







内容说明
本文主要为 HAL Id: inria-00350283的学习记录
感谢原作者
该系列文章使用伺服回路中的计算机视觉数据来控制机器人的运动。
首先给出视觉伺服控制问题的一般性概述。然后介绍了两种典型的视觉伺服控制方案:基于图像的视觉伺服控制和基于位置的视觉伺服控制。
最后,我们讨论了与这两个方案相关的性能和稳定性问题。
基础概念
视觉伺服
视觉伺服控制是一种基于视觉反馈的控制方式。是我们在日常生活中每时每刻都在进行的一种反馈:当你伸出手去抓取桌上的杯子的时候,眼睛会不断的反馈给大脑你的手和杯子的距离,这个距离可以被认为是误差,而大脑则会控制你的手臂进行运动来不断缩小这个误差,直到成功抓取。 1
将这样一个过程变成机器人的控制算法,我们需要用数学的语言来描述以上的过程。
所有的视觉伺服控制的目标都是为了使一个目标误差(error)最小化,其数学表达式:
e(t) = s(m(t),a) − s∗
其中m(t)是由camera所得到的图像数据,a是诸如camera intrinsic parameters此类对于系统本身的附加信息。m(t)和 a用来计算s被称作visual features,是一系列可被量化的视觉特征量,而s*则是这些视觉特征量的目标值。
基于图像的视觉伺服控制(IBVS),其中s由一组在图像数据中立即可用的特征组成。
基于位置的视觉伺服控制(PBVS),其中s由一组三维参数组成,这些参数必须通过图像测量来估计。
基于图像IBVS
最直接的方法是设计速度控制器,为此,我们需要s的时间变化与相机速度之间的关系。
相机的空间速度:vc=(vc,ωc)
用vc表示相机帧原点的瞬时线速度
用ωc表示相机帧的瞬时角速度
最终得到s‘与相机速度间的关系
s’=Lsvc
s’表示s关于时间的导数
Ls∈ Rk×6
于是
e ’ = Levc
where Le= Ls
我们希望error能够尽快地趋向0
所以我们希望error是一个成指数形势的衰减的函数,即指数函数
所以我们希望error求导后还是带参数的本身
(eax’=aeax,即e’=λe)
结合e ’ = Levc 可得
vc= −λLe−1e
Le+= (LeTLe)−1LeT
图像(小写)与世界坐标(大写)的转换
上面带点的是对时间求导


