






前言
如今新能源汽车风靡全球,在汽车行业掀起一场巨大的变革,其中,比亚迪和特斯拉已经成为行业的风向标。对此,我们将利用网络爬虫,基于requests和etree采集这两大巨头的销量数据。
一、数据来源
本文数据均源之于车主之家,涵盖大量汽车行业销量数据。
比亚迪:https://xl.16888.com/b/57328/
特斯拉:https://xl.16888.com/b/126359/
二、步骤
1.引入库
代码如下(示例):
import requests
import pandas as pd
# from lxml import etree
from lxml import html
etree = html.etree
2.解析网页
以比亚迪为例,如图:
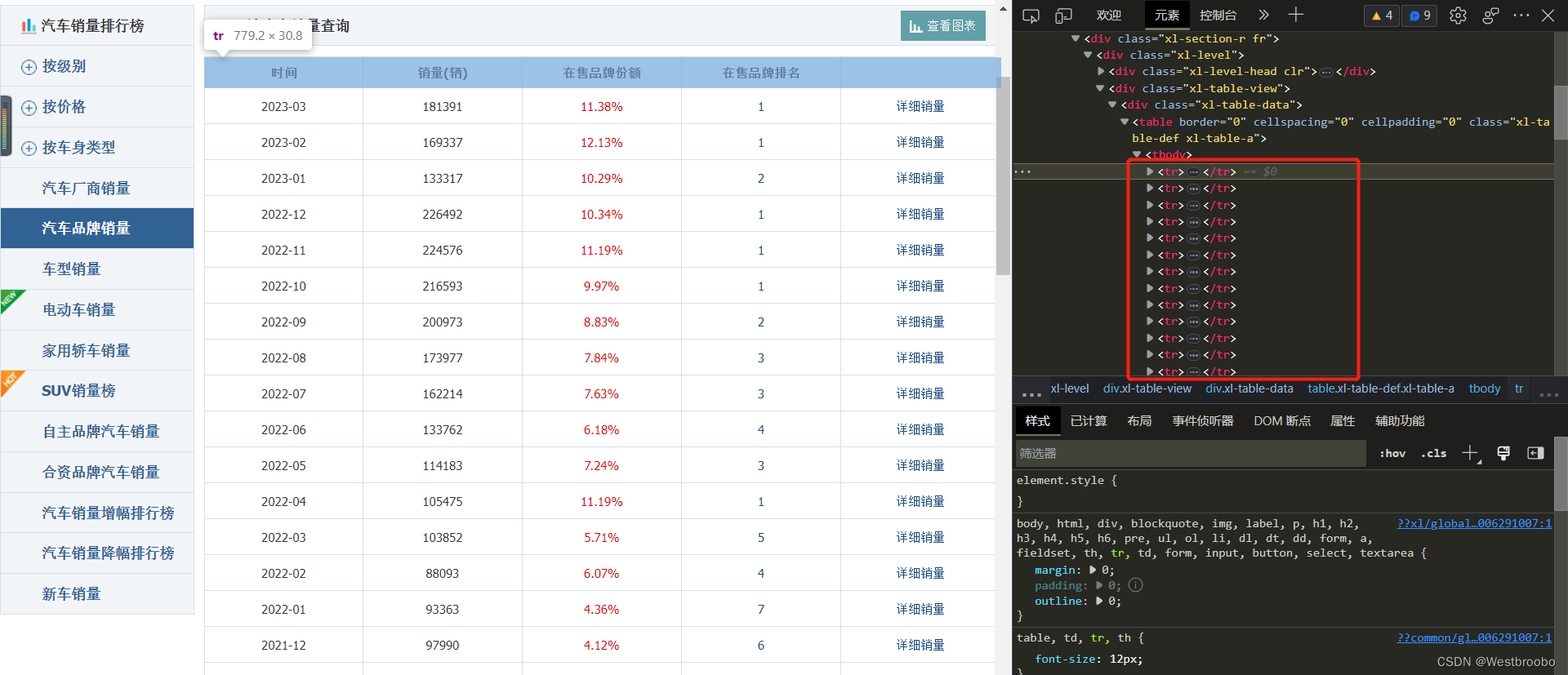
首先利用etree将网页解析为HTML格式,之后利用xpath解析获取每一个tr标签,即为对应的每一行数据,示例代码如下:
rsp = requests.get(url=url,headers=headers)
tree = etree.HTML(rsp.text)
tr_tags = tree.xpath('/html/body/div[5]/div[3]/div[2]/div/div[2]/div[1]/table/tr')
3.简单处理
这里如果将每个tr标签都拿下来,会包含最后面那个“详细销量”,且蓝色部分都还包含一个超链接,如下图。
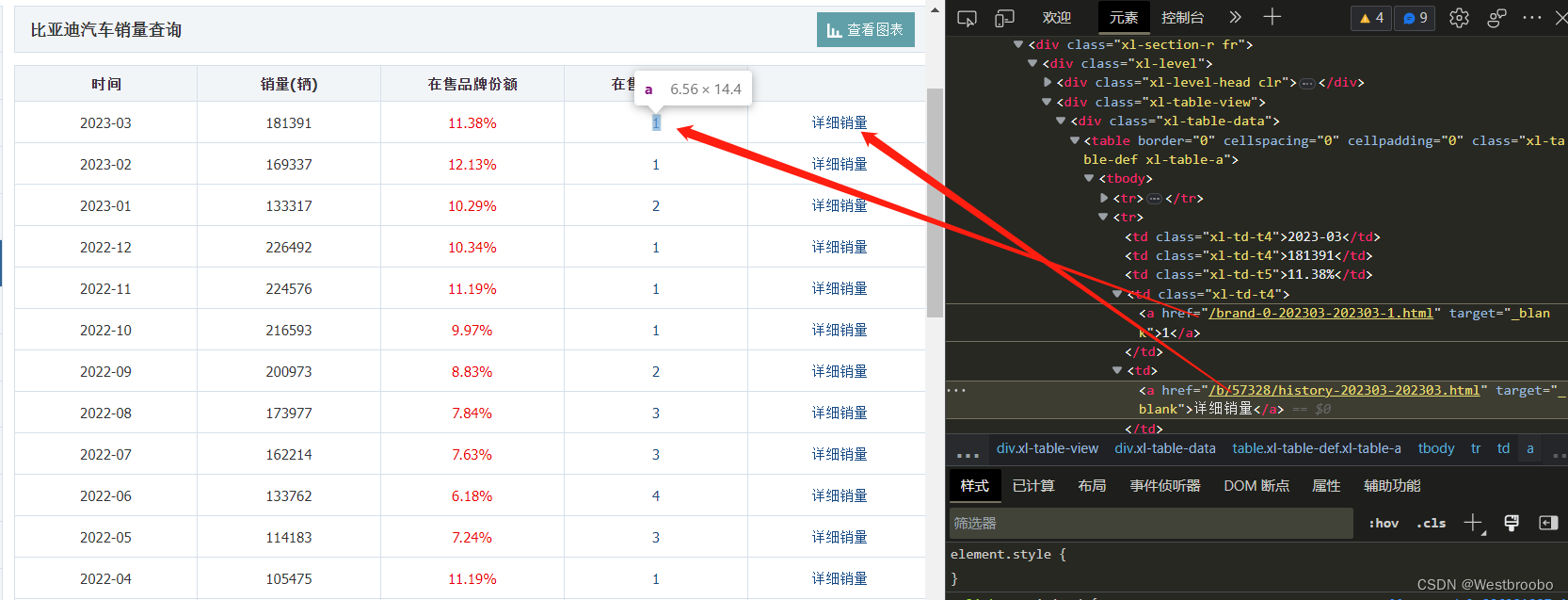
直接解析td或者th标签的文本是找不到对应数据的,所以需要筛掉,只要前4列数据,且不要超链接。通过循环简单处理,代码如下:
for t in tr_tags:
t1 = t.xpath('./th/text()')
t2 = t.xpath('./td/text()')
t3 = t.xpath('./td/a/text()')
if len(t3) == 2:
t2.append(t3[0])
else:
pass
data_list.append(t1)
data_list.append(t2)
4.简单清洗
将得到的数据通过清洗生成DataFrame格式,示例代码如下:
list_save = [d for d in data_list if d != []]
df = pd.DataFrame(list_save[1:],columns = list_save[0])
df = df.iloc[0:18].iloc[::-1]
df.index = df['时间'].tolist()
df.drop('时间',axis=1,inplace=True)
df[['销量(辆)','在售品牌排名']] = df[['销量(辆)','在售品牌排名']].apply(pd.to_numeric)
5.自定义函数汇总以上步骤
代码如下:
def sale_worm(url):
