







概况
训练模型离不开数据,PyTorch通过Dataset和DataLoader两个类,提供了灵活且高效的数据读取机制,实现了数据集代码与模型训练代码的解耦。
Dataset数据集负责处理单样本及其相应的标签,既可以使用内置于Pytorch的数据集,也可以使用自己的数据集。
DataLoader在数据集周围包装了一个可迭代项,进一步为模型训练提供了相应的功能。
Dataset
Dataset类似一个字典,负责处理索引(index)到样本(sample)的映射。
Dataset可以对样本数据进行预处理,并利用getitem方法返回一个样本。
Dataset有两种类型:map-style datasets和iterable-style datasets。
其中,map-style datasets是实现__getitem__()和__len__()协议的数据集,表示idx/key到数据样本的map。该类型数据集使用dataset[idx]访问,返回索引为idx的sample及其标签。
iterable-style datasets是实现__iter_()协议的IterableDataset的子类的实例,可在数据样本上迭代。这种类型的数据集用于不适合随机读取的情况,以及批量大小取决于提取的数据的情况。这种数据集通过iter(dataset)读取。
简单看下Dataset类的源码,由于是抽象类,官方实现的很简单,只定义了两个方法。
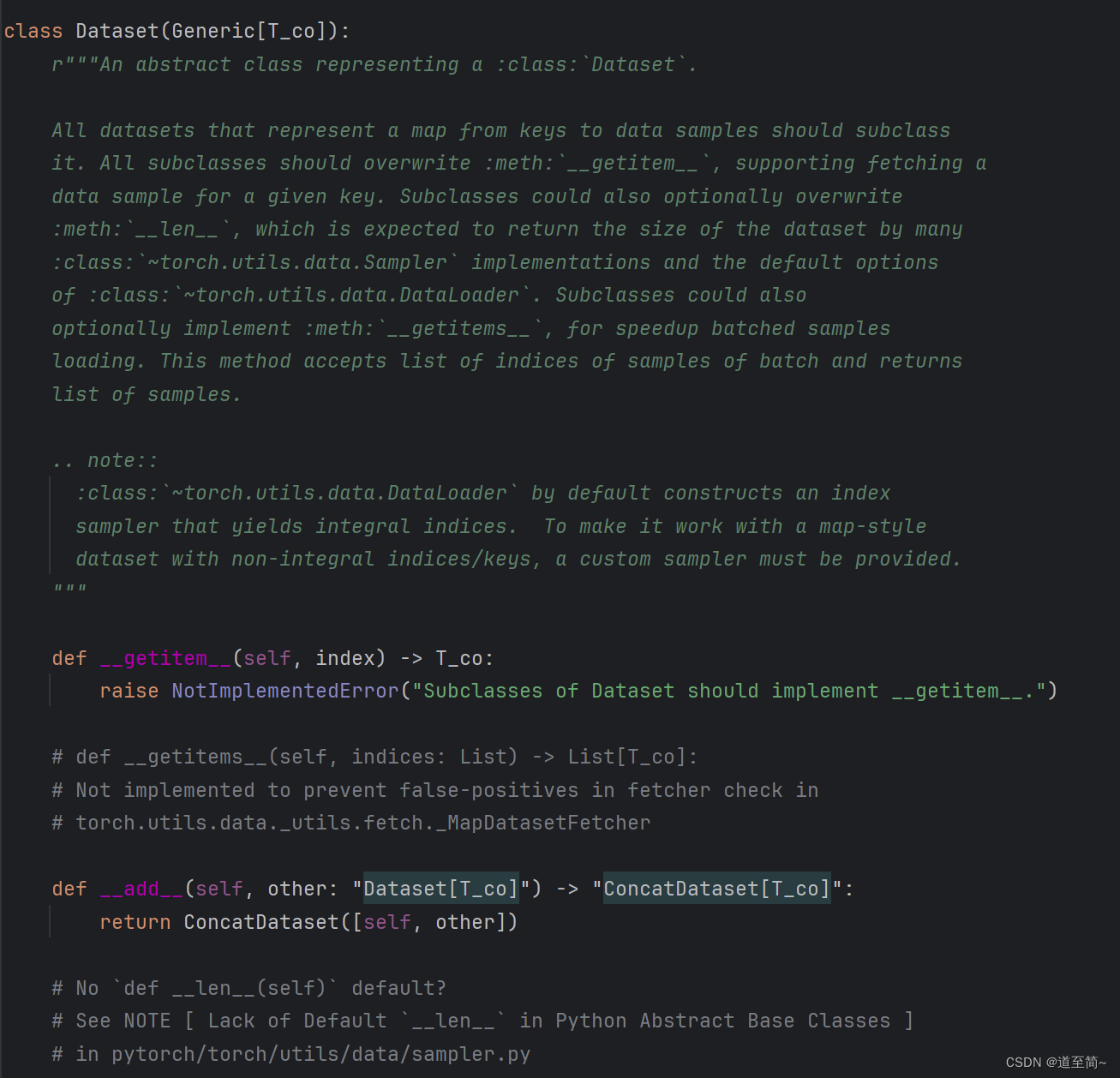
Dataset是抽象类,使用者根据自己的需求实现一个子类,需要实现以下3个方法:
- init():初始化方法。
- getitem():基于index获取数据集的一个sample,包括data和label。
- len():返回数据集的长度。
举一个Dataset的极简例子:
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, data, labels):
self.x = data
self.y = labels
def __len__(self):
return len(self.x)
def __getitem__(self, index):
return self.x[index], self.y[index]
DataLoader
DataLoader提供了数据的批量加载、多线程/进程加载、数据打乱等常用功能。
DataLoader类的实现细节较多,后面单独一节详细了解。
举一个DataLoader的极简例子:
from torch.utils.data import DataLoader
# 创建dataset
dataset = MyDataset(data, targets)
# 创建Dataloader
dataloader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=2)
# 使用Dataloader加载数据
for batch_x, batch_y in dataloader:
# 在这里进行模型的训练或验证操作
pass
