







Motivation
- 小部分节点key players在复杂系统/网络中发挥重要作用
- Finding an optimal set of key players in complex networks has been a long-standing problem in network science, with many real-world applications
- Finding an optimal set of key players in general graphs that optimizes nontrivial and hereditary connectivity measures is typically NP-hard.NP-hard带来的解决方案不通用、无法扩展的问题。
Settings
- 训练图与测试图的生成:Three classic network models, the Erdős–Rényi (ER) model34 , the Watts–Strogatz (WS) 35 model and the Barabási–Albert (BA) model36 , were used to generate both training and test graphs.
- 训练图与测试图特征:In all cases, FINDER is trained on BA graphs of 30–50 nodes. We then evaluate the well-trained FINDER on synthetic BA graphs of different scales: 30–50, 50–100, 100–200, 200–300, 300–400 and 400–500 nodes. For each scale, we randomly generated 100 instances, and reported the average results over them. To obtain node-weighted graphs, we assign each node a normalized weight, which is proportional to its degree (degree-weighted) or a random non-negative number (random-weighted).
- 关于度量图的指标:pairwise connectivity,the size of the GCC(GCC-giant connected component 极大连通分量)
- 最终target与指标:minimizes the following accumulated normalized connectivity (ANC)
Model

offline的选择策略是select the highest-Q node with probability (1 − ε) and take a random action otherwise;real word的选择策略是’batch nodes selection’
GNN与RL结合
E、A、R定义:the environment is the network being analysed, the state is defined as the residual network, the action is to remove or activate the identified key player, and the reward is the decrease of the ANC (equation (1) or equation (2)) after taking the action.
Encode
