







目录
原文链接:A Gentle Introduction to Graph Neural Networks
BG
图表示:实体和实体之间的关系
- V->vertex(or node) 用向量来描述顶点属性
- E->Edge(or link) 用向量来描述边属性
- U->Global(or naster node) 用向量来描述全局属性
数据如何表示成图
1.图片表示为图
244x244x3,一般来说会表示成三个维度的tensor,输入卷积神经网络
当作图:每个像素是一个点,邻接就有边

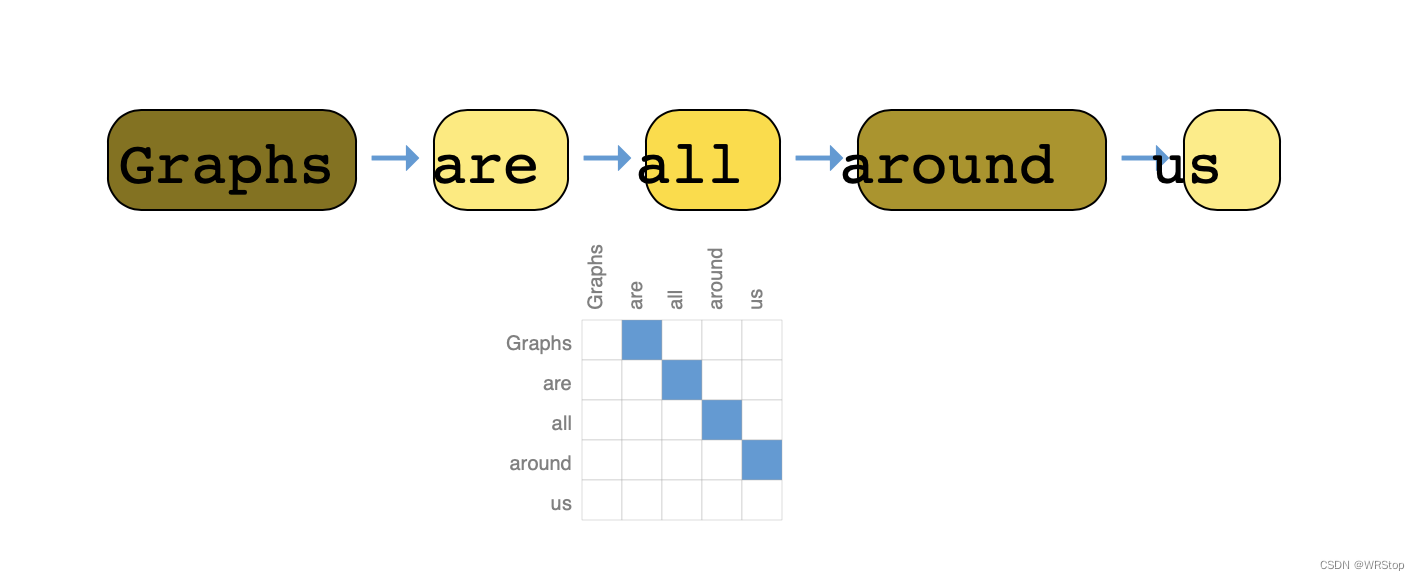
2.文本表示为图
文本可以认为是一个序列,一个词是一个顶点,一个词与下一个词之间有一条有向边
3.分子表示为图

4.社交网络表示为图
图上面可以定义什么样的问题
1.图层面的问题
2.顶点层面的问题
3.边层面的问题
机器学习用到图上有什么挑战
怎么表示图让他跟神经网络兼容
邻接表稀疏(高效计算稀疏矩阵能力不ok,特别是把计算稀疏矩阵用到GPU上面一直是一个比较难的问题),而且邻接表旋转前/后会影响网络的输出:旋转前/后的输入自然不同,但我们要求其给网络后的结果理应一样。所以使用邻接列表存储,得到高效存储和顺序/旋转无影响。

adjacency:第i项=第i条边,连接[x,y]两个顶点
GNN
定义:对图上所有属性(顶点、边、全局的上下文)进行的一个可以优化的变换,可以保持住图的对称信息(也就是把节点进行重新排序之后的结果是不会变化的)
输入:图
输出:图
简单情况
对于顶点向量、边向量、全局向量,分别构造一个MLP,三个MLP组成了一个GNN的层
输出只是属性向量被改变了,但是整体图的结构没有变化

结果预测:输出的最后一个图中的每一个顶点输入全连接层(作为输出层),就可以对顶点作分类。(这里只有一个全连接层,所有的顶点共享一个全连接层的参数,之前的MLP也是,所有的顶点共享一个MLP。边和全局同理)

