







A Crash Course in Good and Bad Controls(一个快速控制好的坏的程序)
作者:Carlos Cinelli, Andrew Forney, Andrew Forney
翻译:Wendy
摘要
许多统计学和计量经济学的学生对传统文献中处理“不良控制”问题的方式表示失望。 当将变量添加到回归方程时,会在回归系数与系数打算表示的效果之间产生意外差异时,就会出现问题。 避免这种差异对数据密集型科学中的所有分析师提出了挑战。 本说明通过一系列说明性示例描述了用于理解、可视化和解决问题的图形工具。 通过让教师和从业者可以使用这个“速成课程”,我们希望将这些工具用于更广泛的关注回归模型因果解释的科学家社区。
引言
学生、数据分析师和经验主义社会科学家可能遇到过“不良控制”的问题。 当分析师需要决定将变量添加到回归方程是否有助于使估计值更接近感兴趣的参数时,就会出现问题。 分析人士早就知道,当添加到回归方程中时,一些变量可能会在回归系数与预期系数所代表的效果之间产生意想不到的差异。 此类变量已被称为“不良控制”,以区别于“良好控制”(也称为“混杂因素”或“去混杂因素”),后者是必须添加到回归方程中以消除所谓的 “省略变量偏差”。
然而,“不良控制”的问题并没有在标准统计和计量经济学文献中得到系统的关注。 尽管大多数被广泛采用的教科书都讨论了忽略“相关”变量的问题,但它们并未就决定哪些变量是相关的,以及哪些变量(如果包含在回归中)可能导致或恶化现有的偏见提供指导。 1 研究人员暴露 只有这些文献可能会让人觉得在回归模型中添加“更多控制”总是更好。 不幸的是,讨论“不良控制”问题的少数例外仅涵盖了问题的一小部分(例如 Angrist 和 Pischke,2009 年,2014 年;Wooldridge,2010 年;Imbens 和 Rubin,2015 年;Gelman 等人,2020 年)。 典型的是 Angrist 和 Pischke (2009, p.64) 中的讨论
一些变量是不好的控制,不应包含在回归模型中,即使它们的包含可能会改变短期回归系数。 不良控制是指在手头的概念实验中本身就是结果变量的变量。 也就是说,糟糕的控制也可能是因变量。 良好的控制是我们可以认为在确定感兴趣的回归量时已经固定的变量。
在这里,“好的控制”被定义为被认为不受添加变量影响的变量,而“坏控制”是原则上可能受添加变量影响的变量。 Rosenbaum (2002) 和 Rubin (2009) 以及 Wooldridge (2005) 中都可以找到类似的讨论,用于限定变量以包含在倾向得分分析中。 一些作者(例如,Wooldridge,2010 年;Gelman 等人,2020 年)简要警告了某些预处理变量的偏差放大的可能性,但没有进一步详细说明。 尽管对没有讨论的情况有所改进,但这些条件对于决定一个变量是否是一个好的控制既不是必要的,也不是充分的。
