









内容简介
收集了学习PCA的两个鸢尾花数据实例。
- 第一个案例:详细复盘了PCA降维课程的内容,将四个特征简化到两个,画二维图展示结果;
- 第二个案例:是sklearn上的例子,侧重于3维可视化,所以特征也是简化到3个。
原理简介:PCA降维,即将高维数据降到低维。比如原本特征值有4个,经过PCA方法后,选取前两个最重要的特征,将特征值降到2个。
例1: PCA降维流程
1. PCA详细流程
#工具包
import numpy as np
import pandas as pd
#导入数据
df = pd.read_csv('iris.data')
df.columns=['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'class']
#可视化分析-观察四个特征在不同类别的情况
from matplotlib import pyplot as plt
import math
label_dict = {1: 'Iris-Setosa',
2: 'Iris-Versicolor',
3: 'Iris-Virgnica'}
feature_dict = {0: 'sepal length [cm]',
1: 'sepal width [cm]',
2: 'petal length [cm]',
3: 'petal width [cm]'}
plt.figure(figsize=(8, 6))
for cnt in range(4):
plt.subplot(2, 2, cnt+1)
for lab in ('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'):
plt.hist(X[y==lab, cnt],
label=lab,
bins=10,
alpha=0.3,)
plt.xlabel(feature_dict[cnt])
plt.legend(loc='upper right', fancybox=True, fontsize=8)
plt.tight_layout()
plt.show()
结果输出:

#切分数据集(这里更新了原课件代码)
X = df.values[:,0:4]
y = df.values[:,4]
#将特征数据标准化
from sklearn.preprocessing import StandardScaler
X_std = StandardScaler().fit_transform(X)
print (X_std) #打印所有结果
#计算协方差矩阵方法
##详细版本
mean_vec = np.mean(X_std, axis=0) #计算均值
cov_mat = (X_std - mean_vec).T.dot((X_std - mean_vec)) / (X_std.shape[0]-1) #协方差矩阵
print('Covariance matrix \n%s' %cov_mat)
##简单版本
print('NumPy covariance matrix: \n%s' %np.cov(X_std.T))
上面两个版本计算出的的协方差矩阵结果都是一样的:

仔细观察,可以看到对角线上值约等于1,按对角线对称。
#计算特征值和特征向量
cov_mat = np.cov(X_std.T)
eig_vals, eig_vecs = np.linalg.eig(cov_mat)
print('Eigenvectors \n%s' %eig_vecs)
print('\nEigenvalues \n%s' %eig_vals)
结果显示:

Eigenvalues [ 2.92442837 0.93215233 0.14946373 0.02098259]
- 特征值大小,可以判断特征向量重要程度,特征值越大越重要。由结果可判断前两个特征重要程度较高
#将特征值和特征向量一一对应起来,第一行对应第一个,第二行对应第二个……
# Make a list of (eigenvalue, eigenvector) tuples
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))]
print (eig_pairs)
print ('----------')
# Sort the (eigenvalue, eigenvector) tuples from high to low
eig_pairs.sort(key=lambda x: x[0], reverse=True)
# Visually confirm that the list is correctly sorted by decreasing eigenvalues
print('Eigenvalues in descending order:')
for i in eig_pairs:
print(i[0])

#将结果转变成百分数
tot = sum(eig_vals)
var_exp = [(i / tot)*100 for i in sorted(eig_vals, reverse=True)] #计算百分数
print (var_exp)
cum_var_exp = np.cumsum(var_exp,dtype=list))#计算累加值,比如第一个值1, 第二个值等于第1、2值相加,第三个值等于第1,2,3个值相加……
cum_var_exp

- 第一二个特征占95%;第三个特征占99.4%,第四个特征小于1%;如果只要95,只选择前两个特征就足够了,下面画个图表更清晰地展现各个特征的占比情况。
#可视化显示,每个特征值占多少
plt.figure(figsize=(6, 4))
plt.bar(range(4), var_exp, alpha=0.5, align='center',
label='individual explained variance')
plt.step(range(4), cum_var_exp, where='mid',
label='cumulative explained variance')
plt.ylabel('Explained variance ratio')
plt.xlabel('Principal components')
plt.legend(loc='best')
plt.tight_layout()
plt.show()