加载一个Dataset
官方文档中举了一个从TorchVision加载Fashion MNIST数据集的示例。
Fashion MNIST是Zalando文章图像的数据集,由60000个训练示例和10000个测试示例组成。每个示例包括一个28×28灰度图像和来自10个类别之一的相关标签。
import torch
from torch.utils.data import Dataset
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
相关参数如下:
- root:数据文件的路径
- train:指定是训练数据集还是测试数据集
- download=True:如果不指定root,是否自动下载数据
- transform和target_transform:指定特征和标签的转换函数
对于加载到Dataset的数据,可以通过index提取数据,也可以利用matplotlib可视化。
labels_map = {
0: "T-Shirt",
1: "Trouser",
2: "Pullover",
3: "Dress",
4: "Coat",
5: "Sandal",
6: "Shirt",
7: "Sneaker",
8: "Bag",
9: "Ankle Boot",
}
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
for i in range(1, cols * rows + 1):
sample_idx = torch.randint(len(training_data), size=(1,)).item()
img, label = training_data[sample_idx]
figure.add_subplot(rows, cols, i)
plt.title(labels_map[label])
plt.axis("off")
plt.imshow(img.squeeze(), cmap="gray")
plt.show()
输出如下图:

自定义Dataset
下面代码自定义CustomImageDataset,通过本地文件加载Dataset,其中,图片数据存储在img_dir目录,标签数据存储在CSV文件:annotations_file。
import os
import pandas as pd
from torchvision.io import read_image
class CustomImageDataset(Dataset):
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
上述代码唯一值得一提的是Dataset通过transform和target_transform两个方法,处理样本数据和标签数据,默认是none。
getitem方法中,image和label数据在返回之前,分别调用这两个方法进行了处理。
这是常用的封装技巧,给外围调用者提供类似回调机制,方便调用者有机会对数据进行自定义处理。
轮到DataLoader登场了
