







Windows环境下开发pyspark程序
一、环境准备
1.1. Anaconda/Miniconda(Python环境)
如果不怕包的版本管理混乱,可以直接使用已有的Python环境。
需要安装anaconda/miniconda(python3.8版本以上):Anaconda下载安装及老版本选择(超详细)
使用conda新建一个虚拟环境用于PySpark开发:Python虚拟环境(windows)
首先,我们新建一个 pyspark_env 文件夹,作为虚拟环境的存放路径(也可以不用,conda创建虚拟环境时检测到没有会自动新建):

创建环境并指定路径:
conda create -p E:\penv\pyspark_env python=3.9
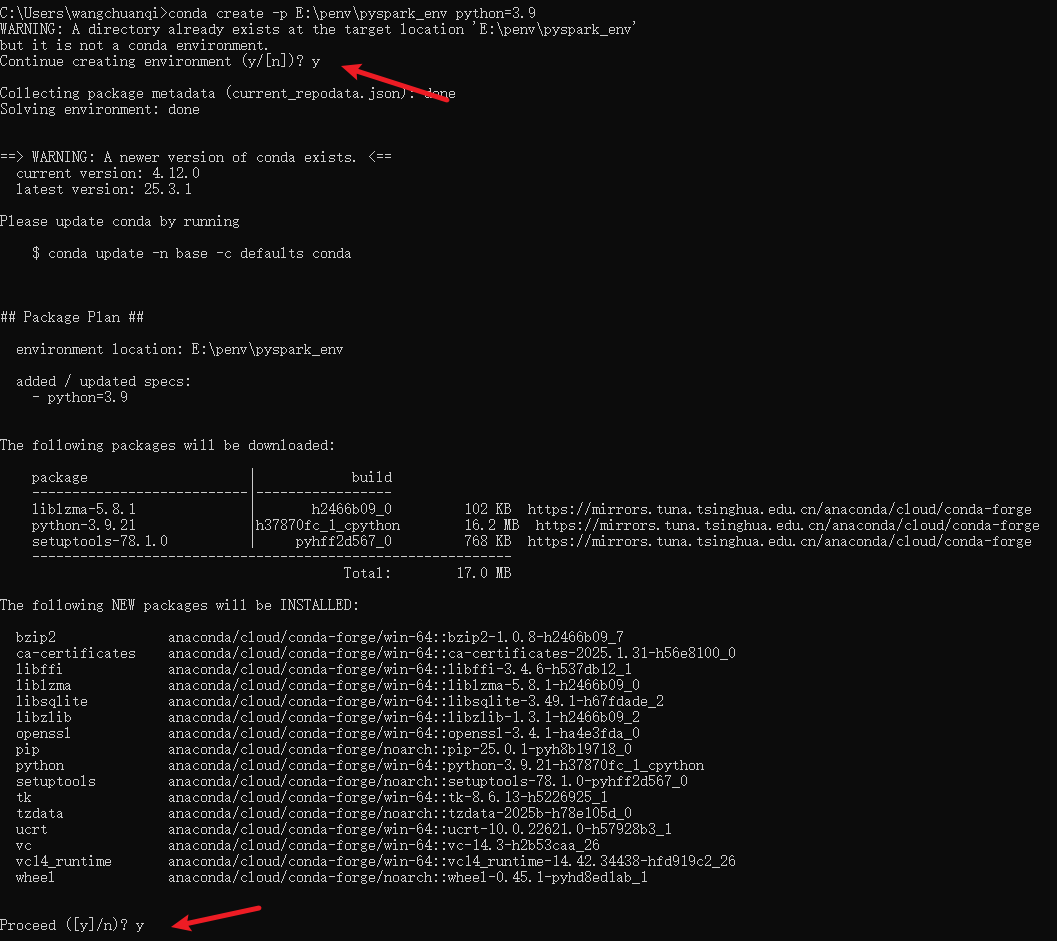
创建完成:
激活环境:
conda activate E:\penv\pyspark_env
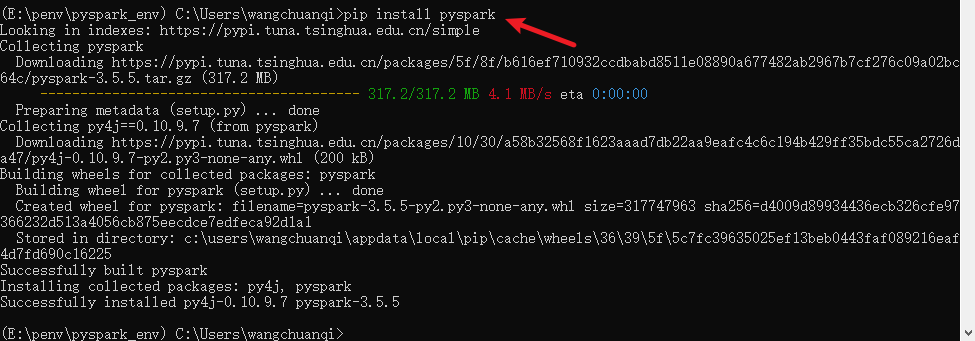
安装pyspark:
pip install pyspark -i https://pypi.tuna.tsinghua.edu.cn/simple/
安装psutil:
pip install psutil

