







https://mp.weixin.qq.com/s?__biz=MzUxNjcxMjQxNg==&mid=2247527357&idx=2&sn=ae28db152ca827a294d87588be0cafaa&chksm=f9a11932ced69024cfd1229477af13496b41e327a68a3b9dd0199f8aeeb1891d06545940531f&mpshare=1&scene=1&srcid=06292DeC1OAJf0TDqkSsC5By&sharer_sharetime=1624941963155&sharer_shareid=42a896371dfe6ebe8cc4cd474d9b747c&key=2e72a6320201bc977059d3ea83c82ae265ebe8cb0dc95a4c029fa47425fa32cf9a2b6a691c4fb833d06dd527d437fa03649e957a409fd28499ff77eae34e2823aab0536f10912af208bf9126595f84c1cffba5ce8f516385f296a25d5bbabb78277690cd84fbc6eeafb987c7c71b5b9832a2b527fae24e988b18c690e681eec6&ascene=1&uin=NjM0NzY4NjM0&devicetype=Windows+XP&version=62060841&lang=zh_CN&exportkey=A82xDm1QRwEk0N%2FdES01T7g%3D&pass_ticket=PT46Sbr%2B2d50tsnG%2BygRHGPL2E5vqjGC1qHVJkdkPjNVtxOxdycgX1f9J0Kd9KdY&wx_header=0
文章目录
- 前言
- SENet:Squeeze-and-Excitation Networks(通道域),CPVR2017
- BAM:Bottleneck Attention Module
- CBAM: Convolutional Block Attention Module(通道域+空间域), ECCV2018
- DANet:Dual Attention Network for Scene Segmentation(空间域+通道域), CPVR2019
- CCNet:Criss-Cross Attention for Semantic Segmentation(十字交叉注意力模块)
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks(通道注意力超强改进)轻量模块ECANet
前言
SENet:Squeeze-and-Excitation Networks(通道域),CPVR2017
https://zhuanlan.zhihu.com/p/65459972/
- Squeeze部分。即为压缩部分。对通道重新加权,模块首先对输入
( H×W ×C2 )使用压缩操作,输出大小为( 1×1×C2 )的特征图,相当于把H* W压缩成一维了,实际中一般是用global average pooling实现的,H* W压缩成一维后,相当于这一维参数获得了之前H*W全局的视野,感受区域更广,得到channel级的全局特征。 - Excitation部分。接着使用提取操作,另参数 ω 学习 C2 个通道间的相关性(学习各个channel间的关系,也得到不同channel的权重),即加入一个FC全连接层(Fully Connected),对每个通道的重要性进行预测,生成
( 1×1× C 2 )的特征图;最后乘以原来的特征图得到最终特征图( H× W× C2 ),C 2 即为加权后通道值。
本质上,SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。


作者在Inception和ResNet模块上使用了se模块:

BAM:Bottleneck Attention Module
依据
人看东西时不可能把注意力放在所有的图像上,会把焦点目光聚集在图像的重要物体上。因此,作者提出了BAM注意力机制,仿照人的眼睛聚焦在图像几个重要的点上。
BAM介绍
在这项工作中,我们把重心放在了Attention对于一般深度神经网络的影响上,我们提出了一个简单但是有效的Attention模型—BAM,它可以结合到任何前向传播卷积神经网络中,我们的模型通过两个分离的路径 channel和spatial, 得到一个Attention Map。

BAM具体结构

两种attention的结合方式
由一系列的实验可得,element-wise summation即逐元素相加perform是最好的。最后再通过sigmoid函数。具体可以参照下图:

CBAM: Convolutional Block Attention Module(通道域+空间域), ECCV2018
简介
作者提出了一个简单但有效的注意力模块 CBAM,给定一个中间特征图,我们沿着空间和通道两个维度依次推断出注意力权重,然后与原特征图相乘来对特征进行自适应调整。 由于 CBAM 是一个轻量级的通用模块,它可以无缝地集成到任何 CNN 架构中,额外开销忽略不计,并且可以与基本 CNN 一起进行端到端的训练。 在不同的分类和检测数据集上,将 CBAM 集成到不同的模型中后,模型的表现都有了一致的提升,展示了其广泛的可应用性。
CBAM总体视图
对于以下结构,我想用比较具体的数字来表示整个流程,比如输入的Feature维度为1x16x10x10(各维度代表BCHW),经过通道注意力机制之后,得到的权重维度为1x16x1x1(权重值越大,代表着那个通道特征图越重要),经过空间注意力机制之后,得到的权重为1x1x10x10(权重越大,代表特征图上的内容越重要)

