






参考:Langchain-Chatchat(原 Langchain-ChatGLM)部署小记 - 知乎
下载langchain-chatchat
首先克隆项目
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
langchain chatchat 发现2023.10.16的时候这个开发文档说明是对应的langchainchatchat 0.2.4版本,建议使用这个版本
进入目录cd Langchain-Chatchat
下载所需LLM模型文件和Embedding模型
我下载的是chatglm2-6b:git clone https://huggingface.co/THUDM/chatglm2-6b
Embedding模型下载的是m3e-base模型: git clone https://huggingface.co/moka-ai/m3e-base
修改configs\model_config.py.example 将其重命名为configs\model_config.py
修改config配置文件
将configs目录下的配置文件进行修改,分别在LLM模型和embedding模型处填入自己所下载的模型的绝对路径;
- 修改本地LLM模型存储路径。
如果使用本地LLM模型,请确认已下载至本地的 LLM 模型本地存储路径写在 llm_model_dict 对应模型的 local_model_path 属性中,如:
llm_model_dict={
"chatglm2-6b-int4": {
"local_model_path": "D:\\Langchain-Chatchat\\chatglm2-6b-int4", # "THUDM/chatglm2-6b-int4",
"api_base_url": "http://localhost:8888/v1", # "URL需要与运行fastchat服务端的server_config.FSCHAT_OPENAI_API一致
"api_key": "EMPTY"
},
}默认模板中没有提供llm_model_dict中,没有chatglm2-6b-int4模型,需要自己添加。
- 修改在线LLM服务接口相关参数
如果使用在线LLM服务,类OpenAi的API,需在llm_model_dict的gpt-3.5-turbo模型,修改对应的API地址和环境变量中的KEY,或新增对应的模型对象。
llm_model_dict={
"gpt-3.5-turbo": {
"local_model_path": "gpt-3.5-turbo",
"api_base_url": "https://api.openai.com/v1",
"api_key": os.environ.get("OPENAI_API_KEY")
},
}
- 修改使用的LLM模型名称
根据上述新增或修改的模型名称,修改LLM_MODEL为使用的模型名称
# LLM 名称
LLM_MODEL = "chatglm2-6b-int4"
- 修改embedding模型存储路径
请确认已下载至本地的 Embedding 模型本地存储路径写在 embedding_model_dict 对应模型属性中,如:
embedding_model_dict = {
"m3e-base": "D:\\Langchain-Chatchat\\m3e-base",
}
- 其他修改项,可根据配置文件中的注释,自行进行修改。
安装虚拟环境
conda安装虚拟环境 langchainChatchat:
conda create -n langchainChatchat python=3.10
激活环境:conda activate langchainChatchat
更新库:
pip install -r requirements.txt
知识库初始化
由于是第一次使用,进行知识库初始化:
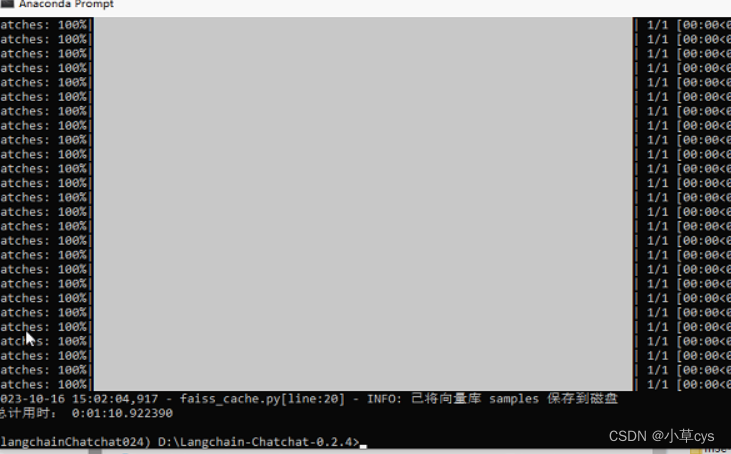
$ python init_database.py --recreate-vs时间有点长
cd your_python_path/site-packages/faiss
ln -s swigfaiss.py swigfaiss_avx2.py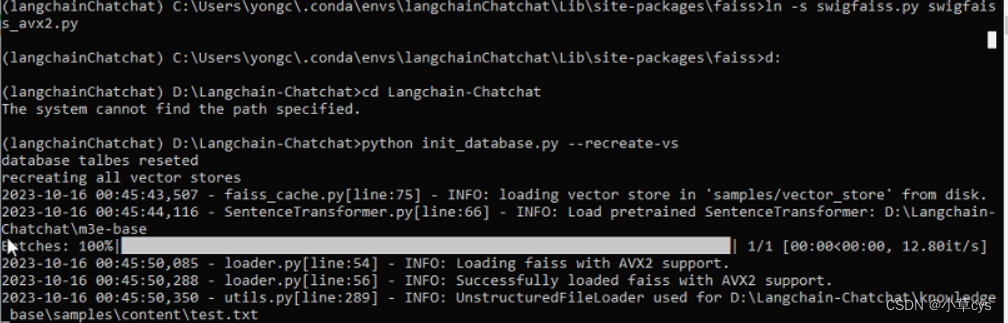
参考:langchain chatchat 发现2023.10.16的时候这个开发文档说明是对应的langchainchatchat 0.2.4版本,如果用最新的版本会在python init_database.py --recreate-vs卡住(我卡了3个小时,后终止),且不报任何错误。
中间会有报错:torch与cuda不兼容,Torch not compiled with CUDA enabled
解决方法:
https://download.pytorch.org/whl/torch_stable.html
下载对应的python版本的、cuda版本的pytorch的whl文件。
