







上回说到,把线性回归做到一定的深度,就涌现出了智能,其实这个说法不严谨。
试想一下,把Y=aX+b嵌套2层:
第一层:X1=a1Y1+b1
第二层:Y1=a2Z1+b2
第二层带入第一层,得到:
X1=a1(a2Z1+b2)+b1=a1a2Z1+a1b2+b1
发现没有,本质上跟一层是一样的,还是个线性回归。
同理,把线性回归的深度做到1w层,其本质也还是个线性变换,白忙活!
那有什么办法,让深度变得更有意义呢?
答案是:激活。
激活
在不使用激活函数的神经网络,无论做多少层,叠加后也还是线性变换。因为线性模型的表达能力通常不够强,就需要通过激活函数引入非线性因素。
如何理解非线性因素呢?
用一个二维空间的例子解释,可以很直观的理解。
比如下面的这种情况,用一根直接就可以分开,也就是说是线性可分的。
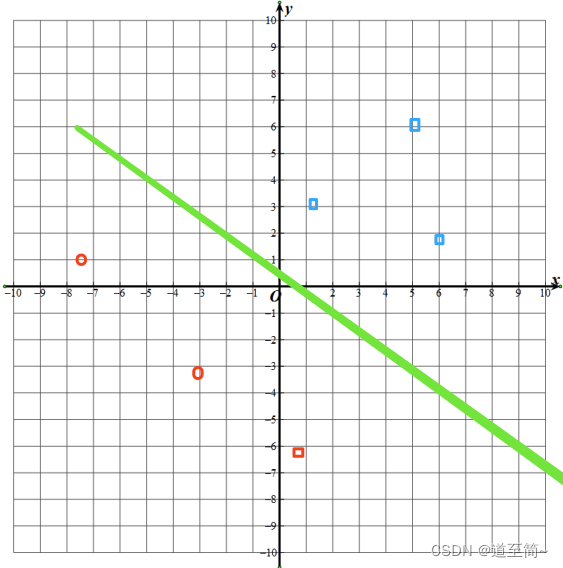
但不是所有情况都是线性可分的,比如下面这种情况:
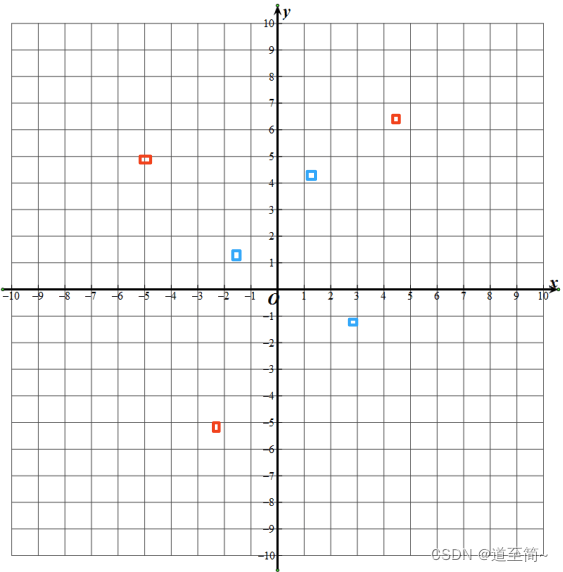
这时候需要引入非线性因素,用一条曲线划分不同的点。
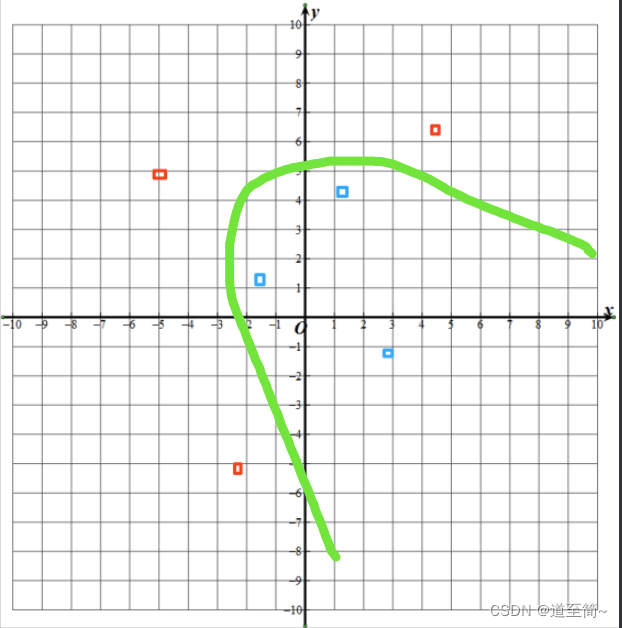
是的,有了激活函数,就把线性变得不那么线性,可以把直线变得弯曲,就可以解决更多更复杂的问题。
有了激活函数的加持,仿佛突然赋予函数一种魔力,让拟合能力无限加强。理论上,只要有足够多的线性回归+激活,可以解决任何分类问题。
常用激活函数
- sigmoid:这是资历最老的激活函数,可以把任何输出转换到区间(0,1)的范围内,完美匹配概率,可以解决分类问题。
存在梯度消失问题,当输入非常大或非常小的时候,输出基本为常数,即变化非常小,进而导致梯度接近于0。

- tanh:属于sigmoid的变形,把输出转换到区间(-1,1),类似正态分布。
同样存在梯度消失问题。
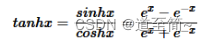
- ReLU:最常用的激活函数,是一个分段函数,如果输入为正,它将直接输出,否则,它将输出为零。
避免梯度消失问题,同时也是计算梯度最快的激励函数。
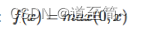
以上三种是比较常用的激活函数。
上面提到梯度,是通过训练寻找最优模型的常用算法,以后再聊。
总结
没有激活,线性回归是死水一潭,再深的层次也没有意义。
有了激活,让深度神经网络完成了从简单的线性到非线性的飞跃,让人工智能真的有了“智能”,让算法有了“灵魂”,让机器人“活”了!















 633
633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