CBAM结构介绍
作者将注意力过程分为两个独立的部分,通道注意力模块和空间注意力模块。这样不仅可以节约参数和计算力,而且保证了其可以作为即插即用的模块集成到现有的网络架构中去。
通道注意力模块
特征的每一个通道都代表着一个专门的检测器,因此,通道注意力是关注什么样的特征是有意义的。为了汇总空间特征,作者采用了全局平均池化和最大池化两种方式来分别利用不同的信息。
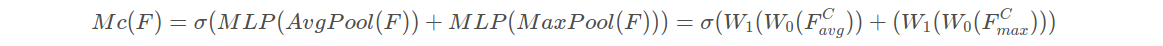
输入是一个 H×W×C 的特征 F,我们先分别进行一个空间的全局平均池化和最大池化得到两个 1×1×C 的通道描述。接着,再将它们分别送入一个两层的神经网络,第一层神经元个数为 C/r,激活函数为 Relu,第二层神经元个数为 C。这个两层的神经网络是共享的。然后,再将得到的两个特征相加后经过一个 Sigmoid 激活函数得到权重系数 Mc。最后,拿权重系数和原来的特征 F 相乘即可得到缩放后的新特征。
空间注意力模块
在通道注意力模块之后,我们再引入空间注意力模块来关注哪里的特征是有意义的。
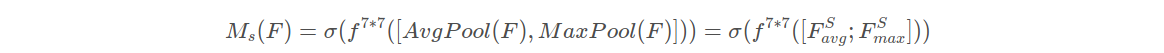
与通道注意力相似,给定一个 H×W×C 的特征 F‘,我们先分别进行一个通道维度的平均池化和最大池化得到两个 H×W×1 的通道描述,并将这两个描述按照通道拼接在一起。然后,经过一个 7×7 的卷积层,激活函数为 Sigmoid,得到权重系数 Ms。最后,拿权重系数和特征 F’ 相乘即可得到缩放后的新特征。

两个注意力通道组合形式
通道注意力和空间注意力这两个模块可以以并行或者顺序的方式组合在一起,但是作者发现顺序组合并且将通道注意力放在前面可以取得更好的效果。
CBAM可视化

利用 Grad-CAM 对不同的网络进行可视化后,可以发现,引入 CBAM 后,特征覆盖到了待识别物体的更多部位,并且最终判别物体的概率也更高,这表明注意力机制的确让网络学会了关注重点信息。
代码:
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, in_planes):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1).cuda()
self.max_pool = nn.AdaptiveMaxPool2d(1).cuda()
self.fc = nn.Sequential(nn.Conv2d(in_planes, in_planes // 16, 1, bias=False),
nn.ReLU(),
nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)).cuda()
self.sigmoid = nn.Sigmoid().cuda()
def forward1(self, x):
avg_out = self.fc(self.avg_pool(x))
max_out = self.fc(self.max_pool(x))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=3):
super().__init__()
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=kernel_size // 2, bias=False).cuda()
self.sigmoid = nn.Sigmoid().cuda()
def forward2(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
问题:
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
错误内容大概就是指输入类型是GPU(torch.cuda.FloatTensor),而参数类型是CPU(torch.FloatTensor)。故,上述参数代码加.cuda()
结论(CBAM和BAM)
由上述及论文更多实验结果表明,不管是引入BAM还是引入CBAM都能提高目标检测和物体分类的精度,因此可以在神经网络中引入这一机制,而且花费的计算开销和参数大小都比较少。
代码解析及开源地址
https://github.com/Jongchan/attention-module
DANet:Dual Attention Network for Scene Segmentation(空间域+通道域), CPVR2019
code: https://github.com/junfu1115/DANet
把Self-attention的思想用在图像分割,可通过long-range上下文关系更好地做到精准分割。
主要思想也是上述文章 CBAM 和 non-local 的融合变形:
把deep feature map进行spatial-wise self-attention,同时也进行channel-wise self-attetnion,最后将两个结果进行 element-wise sum 融合。

这样做的好处是:
在 CBAM 分别进行空间和通道 self-attention的思想上,直接使用了 non-local 的自相关矩阵 Matmul 的形式进行运算,避免了 CBAM 手工设计 pooling,多层感知器 等复杂操作。
CCNet:Criss-Cross Attention for Semantic Segmentation(十字交叉注意力模块)
https://zhuanlan.zhihu.com/p/80317140
本篇文章的亮点在于用了巧妙的方法减少了参数量。在上面的DANet中,attention map计算的是所有像素与所有像素之间的相似性,空间复杂度为(HxW)x(HxW),而本文采用了criss-cross思想,只计算每个像素与其同行同列即十字上的像素的相似性,通过进行循环(两次相同操作),间接计算到每个像素与每个像素的相似性,将空间复杂度降为(HxW)x(H+W-1),以图为例为下:
 整个网络的架构与DANet相同,只不过attention模块有所不同,如下图:在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘,计算相似度。
整个网络的架构与DANet相同,只不过attention模块有所不同,如下图:在计算矩阵相乘时每个像素只抽取特征图中对应十字位置的像素进行点乘,计算相似度。
 经过一轮此attention计算得到的attention map如下图R1所示,对于每个元素只有十字上的相似性,而通过两轮此计算,对于每个元素就会得到整张图的相似性,如R2。
经过一轮此attention计算得到的attention map如下图R1所示,对于每个元素只有十字上的相似性,而通过两轮此计算,对于每个元素就会得到整张图的相似性,如R2。

得到此结果的原因如下图,经过一轮计算,每个像素可以得到在其十字上的相似性,对于不同列不同行(不在其十字上)的像素是没有相似性的,但是这个不同行不同列像素同样也进行了相似性计算,计算了在其十字上的相似性,那么两个十字必有相交,在第二次attention计算的时候,通过交点,相当于是间接计算了这两个不同列不同行像素之间的相似性。
实验结果达到了SOTA水平,但没有计算全部像素的attention方法准确率高。
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks(通道注意力超强改进)轻量模块ECANet
深度解析 | CVPR2020 | 通道注意力超强改进,轻量模块ECANet来了!即插即用,显著提高CNN性能|已开源

参考(感谢)
https://blog.csdn.net/xiewenrui1996/article/details/105760359?utm_medium=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control&dist_request_id=&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-BlogCommendFromMachineLearnPai2-1.control
https://blog.csdn.net/baidu_32885165/article/details/109226784















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









