






个人代码
https://github.com/Violettttee/Pytorch-lstm-attention
数据集
个人认为可以先看看自己数据集的样子,我的数据集是kaggle上的一个房价的数据集:House Property Sales Time Series | Kaggle
该数据集几乎每天都记录了房价,在这里建议对数据预测前,先绘图看看数据的分布是怎么样的,可以画折线图,也可以画点图等等的。事实上原数据(未经处理的数据)点非常密集,表示在一天之中同一种类型的房型都会存在很多个具体的价格。
特征:
原数据
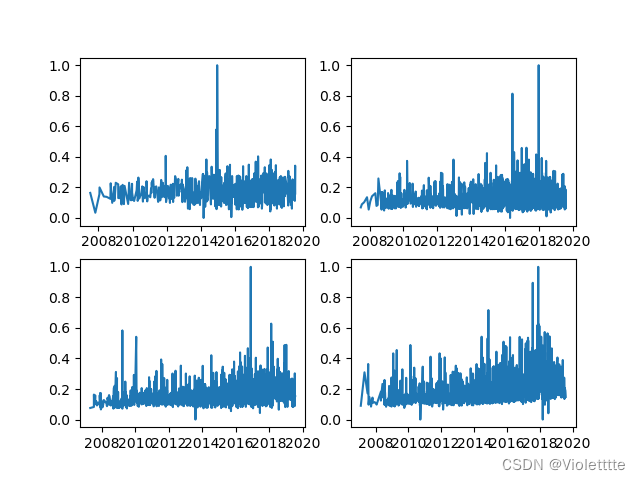
可以明显的看出原数据数据量大,波动也极大,其实这和原数据的特征有关,原数据的房源中包括了”postcode“邮编地址,本质上是不同地方的房型,所以即使在同一个房间数量”bedrooms“下,房价也能出现很大的差异,但是总不可能为每个postcode分别做模型拟合吧?(整个postcode有30多个),所以一种方式是重新聚合数据。
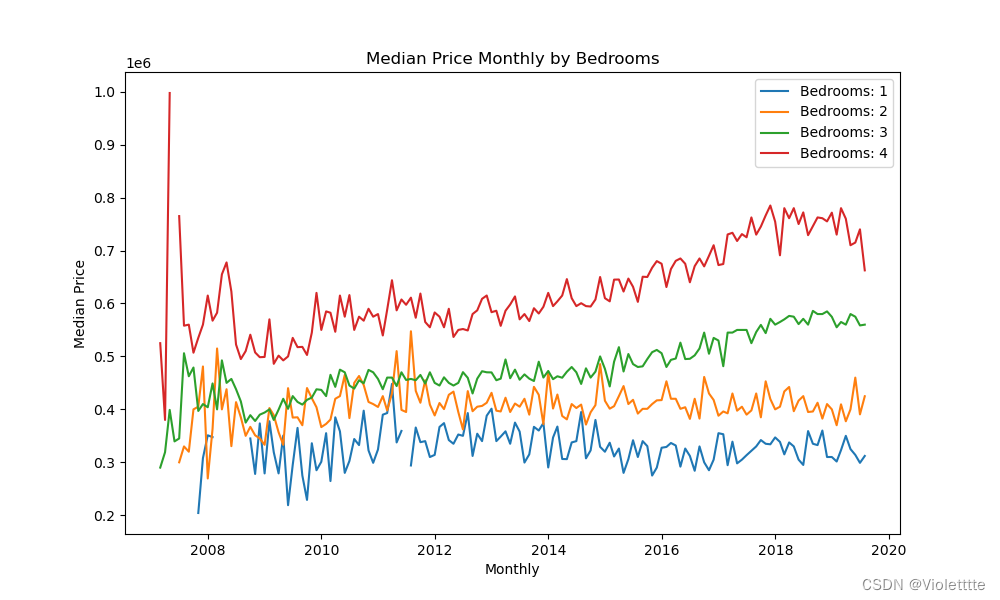
月度
季度
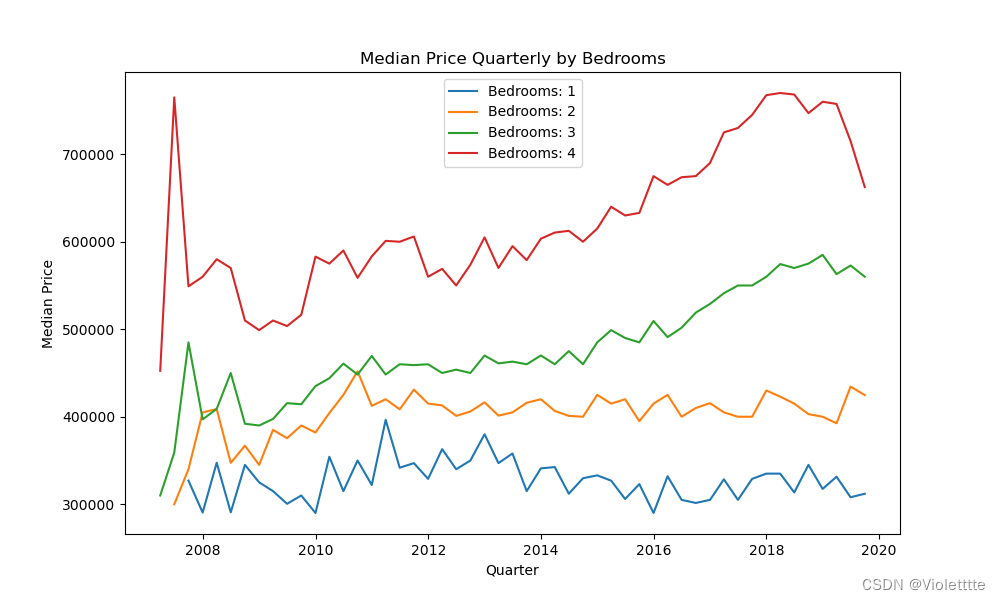
事实上在测试中发现,把数据按照月度聚合基本跑不了,梯度在几次迭代之后直接发生爆炸……所以最后是按照季度数据聚合跑的代码。
解决方式
在一开始尝试了多种方法,文章里会都列举出来,但是在本文的数据上唯一解决的方法是对数据进行处理,所以建议最好一开始就先看下自己的数据波动情况。
