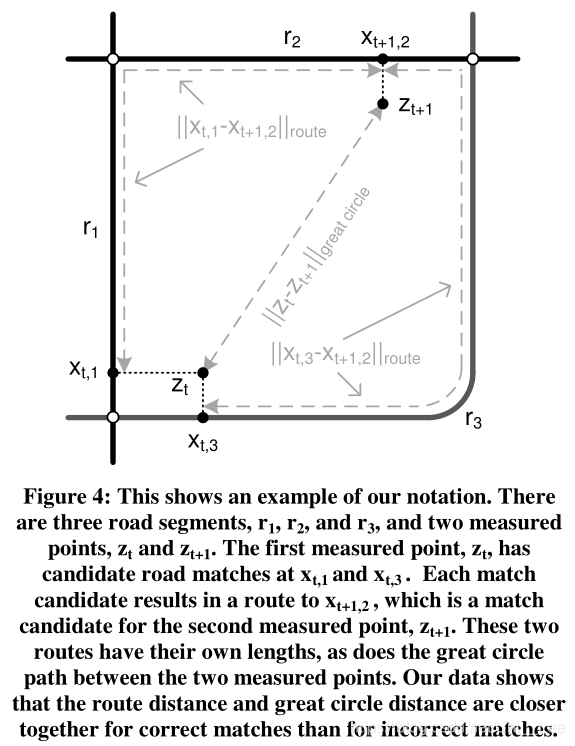
xt,i:the closest point on ri for zt
GPS noise:zero-mean Gaussian model
P(zt|ri)=(sqrt(2*π)δz)-1 exp(-0.5(||zt-zt+1||greatcircle/δz)2)
δz:the standard deviation of GPS measurement
show the trust in the location measurement
δz=1.4826mediant(||zt-xt,i||greatcircle)
πi:initial state probability,i=1,……,Nr
πi=P(z1|ri) //probability of the vehivle’s first road
transition probability:probability of moving between two road
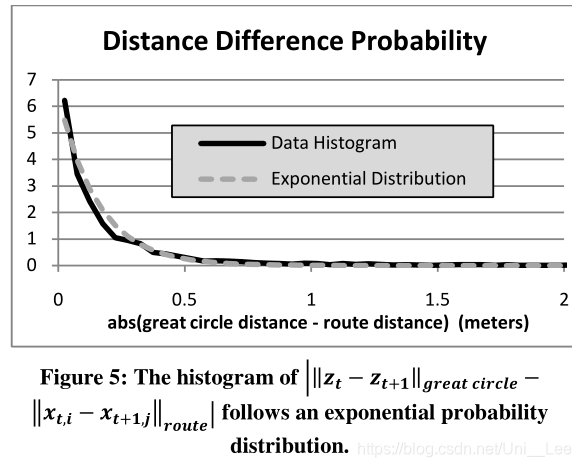
the histogram of the difference between ||xt,i-xt+1,j||route and ||zt-zt+1||greatcircle fits the model P(dt)=β-1 exp(-dt/β)
where dt=| ||xt,i-xt+1,j||route - ||zt-zt+1||greatcircle |
β:show more tolerance of non-direct routes
β=ln(1/2)mediant (||zt-zt+1||greatcircle - ||xt,i-xt+1,j||route)
break:
1、no condicate;P(z1|xt,i) =0 if xt,i>200m
2、||xt,i-xt+1,j||route - ||zt-zt+1||greatcircle >2000m
3、speed calculated is > 50m/s
when break is detected between t and t+1
then remove zt and zt+1
when zt- zt+180s are removed
then split the data into seperate trips
维特比算法介绍
代码解读
# 以下代码排版为更好的解释,如要运行请使用源代码更佳
if __name__ == '__main__':
# 空间,相对路径
arcpy.env.workspace = 'C:\\Users\\Uni_L\\Desktop\\vscode\\transport\\mapmatching\\mapmatching-master'
track = 'testTrack.shp' # GPS轨迹数据
segments = 'testSegments.shp' # 路网数据
decayconstantNet = 30
decayConstantEu = 10
maxDist = 50
addfullpath = True
# 确保参数是浮点类型
decayconstantNet = float(decayconstantNet)
decayConstantEu = float(decayConstantEu)
maxDist= float(maxDist)
#gest start time
start_time = time.time()
#this array stores, for each point in a track, probability distributions over segments, together with the (most probable) predecessor segment taking into account a network distance
V = [{}]
#get track points, build network graph (graph, endpoints, lengths) and get segment info from arcpy
points = getTrackPoints(track, segments) # 得到轨迹点
r = getSegmentInfo(segments) # 得到网路图
endpoints = r[0] # 点的ID
lengths = r[1] # 长度
graph = getNetworkGraph(segments,lengths)
pathnodes = [] #set of pathnodes to prevent loops
# 我自己添加的画图代码
G = nx.Graph()
G = graph
nx.draw(G,with_labels=False,node_size=2)
plt.show()

def getTrackPoints(track, segments):
"""
将轨迹形状文件转换为点几何图形列表,并重新投影到网络文件的平面RS
"""
trackpoints = []
if arcpy.Exists(track):
for row in arcpy.da.SearchCursor(track, ["SHAPE@"]):
# 读取文件每一行的内容,在ArcCatalog中可以预览表的内容帮助理解
#make sure track points are reprojected to network reference system (should be planar)
geom = row[0]
#geom = row[0].projectAs(arcpy.Describe(segments).spatialReference)
trackpoints.append(row[0])
print 'track size:' + str(len(trackpoints))
return trackpoints
else:
print "Track file does not exist!"