图形模型的最新进展产生了区分“好”和“坏”控件的简单标准。 这些范围从决定应调整哪些变量集以识别感兴趣的因果效应的必要和充分条件(例如,Pearl (1995) 和 Shpitser et al. (2012) 中的后门标准和调整标准),到决定 其中,在一组有效的调整集中,将产生更精确的估计(Hahn,2004;White 和 Lu,2011;Henckel 等人,2019;Rotnitzky 和 Smucler,2020;Witte 等人,2020)。 本说明的目的是通过说明性示例为执业分析师提供这些标准的简明、简单和直观的总结。
预备知识和基本术语
因果图,更具体地说,有向无环图 (DAG),已经在社会和健康科学中流行起来,用于以严格但易于理解的方式解释和解决因果推理的难题。 许多关于 DAG 的介绍现已在多个学术领域发表,例如社会学(Elwert,2013;Morgan 和 Winship,2015)、经济学(Hünermund 和 Bareinboim,2019;Cunningham,2021)、心理学(Rohrer,2018)、流行病学 (Greenland et al., 1999; Hernán and Robins, 2020) 和统计数据 (Pearl et al., 2009, 2016)。 在这里,我们假设读者熟悉因果推理、DAG 的基本概念,尤其是“路径阻塞”以及后门路径。 对于那些需要刷新这些概念的人,我们在附录中提供了一个温和的介绍。 尽管如此,鉴于我们说明性示例的简单性,即使是外行的读者也将能够理解本速成课程的主要课程并从中受益。
简而言之,因果 DAG 提供了数据生成过程的定性方面的简约表示。 字母(例如 X)代表随机变量,箭头(例如 X→ Y)表示 X 对 Y 的(可能)直接因果效应。 不需要对因果关系的函数形式进行假设,也不需要对变量的分布进行假设。 对于本速成课程,重要的是要回顾构成 DAG 构建块的三个主要关联来源,以及它们何时关闭或打开:
- 中介或链是 X→ Z→ Y 形式的模式,这意味着 X 通过中介 Z 对 Y 产生因果影响。对链中的 Z 进行调节会阻止(关闭)这种关联流。
- 共同原因或分叉是 X← Z→ Y 形式的模式,这意味着 X 和 Y 共享共同原因(混杂因素)Z,从而导致两个变量之间存在非因果关联。 在叉子中以 Z 为条件会阻止这种关联流。
- 共同效应或碰撞器是 X→ Z← Y 形式的模式,这意味着 X 和 Y 共享共同效应 Z。与其他两个变量相反,默认情况下共同效应不会导致 X 和 Y 之间的关联 . 然而,以 Z 为条件会导致两个变量之间存在非因果关联。
