



 文章讲述了如何通过JsonPath和Python的requests库爬取某证券网站上的比亚迪股价数据,处理非标准JSON格式的响应,以及如何存储和分析数据。主要涉及数据获取、正则表达式处理JSON格式头尾以及数据清洗和存储到Excel的过程。
文章讲述了如何通过JsonPath和Python的requests库爬取某证券网站上的比亚迪股价数据,处理非标准JSON格式的响应,以及如何存储和分析数据。主要涉及数据获取、正则表达式处理JSON格式头尾以及数据清洗和存储到Excel的过程。
相关文章
车主之家销量爬虫
易车网销量爬虫
使用jsonpath时的bug记录
前言
2022年10月24日特斯拉率先在6连涨后宣布降价,又在11月8日宣布推出保险方面的让利政策,因此本文将从股价上入手,从某证券网站上爬取比亚迪2022年10月-2023年2月的股价数据,观察在此时间节点比亚迪股价是如何变的。
以下基于requests和jsonpath采集比亚迪每日股价等数据
一、数据来源
数据均来源于某证券网站,股价数据实时变动。
二、分析网页
查看网页源代码可以发现源码中是没有数据的,网页数据是通过某方**Choice数据实时加载的。
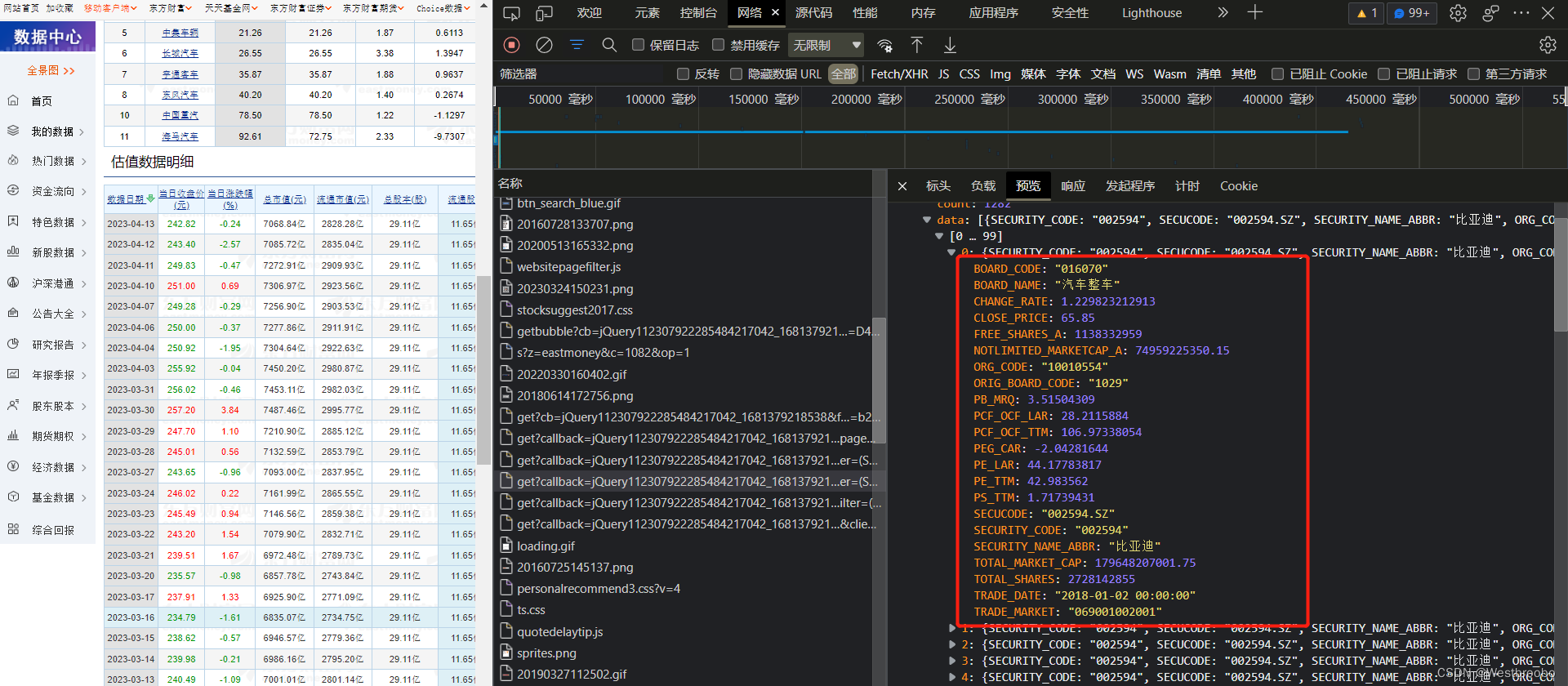
之后再找到源数据发现都是字典类型的,因此下面通过jsonpath进行解析,对应格式化地址为:https://datacenter-web.eastmoney.com/api/data/v1/get?callback=jQuery112305522640988534238_1680571452074&reportName=RPT_VALUEANALYSIS_DET&columns=ALL"eColumns=&pageNumber=1&pageSize=5000&sortColumns=TRADE_DATE&sortTypes=1&source=WEB&client=WEB&filter=(SECURITY_CODE=%22002594%22)&_=1680571452075
可以发现json格式化的开头有以jQuery开头的一串字符串和括号不是json格式,解析时肯定会有错误,关于这个问题之前的bug记录有提到过,解决方案时使用正则表达式处理,文章链接为:http://t.csdn.cn/2Ft8M。
代码如下:
import requests
import json
import re
url = 'https://datacenter-web.eastmoney.com/api/data/v1/get?callback=jQuery112305522640988534238_1680571452074&reportName=RPT_VALUEANALYSIS_DET&columns=ALL"eColumns=&pageNumber=1&pageSize=5000&sortColumns=TRADE_DATE&sortTypes=1&source=WEB&client=WEB&filter=(SECURITY_CODE=%22002594%22)&_=1680571452075'
headers={'referer':r'https://data.eastmoney.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.62'}
