






总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
DeTeCtive: Detecting AI-generated Text via Multi-Level Contrastive Learning
https://arxiv.org/abs/2410.20964
https://www.doubao.com/chat/1663000860263938
文章目录
摘要
目前,检测人工智能生成文本的技术大多局限于手工制作特征和有监督的二元分类模式。打个比方,就像在一堆水果里挑出苹果,以往的方法是人工去观察水果的颜色、形状等特征(手工制作特征),然后按照是不是苹果把水果分成两类(二元分类)。但这种方式存在问题,它会导致性能瓶颈,就好像用这种挑水果的方法挑得又慢又不准确,而且通用性也不好,遇到一些新品种的苹果(新出现的大语言模型生成的文本或者分布外的数据)就没办法准确挑出来了。
在这篇论文里,作者重新审视了人工智能生成文本的检测任务。作者认为,完成这个任务的关键就像是要分辨出不同人画画的风格一样,要去区分不同 “作者” 的写作风格,而不是简单地把文本分为人类写的和人工智能生成的。为了实现这个目标,论文提出了DeTeCtive,这是一个多任务辅助、多层次对比学习的框架。比如说,这个框架就像是一个能学习不同人画画风格特点的系统,它能帮助模型学习不同的写作风格,并且结合了密集信息检索流程来检测人工智能生成的文本。
这个方法可以和多种文本编码器一起使用,就像一把钥匙能开多把锁一样。大量实验表明,DeTeCtive能提高各种文本编码器在检测人工智能生成文本方面的能力。在多个基准测试中,它都取得了最先进的成果。举个例子,在一些测试数据上,它的表现比其他方法都要好。值得注意的是,在分布外零样本评估中,也就是遇到模型训练时没见过的数据时,DeTeCtive比现有的方法优势很大。而且,这个方法还有一个叫做训练自由增量适应(TFIA)的能力。比如,当遇到一批新的没见过的数据时,不用重新训练模型,只要把这些新数据的特征加到原来的数据库里,模型就能更好地检测这些新数据,这进一步提高了它在分布外检测场景中的效果。最后,论文作者会开源代码和模型,希望能为人工智能生成文本检测领域带来新的思路,保证大语言模型的安全应用,提高合规性。
1 引言
最近,大语言模型领域发展得特别快,就像火箭升空一样。它给人们的工作和生活带来了很多便利,比如写文章、回答问题都能借助它快速完成。但是,人工智能生成的文本被广泛使用也带来了问题,威胁到了全球信息安全。比如说,有些虚假信息可能通过人工智能生成并传播开来,就像谣言一样,误导人们,甚至可能引发一些不良行为。所以,检测人工智能生成的文本变得非常重要。
随着大语言模型的不断进步,检测人工智能生成文本这个任务也变得越来越难。早期的一些方法,像水印法和统计法,就好比是给水果贴上标签(水印)或者通过一些简单的统计数据(统计法)来分辨水果是不是苹果,但这些方法依赖人工制作的形式,就像手工贴标签很麻烦一样,它们遇到了性能瓶颈。而且,一旦出现新的大语言模型,这些方法就很难快速适应,就像遇到新品种水果时,原来的标签和统计方法就不管用了。相比之下,最近基于训练的方法有了明显的性能提升,就像用更先进的机器来挑水果,效率和准确性都提高了。但是,这些方法也有问题,它们需要精确匹配的训练数据,而且在遇到分布外的数据时,泛化能力不好。这就好比机器只能识别训练过的那几种水果,遇到没训练过的新品种就不行了。
在这篇论文中,为了克服这些挑战,作者重新思考了人工智能生成文本的检测问题,并且从一个全新的角度来解决它。不同的作者有不同的写作风格,就像不同的画家画画风格不一样,有的喜欢用鲜艳的颜色,有的喜欢细腻的笔触。大语言模型也可以看作是一个特殊的 “作者”,它生成的文本也有自己独特的风格。所以,论文作者提出把人工智能生成文本的检测任务,看作是在一个很大的写作风格特征空间里区分不同风格的任务,而不是简单地进行二元分类。
虽然在这么大的特征空间里区分写作风格听起来比简单的二元分类更难,但作者利用了自然语言处理领域成熟的技术——对比学习。对比学习就像是把不同的水果放在一起比较,找出它们的相同点和不同点,这样就能更好地识别它们。通过对比学习,模型可以获得有区分度的特征表示,从而区分不同的写作风格。