此外,要记住的一个重要事实是,控制变量的后代等同于“部分”控制该变量。 任何从 X 到 Y 的任意路径 p(由一系列中介、共同原因或对撞机组成)将在 Z 条件下被阻塞,当且仅当 Z 是沿路径的共同原因或中介,或者如果 p 包含 collider 和 Z 不是那个对撞机,也不是它的任何后代。 如果 Z 阻塞(关闭)从 X 到 Y 的所有路径,我们说 Z 将 X 从 Y 中分离出来; d-分离意味着在给定 Z 的情况下 Y 和 X 是条件独立的。
请注意,从 X 到 Y 的因果路径是 X→····→ Y 形式的路径,即由一系列(可能为空的)中介组成的路径。 所有其他路径都是非因果的,可能会导致 X 和 Y 之间的“虚假”关联。 特别是,对于给定的变量 X,我们将那些以指向 X 的箭头开头的混杂路径称为“后门”路径。如果我们有兴趣,那么,在估计 X 对 Y 的因果影响时,我们的任务在概念上是 很简单:我们必须阻止 X 和 Y 之间的所有虚假路径,并且我们不能扰乱它们之间的任何因果路径。 这将是我们决定是否应将 Z 包含在回归方程中的指导原则,它表征了称为后门准则和调整准则的图形条件的本质(Pearl,1995;Shpitser 等人, 2012)。 读者可以在附录中找到这些图形标准的正式陈述。
说明性示例
在以下一组模型中,我们分析的目标是原因 X 对结果 Y 的平均因果效应 (ACE),它代表 Y 的预期增加,以响应由于干预导致 X 增加一个单位。观察到的变量将用黑点表示,未观察到的变量用白色空圆圈表示。以红色突出显示的变量 Z 表示待决定是否包含在回归方程中的变量,“良好控制”表示偏差减少,“不良控制”表示偏差增加,“中性控制”当添加Z 既不增加也不减少渐近偏差。对于最后一种情况,我们还将简要说明 Z 如何影响 ACE 估计的精度。习惯于潜在结果框架的读者应该知道,决定 Z 是否是“良好控制”等同于决定原因分配的可忽略性是否成立,以 Z 为条件。喜欢看代数推导的读者可以在附录中找到每个图表的解析表达式,在线性假设下2(然而,“坏控制”的问题是非参数的,即,无论函数形式假设如何,它都成立)。
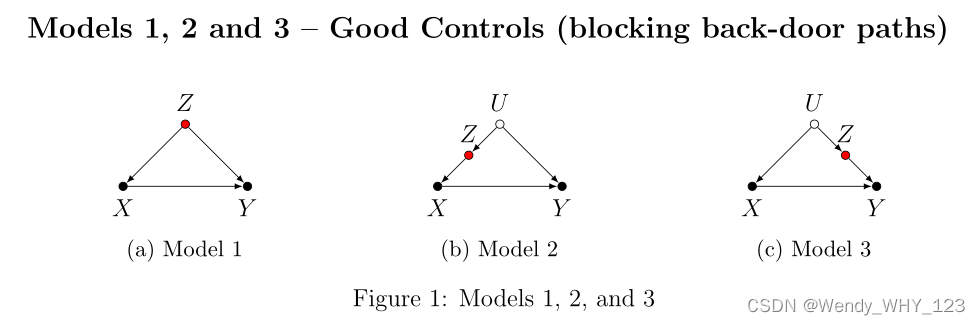
在模型 1 中,Z 代表 X 和 Y 的共同原因。 一旦我们控制了 Z,我们就阻断了从 X 到 Y 的后门路径,从而产生了 ACE 的无偏估计。 在模型 2 和模型 3 中,Z 不是 X 和 Y 的共同原因,因此,不是模型 1 中的传统“混杂因素”。然而,控制 Z 阻止了从 X 到 Y 的后门路径,因为 未观察到的混杂 U ,再次产生 ACE 的无偏估计。
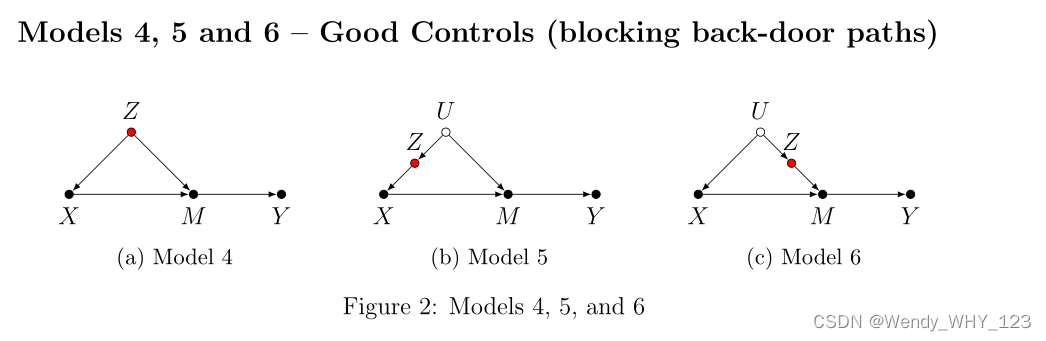
在考虑可能的混淆威胁时,建模者需要记住 X 的常见原因和任何中介(在 X 和 Y 之间)也会混淆 X 对 Y 的影响。 因此,模型 4、5 和 6 类似于模型 1、2 和 3——控制 Z 阻断从 X 到 Y 的后门路径,并产生 ACE 的无偏估计。
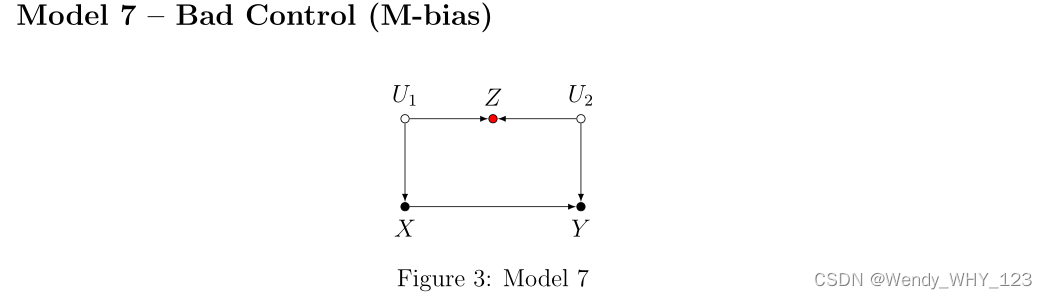
