







对于这个API,我最开始的预想是从 '猫1猫2猫3猫4狗1狗2狗3狗4' 中分割出 '猫1猫2狗4狗1' 和 '猫4猫3狗2狗3' ,但是打印结果和我预想的不一样
数据集文件的存放路径如下图
测试代码如下
import torch
import torchvision
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((512,512)), # 调整图像大小为 224x224
torchvision.transforms.ToTensor(), # 转换为张量
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) # 归一化
])
dataset = torchvision.datasets.ImageFolder('C:\\Users\\ASUS\\PycharmProjects\\pythonProject1\\cats_and_dogs_train',
transform=transform)
val_ratio = 0.2
val_size = int(len(dataset) * val_ratio)
train_size = len(dataset) - val_size
train_dataset, val_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])
cats_num = 0
dogs_num = 0
for x,y in train_dataset:
if y == 0:
cats_num += 1
else:
dogs_num += 1
print("cats_num: ",cats_num)
print("dogs_num: ",dogs_num)
cats_num2 = 0
dogs_num2 = 0
for x,y in val_dataset:
if y == 0:
cats_num2 += 1
else:
dogs_num2 += 1
print("cats_num2: ",cats_num2)
print("dogs_num2: ",dogs_num2)输出如下
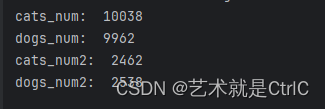
可以看到总共25000张图片的数据集,分割后并不是cats_num:10000,dogs_num:10000,cats_num2:2500,dogs_num2:2500
也就是说,分割后的状况是猫狗的数量并不一定相等,如结果为 '猫1猫2猫4狗1' 和 '狗4猫3狗2狗3'
















 1129
1129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