rsp = requests.get(url=url,headers=headers)
rsp_sub = re.sub('^jQuery112305522640988534238_1680571452074\(', '', rsp.text)
rsp_sub_2 = re.sub('\);', '', rsp_sub)
rsp_json = json.loads(rsp_sub_2)
print(rsp_json)
三、步骤
1.引入库
import requests
import jsonpath
import json
import re
import pandas as pd
2.爬取数据
这里选取2022年10月10日-2023年2月29日的数据,对数据日期、股价、当日涨跌幅(%)、总市值四项数据进行抓取,并整理为DataFrame格式,代码如下(示例):
list = []
df = pd.DataFrame(list).T
for i in jsonpath.jsonpath(rsp_json,'$..data')[0]:
TRADE_DATE = jsonpath.jsonpath(i,'$.TRADE_DATE')
if TRADE_DATE[0] < '2022-10-10' or TRADE_DATE[0] > '2023-02-29':
pass
else:
list.append(TRADE_DATE[0][:-9])
CLOSE_PRICE = jsonpath.jsonpath(i,"$.CLOSE_PRICE")
list.append(CLOSE_PRICE[0])
CHANGE_RATE = jsonpath.jsonpath(i,'$.CHANGE_RATE')
list.append(CHANGE_RATE[0])
TOTAL_MARKET_CAP = jsonpath.jsonpath(i,'$.TOTAL_MARKET_CAP')
list.append(TOTAL_MARKET_CAP[0])
df1 = pd.DataFrame(list).T
df = pd.concat([df1,df])
list = []
3.数据存储
将数据集反转,并添加列索引,重置行索引,之后进行保存。
df = df.iloc[::-1]
df.columns = ['数据日期','股价','当日涨跌幅(%)','总市值']
df = df.reset_index(drop = True)
print(df)
df.to_excel('.\股价数据.xlsx',index = False)
4.结果
数据日期 股价 当日涨跌幅(%) 总市值
0 2022-10-10 251.2 -0.321416 731279085176
1 2022-10-11 255.01 1.51672 7.42371e+11
2 2022-10-12 262.34 2.8744 7.63709e+11
3 2022-10-13 258.18 -1.58573 7.51599e+11
4 2022-10-14 264.54 2.4634 7.70114e+11
.. ... ... ... ...