我们现在遇到了我们的第一个“坏控制”。 这里 Z 与原因和结果相关,它也是一个“原因前”变量。 传统的计量经济学教科书通常认为预处理变量是“良好的控制”。 然而,仔细分析表明,Z 是一个“糟糕的控制”。 控制 Z 将通过打开后门路径 X← U 1→ Z← U 2→ Y 来诱导偏差,从而破坏先前对 ACE 的无偏估计。 这种结构被称为“M-bias”,并引发了一些争议。 读者可以在 Pearl (2009a, p. 186)、Shrier (2009)、Pearl (2009c,b)、Sjölander (2009)、Rubin (2009)、Ding and Miratrix (2015) 和 Pearl (2015) 中找到进一步的讨论。
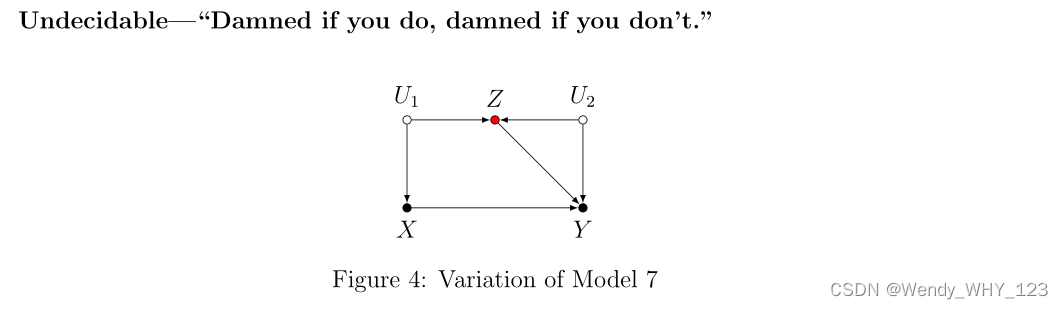
考虑模型 7 的一种变体,使得 Z 对 Y 有直接影响,如图 4 所示。请注意,现在我们有一条开放的后门路径 X← U1→ Z→ Y,未经调整的估计为 更长的公正。 在调整 Z 关闭这条后门路径的同时,它也打开了路径 X← U1→ Z← U2→ Y 的后门,就像我们在前面的示例中所做的那样。 在任何一种情况下,都没有确定因果效应,并且在没有进一步假设的情况下无法确定对 Z 进行调整是否会减少或增加偏差的绝对值(见附录)。 在这种情况下,可以通过敏感性分析取得进展,例如,对 Z 对 Y 的直接影响的强度或潜在变量的影响强度设定合理的界限。
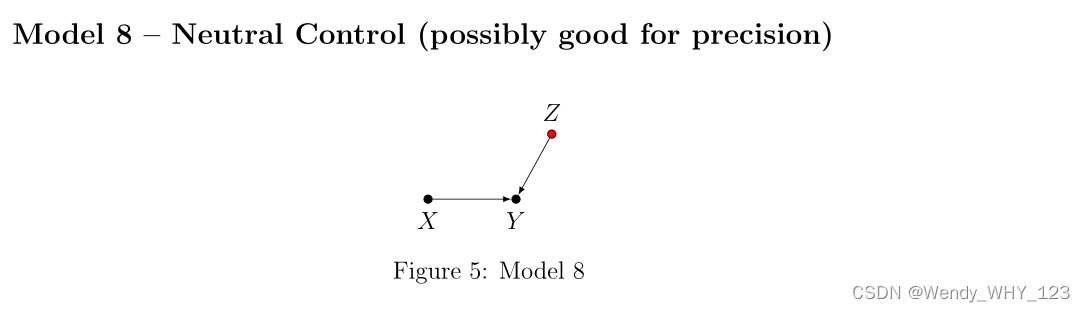
在 Model 8 中,Z 不是混杂因素,也不会阻止任何后门路径。 同样,控制 Z 不会打开从 X 到 Y 的任何后门路径。 因此,就渐近偏差而言,Z 是“中性控制”。 然而,分析表明,控制 Z 减少了结果变量 Y 的变化,并有助于提高 ACE 估计无限样本的精度。
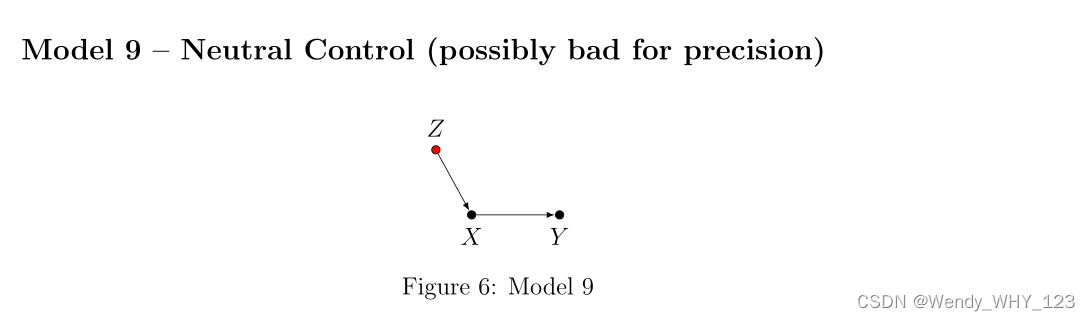
与前一种情况类似,在 Model 9 中,Z 在减少偏差方面是“中性的”。 然而,控制 Z 将减少处理变量 X 的变化,因此可能会损害 ACE 无限样本的估计精度。 作为一般的经验法则,对于识别不是必需的 X 的父母对估计量的渐近方差是有害的; 另一方面,不破坏认同的 Y 的父母是有益的。 参见 Henckel 等人用于通过线性模型调整进行有效估计的图形标准的最新发展。 值得注意的是,这些条件也被证明适用于广泛类别的非参数估计量的非参数模型。
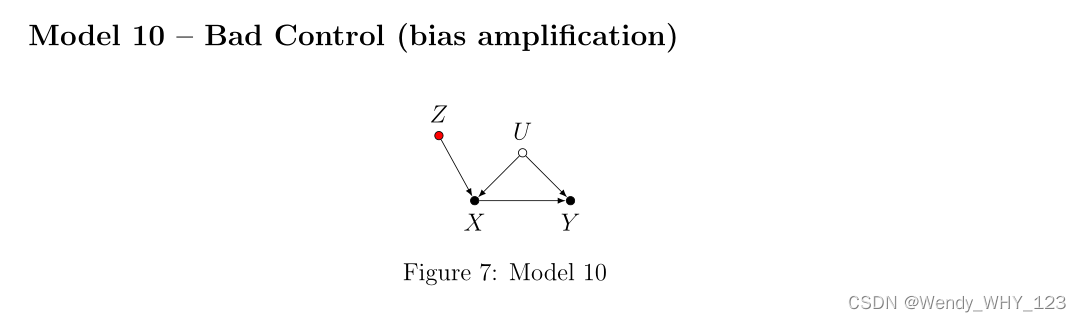
由于一种称为“偏差放大”的现象,我们现在遇到了第二次“预处理”“不良控制”。 在这个模型中对 Z 的朴素控制不仅不能消除 X 对 Y 的影响,而且在线性模型中,会放大任何现有的偏差。