1.2. JDK
请注意,PySpark需要Java 8(不包括8u371之前版本)、11或17,并且JAVA_HOME需要正确设置。设置JAVA安装路径的时候不要有空格,否则会报错。

参考这篇文章:JDK8卸载与安装教程(超详细)
1.3. 安装hadoop
(1)下载
进入hadoop安装包下载地址,这里选择的是hadoop-3.3.6.tar.gz版本:
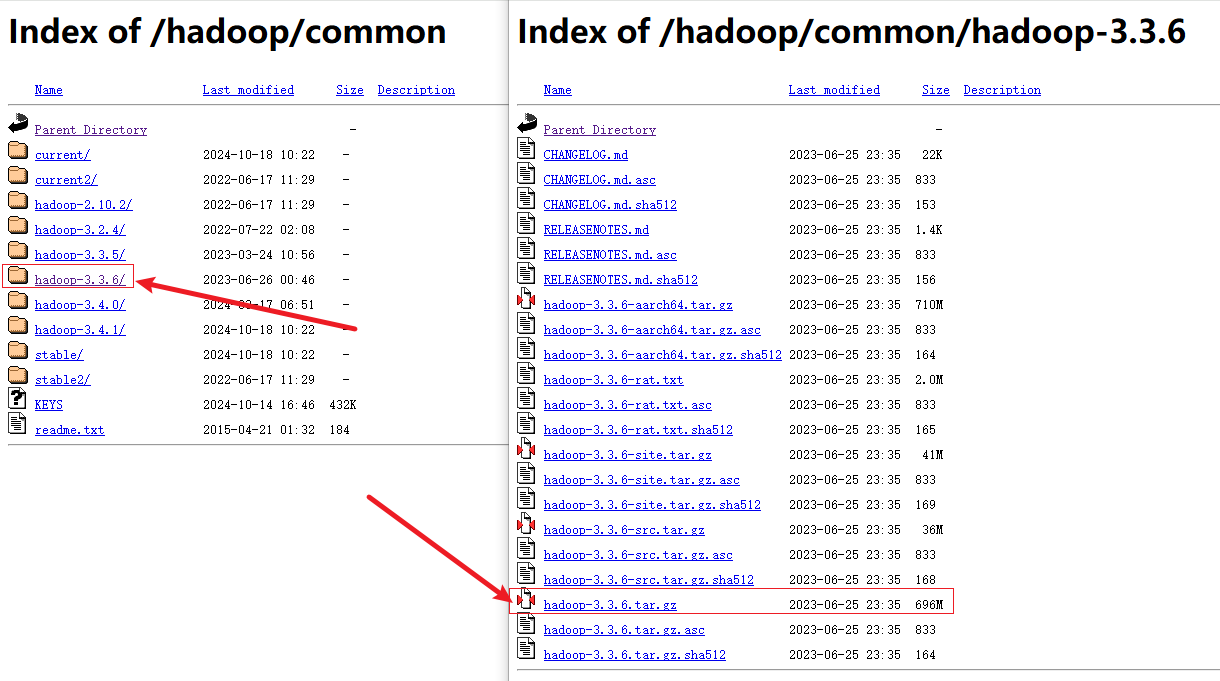
(2)解压
对下载好的文件进行解压,将其解压放在个人想存放的目录中(记住路径,以便配置环境变量)。
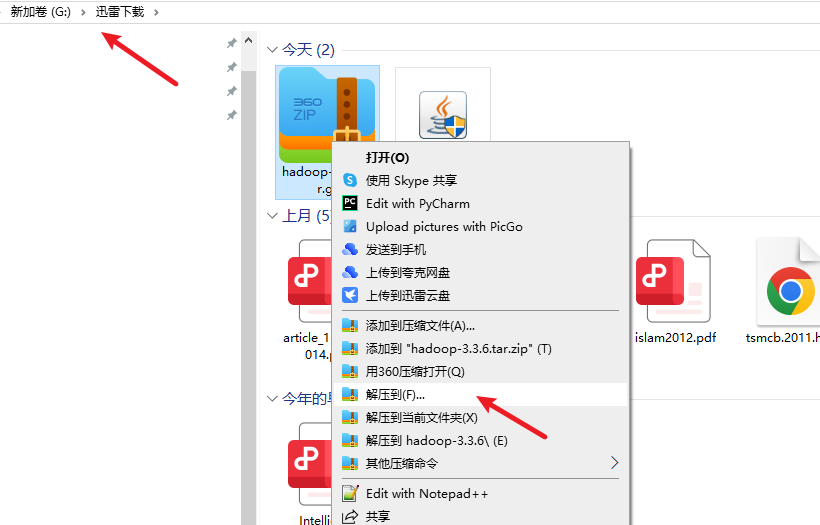
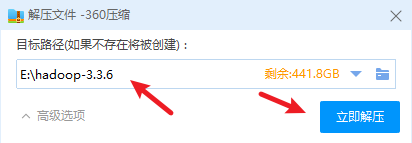
解压成功:
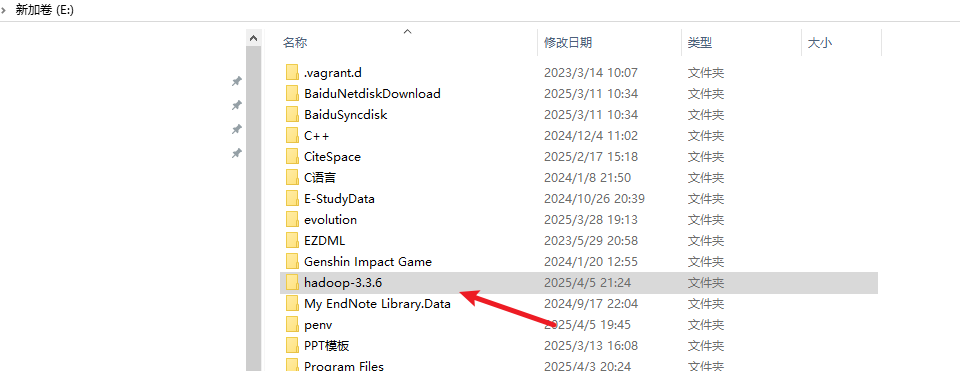
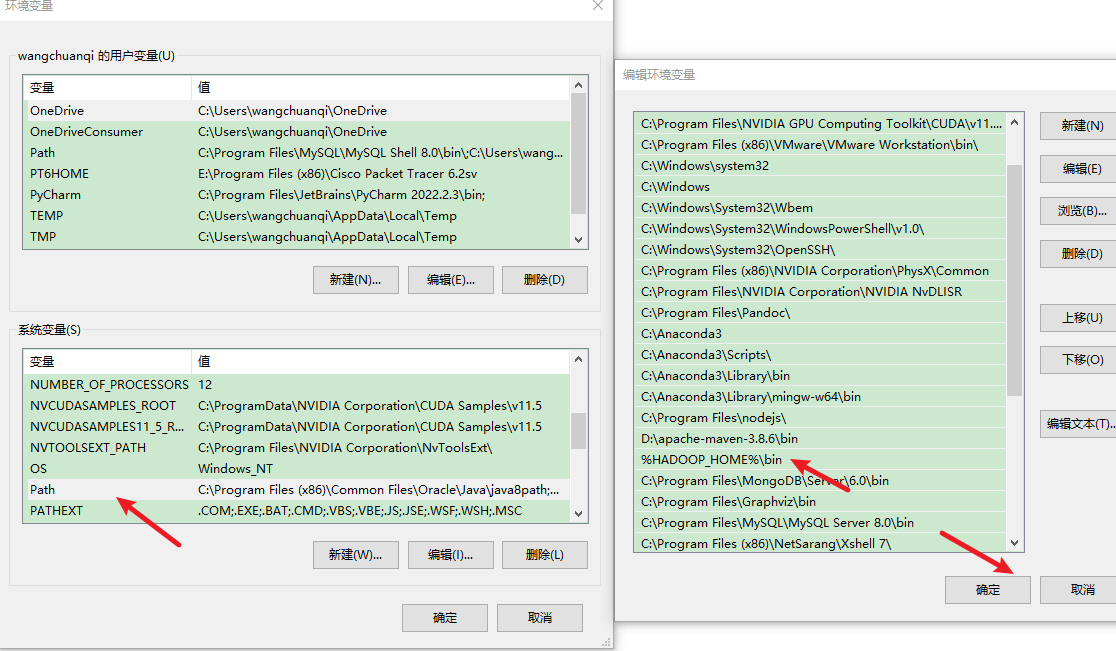
(3)配置环境变量
HADOOP_HOME
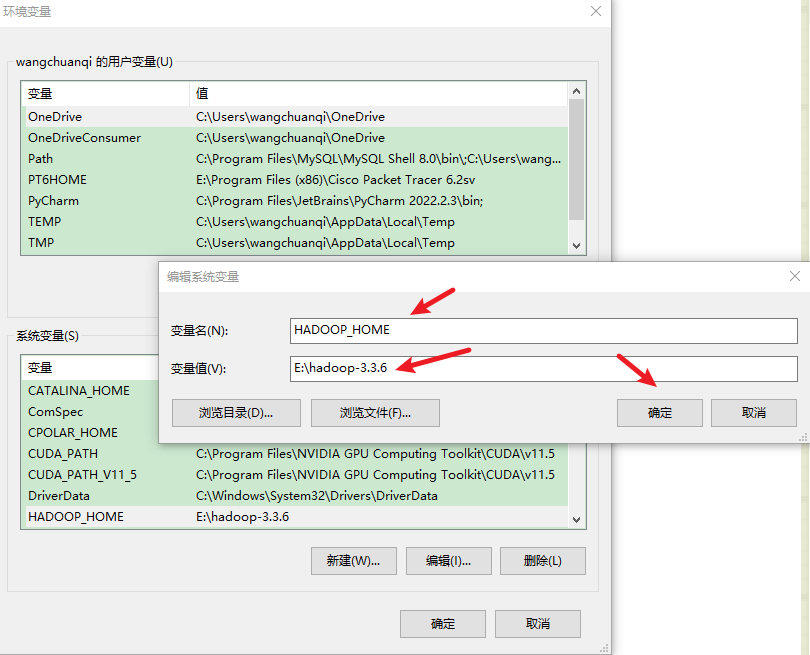
%HADOOP_HOME%\bin
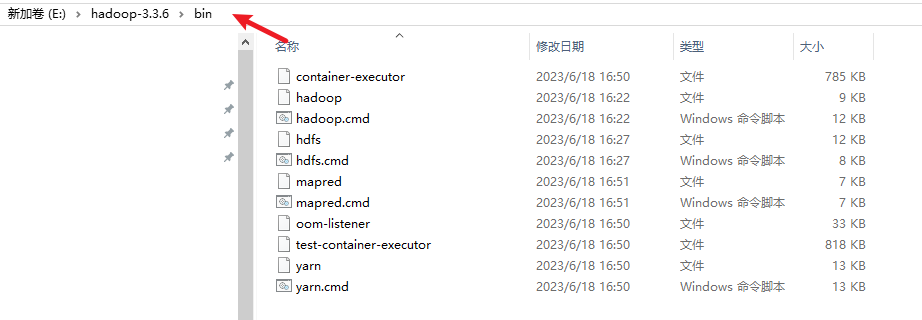
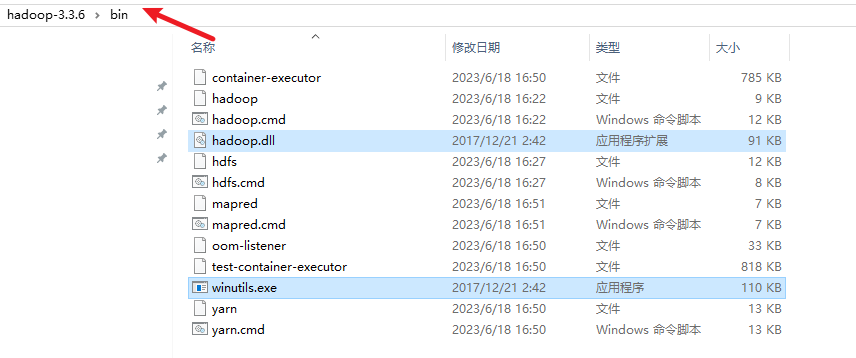
此时bin目录( E:\hadoop-3.3.6\bin)下没有 hadoop.dll及winutils.exe文件:
-
需要进行下载winutils :https://soft.3dmgame.com/down/204154.html