具体来说,论文提出了一个通用框架,把新的多层次对比学习和多任务学习结合起来,专门用于检测人工智能生成的文本。这个框架可以提高各种模型对写作风格的编码能力,像基于BERT和T5的模型都可以用。它能调整不同样本之间的距离,就像调整水果之间的摆放距离,让模型更好地编码不同 “作者” 生成文本的独特特征。在推理的时候,作者提出了一个基于密集信息检索的流程。先把训练数据的特征提取出来存到数据库里,就像把各种水果的特征信息记录下来。然后,对于要检测的文本,就计算它和数据库里特征的相似度,这就好比是对比新水果和记录的水果特征有多像。最后,用K近邻算法进行分类预测,判断这个文本是人类写的还是人工智能生成的。
通过在多个常用数据集上进行实验,作者发现这个方法和各种文本编码器结合使用时,比它们的零样本基线性能都有提升,超越了目前现有的方法,在每个数据集上都建立了新的最优基准。而且,当遇到训练时没见过的数据时,这个方法也表现出了很好的泛化能力。在Deepfake数据集的 “未见模型” 和 “未见领域” 测试集中,平均召回率(AvgRec)指标分别比现有的最优方法高出5.58% 和14.20% 。
此外,论文还介绍了训练自由增量适应(TFIA),这是一种新的、高效的提高分布外检测泛化能力的方法。当遇到一批新的没见过的数据时,以前的方法要么重新训练模型,要么在新数据上微调模型,这就像重新教机器认识新水果或者稍微调整机器的识别方式,都比较麻烦。但在DeTeCtive框架下,不需要再训练,只要用之前训练好的模型对新数据进行编码,然后把这些新数据加到现有的数据库里,形成一个更大的数据库就行。在上述分布外检测场景中,TFIA还能进一步提高模型性能,在 “未见模型” 测试集中,AvgRec分数又提高了0.84% ,在 “未见领域” 测试集中提高了7.03% 。
通过在多个数据集和模型上进行大量实验,充分证明了这个方法比以前的方法更好,在分布内和分布外检测场景中都取得了最先进的性能。总的来说,这篇论文的贡献有很多:
- 提出了一个全新的端到端框架,设计了多任务辅助、多层次对比损失来学习区分不同写作风格的细粒度特征;
- 提出了TFIA,利用少量分布外数据就能提高模型对新领域的适应性,不用再训练,在实际应用中有很大优势;在多个数据集上取得了最先进的性能,大幅超越现有方法;
- 还通过一系列消融实验验证了每个组件的有效性,提供了可视化结果进行进一步分析,对TFIA也进行了详细实验和实证分析。
2 相关工作
在这部分内容中,论文介绍了两个方面的相关工作,分别是人工智能生成文本的检测方法,以及自然语言处理中的对比学习。
在人工智能生成文本检测方面,现有方法大致可分为三类:
- 水印法:这类方法是在人工智能生成的内容中嵌入特定标记,以便后续验证其来源,就像是给商品贴上防伪标签一样。它又包含基于规则和基于深度学习的方法。例如,软水印方法是在推理时对词汇进行分组,并优先解码下一个标记。还有研究提出通过在模型中嵌入由特殊输入触发的后门来添加水印。UPV则是一种不可伪造且可公开验证的算法,能防止伪造和未经授权的检测。比如在一些需要验证文本来源的场景中,水印法可以发挥作用,确保文本的真实性和来源可追溯性。
- 统计法:该方法通过应用统计指标,如熵,作为区分人工智能生成文本和人类撰写文本的阈值。像HowkGPT通过比较人类撰写文本和ChatGPT生成文本的困惑度得分来确定文本来源。DetectGPT利用大语言模型概率密度的结构属性进行零样本检测,即不需要额外训练就能判断文本是否由人工智能生成。DetectLLM则采用归一化扰动对数秩进行识别,对扰动的敏感度较低。比如在判断一篇文章是人工写的还是AI生成的时候,可以通过分析文本的统计特征,像词汇的使用频率、句子结构的复杂度等,来进行判断。
- 监督学习法:GPT-Sentinel将二元分类器集成到RoBERTa和T5模型中,并在特定数据集上进行直接训练,就像是让模型学习大量已知的人类和人工智能生成文本样本,从而具备区分能力。RADAR采用对抗学习方法,不断迭代改进检测器和生成器(两者均为大语言模型),在检测原始和改写后的人工智能生成文本方面表现出色。有些研究利用对比学习学习人类撰写文本的风格表示,并以少样本方式识别不同来源。基于SCL框架的CoCo,将连贯性信息融入文本表示中,提高了在资源受限条件下检测人工智能生成文本的能力。例如在实际应用中,这些方法可以对大量文本进行分类,判断其是否为人工智能生成。
在自然语言处理的对比学习方面,MoCo和SimCLR在计算机视觉领域通过对比学习取得的成功,促使研究人员探索其在自然语言处理领域的潜力,进而产生了多种通过对比学习增强文本编码能力的策略。例如,IS-BERT使用DIM框架学习文本表示;ArcCon损失被提出用于进一步增强模型的语义区分能力;MixCSE引入一种无监督文本表示学习方法,采用混合负样本策略提升模型区分复杂语义的能力;VaSCL通过定义实例级对比损失并集成高斯噪声来获取硬负样本,以无监督方式有效提升模型性能;DCLR通过引入基于噪声的负样本和虚拟对抗训练,解决无监督句子表示学习中负样本带来的各向异性问题,改善表示空间的均匀性;SimCSE提出预测输入句子本身,以无监督方式利用标准随机失活作为噪声,并引入对正样本和硬负样本对进行分类的方法,改进句子表示。这些方法就像是给自然语言处理模型提供了更强大的 “感知” 工具,让模型能够更好地理解文本之间的差异和相似性。