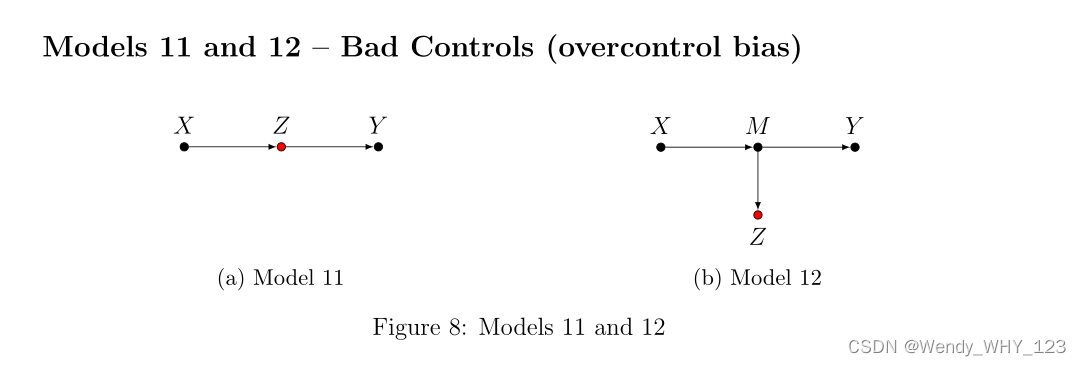
如果我们的目标数量是 ACE,我们希望让因果效应流经的所有渠道“保持不变”。 在模型 11 中,Z 是 X 对 Y 的因果效应的中介。 控制 Z 将阻止我们想要估计的效果(X 对 Y 的总影响),从而使我们的估计产生偏差(这通常被称为“过度控制偏差”)。 在模型 12 中,虽然 Z 本身不是 X 对 Y 的因果影响的中介,但控制 Z 等同于部分控制中介 M,因此会使我们的估计产生偏差。 模型 11 和 12 违反了后门标准(Pearl,2009a),该标准排除了作为治疗后裔的对照,这些对照是沿着通往结果的路径。 请注意,如果我们有一个额外的直接因果路径 X→ Y,同样的结论也会成立。
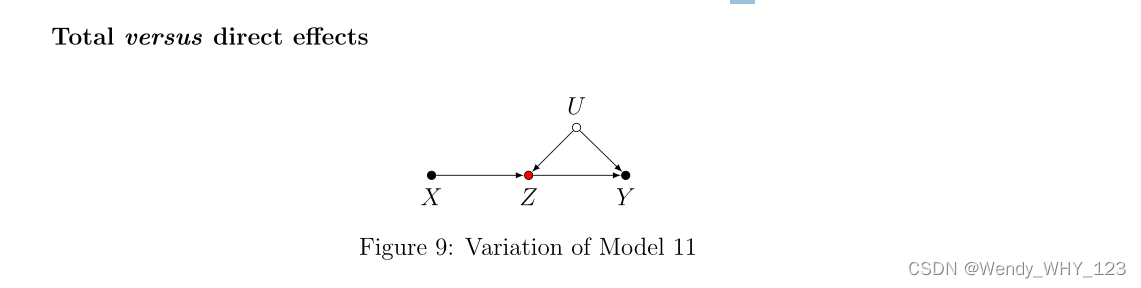
前面的考虑假设研究人员对 X 对 Y 的总体影响感兴趣,正如 ACE 给出的那样。 相反,如果兴趣在于 X 对 Y 的受控直接影响 (CDE)(即通过干预使 Z 保持不变时 X 的影响,请参见 Pearl (2009a, 2011) 以及附录),然后调整 Z 在模型 11(图 8a)中确实是合适的。 然而,考虑模型 11 的一个变体,其中 Z 和 Y 的未观察到的混杂,用 U 表示,如图 9 所示。首先注意到 U 不会混淆 X 对 Y 的影响,因此我们的 ACE 估计仍然是无偏的,因为它 在模型 11 中,只要我们不调整 Z。另一方面,这里调整 Z 现在会打开碰撞路径 X→ Z← U→ Y,从而使 CDE 估计有偏差。
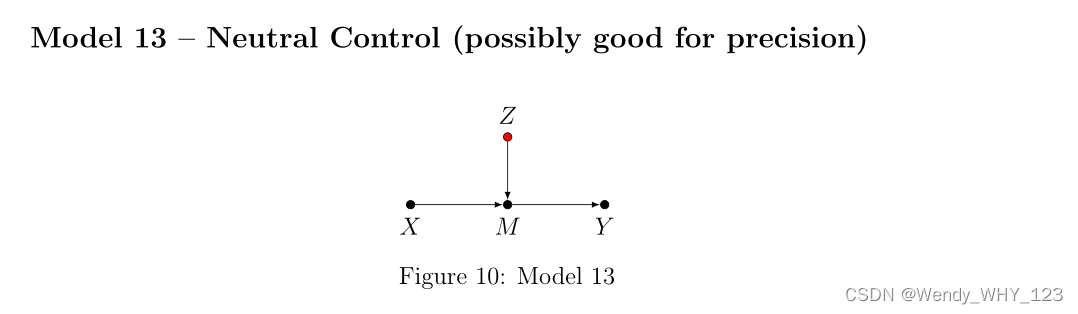
乍一看,模型 13 可能看起来与模型 12 相似,人们可能会认为调整 Z 会通过限制介体 M 的变化来使效果估计产生偏差。 然而,这里的关键区别在于 Z 是中介的原因,而不是结果(因此也是 Y 的原因)。 因此,模型 13 类似于模型 8,因此对 Z 的控制在偏差方面将是中性的,并且可能会增加 ACE 估计无限样本的精度。 读者可以在 Pearl (2013) 中找到对此案例的进一步讨论。
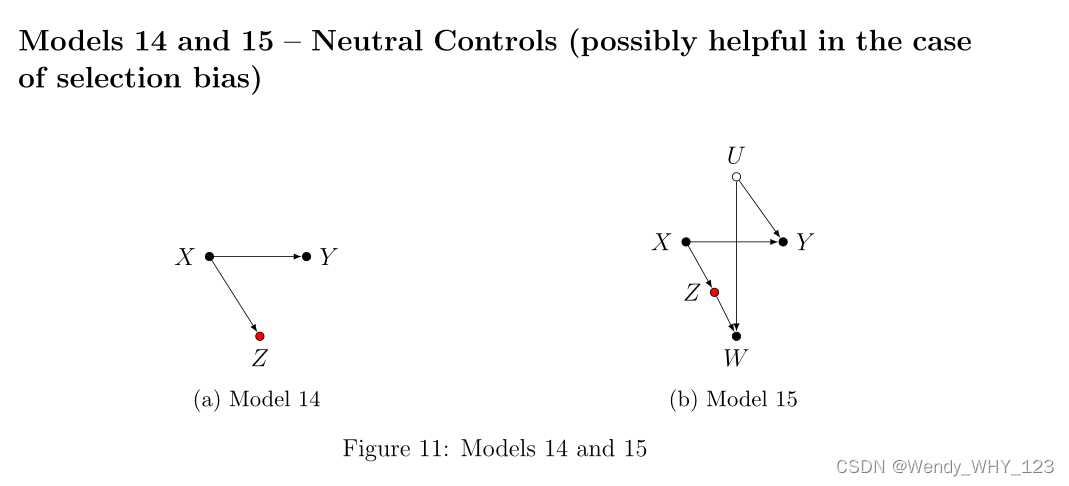
与民间传说相反,并非所有“治疗后”变量本质上都是不良控制。 在模型 14 和 15 中,控制 Z 不会在 X 和 Y 之间打开任何混淆路径。 因此,Z 在偏差方面是中性的。 然而,控制 Z 确实减少了处理变量 X 的变化,因此可能会损害 ACE 估计无限样本的精度。 此外,在模型 15 中,假设仅记录了 W = w 的样本(选择偏差 3 的情况,我们将在下面解释)。 在这种情况下,控制 Z 可以通过阻止由于 W 引起的碰撞路径来帮助获得 X 对 Y 的 W 特定效果。 在线性模型中,控制 Z 实际上完全恢复了 ACE(见附录)。
