









目录
1、模型量化是什么?
简而言之,所谓的模型量化就是将浮点存储(运算)转换为整型存储(运算)的一种模型压缩技术。简单直白点讲,即原来表示一个权重需要使用float32表示,量化后只需要使用int8来表示就可以啦,仅仅这一个操作,我们就可以获得接近4倍的网络加速!
2、为什么需要做模型量化?
随着深度学习技术在多个领域的快速应用,具体包括计算机视觉-CV、自然语言处理-NLP、语音等,出现了大量的基于深度学习的网络模型。这些模型都有一个特点,即大而复杂、适合在N卡上面进行推理,并不适合应用在手机等嵌入式设备中,而客户们通常需要将这些复杂的模型部署在一些低成本的嵌入式设备中,因而这就产生了一个矛盾。为了很好的解决这个矛盾,模型量化应运而生,它可以在损失少量精度的前提下对模型进行压缩,使得将这些复杂的模型应用到手机、机器人等嵌入式终端中变成了可能。
随着模型预测越来越准确,网络越来越深,神经网络消耗的内存大小成为一个核心的问题,尤其是在移动设备上。通常情况下,目前的手机一般配备 4GB 内存来支持多个应用程序的同时运行,而三个模型运行一次通常就要占用1GB内存。
模型大小不仅是内存容量问题,也是内存带宽问题。模型在每次预测时都会使用模型的权重,图像相关的应用程序通常需要实时处理数据,这意味着至少 30 FPS。因此,如果部署相对较小的 ResNet-50 网络来分类,运行网络模型就需要 3GB/s 的内存带宽。网络运行时,内存,CPU 和电池会都在飞速消耗,我们无法为了让设备变得智能一点点就负担如此昂贵的代价。
3、模型量化动机是什么?
-
更少的存储开销和带宽需求。即使用更少的比特数存储数据,有效减少应用对存储资源的依赖,但现代系统往往拥有相对丰富的存储资源,这一点已经不算是采用量化的主要动机;
-
更快的计算速度。即对大多数处理器而言,整型运算的速度一般(但不总是)要比浮点运算更快一些;
-
更低的能耗与占用面积。
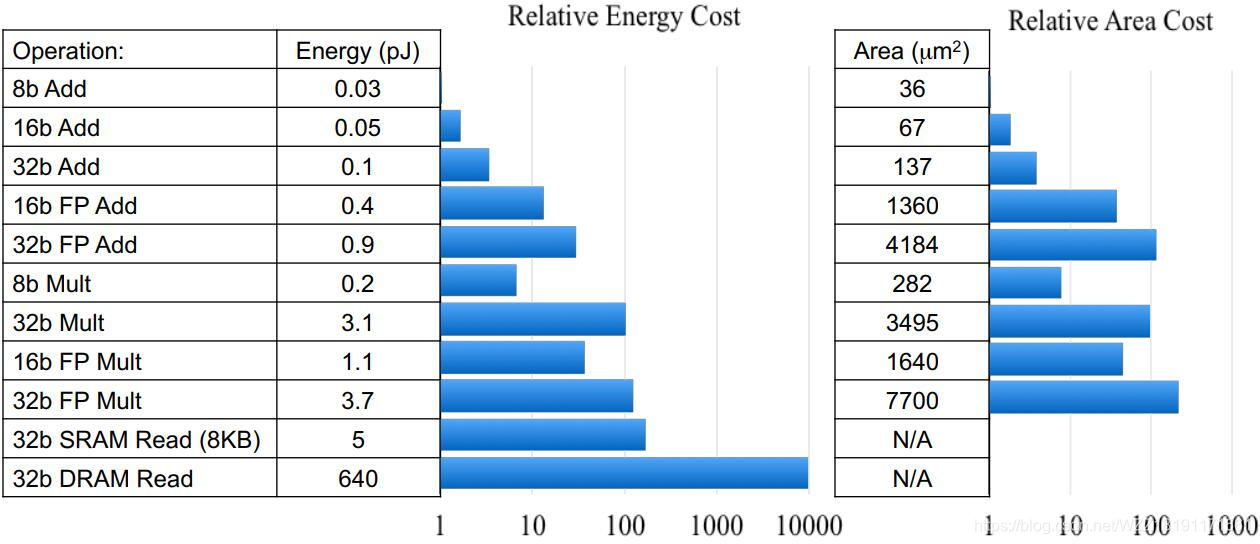
从上图中可以看到,FP32乘法运算的能耗是INT8乘法运算能耗的18.5倍,芯片占用面积则是int8的27.3倍,而对于芯片设计和FPGA设计而言,更少的资源占用意味着相同数量的单元下可以设计出更多的计算单元;而更少的能耗意味着更少的发热,和更长久的续航。 -
尚可接受的精度损失。即量化相当于对模型权重引入噪声,所幸CNN本身对噪声不敏感(在模型训练过程中,模拟量化所引入的权重加噪还有利于防止过拟合),在合适的比特数下量化后的模型并不会带来很严重的精度损失。按照gluoncv提供的报告,经过int8量化之后,ResNet50_v1和MobileNet1.0 _v1在ILSVRC2012数据集上的准确率仅分别从77.36%、73.28%下降为76.86%、72.85%。
-
支持int8是一个大的趋势。即无论是移动端还是服务器端,都可以看到新的计算设备正不断迎合量化技术。比如NPU/APU/AIPU等基本都是支持int8(甚至更低精度的int4)计算的,并且有相当可观的TOPs,而Mali GPU开始引入int8 dot支持,Nvidia也不例外。除此之外,当前很多创业公司新发布的边缘端芯片几乎都支持int8类型。
4、模型量化分类
根据映射函数是否是线性可以分为两类-即线性量化和非线性量化,本文主要研究的是线性量化技术。
4.1 线性量化
常见的线性量化过程可以用以下数学表达式来表示:
r
=
Round
(
S
(
q
−
Z
)
)
r=\operatorname{Round}(S(q-Z))
r=Round(S(q−Z))。
其中,q 表示的是原始的float32数值;
Z表示的是float32数值的偏移量,在很多地方又叫Zero Point;
S表示的是float32的缩放因子,在很多地方又叫Scale;
Round(⋅) 表示的是四舍五入近似取整的数学函数,除了四舍五入,使用向上或者向下取整也是可以的;
r表示的是量化后的一个整数值。
根据参数 Z 是否为零可以将线性量化分为两类—即对称量化和非对称量化。
4.1.1 对称量化

如上图所示,所谓的对称量化,即使用一个映射公式将输入数据映射到[-128,127]的范围内,图中-max(|Xf|)表示的是输入数据的最小值,max(|Xf|)表示输入数据的最大值。对称量化的一个核心即零点的处理,映射公式需要保证原始的输入数据中的零点通过映射公式后仍然对应[-128,127]区间的零点。总而言之,对称量化通过映射关系将输入数据映射在[-128,127]的范围内,对于映射关系而言,我们需要求解的参数即Z和S。
在对称量化中,r 是用有符号的整型数值(int8)来表示的,此时 Z=0,且 q=0时恰好有r=0。在对称量化中,我们可以取Z=0,S的取值可以使用如下的公式,也可以采用其它的公式。
S
=
2
n
−
1
−
1
max
(
∣
x
∣
)
S=\frac{2^{n-1}-1}{\max (|x|)}
S=max(∣x∣)2n−1−1
其中,n 是用来表示该数值的位宽,x 是数据集的总体样本。
4.1.2 非对称量化

如上图所示,所谓的非对称量化,即使用一个映射公式将输入数据映射到[0,255]的范围内,图中min(Xf)表示的是输入数据的最小值,max(Xf)表示输入数据的最大值。总而言之,对称量化通过映射关系将输入数据映射在[0,255]的范围内,对于映射关系而言,我们需要求解的参数即Z和S。
在非对称量化中,r 是用有符号的整型数值(uint8)来表示的。在非对称量化中,我们可以取Z=min(x),S的取值可以使用如下的公式,也可以采用其它的公式。
S
=
2
n
−
1
−
1
max
(
x
)
−
min
(
x
)
S=\frac{2^{n-1}-1}{\max (x)-\min (x)}
S=max(x)−min(x)2n−1−1
4.2 逐层量化、逐组量化和逐通道量化