利用基于图神经网络的图表示学习(又名图嵌入) 将网络结构信息表征为低维embedding space。节点之间迭代信息传递。加入虚拟全局节点。
embedding-就是用一个低维的向量表示一个物体,可以是一个词,或是一个商品,或是一个电影等等。这个embedding向量的性质是能使距离相近的向量对应的物体有相近的含义,比如 Embedding(复仇者联盟)和Embedding(钢铁侠)之间的距离就会很接近,但 Embedding(复仇者联盟)和Embedding(乱世佳人)的距离就会远一些。Embedding能够用低维向量对物体进行编码还能保留其含义的特点非常适合深度学习
除此之外Embedding甚至还具有数学运算的关系,比如Embedding(马德里)-Embedding(西班牙)+Embedding(法国)≈Embedding(巴黎)
Decode
为 score 函数设计了一个深度参数化,即 Q 函数。 Q 函数利用来自编码器的状态和动作的嵌入来计算评估潜在动作质量的分数。具体来说,将外积操作应用于状态和动作的嵌入,以建模更精细的状态-动作依赖关系。然后使用具有校正线性单元激活的多层感知器将外积映射到标量值。
outer product
向量的外积(outer product)与克罗内克积(Kronecker)_努力干活还不粘人的小妖精的博客-CSDN博客_向量的克罗内克积
----------------------------------------------------------------------------------------------
Adam gradient descent
梯度下降的可视化解释(Adam,AdaGrad,Momentum,RMSProp)_视学算法的博客-CSDN博客
TensorFlow 常用优化器:GradientDescent、Momentum、Adam_机器学习Zero的博客-CSDN博客_adam tensorflow
Results
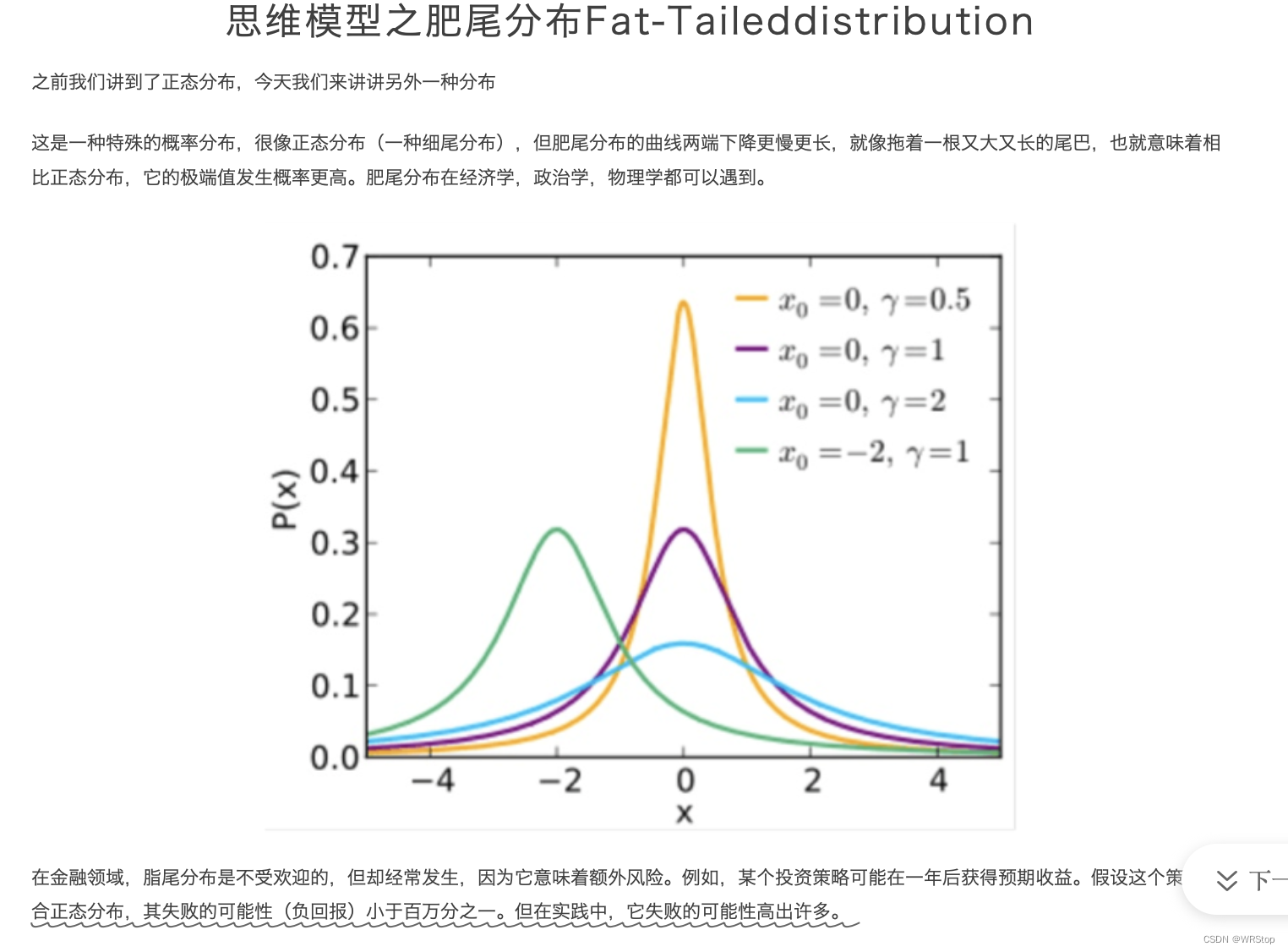
· 由于BA的高度异质性(power-law or fat-tailed degree distributions?)在各种真实的网络测试中,接受BA图训练的代理的表现始终优于接受ER或WS图训练的代理。
power-law or fat-tailed degree distributions

Performance of FiNDer on synthetic graphs

Performance of FiNDer on real-world networks

Cost distributions of key players identified by Finder
FINDER 倾向于避免选择那些“昂贵”的关键参与者,这自然会导致更具成本效益的策略。

不需要特定领域的知识,只需要真实网络的程度异质性,FINDER 通过针对特定应用场景仅在小型合成图上离线自我训练一次来实现这一目标,然后在现实世界网络的不同领域中具有惊人的泛化能力更大的尺寸。
呈现的结果还强调了经典网络模型的重要性,例如 BA 模型。虽然非常简单,但它捕获了许多现实世界网络的关键特征,即度异质性,这对于解决复杂网络上极具挑战性的优化问题非常有用
总结优点:可以在小图上训练应用到大图上,通用,速度快。
other
对偶问题
任何一个求极大化的线性规划问题都有一个求极小化的线性规划问题与之对应,反之亦然,如果我们把其中一个叫原问题,则另一个就叫做它的对偶问题,并称这一对互相联系的两个问题为一对对偶问题。
什么是对偶问题_nciaebupt的博客-CSDN博客_对偶问题
Markov decision process














 2144
2144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