Dataset的主要任务是处理单个样本,但在实际训练的时候肯定不能一条一条数据的训练,而是一批一批的训练,包括每轮训练完后是否需要打乱(reshuffle )再训练下一轮,另外为了提高训练效率有可能还需要考虑多进程,诸如此类的功能,都封装在DataLoader类解决。
创建DataLoader代码:
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
创建DataLoader的时候,需要传入Dataset对象,并指定batch的大小,以及是否需要reshuffle。
test数据一般不需要reshuffle。
一旦我们把Dataset加载到DataLoader中,就可以根据需要遍历Dataset。
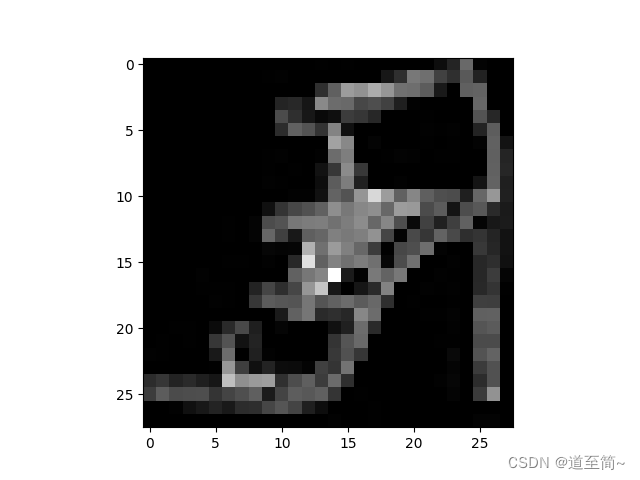
# Display image and label.
train_features, train_labels = next(iter(train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
通过iter函数返回迭代器,然后传给next函数,按批次返回样本数据和标签。
上述代码打印效果如下:
下面就一步一步解析DataLoader源码,看看内部是如何实现这个过程的。
DataLoader源码解析
__init__方法
先看看DataLoader的源码中的__init__方法。
首先对参数进行校验并赋值给属性。
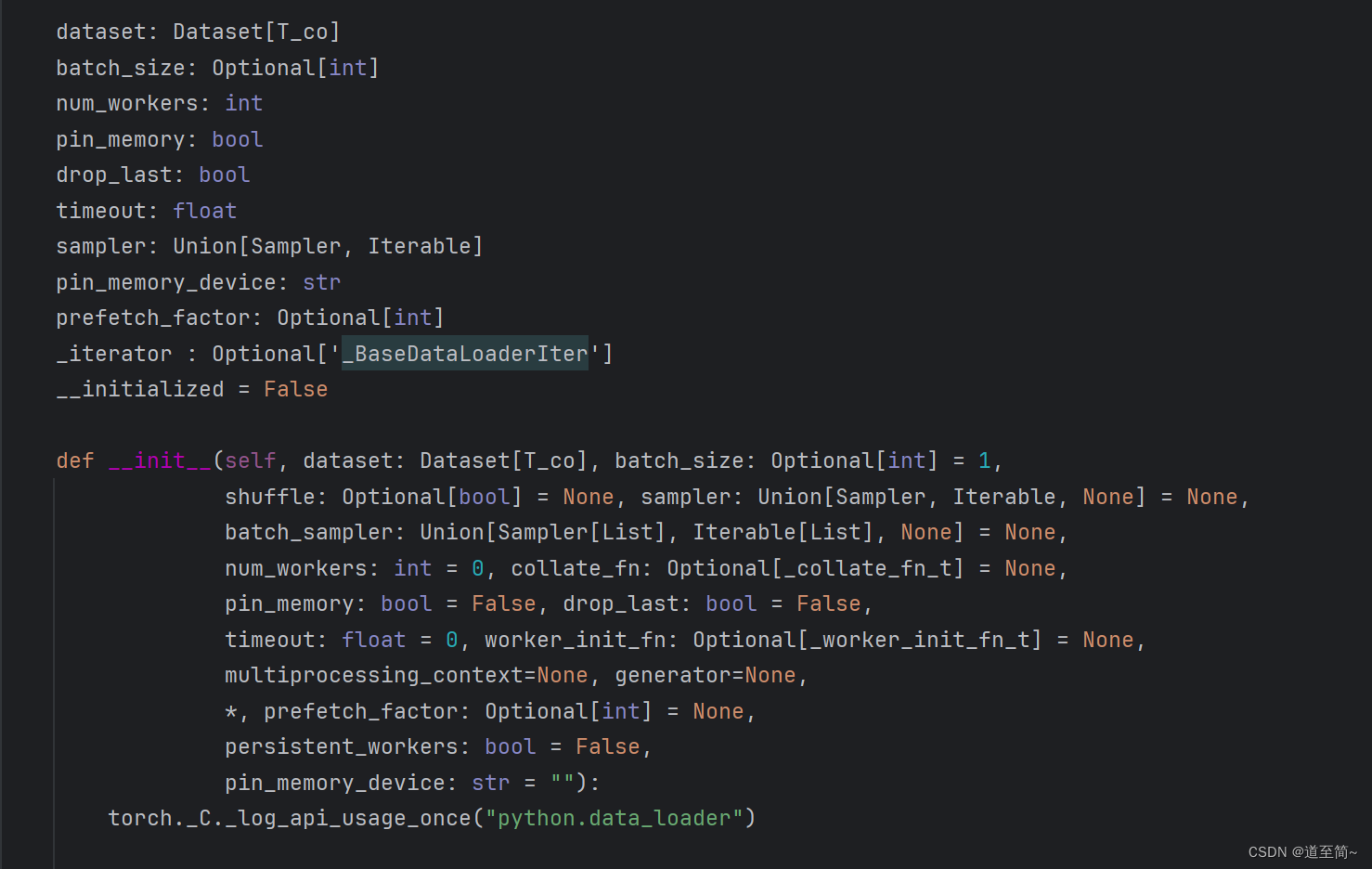
- dataset: 要传入的Dataset实例,也就是待训练的数据。
- batch_size:批次大小,默认为1。
- shuffle:每轮训练后,是否打乱数据。
- sampler:如何对数据进行采样,可以自定义。
- batch_sampler:一次返回一批样本。
- num_workers:进程数,默认为0,也就是单进程。
- collate_fn:聚集函数,可以对一个batch的样本进行后处理。
- pin_memory:是否在GPU中执行。
- drop_last: 如果总样本数据不能被batch_size整除,最后剩下的样本是否丢弃。默认为false。
获取样本的方式有多种,可以以默认的shuffle的方式,由官方定义的采样方法获取样本,也可以以自定义sample或batch_sampler的方式获取样本,两种方式二选一。
看以下源码:
if sampler is not None and shuffle:
raise ValueError('sampler option is mutually exclusive with '
'shuffle')
可以看出,如果同时指定了sample参数和shuffle参数,直接报错,两个参数是互斥的。
同理,batch_sampler也有类似的逻辑。
if batch_sampler is not None:
# auto_collation with custom batch_sampler
if batch_size != 1 or shuffle or sampler is not None or drop_last:
raise ValueError('batch_sampler option is mutually exclusive '
'with batch_size, shuffle, sampler, and '
'drop_last')
batch_size = None
drop_last = False
elif batch_size is None:
# no auto_collation
if drop_last:
raise ValueError('batch_size=None option disables auto-batching '
'and is mutually exclusive with drop_last')
如果设置了batch_sampler ,就不需要设置batch_size 、shuffle,sampler、drop_last,否则直接报错,相当于batch_sampler就把所有问题都解决了。另外,
如果没有设置batch_size且drop_last为true,也会报错,很好理解,既然不用批次,就不会有drop_last的问题。
继续:
if sampler is None: # give default samplers
if self._dataset_kind == _DatasetKind.Iterable:
# See NOTE [ Custom Samplers and IterableDataset ]
sampler = _InfiniteConstantSampler()
else: # map-style
if shuffle:
sampler = RandomSampler(dataset, generator=generator) # type: ignore[arg-type]
else:
sampler = SequentialSampler(dataset) # type: ignore[arg-type]
如果没有指定sampler参数,则使用内置的采样器。
首先判断dataset类型是iter还是map,对于iter采用内置的_InfiniteConstantSampler采样器,对于map类型,如果shuffle为true,则使用内置的随机采样器RandomSampler,否则内置的序列采样器SequentialSampler,也就是按照原来的顺序采样。
这里插入一点细节,了解这两个类的实现。
RandomSampler实现
init方法:
def __init__(self, data_source: Sized, replacement: bool = False,
num_samples: Optional[int] = None, generator=None) -> None:
self.data_source = data_source
self.replacement = replacement
self._num_samples = num_samples
self.generator = generator
...