3 方法
在这部分内容中,论文详细介绍了用于检测人工智能生成文本的方法。具体包含对方法的定义、框架概述,多任务辅助多层次对比学习的设计,以及一种处理分布外(OOD)数据的策略——训练自由增量适应(TFIA)。这部分内容是论文核心方法的阐述,为后续理解实验和结果奠定基础。
3.1 框架概述
本文聚焦于人工智能生成文本的检测任务,即判断一段给定的文本是由人类书写还是由人工智能生成的。以往的方法,有的是人工去设计一些特征来区分,比如观察文本的用词特点、句子结构等;还有的是采用神经网络来学习人类和人工智能生成文本之间的差异特征,但不管哪种方法,最终都把这个任务简化成了一个简单的二元分类问题,也就是非此即彼的判断。
然而,这种做法忽略了一个重要因素。就像不同的作家写作风格不同一样,不同的大语言模型(LLM)由于其模型架构、训练数据和训练策略不一样,生成的文本也会有不同的风格特点。比如,ChatGPT和LLaMA生成的文本在语气、用词偏好等方面可能就有差异。所以,不能简单地把所有大语言模型生成的文本都归为一类。
为了解决这个问题,论文提出了DeTeCtive框架,这个框架可以和多种文本编码器配合使用。它结合了一种新的多层次对比学习和多任务学习方法,能够在特征空间里调整不同样本之间的距离,让模型学习到更独特的特征。
在推理阶段,论文采用了密集信息检索流程。具体来说,就好比有一个装满各种已知文本特征的 “数据库仓库”。首先,从训练数据集中提取文本特征并存储到这个 “仓库” 里。然后,当遇到需要检测的文本(查询文本)时,就像在仓库里找和它最像的特征。通过计算查询文本编码后的特征与数据库中每个特征向量的相似度,来评估它们写作风格的相似程度。最后,使用K近邻(KNN)算法进行分类预测,判断查询文本是人类写的还是人工智能生成的。
3.2 多任务辅助多层次对比学习
优化目标及合理性
正如3.1节中所讨论的,不同作者具有独特的写作风格,这些风格共同构成了一个庞大的特征空间。可以把每个大语言模型(LLM)看作是一个独立的 “作者”,比如ChatGPT、LLaMA等都是不同的 “作者”。因此,检测人工智能生成文本就变成了在这个特征空间里区分不同写作风格的任务。这就好比我们要在一个满是各种画作的画廊中,分辨出不同画家的绘画风格一样,需要敏锐地察觉不同风格之间的相似点和差异点。
具体来说,同一家公司开发的大语言模型,由于它们在模型设计、训练策略以及使用的数据集等方面有很多相似之处,所以生成的文本往往会有相似的偏好和固有倾向。就像同一个绘画流派的画家,他们的作品可能都有一些共同的特点,比如都喜欢用某种特定的色彩或者笔触。常见的技术,比如统一的自回归建模方法,也会在不同公司的模型之间引入一定程度的共性,尽管这种共性可能没有那么明显。所以,大语言模型之间的多层次差异关系,就像是家族成员之间的亲属关系,有的关系紧密,有的则相对疏远。
论文希望通过文本编码器捕捉到这些 “亲属关系”,让编码器能够区分出不同层次的相似点和差异点。用数学公式来表示就是
E
x
∼
P
i
,
y
∼
P
j
[
S
i
m
(
Φ
(
x
)
,
Φ
(
y
)
)
]
>
E
x
∼
P
i
,
y
∼
P
j
+
1
[
S
i
m
(
Φ
(
x
)
,
Φ
(
y
)
)
]
\mathbb{E}_{x \sim P_{i}, y \sim P_{j}}[Sim(\Phi(x), \Phi(y))]>\mathbb{E}_{x \sim P_{i}, y \sim P_{j+1}}[Sim(\Phi(x), \Phi(y))]
Ex∼Pi,y∼Pj[Sim(Φ(x),Φ(y))]>Ex∼Pi,y∼Pj+1[Sim(Φ(x),Φ(y))]
这里
S
i
m
Sim
Sim表示相似度测量,
Φ
\Phi
Φ是编码函数,
P
1
P_1
P1到
P
4
P_4
P4代表不同的文本分布。
P
1
P_1
P1可以是某个特定大语言模型生成文本的分布,比如ChatGPT生成文本的特点集合;
P
2
P_2
P2是同一家公司开发的大语言模型生成文本的分布;
P
3
P_3
P3是所有大语言模型生成文本的分布;
P
4
P_4