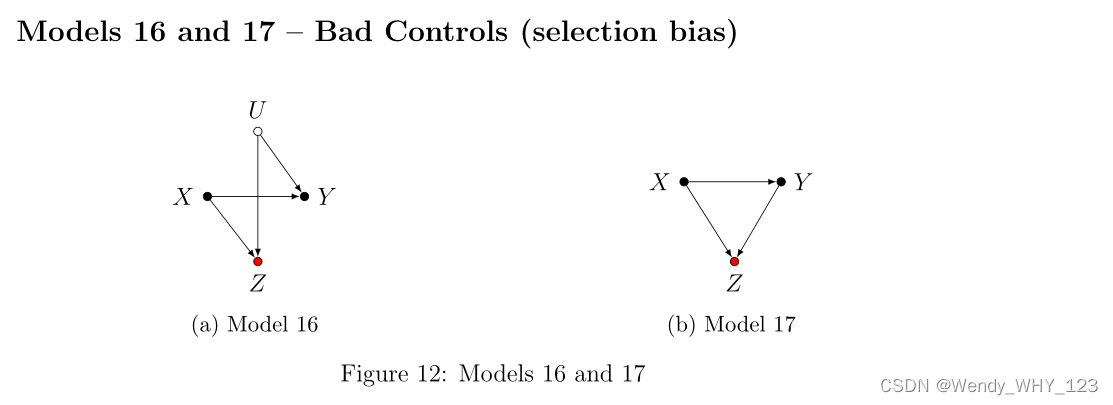
与模型 14 和 15 不同,这里对 Z 的控制不再是无害的,并且会导致经典的“选择偏差”或“对撞机分层偏差”。 在 Model 16 中调整 Z 会打开碰撞路径 X→ Z← U→ Y,因此会偏置 ACE。 在模型 17 中,调整 Z 不仅打开了路径 X→ Z← Y ,而且还打开了由于 Y 的潜在父母而导致的碰撞路径,从而使 ACE 产生偏差并激励我们的最终示例。
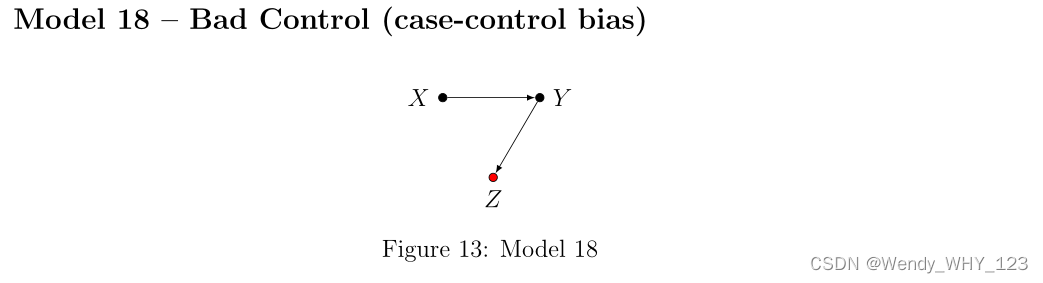
在我们的最后一个示例中,Z 不在从 X 到 Y 的因果路径中,Z 不是 X 的直接原因,并且 Z 与 Y 相连。 因此,人们可能会推测,就像在模型 8 中一样,控制 Z 对识别无害,并且可能有益于无限样本效率。 然而,控制结果 Y 的影响会导致 ACE 估计的偏差,即使没有直接箭头 X→ Z,从而使 Z 成为“不良控制”。 发生这种情况是因为 Z 实际上是对撞机的后代:结果 Y 本身。 可以在 Pearl (2009a, Sec. 11.3) 中找到使用“虚拟对撞机”对这种现象的直观解释。 同样的现象也可以通过在 DAG 上明确绘制潜在结果来解释(参见附录中的两种解释)。 模型 18 是 DAG 选择偏差的特殊情况(参见附录中的两个解释)。 模型 18 是选择偏差的特例。
应用研究中的不良控制
尽管它们很简单,但这些说明性示例应该为从业者提供一个原则框架,以理解现实世界应用程序中发现的许多问题。 为了证明,我们现在简要介绍应用研究中讨论的三个不良控制案例,它们来自流行病学、社会学和经济学等不同领域。
出生体重悖论。 发现吸烟者所生婴儿的死亡风险高于非吸烟者所生婴儿。 然而,在低出生体重 (LBW) 婴儿中,这种关系发生了逆转。 这种效果的逆转在流行病学上引起了许多争议——这是否意味着母亲吸烟对 LBW 婴儿有益? 这种发现的一个合理原因可能只是对撞机分层偏差,如模型 16 所示。这里 X 是母亲吸烟,Y 婴儿死亡率,Z 出生体重,U 代表未观察到的风险因素(例如出生缺陷和营养不良 ),这也可能影响出生体重。 请注意,由于相互竞争的风险因素,按出生体重对分析进行分层会导致吸烟与死亡率之间的虚假关联。 非吸烟者的 LBW 婴儿的 LBW 需要有其他原因(例如营养不良),而这些原因也可能导致更高的死亡率。
社交网络分析中的同质偏见(Elwert 和 Winship,2014 年)。 社交网络因果推理的一项重要任务是估计社会传染的因果效应,也称为“人际效应”。 然而,社交网络分析中的社会关系可能是模型 7 的“M-bias”结构中示例的预处理碰撞器。假设我们有兴趣评估个体 1 (X) 的公民参与是否会导致公民参与 个人 2 在随后的时间段 (Y) 中的参与。 让 Z 表示这些人是否是朋友,U1 和 U2 分别表示个人 1 和 2 的个人特征(例如利他主义)。 在这里,社交关系 Z 是一个对撞机,计算朋友之间 Y 和 X 的关联(Z = 1)会偏向公民参与中的人际因果效应。