- data_source (Dataset): 样本数据源
- replacement (bool): 样本是否按需替换
- num_samples (int): 抽取样本数
- generator (Generator): 用于样本抽取的方法
def __iter__(self) -> Iterator[int]:
n = len(self.data_source)
if self.generator is None: # 如果没有指定generator,则用随机种子抽取数据
seed = int(torch.empty((), dtype=torch.int64).random_().item())
generator = torch.Generator()
generator.manual_seed(seed)
else:
generator = self.generator
if self.replacement:
for _ in range(self.num_samples // 32):
yield from torch.randint(high=n, size=(32,), dtype=torch.int64, generator=generator).tolist()
yield from torch.randint(high=n, size=(self.num_samples % 32,), dtype=torch.int64, generator=generator).tolist()
else:
for _ in range(self.num_samples // n):
yield from torch.randperm(n, generator=generator).tolist()
yield from torch.randperm(n, generator=generator).tolist()[:self.num_samples % n]
看返回,通过torch.randperm方法返回n个索引的随机排列,达到随机的效果。
SequentialSampler实现
这个代码很简单。
def __iter__(self) -> Iterator[int]:
return iter(range(len(self.data_source)))
按照样本原有的顺序抽取数据。
细节插入结束。
回到DataLoader的源码。
if batch_size is not None and batch_sampler is None:
# auto_collation without custom batch_sampler
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
批量采样用到了BatchSampler类,再次插入该类的介绍。
BatchSampler实现
直接看代码+注释。
def __iter__(self) -> Iterator[List[int]]:
# Implemented based on the benchmarking in https://github.com/pytorch/pytorch/pull/76951
if self.drop_last: # 如果drop_last为true,不需要考虑最后一个批次的问题
sampler_iter = iter(self.sampler)
while True:
try:
batch = [next(sampler_iter) for _ in range(self.batch_size)]
yield batch
except StopIteration: # except说明不够一个batch_size,直接break,抛弃最后小部分数据
break
else:
batch = [0] * self.batch_size # 用 0 初始化batch_size 个元素的数组
idx_in_batch = 0 # 利用该变量记录已采样的批次样本数
for idx in self.sampler:
batch[idx_in_batch] = idx # 实际返回的还是idx数组
idx_in_batch += 1
if idx_in_batch == self.batch_size:
yield batch # 达到批次数量,返回
idx_in_batch = 0 # 清零已采样数
batch = [0] * self.batch_size # 重新初始化batch数组
if idx_in_batch > 0:
yield batch[:idx_in_batch] # 最后遗留的部分数据,单独返回
再次回到DataLoader类。
if collate_fn is None:
if self._auto_collation:
collate_fn = _utils.collate.default_collate
else:
collate_fn = _utils.collate.default_convert
根据_auto_collation决定使用那个collate函数。
@property
def _auto_collation(self):
return self.batch_sampler is not None
如果设置了batch_sampler,则_auto_collation为true。
通过查看default_collate源码,可以看到其内部对数据做了校验并返回,本质上没有太多有价值的功能。
总结一下DataLoader的init方法,主要完成了以下功能:
- 校验参数并给属性赋值
- 构建sampler对象,用于采集数据
- 构建collate方法,用于样本数据后处理
__iter__方法
DataLoader实现了__iter__方法,可以实现迭代器调用。
def __iter__(self) -> '_BaseDataLoaderIter':