处理数据(成功)
对数据进行预处理,可以按照月度、季度、半年或整年聚合。当然具体的处理可以更复杂,例如在数据集的链接中做的是按照季度的中值聚合。个人觉得清洗方式可以设计更多规则。从实际意义上来说,对这种涉及到(广义)时间的预测进行聚合是一种更宏观意义上预测数据趋势的做法。
归一化(失败)
归一化并没有解决问题……不过按理来说,对于值较大的数据使用归一是比较好的,本文也最终的代码也是使用了归一化处理器的。
对训练集的归一化
归一化的基本代码如下(在数据训练前),注意需要将Scaler在拟合(fit)后进行返回,而不是在之后重新创建一个minmaxSclaer对预测数据进行反归一
from sklearn.preprocessing import MinMaxScaler
def normalization(data,label):
mm_x=MinMaxScaler() # 导入sklearn的预处理容器
mm_y=MinMaxScaler()
data=data.values # 将pd的系列格式转换为np的数组格式
label=label.values
data=mm_x.fit_transform(data) # 对数据和标签进行归一化等处理
label=mm_y.fit_transform(label)
return data,label,mm_y,mm_x对预测结果反归一
'''
对预测数据(price)做反归一化处理
'''
moudle.eval()
train_predict = moudle(x_data).cpu().detach().numpy()
train_predict_df = pd.DataFrame({
'datesold':list(df['datesold'])[:-(seq_length+1)] ,
'bedrooms':list(df['bedrooms'])[:-(seq_length+1)] ,
'price':train_predict ,
}) # 方便绘图
predict_price = mm_y.inverse_transform(train_predict_df['price'].values.reshape(-1,1))
# predict_price即预测结果
# reshape(-1,1)是因为mm_y.inverse_transform的输入必须是二维的。
最终结果
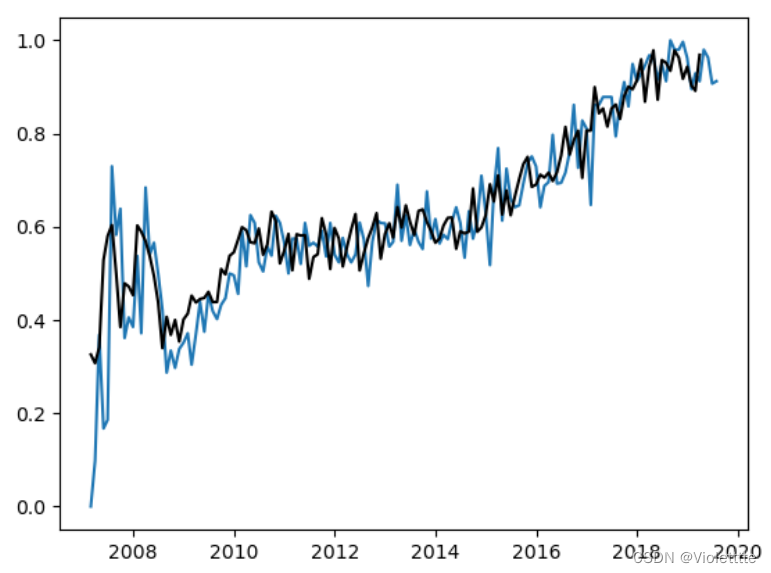
输出单分类预测结果
在输出分类中的单个分类的
输出多分类预测结果
即在输出结果的多个分类上预测的结果
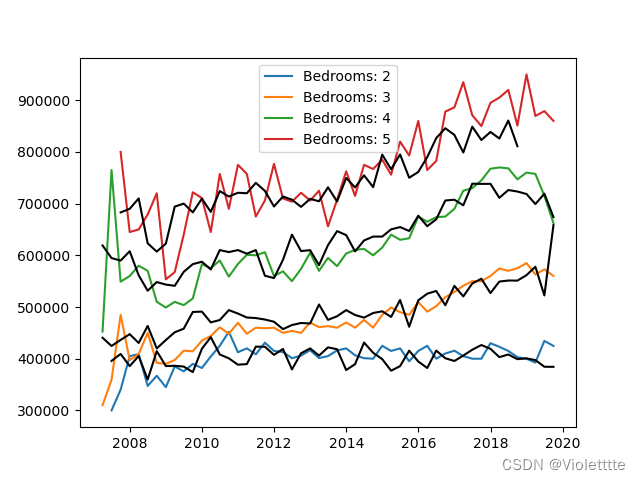
无attention
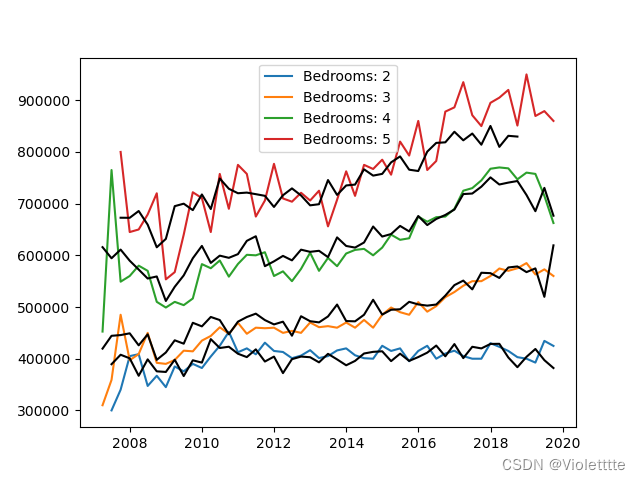
有attention















 84
84











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