P4是人类书写文本的分布。这个公式的意思是,希望模型编码后的特征能够反映出,分布越相近的文本,它们之间的相似度应该越高。通过这种方式,能让模型更好地识别出不同来源文本在特征空间中的关系,从而更细致地分辨出各种写作风格。
多层次对比学习
根据上述相似度约束条件,在处理包含
N
N
N个样本的数据批次时,对于第
i
i
i个样本
T
i
T_i
Ti,会给它一个标签
x
i
x_i
xi 。如果文本是由大语言模型生成的,就标记为
x
i
=
0
x_i = 0
xi=0 ,如果是人类写的,就标记为
x
i
=
1
x_i = 1
xi=1 。对于大语言模型生成的文本(
x
i
=
0
x_i = 0
xi=0 ),还会进一步标记它所属的模型系列
y
i
y_i
yi和具体模型
z
i
z_i
zi 。比如,某个样本是由ChatGPT生成的,那么
x
i
=
0
x_i = 0
xi=0 ,
y
i
y_i
yi表示它属于OpenAI公司的模型系列,
z
i
z_i
zi表示具体是ChatGPT模型。
然后,通过编码函数 Φ ( ⋅ ) \Phi(·) Φ(⋅)把文本映射到一个 d d d维的特征空间。对于任意两个样本 T i T_i Ti和 T j T_j Tj ,计算它们编码特征之间的余弦相似度,用 S ( i , j ) S(i, j) S(i,j)表示。
对于人类写的文本
T
i
T_i
Ti(
x
i
=
1
x_i = 1
xi=1 ),它和其他人类写作文本编码的相似度应该大于和人工智能生成文本编码的相似度。比如说,两篇人类写的诗歌,它们在词汇运用、情感表达等方面可能有相似之处,所以它们编码后的相似度会比较高;而人类写的诗歌和大语言模型生成的诗歌,由于写作方式和特点不同,编码后的相似度就会较低,用公式表示就是
S
(
i
,
j
)
>
S
(
i
,
k
)
,
∀
x
j
=
1
,
x
k
=
0
S(i, j) > S(i, k), \forall x_j = 1, x_k = 0
S(i,j)>S(i,k),∀xj=1,xk=0
同样,对于大语言模型生成的文本
T
i
T_i
Ti(
x
i
=
0
x_i = 0
xi=0 ),不同大语言模型之间也存在多层次的相似和差异关系。例如,同一家公司开发的不同版本大语言模型,它们生成的文本相似度会相对较高;而不同公司开发的大语言模型,生成文本的相似度就会低一些。用公式表示为
S
(
i
,
j
)
>
S
(
i
,
l
)
>
S
(
i
,
m
)
>
S
(
i
,
n
)
,
∀
z
i
=
z
j
,
z
i
≠
z
l
,
y
i
=
y
l
,
y
i
≠
y
m
,
x
i
=
x
m
,
x
i
≠
x
n
S(i, j) > S(i, l) > S(i, m) > S(i, n), \forall z_i = z_j, z_i \neq z_l, y_i = y_l, y_i \neq y_m, x_i = x_m, x_i \neq x_n
S(i,j)>S(i,l)>S(i,m)>S(i,n),∀zi=zj,zi=zl,yi=yl,yi=ym,xi=xm,xi=xn
为了实现这些优化目标,论文提出了一种分层解决这些约束条件的方法。对于不同的约束条件,设置相应的条件来满足它们,最终得到一组不等式。
为了解决这些约束,论文基于SimCLR框架,提出了一种定义正负样本对的方法,并由此得出对比学习损失。这里的正样本不是单个实例,而是满足一定条件的一组样本。计算正样本相似度时,是从当前样本的角度考虑与整个正样本集相关的平均值。例如,对于某个大语言模型生成的文本样本,它的正样本可能是同一家公司其他大语言模型生成的文本集合。通过这种方式计算对比学习损失,不同的约束条件对应不同的正负样本集,从而计算出多层次对比损失。总的多层次对比损失是由不同的部分组成,通过调整相应的系数来平衡不同层次关系的权重。
通过这种精心设计的多层次对比学习,能够让模型学习到不同来源文本的精细特征,就像让模型拥有了更敏锐的 “感知力”,能够更好地分辨出各种不同的写作风格,从而提高检测人工智能生成文本的准确性和通用性。
多任务辅助学习
多任务学习能够让模型在不同任务之间共享有用信息,同时在线学习多个任务。这就好比一个学生同时学习数学和物理,在学习过程中,数学中的逻辑思维方法可以帮助理解物理问题,物理中的实验现象也能加深对数学公式的理解。多任务学习能促使模型学习到更通用、更有区分度的特征,进而增强模型的泛化能力。
因此,在前面提到的对比学习框架基础上,论文在编码器的输出层集成了一个多层感知器(MLP)分类器。这个分类器的作用是进行二元分类,判断给定的查询文本是由人类还是大语言模型生成的。为了优化这个分类器,引入了交叉熵损失
L
c
e