根据量化的粒度(共享量化参数的范围)可以分为逐层量化、逐组量化和逐通道量化。
- 逐层量化以一个层为单位,整个layer的权重共用一组缩放因子S和偏移量Z;
- 逐组量化以组为单位,每个group使用一组S和Z;
- 逐通道量化则以通道为单位,每个channel单独使用一组S和Z;
当 group=1 时,逐组量化与逐层量化等价;当 group=num_filters (即dw卷积)时,逐组量化逐通道量化等价。
4.3 在线量化和离线量化
根据激活值的量化方式,可以分为在线(online)量化和离线(offline)量化。
- 在线量化,即指激活值的S和Z在实际推断过程中根据实际的激活值动态计算;
- 离线量化,即指提前确定好激活值的S和Z;
由于不需要动态计算量化参数,通常离线量化的推断速度更快些,通常通过以下的三种方法来确定相关的量化参数。
- 指数平滑法。即将校准数据集送入模型,收集每个量化层的输出特征图,计算每个batch的S和Z值,并通过指数平滑法来更新S和Z值。
- 直方图截断法。即在计算量化参数Z和S的过程中,由于有的特征图会出现偏离较远的奇异值,导致max非常大,所以可以通过直方图截取的形式,比如抛弃最大的前1%数据,以前1%分界点的数值作为max计算量化参数。
- KL散度校准法。-即通过计算KL散度(也称为相对熵,用以描述两个分布之间的差异)来评估量化前后的两个分布之间存在的差异,搜索并选取KL散度最小的量化参数Z和S作为最终的结果。Tensorflow中就采用了这种方法。
4.4 比特量化
根据存储一个权重元素所需的位数,可以将其分为8bit量化、4bit量化、2bit量化和1bit量化等。
- 二进制神经网络。即在运行时具有二进制权重和激活的神经网络,以及在训练时计算参数的梯度。
- 三元权重网络。即权重约束为+1,0和-1的神经网络。
- XNOR网络。即过滤器和卷积层的输入是二进制的。XNOR 网络主要使用二进制运算来近似卷积。
4.5 权重量化和权重激活量化
根据需要量化的参数可以分类两类-权重量化和权重激活量化。
- 权重量化,即仅仅需要对网络中的权重执行量化操作。由于网络的权重一般都保存下来了,因而我们可以提前根据权重获得相应的量化参数S和Z。由于仅仅对权重执行了量化,这种量化方法的压缩力度不是很大。
- 权重激活量化,即不仅对网络中的权重进行量化,还对激活值进行量化。由于激活层的范围通常不容易提前获得,因而需要在网络推理的过程中进行计算或者根据模型进行大致的预测。
5、模型量化原理详解
5.1 原理详解
模型量化桥接了定点与浮点,建立了一种有效的数据映射关系,使得以较小的精度损失代价获得了较好的收益,要弄懂模型量化的原理就是要弄懂这种数据映射关系。
浮点转换为定点的公式如下所示:
Q
=
R
S
+
Z
Q=\frac{R}{S}+Z
Q=SR+Z
定点转换为浮点的公式如下所示:
R
=
(
Q
−
Z
)
∗
S
R=(Q-Z) * S
R=(Q−Z)∗S
其中R表示输入的浮点数据,Q表示量化之后的定点数据,Z表示Zero Point的数值,S表示Scale的数值,我们可以根据S和Z这两个参数来确定这个映射关系。求解S和Z有很多种方法,这里列举中其中的一种求解方式如下:
S
=
R
max
−
R
min
Q
max
−
Q
min
S=\frac{R_{\max }-R_{\min }}{Q_{\max }-Q_{\min }}
S=Qmax−QminRmax−Rmin
其中
R
max
R_{\max }
Rmax表示输入浮点数据中的最大值,
R
min
R_{\min }
Rmin表示输入浮点数据中的最小值,
Q
max
Q_{\max }
Qmax表示最大的定点值(127/255),
Q
min
Q_{\min }
Qmin表示最小的定点值(-128/0)。
Z
=
Q
max
−
R
max
÷
S
Z=Q_{\max }-R_{\max } \div S
Z=Qmax−Rmax÷S
每通道或每张量的权重用int8进行定点量化的可表示范围为[-127,127],且zero-point就是量化值0;
每张量的激活值或输入值用int8进行定点量化的可表示范围为[-128,127],其zero-point在[-128,127]内依据公式求得;
5.2 具体案例
训练后的模型权重或激活值往往在一个有限的范围内分布,如激活值范围为[-2.0, 6.0],然后我们使用int8进行模型量化,则定点量化值范围为[-128, 127],那么S和Z的求值过程如下所示:
S
=
6.0
−
(
−
2.0
)
127
−
(
−
128
)
=
8.0
255
≈
0.031372549
Z
=
127
−
6.031372549
≈
127
−
191.25
≈
−
64.25
≈
−
64
\begin{array}{l}{S=\frac{6.0-(-2.0)}{127-(-128)}=\frac{8.0}{255} \approx 0.031372549} \\ {Z=127-6.031372549 \approx 127-191.25 \approx-64.25 \approx-64}\end{array}
S=127−(−128)6.0−(−2.0)=2558.0≈0.031372549Z=127−6.031372549≈127−191.25≈−64.25≈−64
如果此时我们有一个真实的激活值为0.28即R=0.28,那么对应Q的求解过程如下所示:
Q
=
0.28
÷
0.031372549
+
(
−
64
)
≈
8.925
−
64
≈
−
55.075
≈
−
55
Q=0.28 \div 0.031372549+(-64) \approx 8.925-64 \approx-55.075 \approx-55
Q=0.28÷0.031372549+(−64)≈8.925−64≈−55.075≈−55
整个网络中的其它参数也按照这种方法就可以获得量化之后的数值。