-
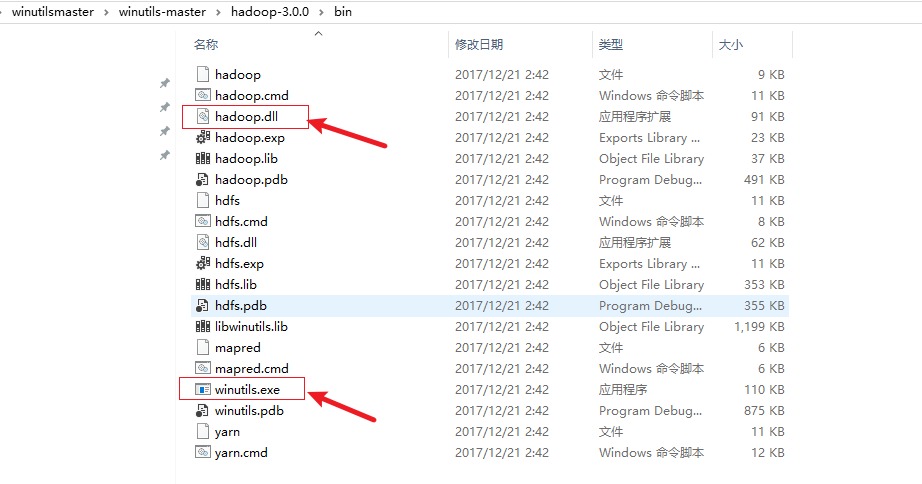
解压文件,选择hadoop版本对应的文件夹bin目录下的hadoop.dll和winutils.exe文件
-
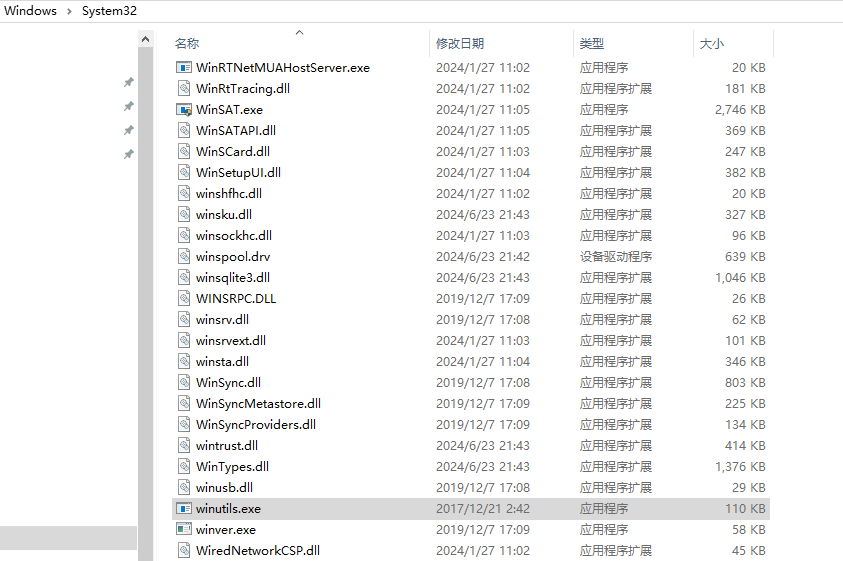
将hadoop.dll和winutils.exe 拷贝到E:\hadoop-3.3.6\bin 、C:\Windows\System32下(两个文件各拷贝一份到两个目录中)
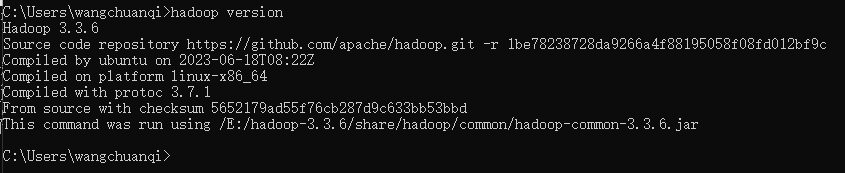
(4)环境测试
二、新建一个Python项目
2.1. 创建项目并配置解释器
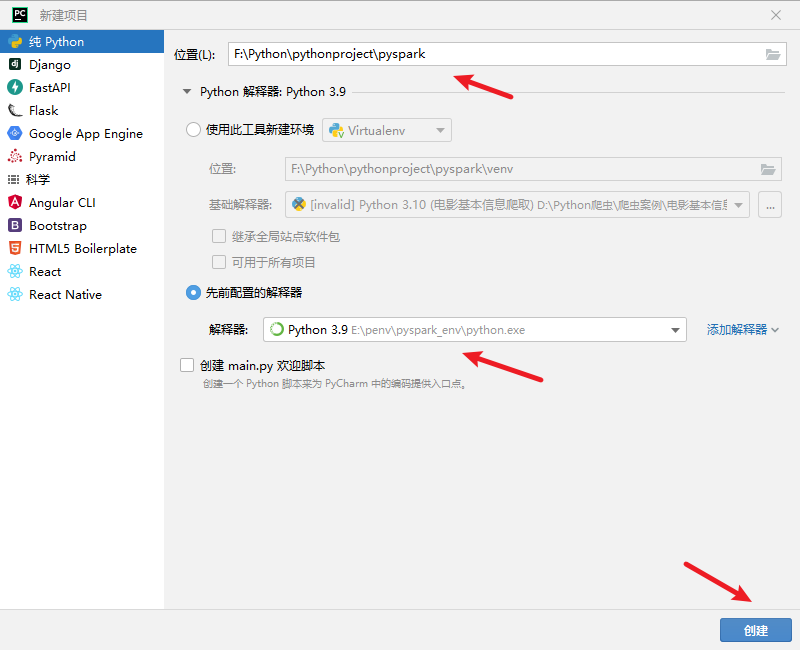
新建一个项目,项目名为pyspark:
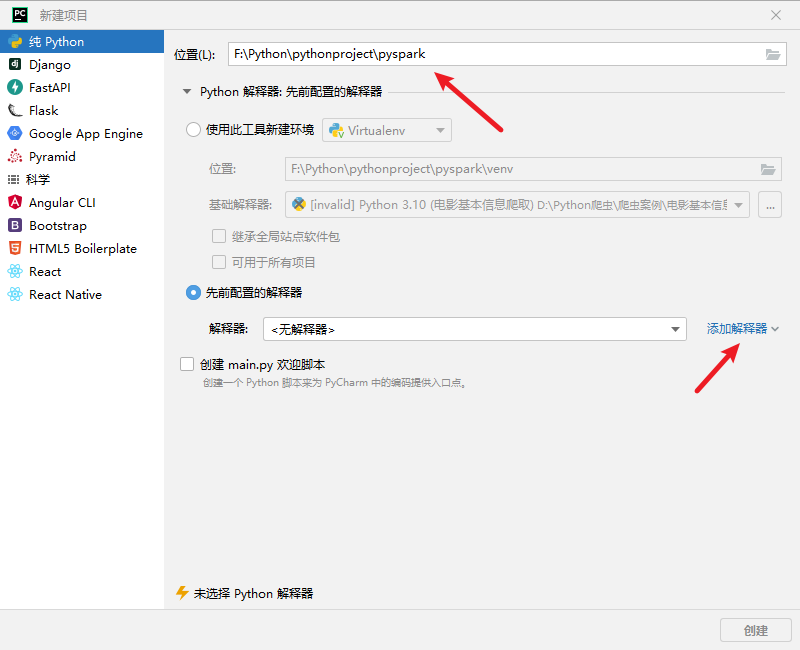
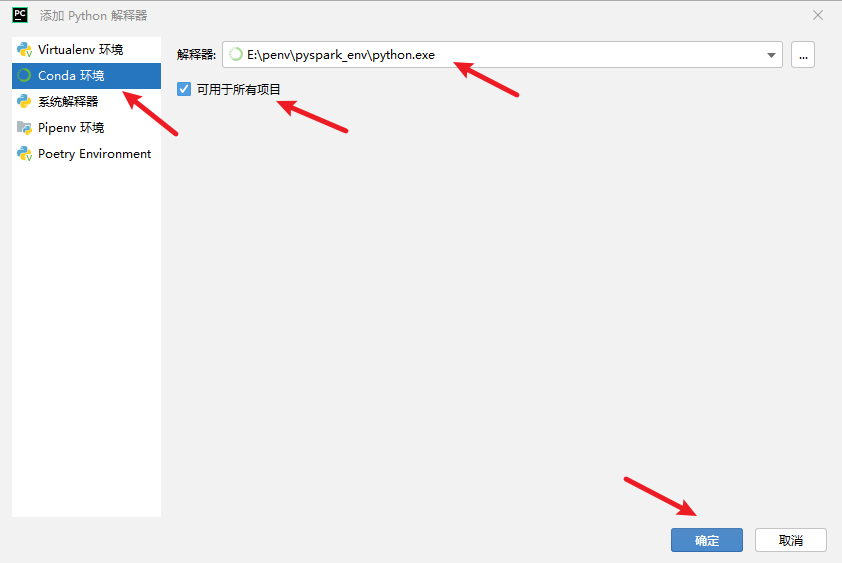
添加新的解释器(找到虚拟环境中的python.exe):