战前之谜(施耐德,2020)。经济史的一个有趣谜题是,在 19 世纪的英国和美国,尽管这些国家的经济条件随着儿童营养状况的改善而改善,但成年男性的平均身高却下降了。对于这种自相矛盾的发现,一种可能的解释是模型 17 和 18 形式的选择偏差,其中研究人员使用来自军队或监狱中的个人数据的研究人员有效地以对撞机为条件。对于军事记录,考虑模型 18,X 表示儿童营养,Y 表示成人身高,Z 表示个人是否入伍。从 Y 到 Z 的因果路径代表了一个事实,即较高的男性可能在民用市场上有更好的机会,因此较矮的男性更有可能入伍。因此,将分析限制在军队入伍人员相当于控制 Z,并导致选择偏差。现在对于监狱记录,考虑模型 17,并让 Z 作为个人是否被捕的指标。在这里,人们可能会争辩说,儿童营养和成人身高都有通过社会经济机会犯罪的途径,从而再次导致选择偏见。
这些例子绝不是详尽无遗的。 读者可以在应用科学中找到其他有趣的案例,例如:对撞机偏差对理解 COVID-19 风险因素的威胁(Griffith et al., 2020); “肥胖悖论”,其中肥胖似乎有益于心力衰竭患者(Banack 和 Kaufman,2013 年); 以及由于在多代流动性(Breen,2018 年)、麻醉学研究(Gaskell 和 Sleigh,2020 年)或动物科学(Bello 等人,2018 年)中调整调解人和对撞机而导致的“不良控制”示例。 可以在 Pearl 和 Mackenzie (2018) 中找到有关理论和应用工作中不良控制的进一步讨论。
多个控件
在考虑多个控制时,单个控制的“好”或“坏”状态可能会根据所考虑的其他变量的上下文而改变。 尽管如此,我们的说明性示例中的主要教训仍然存在。 如果满足以下条件,一组控制变量 Z 将是“好”的: (i) 它阻止了从治疗到结果的所有非因果路径; (ii) 它保留了从治疗到结果“未触及”的任何中介路径(因为我们对总效果感兴趣); 并且,(iii)它不会在处理和结果之间开辟新的虚假路径(例如,由于对撞机)。 至于效率方面的考虑,我们应该优先考虑那些“更接近”结果的变量,而不是那些更接近处理的变量——当然,只要这不会破坏识别。
最后,我们提醒读者,在考虑结构更复杂的模型时,总是可以求助于专门的计算机程序。 用于选择调整集的开源软件实现算法可以在 R 包 pcalg (Kalisch et al., 2012)、dagitty (Textor et al., 2016)4 和 causaleffect (Tikka and Karvanen, 2017) 中找到。 熟悉软件 SAS 的用户可能会发现过程 CAUSALGRAPH 很有用(Thompson,2019)。 还可以使用实现 Bareinboim 和 Pearl (2016) 中讨论的方法的 Web 应用程序。换句话说,给定因果图,确定哪些变量是好控制还是坏控制的问题已经自动化。