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.63',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7'}
rsp = requests.get(url=url,headers=headers)
tree = etree.HTML(rsp.text)
tr_tags = tree.xpath('/html/body/div[5]/div[3]/div[2]/div/div[2]/div[1]/table/tr')
data_list = []
for t in tr_tags:
t1 = t.xpath('./th/text()')
t2 = t.xpath('./td/text()')
t3 = t.xpath('./td/a/text()')
if len(t3) == 2:
t2.append(t3[0])
else:
pass
data_list.append(t1)
data_list.append(t2)
list_save = [d for d in data_list if d != []]
df = pd.DataFrame(list_save[1:],columns = list_save[0])
df = df.iloc[0:18].iloc[::-1]
df.index = df['时间'].tolist()
df.drop('时间',axis=1,inplace=True)
df[['销量(辆)','在售品牌排名']] = df[['销量(辆)','在售品牌排名']].apply(pd.to_numeric)
return df
总结
这里的爬虫只是爬取第一页数据,没做翻页处理,在后续的易车网爬虫中会涉及到。最后通过调用函数可以实现数据采集。
sale_TSLA = sale_worm(url_TSLA)
# sale_TSLA.to_excel('.\特斯拉.xlsx')
print(sale_TSLA.head())
sale_BYD = sale_worm(url_BYD)
# sale_BYD.to_excel('.\比亚迪.xlsx')
print(sale_BYD.head())
结果如下:
销量(辆) 在售品牌份额 在售品牌排名
2021-10 54391 2.77% 14
2021-11 52859 2.44% 14
2021-12 70847 2.98% 11
2022-01 59845 2.8% 14
2022-02 56515 3.89% 7
销量(辆) 在售品牌份额 在售品牌排名
2021-10 88898 4.53% 5
2021-11 97242 4.5% 6
2021-12 97990 4.12% 6
2022-01 93363 4.36% 7
2022-02 88093 6.07% 4
注意:如果切换车主之家其他页面进行销量爬取时,数据结构不同在处理时也要做出改变。















 2317
2317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