创建项目:
2.2. 创建目录文件
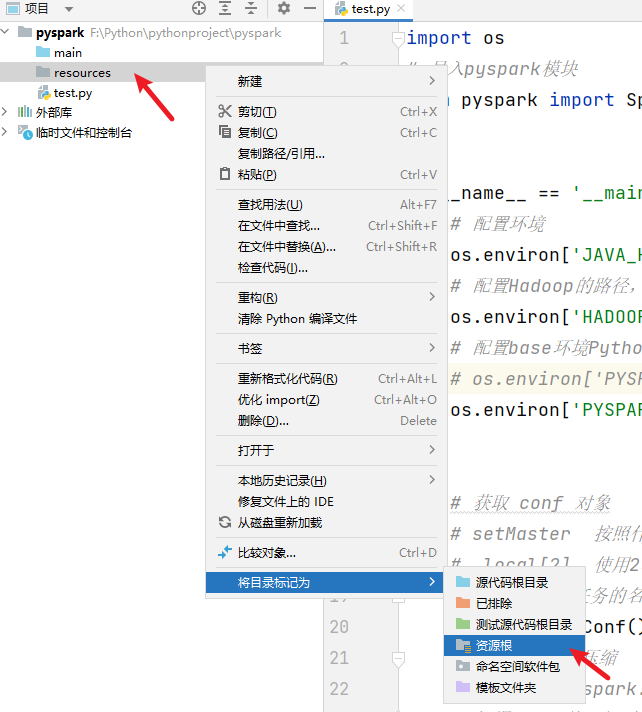
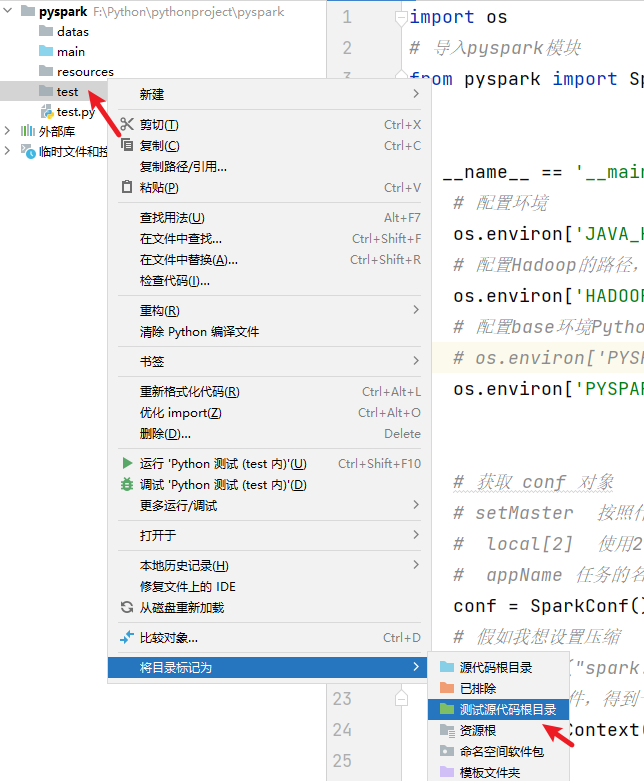
main :用于存放每天开发的一些代码文件
resources :用于存放程序中需要用到的配置文件
datas :用于存放每天用到的一些数据文件
test :用于存放测试时的一些代码文件

2.3. 环境测试
import os
from pyspark import SparkContext, SparkConf # 导入pyspark模块
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk-1.8'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'E:/hadoop-3.3.6'
# 配置Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
# 获取 conf 对象
# setMaster 按照什么模式运行,local bigdata01:7077 yarn
# local[2] 使用2核CPU * 你本地资源有多少核就用多少核
# appName 任务的名字
conf = SparkConf().setMaster("local[*]").setAppName("第一个Spark程序")
# 假如我想设置压缩
# conf.set("spark.eventLog.compression.codec","snappy")
# 根据配置文件,得到一个SC对象,第一个conf 是 形参的名字,第二个conf 是实参的名字
sc = SparkContext(conf=conf)
print(sc)
# 使用完后,记得关闭
sc.stop()
输出结果:
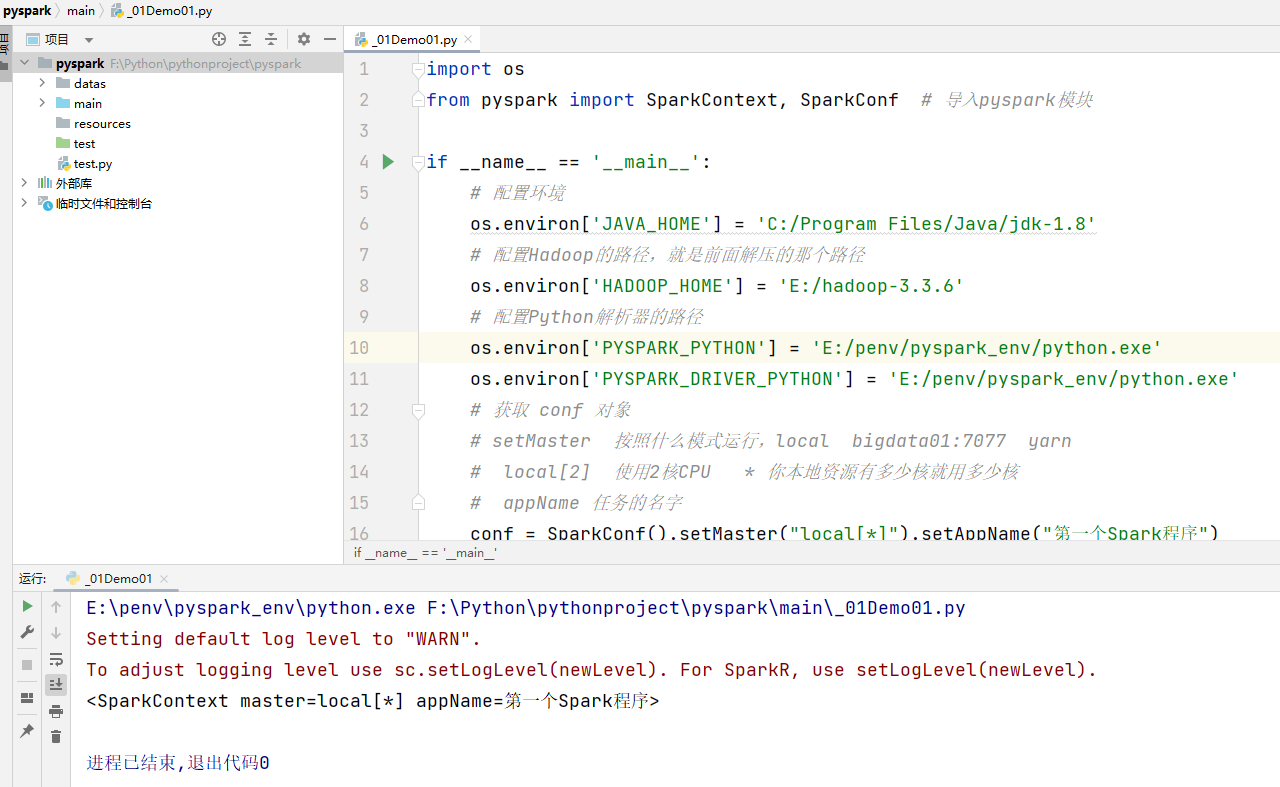
三、WordCount案例
3.1 数据准备
这里我使用文心一言生成了一份数据,用来测试WordCount。
数据如下所示:
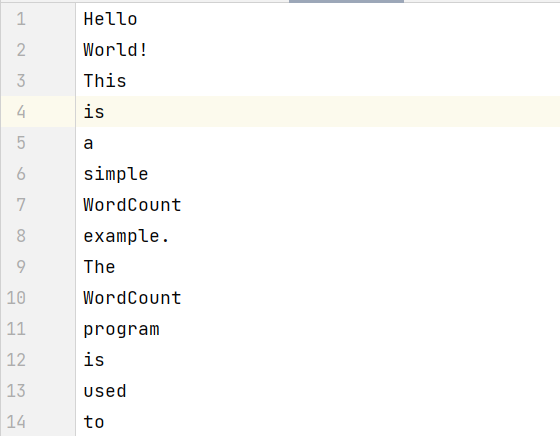
Hello World! This is a simple WordCount example. The WordCount program is used to count the frequency of words in a given text.
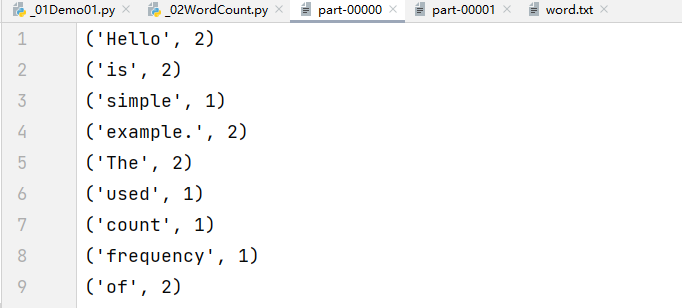
Let's analyze this example: "Hello World!" Hello again, World! Notice how the word 'Hello' appears multiple times, as does 'World'.
The program should ignore case sensitivity, meaning 'Hello' and 'hello' should be treated as the same word. Additionally, punctuation marks like commas, periods, and exclamation points should not affect the word count.
In summary, a WordCount program takes text as input and outputs a list of words along with their corresponding frequencies. For instance, the word 'Hello' might appear 3 times, while 'World' appears 2 times in this example.
数据特点:
- 重复单词:Hello 和 World 多次出现。
- 标点符号:包含逗号、句号和感叹号等标点符号。
- 大小写混合:Hello 和 hello 应被视为同一个单词。
- 自然语言结构:包含简单句子和段落,模拟真实文本。
3.2 代码实现
代码实现如下所示:
import os
import re
from pyspark import SparkContext, SparkConf # 导入pyspark模块
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk-1.8'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'E:/hadoop-3.3.6'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'E:/penv/pyspark_env/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
# 获取 conf 对象
# setMaster 按照什么模式运行,local bigdata01:7077 yarn
# local[2] 使用2核CPU * 你本地资源有多少核就用多少核
# appName 任务的名字
conf = SparkConf().setMaster("local[*]").setAppName("WordCount")
# 假如我想设置压缩
# conf.set("spark.eventLog.compression.codec","snappy")
# 根据配置文件,得到一个SC对象,第一个conf 是 形参的名字,第二个conf 是实参的名字
sc = SparkContext(conf=conf)
fileRdd = sc.textFile("../datas/wordcount/word.txt") # 读取数据
rsRdd = fileRdd \
.filter(lambda line: len(line.strip()) > 0) \
.flatMap(lambda line: line.strip().split(r" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
rsRdd.saveAsTextFile("../output")
# 使用完后,记得关闭
sc.stop()
输出结果:

代码解析:
filter(lambda line: len(line.strip()) > 0):过滤掉空行;

flatMap(lambda line:line.strip().split(r"")):将每一行多个单词转换为一行一个单词,r 的作用是告诉 Python 将字符串按原始字符串处理,避免转义字符的干扰。
.map(lambda word: (word, 1)):将每个单词转换成KeyValue的二元组(word,1)

reduceByKey(lambda a, b: a + b):先根据key值进行分组,然后再进行聚合。
3.3 代码改进
虽然代码实现出来了简单的WordCount,但是没有达到我们想要的预期,主要有以下几点需要改进:
- 单词前后的符号无法处理,导致一个单词分成了不同的组。
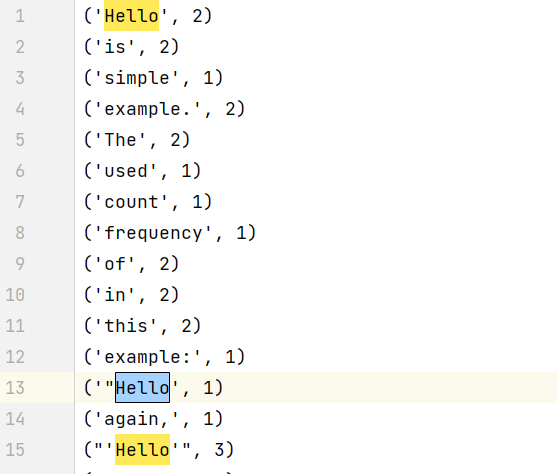
- 对单词的大小写不敏感,如:Hello和hello应视为一个词。
3.3.1 解决标点符号
对于标点符号,我们可以使用正则表达式进行处理。
下面是正则表达式的一个测试用例:
import re
text = "你好,世界!这是一个测试文本。"
# 使用正则表达式去除标点符号
result = re.sub(r'[^\w\s]', '', text)
print(result) # 输出:你好世界这是一个测试文本
其中:
[^\w\s]匹配所有非字母、数字和空格的字符(即标点符号)。- re.sub() 将匹配的字符替换为空字符串。
3.3.2 解决大小写字母
对单词的大小写不敏感,我们可以采取以下措施。
- 全部字母大写或者小写:使用upper()或者lower()函数。
text = "Hello World"
upper_text = text.upper()
lower_text = text.lower()
print(upper_text) # HELLO WORLD
print(lower_text) # hello world
- 首字母大写,其余字母小写:
- 使用 capitalize() 方法 capitalize() 方法会将字符串的第一个字符转换为大写,其余字符转换为小写。
text = "hello world"
capitalized_text = text.capitalize()
print(capitalized_text) # 输出: Hello world
- 使用 title() 方法 如果你希望字符串中每个单词的首字母都大写,可以使用 title() 方法。
text = "hello world"
title_text = text.title()
print(title_text) # 输出: Hello World
3.3.3 代码实现
这里我们采用正则表达式对标点符号进行处理,使用title()方法处理字母大小写。那么,改进后的代码如下:
import os
import re
from pyspark import SparkContext, SparkConf # 导入pyspark模块
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk-1.8'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'E:/hadoop-3.3.6'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'E:/penv/pyspark_env/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
# 获取 conf 对象
# setMaster 按照什么模式运行,local bigdata01:7077 yarn
# local[2] 使用2核CPU * 你本地资源有多少核就用多少核
# appName 任务的名字
conf = SparkConf().setMaster("local[*]").setAppName("WordCount")
# 假如我想设置压缩
# conf.set("spark.eventLog.compression.codec","snappy")
# 根据配置文件,得到一个SC对象,第一个conf 是 形参的名字,第二个conf 是实参的名字
sc = SparkContext(conf=conf)
fileRdd = sc.textFile("../datas/wordcount/word.txt") # 读取数据
rsRdd = fileRdd \
.filter(lambda line: len(line.strip()) > 0) \
.flatMap(lambda line: re.sub(r'[^\w\s]', '', line.strip()).split()) \
.map(lambda word: (word.title(), 1)) \
.reduceByKey(lambda a, b: a + b)
rsRdd.saveAsTextFile("../output3")
# 使用完后,记得关闭
sc.stop()
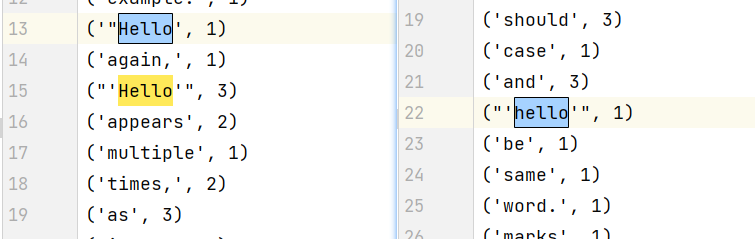
输出结果为:
('Hello', 7)
('World', 5)
('Wordcount', 3)
('Example', 3)
('The', 7)
('Program', 3)
('Count', 2)
('Of', 2)
('Words', 2)
('Lets', 1)
('Analyze', 1)
('Again', 1)
('Appears', 2)
('Should', 3)
('Ignore', 1)
('Sensitivity', 1)
('And', 3)
('Same', 1)
('Punctuation', 1)
('Marks', 1)
('Periods', 1)
('Not', 1)
('Affect', 1)
('Summary', 1)
('Takes', 1)
('Input', 1)
('Outputs', 1)
('List', 1)
('Corresponding', 1)
('Instance', 1)
('Might', 1)
('This', 3)
('Is', 2)
('A', 4)
('Simple', 1)
('Used', 1)
('To', 1)
('Frequency', 1)
('In', 3)
('Given', 1)
('Text', 2)
('Notice', 1)
('How', 1)
('Word', 4)
('Multiple', 1)
('Times', 3)
('As', 3)
('Does', 1)
('Case', 1)
('Meaning', 1)
('Be', 1)
('Treated', 1)
('Additionally', 1)
('Like', 1)
('Commas', 1)
('Exclamation', 1)
('Points', 1)
('Along', 1)
('With', 1)
('Their', 1)
('Frequencies', 1)
('For', 1)
('Appear', 1)
('3', 1)
('While', 1)
('2', 1)
四、数据去重案例
4.1 数据准备
这里提供了csv版本的数据:
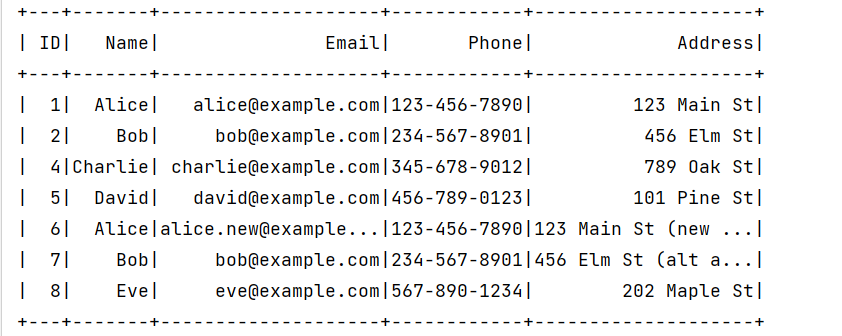
ID , Name , Email , Phone , Address
1 , Alice , alice@example.com , 123-456-7890 , 123 Main St
2 , Bob , bob@example.com , 234-567-8901 , 456 Elm St
3 , Alice , alice@example.com , 123-456-7890 , 123 Main St
4 , Charlie , charlie@example.com , 345-678-9012 , 789 Oak St
5 , David , david@example.com , 456-789-0123 , 101 Pine St
6 , Alice , alice.new@example.com , 123-456-7890 , 123 Main St (new addr)
7 , Bob , bob@example.com , 234-567-8901 , 456 Elm St (alt addr)
8 , Eve , eve@example.com , 567-890-1234 , 202 Maple St
9 , Charlie , charlie@example.com , 345-678-9012 , 789 Oak St
4.2 去重规则
- 完全匹配去重:如果两行数据的所有字段都相同,则认为是重复项,保留其中一行。
- 部分匹配去重(可选):如果某些字段(如 Name 和 Email)相同,但其他字段(如 Phone 和 Address)不同,可以根据业务需求决定是否视为重复项。
在此示例中,我们仅考虑完全匹配去重。
4.3 代码实现
方法一:使用PySpark中dataframe进行实现:
import os
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk-1.8'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'E:/hadoop-3.3.6'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
# 创建SparkSession
spark = SparkSession.builder \
.appName("Data Deduplication") \
.getOrCreate()
# 读取CSV文件
csv_file_path = "../datas/data deduplication/data.csv"
# header=True表示第一行作为列名,inferSchema=True尝试自动推断数据类型。
df = spark.read.csv(csv_file_path, header=True, inferSchema=True)
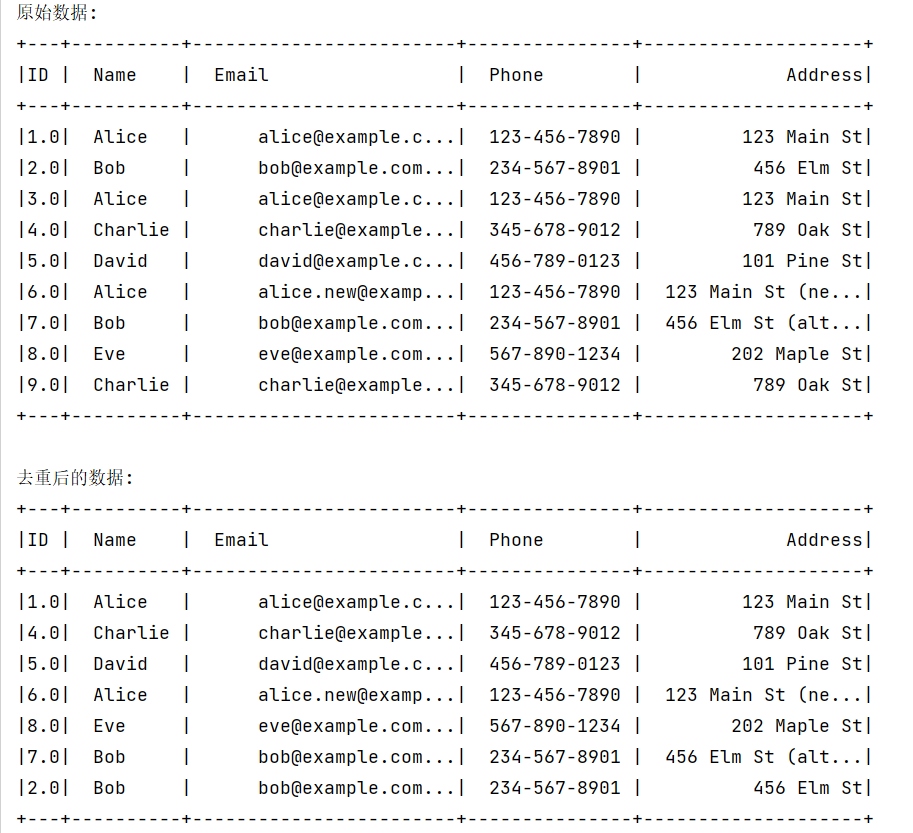
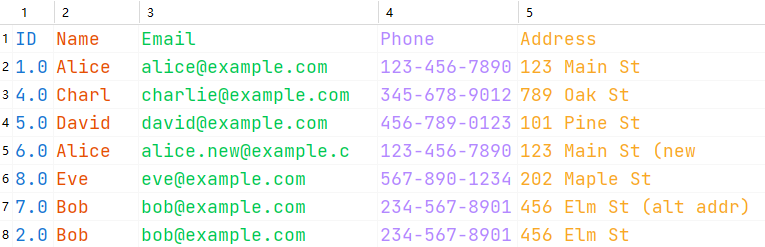
# 显示原始数据
print("原始数据:")
df.show()
# 获取所有列名并排除ID字段
columns_to_check = df.columns[1:]
# 去除重复行(忽略ID字段)
# 使用dropDuplicates()函数基于columns_to_check列表中的列名去除重复行。这意味着如果两行在这些列上的值完全相同,则只保留一行。
df_no_duplicates = df.dropDuplicates(subset=columns_to_check)
# 显示去重后的数据
print("去重后的数据:")
df_no_duplicates.show()
# 如果需要保存去重后的数据到新的CSV文件
output_csv_file_path = "../datas/data deduplication/deduplicated_data.csv"
df_no_duplicates.write.csv(output_csv_file_path, header=True, mode="overwrite")
# 停止SparkSession
spark.stop()
输出结果为:
方法二:使用PySaprk中的SQL进行实现。
import os
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk-1.8'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'E:/hadoop-3.3.6'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
# 创建SparkSession
spark = SparkSession.builder \
.appName("Data Deduplication") \
.getOrCreate()
# 读取CSV文件
csv_file_path = "../datas/data deduplication/data.csv"
# header=True表示第一行作为列名,inferSchema=True尝试自动推断数据类型。
df = spark.read.csv(csv_file_path, header=True, inferSchema=True)
# 获取所有列名并排除ID字段
columns_to_check = df.columns[1:]
# 创建一个不包含ID字段的DataFrame
df = df.select(columns_to_check)
# 创建一个临时视图
df.createOrReplaceTempView("my_table")
spark.sql("select DISTINCT * from my_table").show()
# 停止SparkSession
spark.stop()
输出结果:
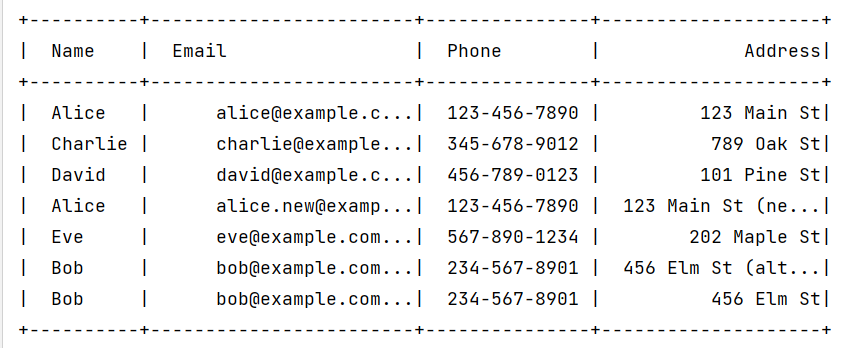
但是这个没有对应的ID列。
方法三:
import os
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk-1.8'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'E:/hadoop-3.3.6'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'E:/penv/pyspark_env/python.exe'
# 创建SparkSession
spark = SparkSession.builder \
.appName("Data Deduplication") \
.getOrCreate()
# 读取CSV文件
csv_file_path = "../datas/data deduplication/data.csv"
# header=True表示第一行作为列名,inferSchema=True尝试自动推断数据类型。
df = spark.read.csv(csv_file_path, header=True, inferSchema=True)