不知道为啥,默认安装的是对应版本的cpu版本,需要下载cuda版本,我是离线安装的,在线安装选的cuda的也是CPU版本。
python init_database.py --recreate-vs运行
一键启动 API 服务或 Web UI
5.1 启动命令
一键启动脚本 startup.py,一键启动所有 FastChat 服务、API 服务、WebUI 服务,示例代码:
$ python startup.py -a
----------------------------------------------------------------------------------------------------------------------------
参考官方文档中的这个版本:
开发部署
软件需求
本项目已在 Python 3.8.1 - 3.10,CUDA 11.7 环境下完成测试。已在 Windows、ARM 架构的 macOS、Linux 系统中完成测试。
1. 开发环境准备
参见 开发环境准备。
安装
环境检查
# 首先,确信你的机器安装了 Python 3.8 - 3.10 版本 $ python --version Python 3.8.13 # 如果低于这个版本,可使用conda安装环境 $ conda create -p /your_path/env_name python=3.8 # 激活环境 $ source activate /your_path/env_name # 或,conda安装,不指定路径, 注意以下,都将/your_path/env_name替换为env_name $ conda create -n env_name python=3.8 $ conda activate env_name # Activate the environment # 更新py库 $ pip3 install --upgrade pip # 关闭环境 $ source deactivate /your_path/env_name # 删除环境 $ conda env remove -p /your_path/env_name
项目依赖
# 拉取仓库 $ git clone https://github.com/chatchat-space/Langchain-Chatchat.git # 进入目录 $ cd Langchain-Chatchat # 安装全部依赖 $ pip install -r requirements.txt # 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
此外,为方便用户 API 与 webui 分离运行,可单独根据运行需求安装依赖包。
-
如果只需运行 API,可执行:
$ pip install -r requirements_api.txt # 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
-
如果只需运行 WebUI,可执行:
$ pip install -r requirements_webui.txt
注:使用 langchain.document_loaders.UnstructuredFileLoader 进行 .docx 等格式非结构化文件接入时,可能需要依据文档进行其他依赖包的安装,请参考 langchain 文档。
请注意: 0.2.5 及更新版本的依赖包与 0.1.x 版本依赖包可能发生冲突,强烈建议新建环境后重新安装依赖包。
2. 下载模型至本地
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding 模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/ChatGLM2-6B 与 Embedding 模型 moka-ai/m3e-base 为例:
下载模型需要先安装 Git LFS,然后运行
$ git clone https://huggingface.co/THUDM/chatglm2-6b $ git clone https://huggingface.co/moka-ai/m3e-base
3. 设置配置项
复制相关参数配置模板文件 configs/*_config.py.example,存储至项目路径下 ./configs 路径下,并重命名为 *_config.py。
在开始执行 Web UI 或命令行交互前,请先检查 configs/model_config.py 和 configs/server_config.py 中的各项模型参数设计是否符合需求:
- 请确认已下载至本地的 LLM 模型本地存储路径(请使用绝对路径)写在
MODEL_PATH对应模型位置,如:
"chatglm2-6b": "/Users/xxx/Downloads/chatglm2-6b",
- 此处是在ubuntu下的目录位置方式。
- 请确认已下载至本地的 Embedding 模型本地存储路径写在
MODEL_PATH对应模型位置,如:
"m3e-base": "/Users/xxx/Downloads/m3e-base",
- 请确认本地分词器路径是否已经填写,如:
text_splitter_dict = {
"ChineseRecursiveTextSplitter": {
"source": "huggingface",
## 选择tiktoken则使用openai的方法,不填写则默认为字符长度切割方法。
"tokenizer_name_or_path": "",
## 空格不填则默认使用大模型的分词器。
}
}
如果你选择使用 OpenAI 的 Embedding 模型,请将模型的 key 写入 ONLINE_LLM_MODEL 中。使用该模型,你需要能够访问 OpenAI 官方的 API,或设置代理。
4. 知识库初始化与迁移
当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库(我们强烈建议您在执行操作前备份您的知识文件)。
-
如果您是从
0.1.x版本升级过来的用户,针对已建立的知识库,请确认知识库的向量库类型、Embedding 模型与configs/model_config.py中默认设置一致,如无变化只需以下命令将现有知识库信息添加到数据库即可:$ python init_database.py
-
如果您是第一次运行本项目,知识库尚未建立,或者配置文件中的知识库类型、嵌入模型发生变化,或者之前的向量库没有开启
normalize_L2,需要以下命令初始化或重建知识库:$ python init_database.py --recreate-vs
5. 一键启动 API 服务或 Web UI
5.1 启动命令
一键启动脚本 startup.py,一键启动所有 FastChat 服务、API 服务、WebUI 服务,示例代码:
$ python startup.py -a
并可使用 Ctrl + C 直接关闭所有运行服务。如果一次结束不了,可以多按几次。
可选参数包括 -a (或--all-webui), --all-api, --llm-api, -c (或--controller), --openai-api, -m (或--model-worker), --api, --webui,其中:
--all-webui为一键启动 WebUI 所有依赖服务;--all-api为一键启动 API 所有依赖服务;--llm-api为一键启动 FastChat 所有依赖的 LLM 服务;--openai-api为仅启动 FastChat 的 controller 和 openai-api-server 服务;- 其他为单独服务启动选项。
更多信息可以通过 python startup.py -h 查看
5.2 启动非默认模型
若想指定非默认模型,需要用 --model-name 选项,示例:
$ python startup.py --all-webui --model-name Qwen-7B-Chat
请注意,指定的模型必须在 model_config.py 中进行了配置。
5.3 多卡加载
项目支持多卡加载,需在 startup.py 中的 create_model_worker_app 函数中,修改如下三个参数:
gpus = None, num_gpus = 1, max_gpu_memory = "20GiB"
其中,gpus 控制使用的显卡的 ID,例如 "0,1";
num_gpus 控制使用的卡数;
max_gpu_memory 控制每个卡使用的显存容量。
注1:server_config.py 的 FSCHAT_MODEL_WORKERS 字典中也增加了相关配置,如有需要也可通过修改 FSCHAT_MODEL_WORKERS 字典中对应参数实现多卡加载。
注2:少数情况下,gpus 参数会不生效,此时需要通过设置环境变量 CUDA_VISIBLE_DEVICES 来指定 torch 可见的 GPU,示例代码:
CUDA_VISIBLE_DEVICES=0,1 python startup.py -a
5.4 PEFT 加载(包括 lora, p-tuning, prefix tuning, ia3等)
本项目基于 FastChat 加载 LLM 服务,故需以 FastChat 加载 PEFT 路径,即保证路径名称里必须有 peft 这个词,配置文件的名字为 adapter_config.json,peft 路径下包含 .bin 格式的 PEFT 权重,peft 路径在 startup.py 中 create_model_worker_app 函数的 args.model_names 中指定,并开启环境变量 PEFT_SHARE_BASE_WEIGHTS=true 参数。
注:如果上述方式启动失败,则需要以标准的 FastChat 服务启动方式分步启动。PEFT 加载详细步骤参考 加载 LoRA 微调后模型失效



















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











