







一.通用近似定理
通俗的来说,这个定理可以推出一个两层的全连接神经网络,就可以做一切神经网络可以做的事情了。
当然,定理的具体表达和严格证明都涉及到不少泛函的东西,因此这里不做严格证明,但笔者整理了一下各处的思路,可以用如下方法去考虑:
总得来说,想解决的问题有三类:布尔表达式判断,分类,和拟合函数。
对于布尔表达式判断,就是有多个布尔输入,最后判断对还是错。学过数字逻辑就可以知道,任何的逻辑表达式都可以化为标准与或式,如下图所示。然而单层的神经元是可以模拟多个表达式的与和多个表达式的,所以这张图的与门和或门就可以看成是神经元,从而两层神经网络就可以解决一切判断类问题。(当然,多层的电路可以更省资源,这也是后面模组化的例子)

而对于多维的分类问题,我们可以知道一个神经元可以表示任意一个超平面。我们可以用二维情况来举例,由于分类是对离散的点去分类,因此边界一定可以由一条条直线组合而成,因此只要有足够多的直线,最后再用一个神经元来判断这些是取这些线的上半部分还是下半部分即可,而也同理;因此也是二层神经网络就可以了。

而对于拟合函数而言就要利用积分的思想。一元函数我们可以用两个处在同层的神经元模拟一个脉冲,或者说是一个小长方形,从而我们利用积分的思想,第一层构建出各种各样的小长方形,第二层使用简单的加法,将所有的小长方形累加起来,即可逼近一切函数。对于多元函数也是同理的,只是要用更多的处在同层的神经元去模拟高维脉冲,仅此而已。
二.深层网络的合理性
1.模组化
有了上面的定理,理论上只用两层神经网络就可以解决一切问题了,那更深层的网络还有意义吗?深度学习的深又体现在哪里呢?这就引发了一系列讨论。
结论当然是更深层的网络有更多优势。
首先是性能问题,我们希望用尽量少的参数和尽量少的数据,就可以得到更好的结果。这个很难理论去证明,只能去实践。下图为老师给的一个结果,同行的表示参数数量一样多,我们可以看出双层神经网络的性能明显较低;也就是说机器还是难以高效的去学习。

视频中提到了很多模组化的例子,来说明了深层神经网络架构的合理性。我认为可以从另一个角度去理解:那就是我们去用java去编写一个上万行的程序,然后去查看各个类和接口的继承和实现关系,把类和接口看成神经元,继承和实现接口看成是连接(合理性在于逻辑上道理相同);那双层神经网络就类似于所有类都是很多个接口的实现的final的类,而深层的就代表他们的关系可以任意嵌套;而显然任意嵌套带来了效率的极大提升,即使前者总是可以创建出任意的类,但是耗费太多额外资源。而java的这种模式很好的描述了现实中的很多事物,因此模组化是显然的。
2.端到端学习
这里老师主要是举了语音识别和图像识别的例子。
首先是没有用深层神经网络,只是采用了传统的机器学习算法或单层感知机分类+传统的严谨算法的情况,总之就是步骤很多,利用到很多专业知识。
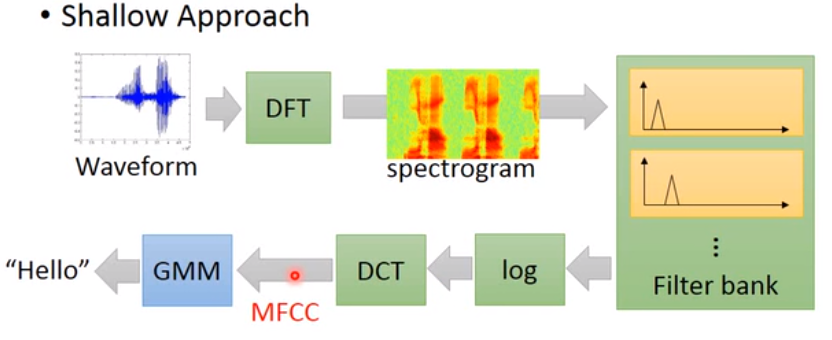
上图是传统的语音识别模型,只有最后一步使用了GMM(高斯混合模型,一种聚类方式)。

上图是传统的图像识别模型,也是只有最后一步使用了简单分类器。不过在后面我们其实可以看出传统方式的思维其实对卷积神经网络有着深远的影响。
然而,现在的深度神经网络可以做到,忽视掉这些所谓的所有这些步骤,转换成一整个黑盒神经网络,直接就是从输入端进入,输出端得到结果,直接进行端到端的学习,例如图像识别就如下图所示。当然,至于到底每层做了什么,为什么做成这样,没人可以说出原理,但是结果就是这样做不需要专业知识,效果可以几乎一样好甚至可以更好。
















 523
523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