L_{ce}
Lce 。总的多任务辅助多层次对比损失就是多层次对比损失
L
m
c
l
L_{mcl}
Lmcl和交叉熵损失
L
c
e
L_{ce}
Lce相加。通过这种多任务辅助学习的方式,进一步提升模型检测人工智能生成文本的能力。
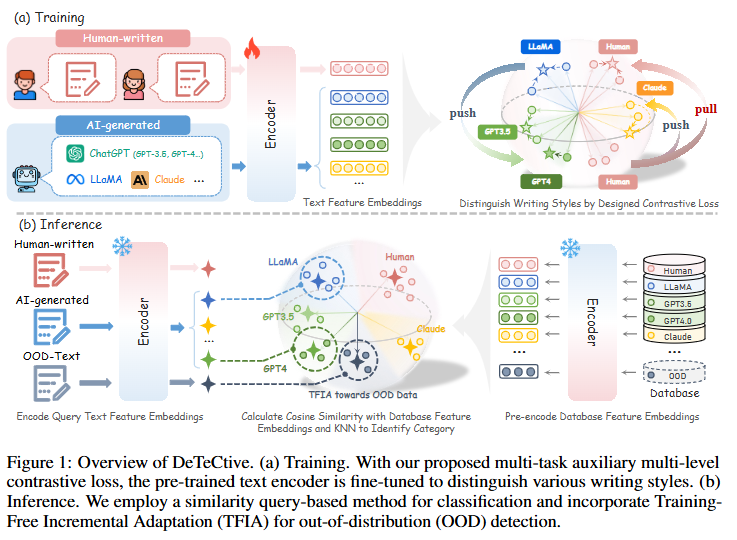
图1:DeTeCtive概述
图1展示了DeTeCtive框架在训练和推理阶段的工作流程。
在训练阶段,利用论文提出的多任务辅助多层次对比损失,对预训练的文本编码器进行微调。可以把预训练的文本编码器想象成一个刚入职的员工,虽然有一定的基础能力,但对于检测人工智能生成文本这项工作还不够专业。而多任务辅助多层次对比损失就像是一套精心设计的培训方案,通过这套方案对这个 “新员工” 进行专项训练,能让它更好地区分各种不同的写作风格。
比如在现实生活中,不同的人说话和写作的风格都不一样,有人喜欢用华丽的辞藻,有人说话简洁明了;同样,不同的大语言模型生成文本的风格也各有特点。ChatGPT生成的文本可能在语气上更加自然流畅,像是和人亲切交流;而其他大语言模型,比如LLaMA、Claude等,它们生成的文本在词汇选择、语句结构等方面可能和ChatGPT存在差异,甚至不同版本的GPT(如GPT - 3.5、GPT - 4)之间也有细微的风格差别。这个训练过程就是让 “文本分析助手” 能够敏锐地察觉到这些差异,就像专业的品酒师能分辨出不同产地、不同品种葡萄酒的独特风味一样。
在推理阶段,采用基于相似度查询的方法进行分类。当有一个新的查询文本时,先对它进行编码得到特征,然后在之前建好的特征数据库中,查找和它特征相似度高的文本。这就如同在一个巨大的图书馆里,每本书都代表一个文本特征样本,我们需要找到和新文本最相似的那几本书。这里的特征数据库就像是这个图书馆,而编码后的新文本特征就是我们进入图书馆寻找相似样本的 “线索” 。最后通过K近邻算法确定新文本是人类写的还是人工智能生成的,就好像根据找到的相似 “书籍” 来判断新文本的 “身份” 。
此外,在处理分布外数据时,还融入了训练自由增量适应(TFIA)策略。分布外数据就像是图书馆里突然出现的一些特殊书籍,这些书籍的类型在之前的馆藏中从未出现过。按照传统方法,我们可能需要重新整理整个图书馆的分类系统(重新训练模型)才能处理这些新书籍,但这样做既麻烦又耗时。而TFIA策略就像是一个灵活的图书管理员,当遇到这些特殊书籍(分布外数据)时,它不需要重新规划整个图书馆的分类,只需要给这些新书籍进行编号(编码),然后把它们加入到现有的馆藏(现有数据库)中。这样一来,当再次遇到类似的特殊书籍时,就能更快速、准确地判断它们的类别,从而增强了模型在处理分布外数据时的性能。
3.3 训练自由增量适应(TFIA)
随着大语言模型(LLMs)的快速发展以及应用的不断增多,新的模型不断涌现,涉及的领域也越来越广泛。现有的人工智能生成文本检测方法,通常把这个任务当作简单的二元分类问题(即判断文本是人类写的还是AI生成的)。但当遇到新模型或者新领域产生的分布外(OOD)数据时,这些方法很难很好地应对。
比如说,之前的检测模型只在新闻文本和小说文本上进行过训练,当遇到医学领域或者科技领域的文本(这些就是分布外数据),或者新出现的大语言模型生成的文本时,模型的检测效果就会变差。通常情况下,面对这些分布外数据,现有的方法往往需要重新训练模型,这在实际应用中既耗时又耗力。
为了解决这个挑战,论文在现有的框架基础上,提出了一种新的解决方案——训练自由增量适应(TFIA)。这个方法可以让模型在不需要进一步训练的情况下,就能适应新的领域或者新出现的大语言模型。具体来说,当遇到训练集中没有涵盖的分布外数据时,只需要用微调后的文本编码器对这些数据进行编码,然后把编码后的特征加入到现有的特征数据库中。
例如,原来的特征数据库里存的是常见的新闻和小说文本的特征,现在遇到了一些医学论文(分布外数据),就把这些医学论文编码后的特征添加到数据库里。在推理的时候,用扩展后的特征数据库代替原来的数据库,这样模型在处理分布外数据时的性能就会得到提升。TFIA能够增强DeTeCtive框架识别不同来源文本的能力,利用模型的泛化能力,使DeTeCtive框架无需重新训练就能适应分布外数据。论文通过一系列实验验证了TFIA的有效性。
4 实验
这部分主要介绍了为验证所提出方法而进行的实验内容,包括使用的数据集、评估指标、基线方法以及实施细节,还展示了主要实验结果、其他应用,以及进行了消融研究和对训练自由增量适应(TFIA)的分析。
4.1 实验设置
- 数据集:论文使用了三个具有挑战性且被广泛应用的数据集来评估提出的方法。