6、模型量化实现步骤
对于模型量化任务而言,具体的执行步骤如下所示:
- 步骤1-在输入数据(通常是权重或者激活值)中统计出相应的min_value和max_value;
- 步骤2-选择合适的量化类型,对称量化(int8)还是非对称量化(uint8);
- 步骤3-根据量化类型、min_value和max_value来计算获得量化的参数Z/Zero point和S/Scale;
- 步骤4-根据标定数据对模型执行量化操作,即将其由FP32转换为INT8;
- 步骤5-验证量化后的模型性能,如果效果不好,尝试着使用不同的方式计算S和Z,重新执行上面的操作;
7、Pytorch模型量化详解
7.1 简介
具体的细节请参考该链接。
量化是指用于执行计算并以低于浮点精度的位宽存储张量的技术。量化模型对张量使用整数而不是浮点值执行部分或全部运算。这允许更紧凑的模型表示,并在许多硬件平台上使用高性能矢量化操作。与典型的FP32型号相比,PyTorch支持INT8量化,从而可将模型尺寸减少4倍,并将内存带宽要求减少4倍。与FP32计算相比,对INT8计算的硬件支持通常快2到4倍。量化主要是一种加速推理的技术,并且量化算子仅支持前向传递。
PyTorch支持多种量化深度学习模型的方法。在大多数情况下,该模型在FP32中训练,然后将模型转换为INT8。此外,PyTorch还支持训练时量化,该训练使用伪量化模块对前向和后向传递中的量化误差进行建模。注意,整个计算是在浮点数中进行的。在量化意识训练结束时,PyTorch提供转换功能,将训练后的模型转换为较低的精度。
PyTorch支持每个张量和每个通道非对称线性量化。每个张量意味着张量内的所有值都以相同的方式缩放。每通道意味着对于每个尺寸(通常是张量的通道尺寸),张量中的值都按比例缩放并偏移一个不同的值(实际上,比例和偏移成为矢量)。这样可以在将张量转换为量化值时减少误差。为了在PyTorch中进行量化,我们需要能够以张量表示量化数据。量化张量允许存储量化数据(表示为int8 / uint8 / int32)以及诸如scale和zero_point之类的量化参数。量化张量除了允许以量化格式序列化数据外,还允许许多有用的操作使量化算术变得容易。
7.2 pytorch量化工作流程详解
PyTorch提供了三种量化模型的方法,具体包括训练后动态量化、训练后静态量化和训练时量化。
- 训练后动态量化。这是最简单的量化形式,其中权重被提前量化,而激活在推理过程中被动态量化。这种方法用于模型执行时间由从内存加载权重而不是计算矩阵乘法所支配的情况,这适用于批量较小的LSTM和Transformer类型。对整个模型应用动态量化只需要调用一次torch.quantization.quantize_dynamic()函数即可完成具体的细节请参考该量化教程。
- 训练后静态量化。这是最常用的量化形式,其中权重是提前量化的,并且基于在校准过程中观察模型的行为来预先计算激活张量的比例因子和偏差。CNN是一个典型的用例,训练后量化通常是在内存带宽和计算节省都很重要的情况下进行的。进行训练后量化的一般过程如下所示:
步骤1-准备模型:通过添加QuantStub和DeQuantStub模块,指定在何处显式量化和反量化激活值;确保不重复使用模块;将需要重新量化的任何操作转换为模块的模式;
步骤2-将诸如conv + relu或conv + batchnorm + relu之类的组合操作融合在一起,以提高模型的准确性和性能;
步骤3-指定量化方法的配置,例如选择对称或非对称量化以及MinMax或L2Norm校准技术;
步骤4- 插入torch.quantization.prepare()模块来在校准期间观察激活张量;
步骤5-使用校准数据集对模型执行校准操作;
步骤6-使用torch.quantization.convert() 模块来转化模型,具体包括计算并存储每个激活张量要使用的比例和偏差值,并替换关键算子的量化实现等。 - 训练时量化。在极少数情况下,训练后量化不能提供足够的准确性,可以插入torch.quantization.FakeQuantize()模块执行训练时量化。计算将在FP32中进行,但将值取整并四舍五入以模拟INT8的量化效果。具体的量化步骤如下所示:
步骤1-准备模型:通过添加QuantStub和DeQuantStub模块,指定在何处显式量化和反量化激活值;确保不重复使用模块;将需要重新量化的任何操作转换为模块的模式;
步骤2-将诸如conv + relu或conv + batchnorm + relu之类的组合操作融合在一起,以提高模型的准确性和性能;
步骤3-指定伪量化方法的配置,例如选择对称或非对称量化以及MinMax或L2Norm校准技术;
步骤4-插入torch.quantization.prepare_qat() 模块,该模块用来在训练过程中的模拟量化;
步骤5-训练或者微调模型;
步骤6-使用torch.quantization.convert() 模块来转化模型,具体包括计算并存储每个激活张量要使用的比例和偏差值,并替换关键算子的量化实现等。
7.3 Pytorch模型量化代码实战
# 导入第三方的库函数
import os
from io import open
import time
import torch
import torch.nn as nn
import torch.quantization
import torch.nn.functional as F
# 创建LSTM模型类
class LSTMModel(nn.Module):
"""整个网络包含一个encoder, 一个recurrent模块和一个decoder."""
def __init__(self, ntoken, ninp, nhid, nlayers, dropout=0.5):
super(LSTMModel, self).__init__()