def getSegmentInfo(segments):
"""
建立字典以查找网段的端点(仅当networkx图形按节点标识边时才需要)
"""
if arcpy.Exists(segments):
cursor = arcpy.da.SearchCursor(segments, ["OBJECTID", "SHAPE@"])
endpoints = {}
segmentlengths = {}
for row in cursor:
endpoints[row[0]]=((row[1].firstPoint.X,row[1].firstPoint.Y), (row[1].lastPoint.X, row[1].lastPoint.Y))
segmentlengths[row[0]]= row[1].length
del row
del cursor
print "Number of segments: "+ str(len(endpoints))
#prepare segment layer for fast search
arcpy.Delete_management('segments_lyr')
arcpy.MakeFeatureLayer_management(segments, 'segments_lyr')
return (endpoints,segmentlengths) # 返回起点和终点坐标,返回该路段长度
else:
print "segment file does not exist!"
def getNetworkGraph(segments,segmentlengths):
"""
从网络文件构建networkx图形,包括从arcpy获取的段长度。
它选择网络中最大的连接组件(以防止在未连接的部分之间路由错误)
"""
# 生成GDAL能够读取文件的完整网络路径
path =str(os.path.join(arcpy.env.workspace,segments))
print path
if arcpy.Exists(path):
g = nx.read_shp(path)
# 生成最大连通子图
sg = list(nx.connected_component_subgraphs(g.to_undirected()))[0]
print "graph size (excluding unconnected parts): "+str(len(g))
# 获取每个路段的长度,并将其作为属性附加到图形中的边
for n0, n1 in sg.edges():
oid = sg[n0][n1]["OBJECTID"]
sg[n0][n1]['length'] = segmentlengths[oid]
return sg
else:
print "network file not found on path: "+path
# 初始化第一个点 即求解π~i~
sc = getSegmentCandidates(points[0], segments, decayConstantEu, maxDist)
for s in sc:
V[0][s] = {"prob": sc[s], "prev": None, "path": [], "pathnodes":[]}
def getSegmentCandidates(point, segments, decayConstantEu, maxdist=50):
"""
返回具有先验概率的最接近的候选段
基于线段与点的最大空间距离
"""
p = point.firstPoint # 获取点几何体的坐标
#print "Neighbors of point "+str(p.X) +' '+ str(p.Y)+" : "
# 选择最大距离内的所有线段
arcpy.SelectLayerByLocation_management ("segments_lyr", "WITHIN_A_DISTANCE", point, maxdist)
candidates = {}
# 通过这些计算距离,概率,并将它们存储为候选
cursor = arcpy.da.SearchCursor('segments_lyr', ["OBJECTID", "SHAPE@"])
row =[]
for row in cursor:
feat = row[1]
# 计算空间距离
dist = point.distanceTo(row[1])
# 计算相应的概率,大概就是距离越远,概率越小
candidates[row[0]] = getPDProbability(dist, decayConstantEu)
del row
del cursor
#print str(candidates)
return candidates
def getPDProbability(dist, decayconstant = 10):
"""
给定点和线段之间一定距离,点位于线段上的概率
这需要参数化
用指数衰减函数化差为概率
"""
decayconstant= float(decayconstant)
dist= float(dist)
try:
p = 1 if dist == 0 else round(1/exp(dist/decayconstant),4)
except OverflowError:
p = round(1/float('inf'),2)
return p
# 维特比算法,本质是递推
# 添加了print,用来帮助理解代码框架
for t in range(1, 3):
V.append({})
# 存储以前的候选段
lastsc = sc
# 获取候选线段及其先验概率(基于当前点t的欧氏距离)
sc = getSegmentCandidates(points[t], segments, decayConstantEu, maxDist)
for s in sc:
max_tr_prob = 0
prev_ss = None
path = []
for prev_s in lastsc:
# 确定从先前候选到s的最大网络转移概率,得到相应的网络路径
pathnodes = V[t-1][prev_s]["pathnodes"][-10:]
n = getNetworkTransP(prev_s, s, graph, endpoints, lengths, pathnodes, decayconstantNet)
print("-----------------")
np = n[0] # 这里存储 transition probability
tr_prob = V[t-1][prev_s]["prob"]*np
# 这将选择最可能的前置候选对象及其路径
if tr_prob > max_tr_prob:
max_tr_prob = tr_prob
prev_ss = prev_s
path = n[1]
if n[2] != None:
pathnodes.append(n[2])
# 候选的最终概率是先验概率和网络转移概率的乘积
max_prob = sc[s] * max_tr_prob
V[t][s] = {"prob": max_prob, "prev": prev_ss, "path": path, "pathnodes":pathnodes}
print("================")
# 现在最大值标准化所有p值,以防止用完数字
maxv = max(value["prob"] for value in V[t].values())
maxv = (1 if maxv == 0 else maxv)
for s in V[t].keys():
V[t][s]["prob"]=V[t][s]["prob"]/maxv
def getNetworkTransP(s1, s2, graph, endpoints, segmentlengths, pathnodes, decayconstantNet):
"""
返回从段s1到段s2的转移概率,基于段的网络距离以及相应的路径
s1是之前的候选段,s2是此时的候选段
"""