- Deepfake数据集:包含由27个不同大语言模型生成的文本,以及来自10个领域多个网站的人类撰写的内容,有332K条训练数据和57K条测试数据。它涵盖了六种不同的测试场景,从跨领域到跨分布检测等各种情况。比如,在这个数据集中,可能既有新闻领域的文本,也有文学领域的文本,还有不同大语言模型生成的对应领域的文本,能全面测试模型在不同情况下的检测能力。
- M4数据集:这是一个多领域、多模型、多语言的数据集,包含来自8个大语言模型、6个领域和9种语言的数据。在测试数据中,还有经过OUTFOX改写的机器文本,这使得任务更加复杂。论文在单语言和多语言场景下都进行了实验,单语言场景有120K训练数据和34K测试数据,多语言场景有157K训练数据和42K测试数据。例如,在多语言场景中,可能会有英语、中文、法语等不同语言的文本,以及不同大语言模型生成的这些语言的文本,能测试模型在多语言环境下对人工智能生成文本的检测效果。
- TuringBench数据集:主要从新闻标题和内容中收集人类撰写的文本,大多与政治相关。它结合了来自19个大语言模型在单一领域的数据,形成了一个有112K条训练数据和37K条测试数据的数据集。
- 评估指标:和现有研究一致,论文使用平均召回率(AvgRec)和F1分数作为主要评估指标。平均召回率是人类撰写文本召回率(HumanRec)和人工智能生成文本召回率(MachineRec)的平均值。在数据不平衡的情况下,简单的准确率不能很好地反映模型的性能,而平均召回率能更全面地评估模型。F1分数综合考虑了模型的精确率和召回率,通过计算两者的调和平均数来评估模型的整体性能。这两个指标结合起来,可以更全面地评估模型检测人工智能生成文本的有效性。
- 基线方法:在评估论文提出的方法与各种文本编码器的兼容性实验中,以这些预训练文本编码器在Deepfake数据集的跨领域和跨模型子集上的零样本结果作为基线。然后将论文方法微调后的结果与基线进行比较。在后续实验中,为了进行比较分析,还使用了基于预训练SimCSE - RoBERTa模型作为文本编码器,与几种基于RoBERTa的方法在所有三个数据集上进行比较,这些方法包括TS - centroid、T5 - Sentinel和SCL 。此外,在Deepfake数据集的所有六种场景中,还将比较对象扩展到包括基于手工特征的FastText和GLTR,以及基于统计方法的DetectGPT 。
- 实施细节:在论文方法的所有实验中,使用HuggingFace transformers库的接口和预训练模型权重。冻结嵌入层,只训练剩下的模型参数。所有实验都使用带有余弦退火学习率调度的AdamW优化器,峰值学习率设置为2e - 05 ,预热2000步,权重衰减设置为1e - 04 。最大输入文本长度为512 ,在32个GPU(NVIDIA V100)上训练50个epochs ,批量大小为32 。在推理时,使用Faisce库提供的高效K近邻(KNN)算法进行分类。对于所有比较实验,都使用开源代码和默认设置进行训练、测试,然后报告结果。
4.2 主要结果
论文从三个方面展示了主要实验结果,验证所提出方法在不同方面的性能。
- 兼容性验证:论文首先使用提出的方法,在Deepfake数据集的跨领域和跨模型子集上,对多个预训练的文本编码器进行微调,目的是验证该方法具有广泛的兼容性。从表6(文中未展示)的结果来看,所有模型相对于它们的基线都有提升。这就好比给不同类型的汽车都换上同一款性能良好的发动机,每辆车的动力都得到了增强,这证明了该方法在人工智能生成文本检测中,对于不同的文本编码器都是有效的。在这些模型中,SimCSE - RoBERTa模型在参数相对较少的情况下,取得了第二好的性能。所以,论文选择这个模型作为后续所有实验的文本编码器。
- 性能对比验证:为了验证论文提出的方法与现有方法相比的性能,以及确定其稳健性,论文在三个常用数据集上进行了实验,包括M4数据集(分为单语言和多语言版本)、TuringBench数据集,以及Deepfake数据集中最大且最具挑战性的跨领域和跨模型子集。实验结果如表1所示。以平均召回率(AvgRec)指标为例,在M4单语言场景中,论文提出的方法DeTeCtive比第二好的方法高出6.52% ;在M4多语言场景中,高出7.15% 。尽管较早发布的TuringBench数据集难度相对较低,所有对比方法在该数据集上都表现良好,但DeTeCtive模型仍然比第二好的方法高出0.15% 。此外,在Deepfake的跨领域和跨模型子集中,DeTeCtive方法比排名第二的方法高出2.66% 。这些实验结果表明,论文提出的方法在多个数据集上都表现出色,说明所提出的框架对于不同的数据分布和场景具有很强的适应性。