# 预定义一些网络层
self.drop = nn.Dropout(dropout)
self.encoder = nn.Embedding(ntoken, ninp)
self.rnn = nn.LSTM(ninp, nhid, nlayers, dropout=dropout)
self.decoder = nn.Linear(nhid, ntoken)
self.init_weights()
self.nhid = nhid
self.nlayers = nlayers
def init_weights(self):
'''
初始化模型权重
'''
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self, input, hidden):
'''
搭建网络并执行前向推理
'''
emb = self.drop(self.encoder(input))
output, hidden = self.rnn(emb, hidden)
output = self.drop(output)
decoded = self.decoder(output)
return decoded, hidden
def init_hidden(self, bsz):
'''
初始化hidden层的权重
'''
weight = next(self.parameters())
return (weight.new_zeros(self.nlayers, bsz, self.nhid),
weight.new_zeros(self.nlayers, bsz, self.nhid))
# 创建一个词典类,用来处理数据
class Dictionary(object):
def __init__(self):
self.word2idx = {}
self.idx2word = []
def add_word(self, word):
'''
在词典中添加新的word
'''
if word not in self.word2idx:
self.idx2word.append(word)
self.word2idx[word] = len(self.idx2word) - 1
return self.word2idx[word]
def __len__(self):
'''
返回词典的长度
'''
return len(self.idx2word)
class Corpus(object):
def __init__(self, path):
self.dictionary = Dictionary()
# 分别获取训练集、验证集和测试集
self.train = self.tokenize(os.path.join(path, 'train.txt'))
self.valid = self.tokenize(os.path.join(path, 'valid.txt'))
self.test = self.tokenize(os.path.join(path, 'test.txt'))
def tokenize(self, path):
"""对输入的文件执行分词操作"""
assert os.path.exists(path)
# 将新的单词添加到词典中
with open(path, 'r', encoding="utf8") as f:
for line in f:
words = line.split() + ['<eos>']
for word in words:
self.dictionary.add_word(word)
# 标记文件的内容
with open(path, 'r', encoding="utf8") as f:
idss = []
for line in f:
words = line.split() + ['<eos>']
ids = []
for word in words:
ids.append(self.dictionary.word2idx[word])
idss.append(torch.tensor(ids).type(torch.int64))
ids = torch.cat(idss)
return ids
# 设置模型的路径
model_data_filepath = 'data/'
corpus = Corpus(model_data_filepath + 'wikitext-2')
ntokens = len(corpus.dictionary)
# 搭建网络模型
model = LSTMModel(
ntoken = ntokens,
ninp = 512,
nhid = 256,
nlayers = 5,
)
# 装载预训练的权重
model.load_state_dict(
torch.load(
model_data_filepath + 'word_language_model_quantize.pth',
map_location=torch.device('cpu')
)
)
# 将模型切换为推理模式,并打印整个模型
model.eval()
print(model)
# 获取一个随机的输入数值
input_ = torch.randint(ntokens, (1, 1), dtype=torch.long)
hidden = model.init_hidden(1)
temperature = 1.0
num_words = 1000
# 遍历数据集进行前向推理并将结果保存起来
with open(model_data_filepath + 'out.txt', 'w') as outf:
with torch.no_grad(): # no tracking history
for i in range(num_words):