超越调整(Beyond adjustment)
在这里,我们专注于通过简单的协变量调整来识别因果效应,根据这个标准将 Z 分类为“好”或“坏”控制。然而,其他识别机会可能是可用的。例如,再回到模型 10,Z 就是通常所说的“工具变量”。在这种情况下,虽然 Z 确实是一个“糟糕的控制”,但它仍然可以用作在某些参数假设下限制或指出因果效应的工具,尽管使用不同的公式。更一般地说,除了简单的调整公式之外,do-calculus 为因果 DAG 中治疗效果的非参数识别任务提供了完整的解决方案。在某些情况下,例如“前门”标准,这允许利用后处理变量进行识别。关于 do-calculus 的更多细节应该是单独的速成课程的主题。
敏感性分析
在现实世界的应用中,X 对 Y 的因果影响可能无法仅从 DAG 结构中识别出来。发生这种情况时,如果没有进一步的假设,通常无法确定回归方程中包含 Z 是否会减少或增加偏差的绝对值,正如我们在图 4 的示例中看到的那样。在这种情况下,关于X 对 Y 的因果影响必须依赖于 DAG 约束之外的知识,例如合理性判断 (i) 关于观察变量的直接影响,(ii) 关于潜在变量与 X 和 Y 的关联强度,或(iii) 与观察到的混杂因素相比,未观察到的混杂因素的相对重要性。可以在用于 R、Stata 和 Python 的 sensemakr 包中找到一套敏感性分析工具,用于检查线性回归估计对遗漏变量偏差 (OVB) 的稳健性。还提供交互式网络应用程序。 Chernozhukov 等人开发了使用去偏机器学习将 OVB 结果推广到完全非参数模型。
结束语
在本文中,我们通过说明性示例演示了如何使用简单的图形标准来决定何时应该(或不应该)将变量包含在回归方程中,从而确定它是否可以被视为“好”或“坏”控制 . 这些例子中的许多都是针对流行做法的警示:例如,模型 7 到 10 表明,人们应该谨慎对待通常来自倾向评分逻辑的一般性建议,即以治疗分配的所有治疗前预测因子为条件7; 而模型 14 和 15 表明,并非所有“治疗后”变量都是“不良对照”,有些甚至可能有助于识别。
在所有情况下,结构知识对于决定一个变量是好还是坏的控制都是必不可少的,而图形模型为表达这些知识提供了一种自然语言,并为检查其逻辑分支提供了有效的工具。 我们发现,一种基于示例的“不良控制”方法,例如这里介绍的方法,可以作为一种强大的教学工具来补充对问题的更广泛和正式的讨论。 通过让教师和从业者可以使用这个“速成课程”,我们希望将这些工具用于更广泛的关注回归模型因果解释的科学家社区。















 584
584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