- 领域适应和分布外检测能力验证:为了验证该方法在领域适应和分布外(OOD)检测方面的能力,论文在Deepfake数据集提出的所有六种场景上进行了实验。这个数据集被严格划分为不同的子集,以确保任何一个场景的测试数据不会被用作其他场景的训练数据。在分布内检测中,对比方法分别在每个特定子集上进行训练,然后取平均值得到最终结果;而DeTeCtive方法只在跨领域和跨模型子集上进行训练。测试时,DeTeCtive方法只使用每个场景的训练数据作为数据库,跳过额外的训练和处理,直接进行推理。表2的第一行展示了对比实验中平均召回率的结果。在分布外检测中,又进一步分为未见模型(Unseen Models)和未见领域(Unseen Domains)两种情况。测试集包含上述两种场景中未出现过的数据。表2的第二行展示了平均召回率结果,DeTeCtive方法在未见模型和未见领域场景中,分别比其他方法高出5.58% 和14.2% 。这表明该方法的泛化性能明显优于现有方法。最后,论文还设计了一组实验,将来自跨领域和跨模型子集训练集中相应的分布外数据纳入数据库以辅助检测。在未见领域场景中,平均召回率有了显著提高,增加了7.03% ;在未见模型场景中,有轻微提升,这可以归因于模型现有的识别相似模型的能力。这也凸显了论文方法中多层次对比学习的有效性,以及训练自由增量适应(TFIA)的作用。关于TFIA的深入分析可以在4.4节中找到。
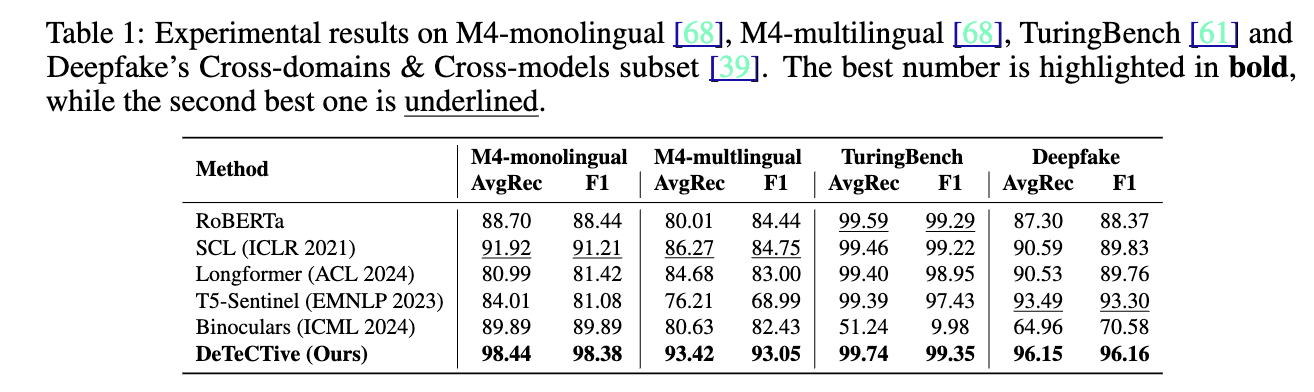
Table 1
该表展示了在M4单语言、M4多语言、TuringBench以及Deepfake的跨领域和跨模型子集这几个数据集上的实验结果。表格对比了包括RoBERTa、SCL(ICLR 2021)、Longformer(ACL 2024)、TS-Sentinel(EMNLP 2023)、Binoculars(ICML 2024)等多种方法,以及论文提出的DeTeCtive方法。每列分别列出了平均召回率(AvgRec)和F1分数两个评估指标。从表中可以清晰地看到,在每个数据集上,DeTeCtive方法的AvgRec和F1分数大多都是最高的(最好的数字用粗体突出显示,第二好的数字加下划线),这直观地表明了DeTeCtive方法在这些数据集上的性能优于其他对比方法。例如,在M4单语言数据集中,DeTeCtive方法的AvgRec达到98.44,F1分数为98.38,明显高于其他方法。

Table 2
该表展示了在Deepfake数据集提出的六种检测场景下的平均召回率(AvgRec)实验结果。分为分布内(In-distribution)和分布外(Out-of-distribution)两种情况。分布内检测场景包括跨领域和跨模型(Cross-domains & Cross-models)、跨领域和特定模型(Cross-domains & Model-specific)、特定领域和特定模型(Domain-specific & Model-specific)。分布外检测场景包括未见模型(Unseen Models)和未见领域(Unseen Domains)。表格对比了Longformer、GLTR、DetectGPT、FastText等方法以及DeTeCtive方法。对于DeTeCtive方法,在分布外检测中给出了两个结果,左边是常规测试结果,右边是结合TFIA后的结果。从表中可以看出,在分布内检测的各个场景中,DeTeCtive方法的AvgRec大多高于其他对比方法;在分布外检测的未见模型和未见领域场景中,DeTeCtive方法的优势更加明显,结合TFIA后性能进一步提升。比如在未见领域场景中,DeTeCtive方法结合TFIA后的AvgRec达到89.63,远超其他方法。
4.3 更多应用
这部分内容主要介绍了论文所提出方法在两个不同应用场景中的实验及结果,展示了该方法在攻击鲁棒性和作者归属检测方面的性能。
- 攻击鲁棒性:为了研究论文提出的方法对改述攻击(paraphrasing attack)的鲁棒性,在OUTFOX数据集上进行了实验。实验分为三种场景:未受攻击(Non - attacked)、DIPPER攻击和OUTFOX攻击,结果展示在表3中。从实验结果可以看出,在这三种设定下,论文提出的DeTeCtive方法都取得了最好的结果。而且在受到攻击后,该方法的性能下降幅度不大,而其他方法的性能则显著下降。比如,在面对DIPPER攻击时,其他一些方法的平均召回率(AvgRec)和F1分数大幅降低,而DeTeCtive方法依然保持较高水平。论文认为,这是因为使用K近邻(KNN)算法进行分类,为该方法提供了一定程度的容错能力。就像在一堆相似的物品中找东西,即使这些物品受到一些小的干扰,KNN算法也能通过比较它们之间的相似性找到目标,不会因为一些小的变化而找不到。所以,某些攻击引起的轻微干扰不会导致显著的特征漂移,从而使该方法在检测中仍然有效。这些实验表明,DeTeCtive方法对改述攻击具有良好的鲁棒性。
