






Suppose that has two variables{
1,
2}
Randomly start at

Vanilla Gradient descent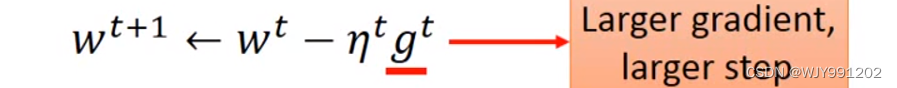
梯度越大,步伐越大
Adagrad
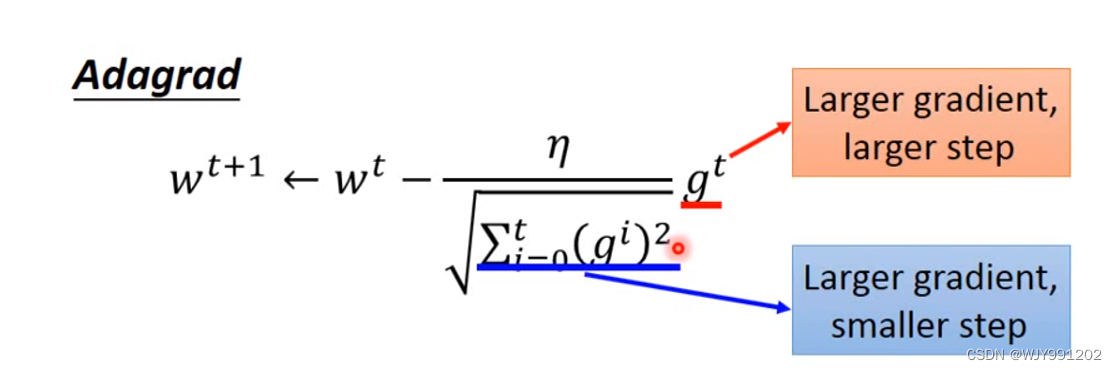
泰勒展开式:如果红色圆圈足够小,在红色圆圈内找到误差最小的值是L()
L() ≈ s + μ(
1-a) + v(
2-b)
找到最小值在红色圆圈内
(1-a)²+(
2-b)² <= d²
(1-a) = Δ
1
(2-b) = Δ
2
optimization
优化器: 找出一个参数,越贴近越好,降低的Loss越多越好。
找到一组参数获得最低的L()
SGDM+RMSProp
SGD
with momentum
自动提升优化器
Adagrad
RMSProp
Adam
改进SGDM
One-cycle LR
warm-up + annealing +fine-tuning
调整learning-rate















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