output, hidden = model(input_, hidden)
word_weights = output.squeeze().div(temperature).exp().cpu()
word_idx = torch.multinomial(word_weights, 1)[0]
input_.fill_(word_idx)
word = corpus.dictionary.idx2word[word_idx]
outf.write(str(word.encode('utf-8')) + ('\n' if i % 20 == 19 else ' '))
if i % 100 == 0:
print('| Generated {}/{} words'.format(i, 1000))
with open(model_data_filepath + 'out.txt', 'r') as outf:
all_output = outf.read()
print(all_output)
bptt = 25
criterion = nn.CrossEntropyLoss()
eval_batch_size = 1
# 创建测试数据集
def batchify(data, bsz):
# 对测试数据集进行分块
nbatch = data.size(0) // bsz
# 去掉多余的元素
data = data.narrow(0, 0, nbatch * bsz)
# 在bsz批处理中平均划分数据
return data.view(bsz, -1).t().contiguous()
test_data = batchify(corpus.test, eval_batch_size)
# 获取bath块的输入数据
def get_batch(source, i):
seq_len = min(bptt, len(source) - 1 - i)
data = source[i:i+seq_len]
target = source[i+1:i+1+seq_len].view(-1)
return data, target
def repackage_hidden(h):
"""
用新的张量把隐藏的状态包装起来,把它们从历史中分离出来
"""
if isinstance(h, torch.Tensor):
return h.detach()
else:
return tuple(repackage_hidden(v) for v in h)
# 评估函数
def evaluate(model_, data_source):
# 打开评估模式
model_.eval()
total_loss = 0.
hidden = model_.init_hidden(eval_batch_size)
with torch.no_grad():
for i in range(0, data_source.size(0) - 1, bptt):
# 获取测试数据
data, targets = get_batch(data_source, i)
# 执行前向推理
output, hidden = model_(data, hidden)
hidden = repackage_hidden(hidden)
output_flat = output.view(-1, ntokens)
# 获取训练loss
total_loss += len(data) * criterion(output_flat, targets).item()
return total_loss / (len(data_source) - 1)
# 初始化动态量化模块
quantized_model = torch.quantization.quantize_dynamic(
model, {nn.LSTM, nn.Linear}, dtype=torch.qint8
)
print(quantized_model)
def print_size_of_model(model):
torch.save(model.state_dict(), "temp.p")
print('Size (MB):', os.path.getsize("temp.p")/1e6)
os.remove('temp.p')
print_size_of_model(model)
print_size_of_model(quantized_model)
torch.set_num_threads(1)
# 评估模型的运行时间
def time_model_evaluation(model, test_data):
s = time.time()
loss = evaluate(model, test_data)
elapsed = time.time() - s
print('''loss: {0:.3f}\nelapsed time (seconds): {1:.1f}'''.format(loss, elapsed))
time_model_evaluation(model, test_data)
time_model_evaluation(quantized_model, test_data)
8、Tensorflow模型量化详解
8.1 简介
具体的细节请参考该链接。
Tensorflow Lite 和 Tensorflow Model Optimization Toolkit (Tensorflow模型优化工具包)提供了最小优化推理复杂性的工具。对于移动和物联网 (IoT) 等边缘设备,推理效率尤其重要。这些设备在处理,内存,能耗和模型存储方面有许多限制。 此外,模型优化解锁了定点硬件 (fixed-point hardware) 和下一代硬件加速器的处理能力。
深度神经网络的量化使用了一些技术,这些技术可以降低权重的精确表示,并且可选的降低存储和计算的激活值。量化的优点包括:
- 1、对现有 CPU 平台的支持。
- 2、激活值得的量化降低了用于读取和存储中间激活值的存储器访问成本。
- 3、许多 CPU 和硬件加速器实现提供 SIMD 指令功能,这对量化特别有益。
TensorFlow Lite 对量化提供了多种级别的对量化支持。
- Tensorflow Lite post-training quantization 量化使权重和激活值的 Post training 更简单。
- Quantization-aware training 可以以最小精度下降来训练网络;这仅适用于卷积神经网络的一个子集。
8.2 tensorflow训练后量化详解
tensorflow训练后量化是针对已训练好的模型而言的,针对大部分我们已训练好的的网络模型来说均可使用此方法进行模型量化。tensorflow提供了一整套完整的模型量化工具,如TensorFlow Lite Optimizing COnverter(toco命令工具)以及TensorFlow Lite converter(API源码调用接口)。
8.2.1 混合量化-仅量化权重
该方式将浮点型的权重量化为int8整型,可将模型大小直接减少75%、提升推理速度最大3倍。该方式在推理的过程中,需要将int8量化值反量化为浮点型后再进行计算,如果某些Ops不支持int8整型量化,那么其保存的权重依然是浮点型的,即部分支持int8量化的Ops其权重保存为int8整型且存在quantize和dequantize操作,否则依然是浮点型的,因而称该方式为混合量化。该方式可达到近乎全整型量化的效果,但存在quantize和dequantize操作其速度依然不够理想。
混合量化的实现方式比较简单,仅需调用tf.lite.TFLiteConverter的API转化即可。
import tensorflow as tf
# 装载预训练模型
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
# 设置优化器
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]
# 执行转换操作
tflite_quant_model = converter.convert()
8.2.2 全整型量化-权重和激活值都进行量化
该方式试图将权重、激活值及输入值均全部做int8量化,并且将所有模型运算操作置于int8下进行执行,以达到最好的量化效果。为了达到此目的,我们需要一个具有代表性的小数据集,用于统计激活值和输入值等的浮点型范围,以便进行精准量化。
全整型量化的输入输出依然是浮点型的,但如果某些Ops未实现该方法,则转化是没问题的且其依然会自动保存为浮点型,这就要求我们的硬件支持这样的操作。
import tensorflow as tf
def representative_dataset_gen():
for _ in range(num_calibration_steps):
# Get sample input data as a numpy array in a method of your choosing.
yield [input]
# 装载预训练模型
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
# 设置优化器
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 获得标注数据
converter.representative_dataset = representative_dataset_gen
# 执行转化操作
tflite_quant_model = converter.convert()
8.2.3 半精度量化-仅量化权重
该方式是将权重量化为半精度float16形式。它可以将模型大小压缩1倍,与int8相比能够获得更小的精度损失,它的前提需要你使用的硬件支持FP16操作,而FP16操作仅在一些设备上面才能使用。使用该方法的示例代码如下所示:
import tensorflow as tf
# 装载预训练模型
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
# 设置优化器
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# 判断当前的设备是否支持FP16操作
converter.target_spec.supported_types = [tf.lite.constants.FLOAT16]
# 执行转换
tflite_quant_model = converter.convert()
8.3 tensorflow训练时量化详解
tensorflow中的训练时量化是一种伪量化。它是在可识别的某些操作内嵌入伪量化节点(fake quantization nodes),用以统计训练时流经该节点数据的最大值和最小值,便于在使用TOCO转换tflite格式时量化使用并减少精度损失,它参与模型训练的前向推理过程令模型获得量化损失,但梯度更新需要在浮点下进行因而其并不参与反向传播过程。某些操作无法添加伪量化节点,这时候就需要人为的去统计某些操作的最大最小值,但如果统计不准确那么将会带来较大的精度损失,因而需要谨慎检查哪些操作无法添加伪量化节点。值得注意的是,伪量化节点的意义在于统计流经数据的最大最小值并参与前向传播过程来提升模型精度,但其在TOCO工具转换为量化模型后,其工作原理还是与训练后量化方式一致的!具体的量化流程如下图所示:
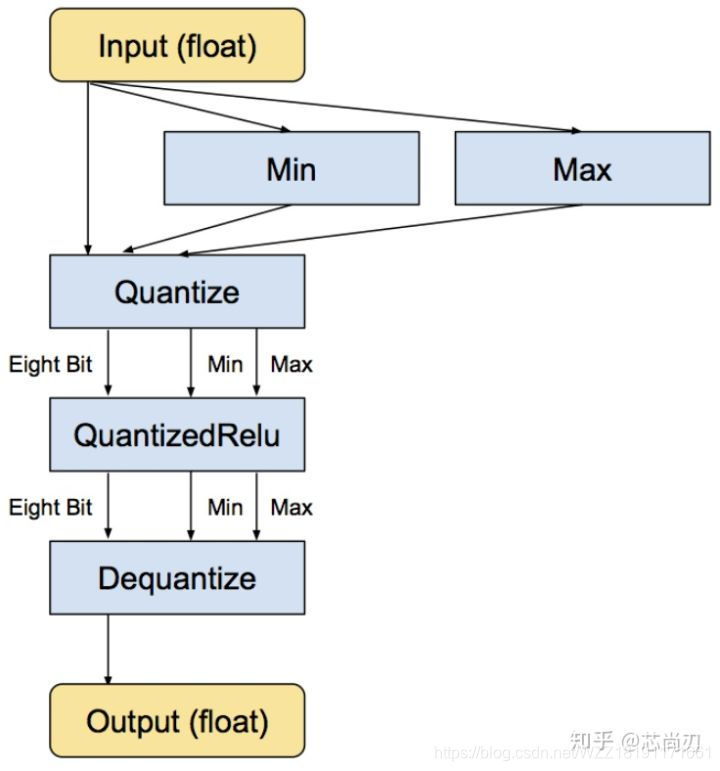