27‘全连接层!!!!!!!再看看!!!!!
想对顶点做预测但是没有顶点向量描述属性怎么办
解决:pooling
前提假设:所有顶点、边、全局向量的维度都相同。(不一样的话就需要做一些投影)
把没有向量的顶点所连接的边,以及全局向量拿出来(比如图中顶点向量缺失后就需要拿出5个向量),向量相加就代表此顶点的向量

但是这种简单结构最大的问题是,在GNN blocks中没有使用图的结构信息
信息传递
(除了+,concat也可以)
1.顶点与顶点间
对某一个顶点向量进行更新时,把所有邻居向量与自身向量相加后再输入MLP

跟卷积有一些像但有区别!!!!!!!!33’
“1”表示1近邻,即距离为1的邻居,一层只汇聚其距离为1的邻居的信息。但是很多层之后,其实一个节点上就会把邻居的邻居的邻居的...信息都汇聚过来。

2.顶点与边之间
边连接的顶点向量加到边向量上,同理顶点连接的边向量加到顶点向量上,完成两次传递之后,进入各自的MLP进行更新。顶点的信息给边,然后边做更新,然后把接收过顶点信息的边的信息传递给顶点,顶点再做更新。

同样的,存在先边后顶点, 也就存在先顶点后边,他们的结果不同但无法说明谁好谁坏,所以作者提出可以同时进行,如图:
3.全局
如果一张图足够大且连接没有那么紧密时,一个消息从一个点传递到另一个很远的点通过以上方式需要走很长的路,所以加入master node/context vector:可以跟所有的边、顶点相连。所以给边汇聚信息时,U与V都要汇聚过来。

可以认为GNN是一个attention mechanism ????
GNN playground
GNN训练程序嵌入到JS中,做了一个比较小的分子图的预测数据集,我们可以调节图神经网络里不同的超参数,来观察实际训练的效果。
可调节超参数有:
图神经网络的层数(1-4)
aggregation的实际做法(sum,mean,max),mean与max分别代表了卷积神经网络池化层的max pooling 与 average pooling
顶点、边、全局向量都有多大,也可以选择不对某一方面学习。
每次50epoch,输出AUC。
调参
什么样的参数可以调出好的效果?作者给出了一张图表示不同超参数对应的训练效果。可以看出模型参数变高时,AUC的上限是在增高的,但哪怕模型很大,参数调的不好也会跌到跟小模型一样。

具体分析
每一个属性向量的长度(统计学经典图boxplot箱线图,对于x轴特定的向量长度,变换其他参数看AUC的变化范围,中间横线为中值,横线上下的柱状bar为25%与75%的quantile(分位数),也就是只有25%和25%的点落在了bar所对应的的AUC之外,横线尽头时最小值和最大值)总体是希望中值越大越好,bar越短越好(太长则表示非常敏感)。

GNN层数,从boxplot可以看出层数越高中值越高,但是方差比较大(所以哪怕层数调高,也需要其他参数调的够好)

不同的aggregation操作,区别不大(至少在这个数据集上)

哪些属性之间传递信息,可以看出传递信息后效果更好一些,但是存在outlayer离群

总之,GNN对参数比较敏感,调的空间比较大
其他相关问题
特殊图
Mutigraph,顶点之间可以有多种不同的边
图可能是分层的,一个顶点可能代表了一张图
如何采样和batch
如果一个图的连通性足够,那么最后肯定有点可以看到整个图。计算梯度时,要存储整个forward里所有的中间结果,如果要计算最后这个点,那么就要存储所有的中间结果,计算可能无法承受。故需要进行采样:每次采一个小图出来在小图上做pooling,这样算梯度的时候只需要把小图上中间结果记录下来即可。
采样方法:(1)随机采点,然后找他的邻居组成子图。(2)随机游走。规定最多随机走多少步,形成一个子图。(3)1、2结合,随机走x 步,然后把x个点的邻居找出来组成子图。(4)取一个点找到其1、2、3...k近邻。
性能上考虑,不想对每一个顶点做逐步逐步更新,每一步计算量太小不利于并行。53’!!!!!!!!!!!!!!!!!!!!
inductive biases
模型都在假设的条件下存在,卷积神经网络假设的是空间变换的不变性,循环神经网络假设的事时序的连续性,GNN假设保持图的对称性(不管如何交换顶点的顺序)。
aggregation操作
其实三种方法都不是特别理想,实际应用中要具体问题具体选择。
......















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