从图中更直接地看到,前两个特征比较重要,后面两个特征占比很小,因此只需要取前面两个最重要的特征即可。
#提取前两个特征
matrix_w = np.hstack((eig_pairs[0][1].reshape(4,1),
eig_pairs[1][1].reshape(4,1)))
print('Matrix W:\n', matrix_w)
#计算
Y = X_std.dot(matrix_w)
Y
#可视化
#原来的图
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(X[y==lab, 0],
X[y==lab, 1],
label=lab,
c=col)
plt.xlabel('sepal_len')
plt.ylabel('sepal_wid')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
#降维后的结果
plt.figure(figsize=(6, 4))
for lab, col in zip(('Iris-setosa', 'Iris-versicolor', 'Iris-virginica'),
('blue', 'red', 'green')):
plt.scatter(Y[y==lab, 0],
Y[y==lab, 1],
label=lab,
c=col)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend(loc='lower center')
plt.tight_layout()
plt.show()
结果输出:
- 降维前二维图:红色和绿色混和在一起

- 降维后结果:比较降维前后两个图,降维后分类更加聚集,每个颜色的小点比降维前更集中。

2. 简略流程
这里直接使用sklearn.decomposition降维,更加简单方便。
#导入模块
import numpy as np
import matplotlib.pyplot as plt
from sklearn import decomposition
from sklearn import datasets
#导入数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
#建模降维
pca = decomposition.PCA(n_components=2) #降到二维
pca.fit(X)
X = pca.transform(X)
#作图
plt.figure(figsize=(6, 4))
for name, label in [('Setosa',0), ('Versicolour',1), ('Virginica',2)]:
plt.scatter(X[y==label, 0],
X[y==label, 1],
label=label,
)
plt.xlabel('sepal_len')
plt.ylabel('sepal_wid')
plt.legend(loc='best')
plt.tight_layout()
plt.show()
结果输出:直接使用pca = decomposition.PCA(n_components=2)比之前逐步计算的效果更加好。其中n_components表示保留几个特征值。

例2:PCA example with Iris Data-set 3D可视化
1.建模降维度
#导入数据包
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn import decomposition
from sklearn import datasets
# 导入函数
np.random.seed(5)
centers = [[1, 1], [-1, -1], [1, -1]]
iris = datasets.load_iris()
X = iris.data
y = iris.target
# PCA降维度
pca = decomposition.PCA(n_components=3) #降到三维
pca.fit(X)
X = pca.transform(X)
#打印X看看结果
X
结果输出:原本有4列数字,现在变成3列了。

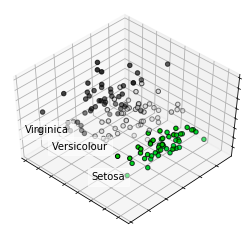
2. 3D可视化
#3D图
fig = plt.figure(1, figsize=(4, 3))
plt.clf()
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
plt.cla()
for name, label in [('Setosa', 0), ('Versicolour', 1), ('Virginica', 2)]:
ax.text3D(X[y == label, 0].mean(),
X[y == label, 1].mean() + 1.5,
X[y == label, 2].mean(), name,
horizontalalignment='center',
bbox=dict(alpha=.5, edgecolor='w', facecolor='w'))
# Reorder the labels to have colors matching the cluster results
y = np.choose(y, [1, 2, 0]).astype(np.float)
ax.scatter(X[:, 0], X[:, 1], X[:, 2], c=y, cmap=plt.cm.nipy_spectral,
edgecolor='k')
ax.w_xaxis.set_ticklabels([])
ax.w_yaxis.set_ticklabels([])
ax.w_zaxis.set_ticklabels([])
plt.show()
结果输出:















 3892
3892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