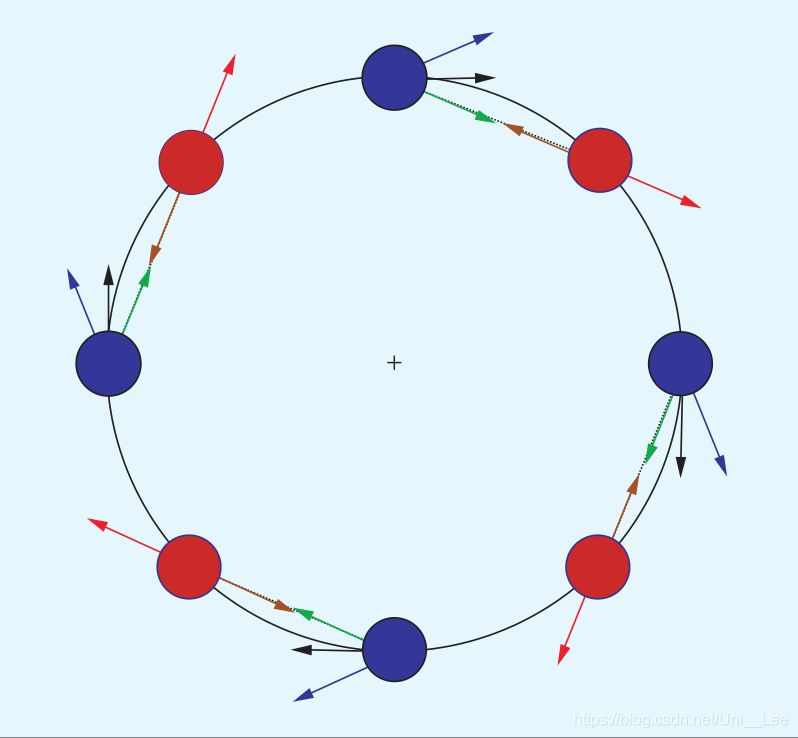
存在四种不同的摄像机姿态,使得e=0,即存在四个全局最小值,并且不可能区分它们
Le−1要么求得Z,要么求近似值Le∗-1,过弯
Le∗ 是 Le 在 e = e*= 0 时的值,Le∗-1是个常数,过直
或者Le−1= 1/2(Le+ Le∗)-1,其效果最好,如下
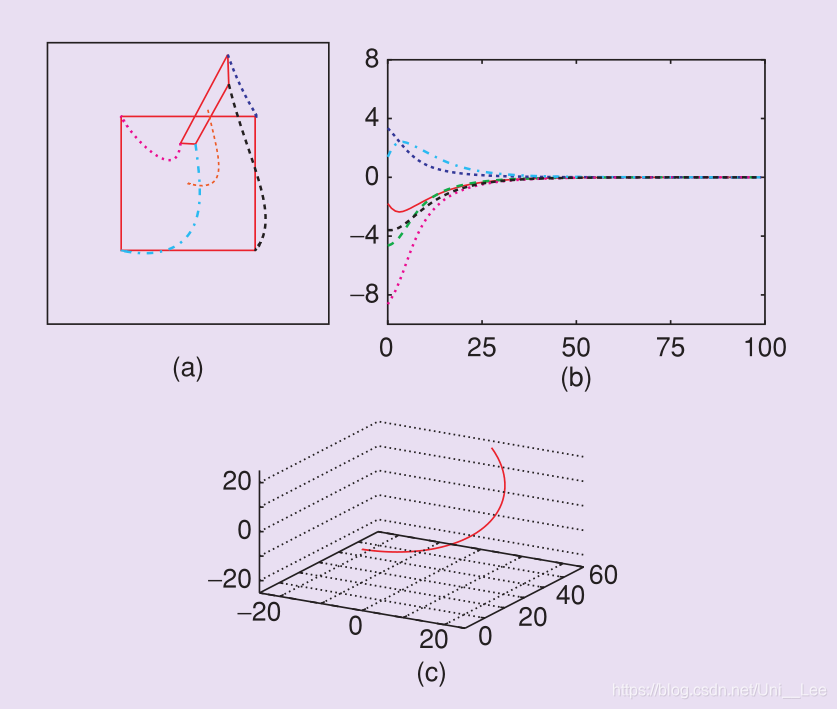
几何解释
这意味着当x和y图像点坐标构成该误差时,图像中的点的轨迹在可能的情况下从其初始位置到其所需位置沿着直线。这将导致在图中以绿色绘制的图像运动。
如果初始配置和期望配置之间的旋转非常大,这种现象会被放大。
另一方面,当旋转很小时,这种现象几乎消失。
综上所述,行为是局部满意的(即当误差很小时),但当误差很大时则可能是不满意的。
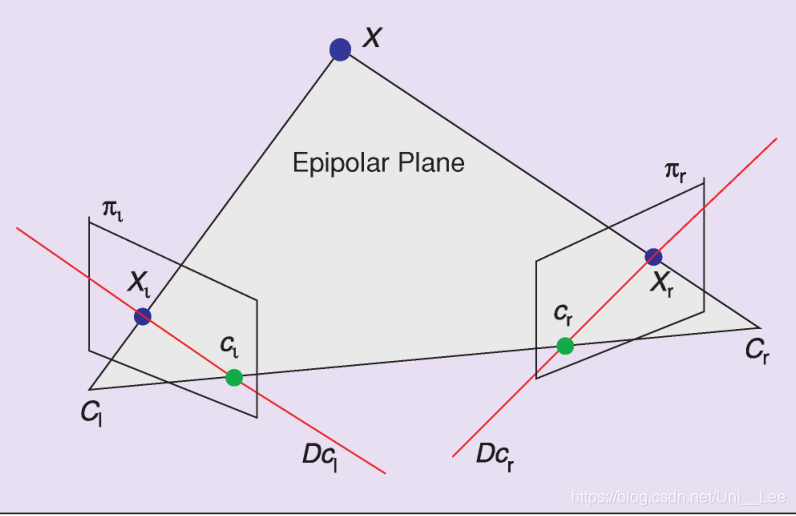
双目系统
s = xs= (xl,xr)
xl= Lxlvl
xr= Lxrvr

以下为翻译:
请注意,Lxs∈R4×6总是rank=3,因为在立体视觉系统中,极线约束连接了三维点的透视投影。
另一个简单的解释是,一个三维点由三个独立的参数来表示,这使得使用任何一个观察该点的传感器都不可能找到三个以上的独立参数。
为了控制系统的6自由度,需要考虑至少3个点,仅考虑2个点的相互作用矩阵的秩等于5。
使用立体视觉系统,由于在两幅图像中观察到的任何点的三维坐标都可以通过简单的三角测量过程很容易地估计出来,因此在特征集中使用这些三维坐标是可能的,也是很自然的。
严格地说,这种方法是基于位置的方法,因为它需要三维参数s。
基于位置PBVS 待研究
根据一幅图像中的一组测量值计算该姿态,需要相机的内在参数和观察到的物体的三维模型是已知的。
待研究

















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