# When using a single worker the returned iterator should be
# created everytime to avoid resetting its state
# However, in the case of a multiple workers iterator
# the iterator is only created once in the lifetime of the
# DataLoader object so that workers can be reused
if self.persistent_workers and self.num_workers > 0:
if self._iterator is None:
self._iterator = self._get_iterator()
else:
self._iterator._reset(self)
return self._iterator
else:
return self._get_iterator()
该方法的逻辑很简单,调用_get_iterator()方法并返回。
def _get_iterator(self) -> '_BaseDataLoaderIter':
if self.num_workers == 0:
return _SingleProcessDataLoaderIter(self)
else:
self.check_worker_number_rationality()
return _MultiProcessingDataLoaderIter(self)
根据是否多线程,返回DataLoaderIter对象。
下面以_SingleProcessDataLoaderIter为例,简单了解DataLoaderIter对象。
该类主要作用是创建fetcher对象:
self._dataset_fetcher = _DatasetKind.create_fetcher(
self._dataset_kind, self._dataset, self._auto_collation, self._collate_fn, self._drop_last)
create_fetcher方法如下:
@staticmethod
def create_fetcher(kind, dataset, auto_collation, collate_fn, drop_last):
if kind == _DatasetKind.Map:
return _utils.fetch._MapDatasetFetcher(dataset, auto_collation, collate_fn, drop_last)
else:
return _utils.fetch._IterableDatasetFetcher(dataset, auto_collation, collate_fn, drop_last)
根据Dataset的类型分别创建fetcher对象。
fetcher对象只实现了fatch方法。
例如_MapDatasetFetcher类:
class _MapDatasetFetcher(_BaseDatasetFetcher):
def fetch(self, possibly_batched_index):
if self.auto_collation:
if hasattr(self.dataset, "__getitems__") and self.dataset.__getitems__:
data = self.dataset.__getitems__(possibly_batched_index)
else:
data = [self.dataset[idx] for idx in possibly_batched_index]
else:
data = self.dataset[possibly_batched_index]
return self.collate_fn(data)
上面的代码逻辑很清晰,就是根据不同情况获取dataset的样本数据。
再次回到_SingleProcessDataLoaderIter类,还有个关键方法:_next_data。
def _next_data(self):
index = self._next_index() # may raise StopIteration
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
if self._pin_memory:
data = _utils.pin_memory.pin_memory(data, self._pin_memory_device)
return data
该方法在哪里调用的呢?
_SingleProcessDataLoaderIter基类_BaseDataLoaderIter的__next__方法:
def __next__(self) -> Any:
with torch.autograd.profiler.record_function(self._profile_name):
if self._sampler_iter is None:
# TODO(https://github.com/pytorch/pytorch/issues/76750)
self._reset() # type: ignore[call-arg]
data = self._next_data() # 在这里!!!
......
通过以上的逻辑,整个逻辑全通了!
或者,全乱了~~~
还记得通过Dataloader获取数据的代码吗?
train_features, train_labels = next(iter(train_dataloader))
总结一下,整个流程就是通过__iter__ 和__next__ 两个魔法方法实现,然后通过next(iter(train_dataloader))这种形式优雅的串联了数据采样流程。
总结
本文总结了Dataset和DataLoader两个核心类,是模型训练绕不开的基础类,希望阅读本文能带来收获。
另外,阅读源码确实就像盗梦空间的层层梦境一样,不知道这种行文方式是否方便大家阅读,有什么好的建议欢迎留言。















 2234
2234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