对于Relu节点而言,由于其支持量化操作,输入的数据仍然是FP32类型的,使用Min和Max函数分别来统计输入数据中的最大值和最小值;然后在Relu层的前面添加一个Quantize层来获得量化后的QuantizedRelu,此时已经转化为INT8类型;接着执行相应的Relu计算(INT8类型);接着添加一个dequantize层来将INT8的结果转换为FP32,即该层的最终输出仍然是FP32类型的。需要注意的是,当多个可识别的操作相邻时,多个quantize和dequantize连接时是可以相互抵消的。
8.3.1 训练时量化代码实战
步骤1-在训练图结构内添加伪量化节点
# 获取loss函数
loss = tf.losses.get_total_loss()
# 获取原始的图,并在原始的图的基础上创建一个量化图
g = tf.get_default_graph()
tf.contrib.quantize.create_training_graph(input_graph=g, quant_delay=2000000)
# 设计优化器并执行反向传播
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
optimizer.minimize(loss)
一般是在loss之后optimizer之前添加tf.contrib.quantize.create_training_graph关键函数,其将自动的帮我们在可识别的操作上嵌入伪量化节点,训练并保存模型后,模型图结构就会自动的存在伪量化节点及其统计的参数。tf.contrib.quantize.create_training_graph的参数input_graph表示训练的默认图层,quant_delay是指多少次迭代之后再进行量化,如果是已训练好进行微调量化的话,那么可以将quant_del ay设为0。
步骤2-重写推理图结构并保存为新的模型
# 设置loss函数
logits = tf.nn.softmax_cross_entropy_with_logits_v2(...)
# 获取原始的图,并在原始的图的基础上创建一个量化图
g = tf.get_default_graph()
tf.contrib.quantize.create_eval_graph(input_graph=g)
# 保存量化后的图文件
with open(eval_graph_file, ‘w’) as f:
f.write(str(g.as_graph_def()))
saver = tf.train.Saver()
saver.save(sess, checkpoint_name)
由于推理和训练的伪量化图结构存在着较大差异,该操作的作用是消除量化操作对BN层的影响。
步骤3-转换模型为全量化模型
首先,需要对第二步重写后的模型执行固化操作。
freeze_graph \
--input_graph=eval_graph_def.pb \
--input_checkpoint=checkpoint \
--output_graph=frozen_eval_graph.pb --output_node_names=outputs
然后,使用TOCO转换得到真正的量化模型。
toco \
--input_file=frozen_eval_graph.pb \
--output_file=tflite_model.tflite \
--input_format=TENSORFLOW_GRAPHDEF --output_format=TFLITE \
--inference_type=QUANTIZED_UINT8 \
--input_shape="1,224, 224,3" \
--input_array=input \
--output_array=outputs \
--std_value=127.5 --mean_value=127.5
8.4 tensorflow量化方法比较
两种量化的相同点如下所示:
- 两者均可达到模型量化的作用;
- 两者的推理工作原理是一样的;
- 两者都可工作在Tensorflow lite推理框架下并进行相应加速;
两种量化的不同点如下所示:
- 前者是一种offline的方式,而后者则是一种online的方式;
- 训练后量化工作量稍微简单些,而量化感知训练工作量更繁琐一些;
- 量化感知训练比训练后量化损失的精度更少,官方推荐使用量化感知训练方式;
8.5 Tensorflow量化效果展示与分析
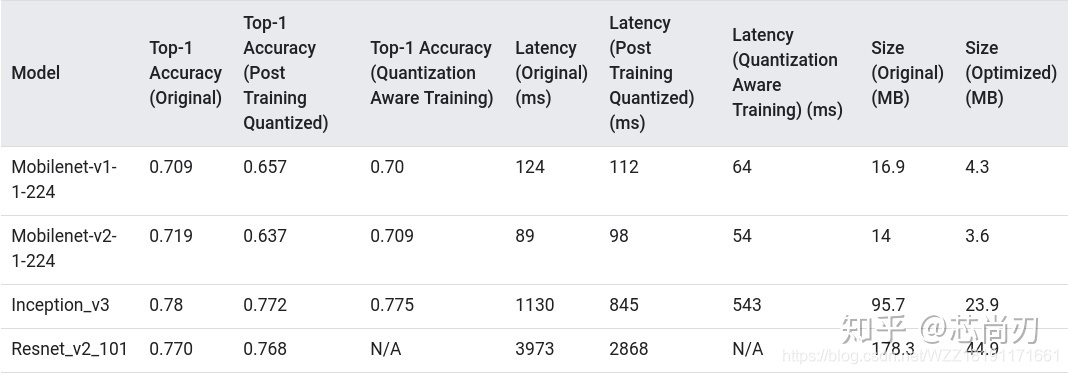
上图展示了Tensorflow两种不同的量化方式在不同模型上面的量化效果。该表中所有单帧推理时间都是在使用单个大内核的 Pixel 2 设备上测量的,通过该表我们可以得出初步的结论:训练时量化比训练后量化效果更好。
9、MxNet模型量化详解
9.1 简介
具体的细节请参考该链接。
MxNet当前支持的模型量化方式包括两种,即使用英特尔®MKL-DNN进行模型量化和使用CUDNN进行模型量化。
9.2 使用英特尔MKL-DNN进行模型量化
英特尔®MKL-DNN支持通过英特尔®CPU平台上的子图功能进行量化,并可以在英特尔®至强®可扩展平台上带来性能改进。设计了一个新的量化脚本imagenet_gen_qsym_mkldnn.py,以使用英特尔®MKL-DNN启动图像分类模型的量化。该脚本与Gluon-CV modelzoo集成在一起,因此可以从Gluon-CV下载更多经过预训练的模型,然后进行转换以进行量化。要将量化流程直接应用于您的项目,请参阅使用MKL-DNN后端量化自定义模型。
9.2.1 环境配置
pip install gluoncv
pip install mxnet-mkldnn
9.2.2 工具实战
从Gluon-CV下载预训练的模型,并将其转换为最终将被量化的符号模型。该标定数据集可用于测试预先训练的模型。
python imagenet_gen_qsym_mkldnn.py --model=resnet50_v1 --num-calib-batches=5 --calib-mode=naive