91 2023-02-22 270.42 -1.57598 7.87231e+11
92 2023-02-23 270.44 0.0073959 7.87289e+11
93 2023-02-24 267.58 -1.05754 7.78964e+11
94 2023-02-27 259.81 -2.9038 7.56344e+11
95 2023-02-28 260.8 0.381048 759226056584
4.代码汇总
import requests
import jsonpath
import json
import re
import pandas as pd
url = 'https://datacenter-web.eastmoney.com/api/data/v1/get?callback=jQuery112305522640988534238_1680571452074&reportName=RPT_VALUEANALYSIS_DET&columns=ALL"eColumns=&pageNumber=1&pageSize=5000&sortColumns=TRADE_DATE&sortTypes=1&source=WEB&client=WEB&filter=(SECURITY_CODE=%22002594%22)&_=1680571452075'
headers={'referer':r'https://data.eastmoney.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.62'}
rsp = requests.get(url=url,headers=headers)
rsp_sub = re.sub('^jQuery112305522640988534238_1680571452074\(', '', rsp.text)
rsp_sub_2 = re.sub('\);', '', rsp_sub)
rsp_json = json.loads(rsp_sub_2)
list = []
df = pd.DataFrame(list).T
for i in jsonpath.jsonpath(rsp_json,'$..data')[0]:
TRADE_DATE = jsonpath.jsonpath(i,'$.TRADE_DATE')
if TRADE_DATE[0] < '2022-10-10' or TRADE_DATE[0] > '2023-02-29':
pass
else:
list.append(TRADE_DATE[0][:-9])
CLOSE_PRICE = jsonpath.jsonpath(i,"$.CLOSE_PRICE")
list.append(CLOSE_PRICE[0])
CHANGE_RATE = jsonpath.jsonpath(i,'$.CHANGE_RATE')
list.append(CHANGE_RATE[0])
TOTAL_MARKET_CAP = jsonpath.jsonpath(i,'$.TOTAL_MARKET_CAP')
list.append(TOTAL_MARKET_CAP[0])
df1 = pd.DataFrame(list).T
df = pd.concat([df1,df])
list = []
df = df.iloc[::-1]
df.columns = ['数据日期','股价','当日涨跌幅(%)','总市值']
df = df.reset_index(drop = True)
print(df)
# df.to_excel('.\股价数据.xlsx',index = False)
简单分析
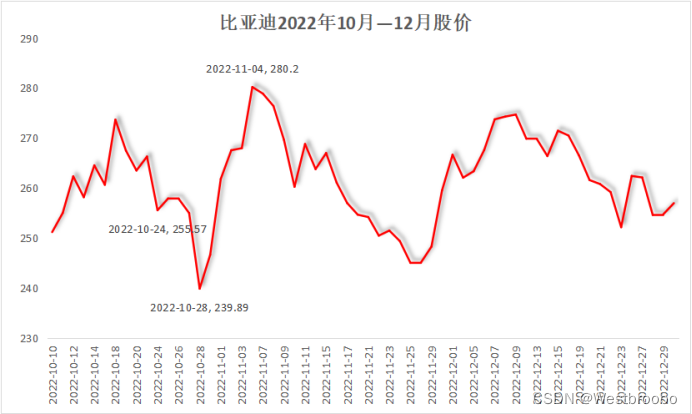
股价方面,特斯拉宣布降价后的几天,对比亚迪的股价短时间造成了一定的冲击,10月28日一度达到2022年末两个月的最低点,但之后又开始回暖,次月4号达到了最高值,280.2元,11月份持续下跌,12月回升后趋于平稳,短期内有一定的明显变化。
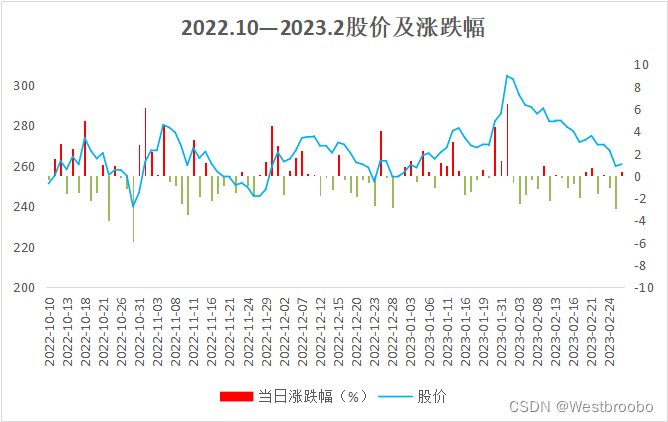
从整体上看,10月份到11月初经历了触底反弹,11月整体下跌,12月回升后稳定维持之前的水平,可以说是迅速做出了调整,知道2023年1月底到2月初可能由于某些原因又创了一次股价新高,之后回调,可以看到始终在一定的水平上涨跌,时间越长越越趋于稳定,若从股价上可以说,此次降价对比亚迪的股价没有造成太大影响。

















 1282
1282

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