# 创建一个临时视图
df.createOrReplaceTempView("tt")
spark.sql("""
SELECT * FROM tt
WHERE ID IN (select min(ID) from tt group by Name,Email,Phone,Address)
""").show()
# 停止SparkSession
spark.stop()
输出结果:
五、Movielens
5.1 Movielens介绍
MovieLens 是一个广泛用于推荐系统研究和教育的公开数据集,由 GroupLens 研究团队(明尼苏达大学)收集和维护。它包含用户对电影的评分、标签、用户人口统计信息以及电影元数据。
5.1.1 主要数据集版本
MovieLens 提供不同规模的数据集,适用于不同需求:
- MovieLens 100K:10万条评分,适用于快速实验。
- MovieLens 1M:100万条评分,用户和电影数量更多。
- MovieLens 10M/20M:千万级评分,包含更丰富的用户行为和电影元数据。
- MovieLens Latest(持续更新):小规模但包含最新数据。
5.1.2 核心数据内容
(1) 评分数据(Ratings)
- 字段:用户ID、电影ID、评分(1-5星)、时间戳。
- 特点:显式反馈数据,直接反映用户偏好。
(2) 电影数据(Movies)
- 字段:电影ID、标题、上映年份、类型(如喜剧、动作,多标签)。
- 示例:
1, Toy Story (1995), Animation|Comedy|Family
(3) 用户数据(Users)
- 字段:用户ID、性别、年龄、职业、邮编。
- 用途:支持基于人口统计的推荐(如性别、年龄分组)。
(4) 标签数据(Tags)
- 字段:用户ID、电影ID、标签(自由文本)、时间戳。
- 示例:用户可能为电影标记“科幻”或“诺兰导演”。
5.1.3 数据获取
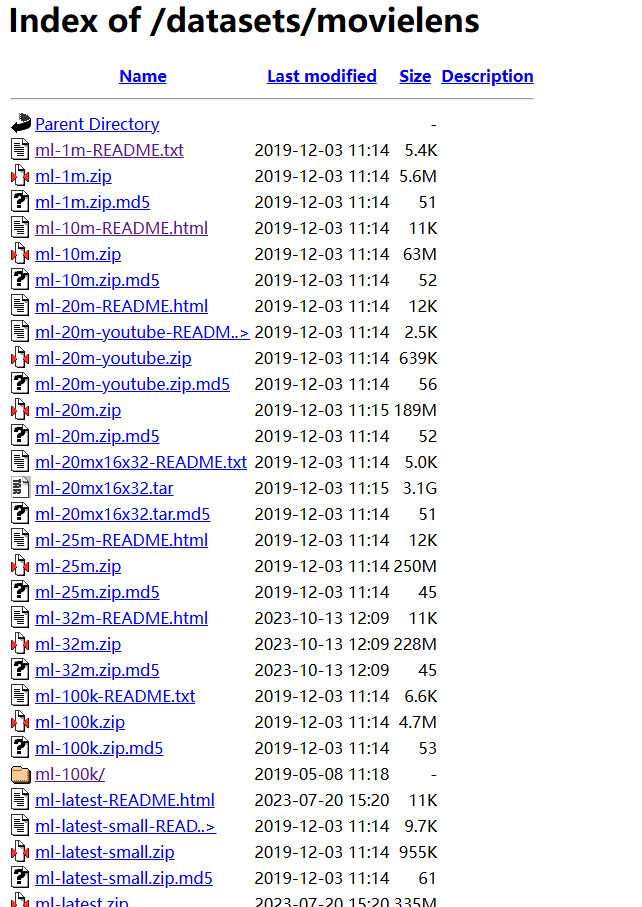
数据获取:Index of /datasets/movielens
5.2 数据说明
这里,以ml-1m为例。
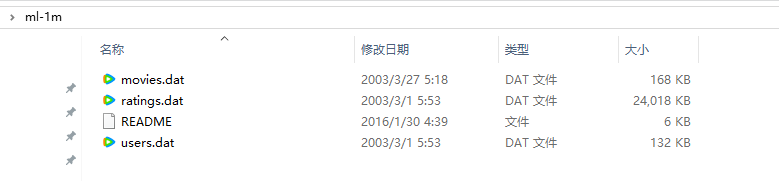
下载解压后,数据如下图所示:
5.2.1 RATINGS(评分)
所有评分都包含在 ratings.dat 文件中,数据格式如下:
UserID::MovieID::Rating::Timestamp
- 用户ID(UserID)范围为1到6040
- 电影ID(MovieID)范围为1到3952
- 评分(Rating)采用5星制(仅限整星评分)
- 时间戳(Timestamp)以自纪元以来的秒数表示,由time(2)函数返回
- 每个用户至少有20条评分
5.2.2 USERS(用户)
用户信息存储在文件 users.dat 中,格式如下:
UserID::Gender::AgeID::OccupationID::Zip-code
- 性别(Gender)用“M”表示男性,用“F”表示女性
- 年龄(AgeID)选择以下范围之一:
- 1: “Under 18”
- 18: “18-24”
- 25: “25-34”
- 35: “35-44”
- 45: “45-49”
- 50: “50-55”
- 56: “56+”
- 职业(OccupationID)选择如下:
- 0: “other” or not specified
- 1: “academic/educator”
- 2: “artist”
- 3: “clerical/admin”
- 4: “college/grad student”
- 5: “customer service”
- 6: “doctor/health care”
- 7: “executive/managerial”
- 8: “farmer”
- 9: “homemaker”
- 10: “K-12 student”
- 11: “lawyer”
- 12: “programmer”
- 13: “retired”
- 14: “sales/marketing”
- 15: “scientist”
- 16: “self-employed”
- 17: “technician/engineer”
- 18: “tradesman/craftsman”
- 19: “unemployed”
- 20: “writer”
- 邮编(Zip-code)
5.2.3 MOVIES(电影)
电影信息在 movies.dat 文件中,格式如下:
MovieID::Title::Genres
- 标题与IMDB提供的标题(包括发行年份)完全相同
- 类型用竖线分隔,并从以下类型中选择:
- Action
- Adventure
- Animation
- Children’s
- Comedy
- Crime
- Documentary
- Drama
- Fantasy
- Film-Noir
- Horror
- Musical
- Mystery
- Romance
- Sci-Fi
- Thriller
- War
- Western
5.2.4 Occupation(职业)
创建一个 occupations.dat 文件,数据格式和数据如下所示:
数据格式:
OccupationID::Occupation
数据:
0::other or not specified
1::academic/educator
2::artist
3::clerical/admin
4::college/grad student
5::customer service
6::doctor/health care
7::executive/managerial
8::farmer
9::homemaker
10::K-12 student
11::lawyer
12::programmer
13::retired
14::sales/marketing
15::scientist
16::self-employed
17::technician/engineer
18::tradesman/craftsman
19::unemployed
20::writer
5.2.5 Age(年龄)
创建一个 ages.dat 文件,数据格式和数据如下所示:
数据格式:
AgeID::Age
数据:
1::"Under 18"
18::"18-24"
25::"25-34"
35::"35-44"
45::"45-49"
50::"50-55"
56::"56+"
5.2.6 任务说明
1、分别统计用户数,男女人数,职业的个数。
2、查看统计年龄分布情况。
3、查看统计职业分布情况(按照职业统计人数)
4、统计最高评分,最低评分,平均评分,中位评分,平均每个用户的评分次数,平均每部影片被评分次数:
5、统计评分分布情况
6、统计不同用户的评分次数。
7、统计不同类型的电影分布情况
8、统计每年的电影发布情况。
9、统计每部电影有多少用户评价,总评分情况,平均分情况
10、统计每个用户评价次数,评价总分以及平均分情况
11、求被评分次数最多的 10 部电影,并给出评分次数(电影名,评分次数)
12、分别求男性,女性当中评分最高的 10 部电影(性别,电影名,影评分)
13、分别求男性,女性看过最多的 10 部电影(性别,电影名)
14、年龄段在“18-24”的男人,最喜欢看 10 部电影
15、求 movieid = 2116 这部电影各年龄段(年龄段为7段)的平均影评(年龄段,影评分)
16、求最喜欢看电影(影评次数最多)的那位女性评最高分的 10 部电影的平均影评分(观影者,电影名,影评分)
17、求好片(评分>=4.0)最多的那个年份的最好看的 10 部电影
18、求 1997 年上映的电影中,评分最高的 10 部 Comedy 类电影
19、该影评库中各种类型电影中评价最高的 5 部电影(类型,电影名,平均影评分)
20、各年评分最高的电影类型(年份,类型,影评分)
5.3 数据分析
5.3.1 数据加载
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, IntegerType, StringType, FloatType
# 定义数据模式
movies_schema = StructType([
StructField("movie_id", IntegerType(), True),
StructField("title", StringType(), True),
StructField("genres", StringType(), True)
])
ratings_schema = StructType([
StructField("user_id", IntegerType(), True),
StructField("movie_id", IntegerType(), True),
StructField("rating", FloatType(), True),
StructField("timestamp", IntegerType(), True)
])
users_schema = StructType([
StructField("user_id", IntegerType(), True),
StructField("gender", StringType(), True),
StructField("age_id", IntegerType(), True),
StructField("occupation_id", IntegerType(), True), # 修改为 IntegerType
StructField("zip_code", StringType(), True)
])
occupations_schema = StructType([
StructField("occupation_id", IntegerType(), True),
StructField("occupation", StringType(), True)
])
ages_schema = StructType([
StructField("age_id", IntegerType(), True),
StructField("age_range", StringType(), True)
])
# 读取数据
def load_data(spark, load_movies=False, load_ratings=False, load_users=False, load_occupations=False, load_ages=False):
dfs = {}
if load_movies:
movies_df = spark.read.csv(
"F:/Python/pythonproject/pyspark/datas/ml-1m/movies.dat",
sep="::",
schema=movies_schema,
header=False
)
dfs['movies_df'] = movies_df
if load_ratings:
ratings_df = spark.read.csv(
"F:/Python/pythonproject/pyspark/datas/ml-1m/ratings.dat",
sep="::",
schema=ratings_schema,
header=False
)
dfs['ratings_df'] = ratings_df
if load_users:
users_df = spark.read.csv(
"F:/Python/pythonproject/pyspark/datas/ml-1m/users.dat",
sep="::",
schema=users_schema,
header=False
)
dfs['users_df'] = users_df
if load_occupations:
occupations_df = spark.read.csv(
"F:/Python/pythonproject/pyspark/datas/ml-1m/occupations.dat",
sep="::",
schema=occupations_schema,
header=False
)
dfs['occupations_df'] = occupations_df
if load_ages:
ages_df = spark.read.csv(
"F:/Python/pythonproject/pyspark/datas/ml-1m/ages.dat",
sep="::",
schema=ages_schema,
header=False
)
dfs['ages_df'] = ages_df
return dfs
# 加载数据的函数
def load(spark, load_movies=False, load_ratings=False, load_users=False, load_occupations=False, load_ages=False):
return load_data(spark, load_movies, load_ratings, load_users, load_occupations, load_ages)
if __name__ == "__main__":
# 创建SparkSession
spark = SparkSession.builder \
.appName("MovieLens Data Loading") \
.getOrCreate()
# 加载所有数据
data = load(spark, load_movies=True, load_ratings=True, load_users=True, load_occupations=True, load_ages=True)
# 显示数据
if 'movies_df' in data:
data['movies_df'].show(10)
if 'ratings_df' in data:
data['ratings_df'].show(10)
if 'users_df' in data:
data['users_df'].show(10)
if 'occupations_df' in data:
data['occupations_df'].show(10)
if 'ages_df' in data:
data['ages_df'].show(10)
# 停止SparkSession
spark.stop()
输出结果(每个数据输出前10行):
电影数据:

评分数据:
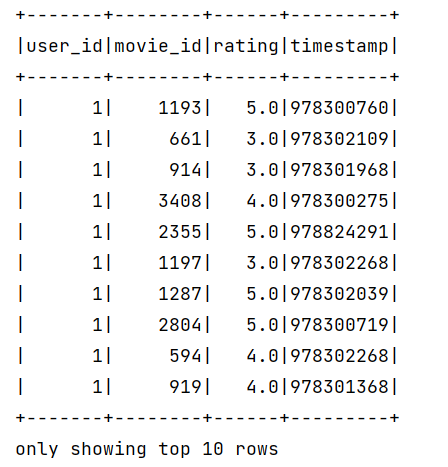
用户数据:
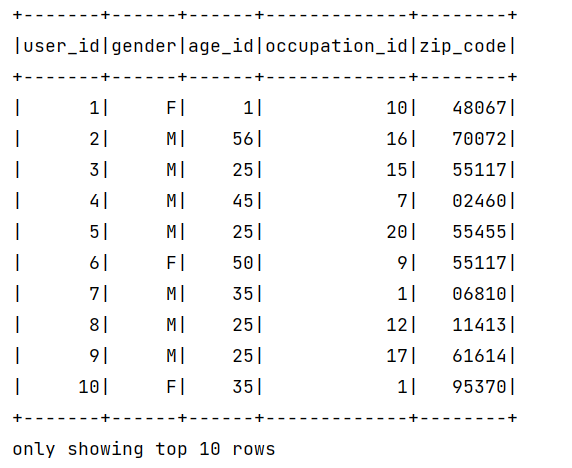
职业数据:

年龄数据:

5.3.2 Task01:分别统计用户数、男女人数、职业个数
from load_data import load
from pyspark.sql import SparkSession
from pyspark.sql.functions import countDistinct
"""
Task01: 统计用户数、男女人数、职业个数
"""
# 创建SparkSession
spark = SparkSession.builder \
.appName("Task01") \
.getOrCreate()
# 调用 load 函数进行数据加载,只加载 users_df和 occupations_df
data = load(spark, load_users=True, load_occupations=True)
# 显示数据
users_df = data['users_df']
occupations_df = data['occupations_df']
# users_df.show(10)
# 统计用户个数
user_count = users_df.count()
print(f"用户个数: {user_count}")
# 统计男女人数
gender_count = users_df .groupBy("gender") .agg(countDistinct("user_id").alias("count"))
gender_count.show()
# 统计职业个数
occupation_count = occupations_df.count()
print(f"职业个数: {occupation_count}")
# 停止SparkSession
spark.stop()
代码解析:
users_df.groupBy("gender"):按gender列对users_df进行分组。
.agg(countDistinct("user_id").alias("count")):对每个分组计算user_id的唯一值数量,并将结果列命名为count。
gender_count:将结果存储在变量gender_count中。
输出结果:

5.3.3 Task02:统计年龄分布情况
from pyspark.sql import SparkSession
from pyspark.sql.functions import countDistinct
from load_data import load
"""
Task02: 统计年龄分布情况
"""
# 创建SparkSession
spark = SparkSession.builder \
.appName("Task02") \
.getOrCreate()
# 调用 load 函数进行数据加载,加载 users_df 和 ages_df
data = load(spark, load_users=True, load_ages=True)
# 显示数据
users_df = data['users_df']
ages_df = data['ages_df']
# 将 users_df 和 ages_df 进行连接
users_df = users_df.join(ages_df, users_df.age_id == ages_df.age_id, "left").select("user_id","age_range")
# 显示前10条数据
users_df.show(10)
# 统计年龄范围个数
age_range_count = users_df.groupBy("age_range").agg(countDistinct("user_id").alias("count"))
age_range_count.show()
# 停止SparkSession
spark.stop()
输出结果:
左连接后的表:

统计结果:

5.3.4 Task03:统计职业分布情况
5.3.5
5.3.6
5.3.7
5.3.8
5.3.9
5.3.10
问题
1. 测试hadoop出现错误
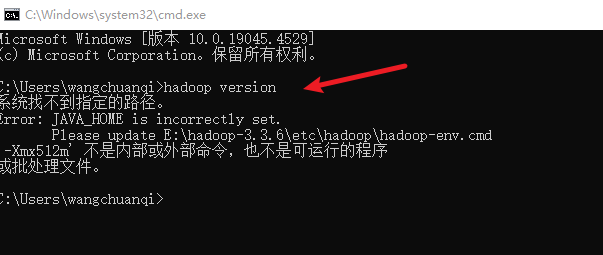
原因分析:这时候,多半是因为你的java环境变量路径含有空格。
解决方法:
(1)找到hadoop\etc\hadoop这个目录下的hadoop-env.cmd这个命令脚本。
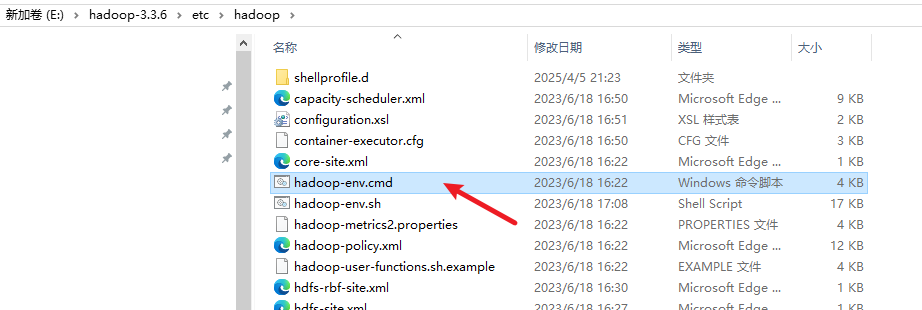
然后,右键,编辑/notpad ++ ,进入编辑页面:

修改JAVA_HOME,我的JAVA的安装路径为:C:\Program Files\Java\jdk-1.8
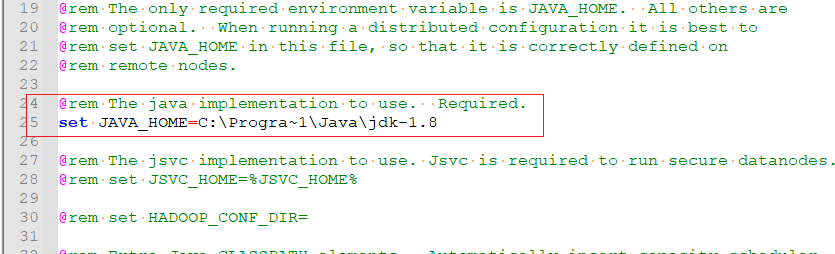
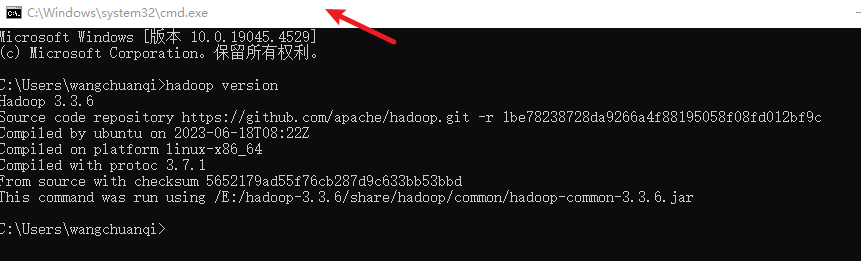
添加引号:

查看hadoop版本:
2. Please install psutil
运行代码,出现下面的情况:
E:\penv\pyspark_env\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
E:\penv\pyspark_env\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
E:\penv\pyspark_env\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
E:\penv\pyspark_env\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
进程已结束,退出代码0

解决方案,安装这个包:
pip install psutil


















 3159
3159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