执行上述操作之后,模型将会自动执行融合和量化操作,并将量化之后的结果保存在./model文件夹中。我们可以通过执行下面的代码来进行量化后的模型推理。
# Launch FP32 Inference
python imagenet_inference.py --symbol-file=./model/resnet50_v1-symbol.json --param-file=./model/resnet50_v1-0000.params --rgb-mean=123.68,116.779,103.939 --rgb-std=58.393,57.12,57.375 --num-skipped-batches=50 --batch-size=64 --num-inference-batches=500 --dataset=./data/val_256_q90.rec --ctx=cpu
# Launch INT8 Inference
python imagenet_inference.py --symbol-file=./model/resnet50_v1-quantized-5batches-naive-symbol.json --param-file=./model/resnet50_v1-quantized-0000.params --rgb-mean=123.68,116.779,103.939 --rgb-std=58.393,57.12,57.375 --num-skipped-batches=50 --batch-size=64 --num-inference-batches=500 --dataset=./data/val_256_q90.rec --ctx=cpu
# Launch dummy data Inference
python imagenet_inference.py --symbol-file=./model/resnet50_v1-symbol.json --batch-size=64 --num-inference-batches=500 --ctx=cpu --benchmark=True
python imagenet_inference.py --symbol-file=./model/resnet50_v1-quantized-5batches-naive-symbol.json --batch-size=64 --num-inference-batches=500 --ctx=cpu --benchmark=True
9.3 使用CUDNN进行模型量化
请在该链接下载该文件。此文件夹包含使用或不使用校准对FP32模型进行量化以及使用校准的量化进行推理的示例。以两个预先训练的imagenet模型为例进行量化。一个是Resnet-152,另一个是Inception with BatchNorm。校准数据集是用于测试预先训练的模型的验证数据集。
- imagenet_gen_qsym.py此脚本提供了一个示例,使用FP32模型和校准数据集生成校准的量化模型。第一次启动时,脚本会将用户指定的模型(Resnet-152或Inception)和校准数据集分别下载到模型和数据文件夹中。生成的量化模型可以在模型文件夹中找到;
- imagenet_inference.py该脚本用于计算验证数据集上的FP32模型或量化模型的准确性,该数据已在中下载用于校准imagenet_gen_qsym.py;
- launch_quantize.sh这是一个Shell脚本,可为Resnet-152和带有BatchNorm的Inception生成具有各种配置的各种量化模型。用户可以将命令从脚本复制并粘贴到控制台,以针对特定配置运行模型量化;
- launch_inference.sh这是一个Shell脚本,用于计算通过调用生成的所有量化模型的精度launch_quantize.sh;
10、总结
所谓的模型量化就是将浮点存储(运算)转换为整型存储(运算)的一种模型压缩技术。偶遇该技术可以可以极大的缩小模型的大小,提高模型的运行速度,从而满足机器人、手机等嵌入式终端的需求,因而得到了工业界的大量应用。当前比较成熟的模型量化技术主要分为两种,即训练后量化和训练时量化,训练时量化不仅能够达到量化效果,同时还可以获得准确的量化结果。当前的很多深度学习框架中已经将模型量化方法嵌入其中,便于用户的模型部署。除此之外,无论是移动端还是服务器端,都可以看到新的计算设备正不断迎合量化技术,因而量化技术一定会越来越完善,从而进一步推动深度学习模型在低功率、低成本、低性能的终端上面的部署。
参考资料
[1] 线性量化
[2] 神经网络量化简介
[3] pytorch模型量化
[4] tensorflow模型量化
[5] mxnet模型量化
注意事项
[1] 如果您对AI、自动驾驶、AR、ChatGPT等技术感兴趣,欢迎关注我的微信公众号“AI产品汇”,有问题可以在公众号中私聊我!
[2] 该博客是本人原创博客,如果您对该博客感兴趣,想要转载该博客,请与我联系(qq邮箱:1575262785@qq.com),我会在第一时间回复大家,谢谢大家的关注。
[3] 由于个人能力有限,该博客可能存在很多的问题,希望大家能够提出改进意见。
[4] 如果您在阅读本博客时遇到不理解的地方,希望您可以联系我,我会及时的回复您,和您交流想法和意见,谢谢。
[5] 本人业余时间承接各种本科毕设设计和各种小项目,包括图像处理(数据挖掘、机器学习、深度学习等)、matlab仿真、python算法及仿真等,有需要的请加QQ:1575262785详聊,备注“项目”!!!














 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









