







自增运算符重载
总所周知,C++的自增运算符有两种基本使用方法,在这里我们分别称为i++和++i,想必大家在C语言课上已经学了自增运算符和自减运算符,这里就不再赘述,这里主要讲解自增运算符重载,自减运算符完全可以触类旁通。
首先了解什么是运算符重载。
定义:运算符重载是面向对象编程语言中的一种特性,它允许程序员重新定义或重载大部分的内置运算符,以便它们能用于自定义的数据类型。
什么意思呢?举个简单的例子,两个同为整型数的数相加很正常,大家也很常见。可大家看过两个同类型的自定义结构体或对象相加吗?这并非不可思议,在C++的世界里大量充斥着这些语法,并且它们有着良好的可读性。
先看一段简单的例子:
class Example {
public:
double a,b;
Example(){}
Example(double r, double i) : a(r), b(i) {}
};
int main() {
Example c1(1.0, 2.0);
Example c2(3.0, 4.0);
Example sum = c1 + c2;
return 0;
}
当你放到IDE里会报错,没错因为编译器并不认识这个加号,它不知道你想干什么,它该怎么做。这时,我们就需要加法运算符重载了,它的功能就是告诉编译器这个加法究竟该怎么做。
重载后:
class Example {
public:
double a,b;
Example(){}
Example(double r, double i) : a(r), b(i) {}
Example operator+(const Example &rhs) const {
return {a + rhs.a,b + rhs.b};
}
};
int main() {
Example c1(1.0, 2.0);
Example c2(3.0, 4.0);
Example sum = c1 + c2;
return 0;
}
再次运行,就成功了。
这篇文章的主题是自增运算符重载,自然就要重点讲它了!它的重载,其实跟其他运算符的重载没有本质的区别,就是告诉编译器这个结构体或类的自增该如何自增。
假设我们的自增操作只针对a,也就是说每次自增a加1,b不变(当然你也可以假设其他的自增方式)。大家初次看,其实会对这种写法感到奇怪。事实上这种写法比较固定,多写几遍自然就记得了。
代码展示:
class Example {
public:
double a,b;
Example(){}
Example(double r, double i) : a(r), b(i) {}
friend ostream &operator<<(ostream &os,const Example &example){//流输出运算符,只是为了方便输出及观察效果
os << "a: " << example.a << " b: " << example.b;
return os;
}
//重点
Example& operator++(){//++i类型的运算符重载
//先加一,再返回
a++;
return *this;
}
Example operator++(int){//i++类型的运算符重载
//先返回,再加一
Example temp= *this;
a++;
return temp;
}
};
int main() {
Example c(1.0, 2.0);
cout<<c<<endl;//{1,2}
cout<<++c<<endl;//a先加一变为2,再返回,{2,2}
cout<<c++<<endl;//先返回,a再加一变为3,{2,2}
cout<<c<<endl;//{3,2}
return 0;
}
检测结果:

效率对比
我们为什么要学习这些东西呢?~~当然是为了炫技。~~其实是为了写出更好的程序。细心的同学可能已经发现了端倪:两种自增方式的返回方式不一样,++i直接返回引用,i++是重新构造了一个对象返回。我们这里暂时不去说左值右值的问题,我们现在关心的是它的效率。
熟悉类和对象的同学应该知道,既然++i直接返回引用,不需要重新构造一个对象,那它就应该比i++效率更高,这是一个很简单的道理,因为它没有构造、复制值、析构等一系列的开销,而这些开销会导致额外的运行时间。
那么事实是不是如此呢?让我们赶紧来测试一下:
测试代码:
Example v,u;
double start,end;//记录时间
for (int k = 0; k < 5; ++k) {//重复测试5次
start=clock();
for (v.a=0;v.a<30000;++v){
for (u.a = 0; u.a < 30000; ++u) {
double a=u.a+v.a;
}
}
end=clock();
cout<<format("++i共耗时{:.2f}秒",(end-start)/1000)<<endl;//++i耗时
start=clock();
for (v.a=0;v.a<30000;v++){
for (u.a = 0; u.a < 30000; u++) {
double a=u.a+v.a;
}
}
end=clock();
cout<<format("i++共耗时{:.2f}秒",(end-start)/1000)<<endl<<endl;//i++耗时
}
测试结果:
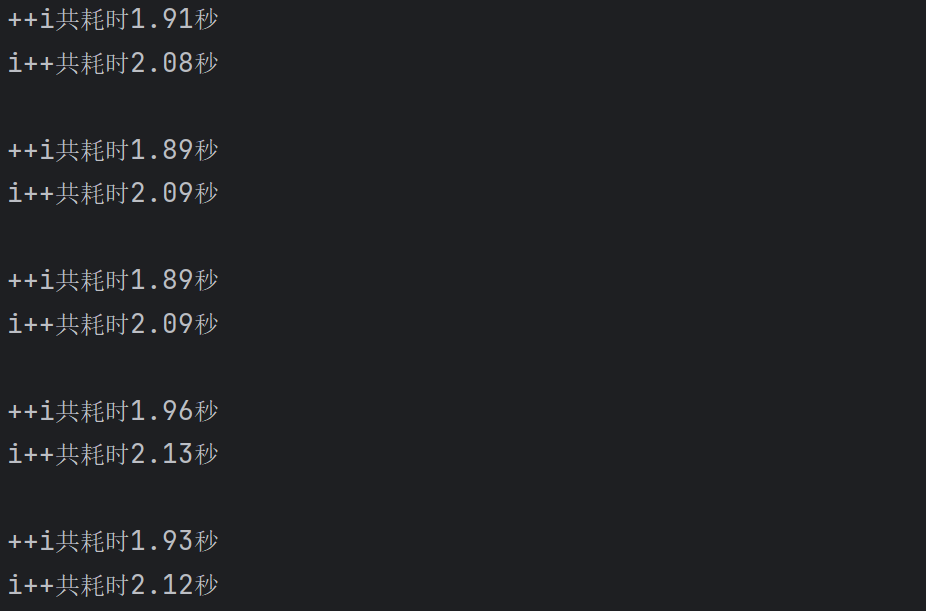
可以看到,++i的确比i++更快。具体快多少则取决于你的构造函数和析构函数的操作需要耗时多少。
如果是没有构造函数和析构函数的类型呢?比如说int,float这种类型呢?再来测试一下:
double start,end;//记录时间
for (int k = 0; k < 5; ++k) {//重复测试5次
start=clock();
for (int i = 0; i < 70000; ++i) {
for (int j = 0; j < 70000; ++j) {
int n=i+j;
}
}
end=clock();
cout<<format("++i共耗时{:.2f}秒",(end-start)/1000)<<endl;//++i耗时
start=clock();
for (int i = 0; i < 70000; i++) {
for (int j = 0; j < 70000; j++) {
int n=i+j;
}
}
end=clock();
cout<<format("i++共耗时{:.2f}秒",(end-start)/1000)<<endl<<endl;//i++耗时
}
测试结果:
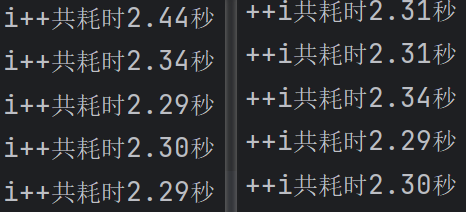
可以看到,结果差不太多。其实抛开编译器优化和可用内存的影响,像int这种内置类型,两种方式效率几乎一样。
结论:自定义类型++i效率更高,内置类型两者几乎没有区别。综上,在循环体中应尽量使用++i的方式。















 779
779











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