subpath = []
s1_point = None
s2_point = None
if s1 == s2:
dist = 0
else:
# 获取段标识符的边(端点的元组)
s1_edge = endpoints[s1]
s2_edge = endpoints[s2]
s1_l = segmentlengths[s1]
s2_l = segmentlengths[s2]
# 这将确定彼此最接近的两个线段的线段端点
minpair = [0,0,100000]
for i in range(0,2):
for j in range(0,2):
d = round(pointdistance(s1_edge[i],s2_edge[j]),2)
if d<minpair[2]:
minpair = [i,j,d]
s1_point = s1_edge[minpair[0]]
s2_point = s2_edge[minpair[1]]
print("s1_edge")
print(s1_edge)
print("s2_point")
print(s2_point)
## if (s1_point in pathnodes or s2_point in pathnodes): # Avoid paths reusing an old pathnode (to prevent self-crossings)
## dist = 100
## else:
if s1_point == s2_point:
#If segments are touching, use a small network distance
dist = 5
else:
try:
# 在图上计算最短路径(使用段长度),其中段端点是节点,段是(无向)边
if graph.has_node(s1_point) and graph.has_node(s2_point):
dist = nx.shortest_path_length(graph, s1_point, s2_point, weight='length')
path = nx.shortest_path(graph, s1_point, s2_point, weight='length')
#get path edges
path_edges = zip(path,path[1:])
#print "edges: "+str(path_edges)
subpath = []
# 得到path里各个路段的ID
for e in path_edges:
oid = graph[e[0]][e[1]]["OBJECTID"]
subpath.append(oid)
print("subpath")
print(subpath)
#print "oid path:"+str(subpath)
else:
#print "node not in segment graph!"
dist = 3*decayconstantNet #600
except nx.NetworkXNoPath:
#print 'no path available, assume a large distance'
dist = 3*decayconstantNet #700
#print "network distance between "+str(s1) + ' and '+ str(s2) + ' = '+str(dist)
return (getNDProbability(dist,decayconstantNet),subpath,s2_point)
#opt is the result: a list of (matched) segments [s1, s2, s3,...] in the exact order of the point track: [p1, p2, p3,...]
# 维比特算法的终止部分
opt = []
# 在track末端获得最大概率
max_prob = max(value["prob"] for value in V[-1].values())
previous = None
if max_prob == 0:
print " probabilities fall to zero (network distances in data are too large, try increasing network decay parameter)"
# 获取最可能的结束状态及其回溯
for st, data in V[-1].items():
if data["prob"] == max_prob:
opt.append(st)
previous = st
break
## print " previous: "+str(previous)
## print " max_prob: "+str(max_prob)
## print " V -1: "+str(V[-1].items())
# 跟踪回溯直到第一次观测,找出最可能的状态和相应的路径
for t in range(len(V) - 2, -1, -1):
# 获取上一段和最可能的上一段之间的子路径,并将其添加到结果路径中
path = V[t + 1][previous]["path"]
opt[0:0] =(path if path !=None else [])
#Insert the previous segment
opt.insert(0, V[t + 1][previous]["prev"])
previous = V[t + 1][previous]["prev"]
intertime2 = time.time()
print("--- Viterbi backtracking: %s seconds ---" % (intertime2 - intertime1))
# 将结果写入文件
#Clean the path (remove double segments and crossings) (only in full path option)
print "path length before cleaning :" +str(len(opt))
opt = cleanPath(opt, endpoints)
intertime3 = time.time()
print("--- Path cleaning: %s seconds ---" % (intertime3 - intertime2))
print "final length: "+str(len(opt))
pointstr= [str(g.firstPoint.X)+' '+str(g.firstPoint.Y) for g in points]
optstr= [str(i) for i in opt]
print 'The path for points ['+' '.join(pointstr)+'] is: '
print '[' + ' '.join(optstr) + '] with highest probability of %s' % max_prob
#If only a single segment candidate should be returned for each point:
if addfullpath == False:
opt = getpointMatches(points,opt)
optstr= [str(i) for i in opt]
print "Individual point matches: "+'[' + ' '.join(optstr) + ']'
intertime4 = time.time()
print("--- Picking point matches: %s seconds ---" % (intertime4 - intertime3))
return opt

















 8595
8595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