- 作者归属检测:为了进一步探究论文提出的方法在作者归属检测任务中的有效性,在TuringBench数据集上进行了全面的实验,并将该方法与各种基线解决方案进行比较。从表4的结果可以看到,在这个任务中,DeTeCtive方法展现出了出色的性能。以精度(Precision)、准确率(Accuracy)、召回率(Recall)和F1分数等指标来衡量,DeTeCtive方法的数值大多是最高的。比如在精度指标上达到了84.04,明显高于其他对比方法。这表明该方法能够在多分类的情境中,有效地学习和应用多层次特征,从而准确地判断文本的作者归属。
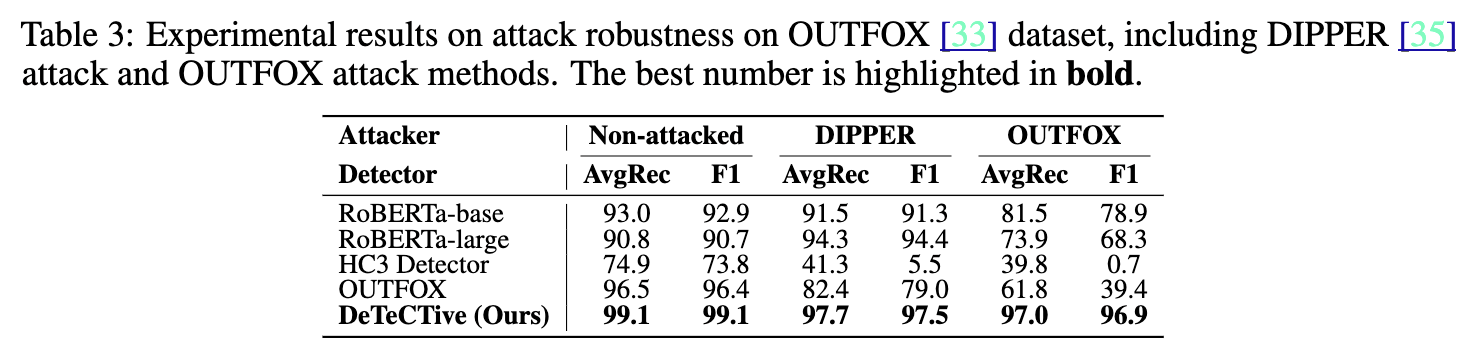
Table 3
该表展示了在OUTFOX数据集上关于攻击鲁棒性的实验结果,包含了DIPPER攻击和OUTFOX攻击两种攻击方法,以及未受攻击的情况。表格对比了RoBERTa-base、RoBERTa-large、HC3 Detector、OUTFOX以及DeTeCtive等多种检测方法。每列分别列出了平均召回率(AvgRec)和F1分数两个评估指标。从表中可以清晰地看到,在未受攻击时,DeTeCtive方法的AvgRec和F1分数都是99.1;在DIPPER攻击场景下,DeTeCtive方法的AvgRec为97.7,F1分数为97.5;在OUTFOX攻击场景下,DeTeCtive方法的AvgRec为97.0,F1分数为96.9。在这三种场景下,DeTeCtive方法的这两个指标数值大多都是最高的(最好的数字用粗体突出显示),直观地体现了该方法在面对不同攻击时的鲁棒性优势。

Table 4
该表展示了在TuringBench数据集上进行作者归属检测的实验结果。表格对比了随机森林(Random Forest)、支持向量机(SVM (3-grams))、WriteprintsRFC、Syntax-CNN、N-gram CNN、N-gram LSTM、OpenAI Detector、BertAA、BERT-Multinomial、RoBERTa-Multinomial以及DeTeCtive等多种方法。每列分别列出了精度(Precision)、准确率(Accuracy)、召回率(Recall)和F1分数四个评估指标。从表中可以看出,DeTeCtive方法在这四个指标上的数值大多领先于其他方法(最好的数字用粗体突出显示),如精度达到84.04,准确率为82.75,召回率是82.59,F1分数为83.05。这表明在作者归属检测任务中,DeTeCtive方法相较于其他对比方法具有更好的性能。
4.4 消融研究与分析
- 消融研究:为了系统地评估论文提出方法中每个组件的效果,进行了一系列消融研究,结果如表5所示。消融研究就像是拆机器零件,看看拆掉某个零件后,机器的性能会受到怎样的影响。实验表明,去掉任何一个损失项,都会导致模型性能下降。特别要注意的是,当把论文提出的多层次对比损失(L_{mcl})(公式9中的)替换为普通的对比损失(L_{pcl})时,性能下降最为明显。这是因为普通对比损失只把人类撰写的文本和人工智能生成的文本当作负样本对,没有考虑到文本之间更细致的内部关系。就好比在区分动物时,只简单地把猫和狗区分开,而不考虑猫科动物或犬科动物内部的不同种类之间的关系。此外,使用基于相似度的K近邻(KNN)分类方案也能提升模型性能。例如在判断新文本是人类写的还是AI生成的时候,KNN算法通过比较新文本与数据库中文本的相似度来进行分类,能让判断更准确 。
- 对训练自由增量适应(TFIA)的分析:进一步探究逐步添加相应的分布外(OOD)样本对模型性能有何影响,结果如图2所示。从图中可以看到,随着越来越多的OOD数据被加入到数据库中,模型的性能持续提升。即使只添加少量的OOD数据,也能显著提高模型性能,在未见领域的场景中这种提升尤为明显。这说明在实际应用中,TFIA能够有效地缓解当前方法对OOD数据适应性不足的问题。比如,之前模型没见过医学领域的文本数据(OOD数据),检测效果不好,加入一些医学领域的文本数据到数据库后,模型对医学领域文本的检测能力就提高了。
- 对学习到的嵌入的可视化:为了进一步验证该方法区分不同写作风格的能力,对Deepfake数据集中跨领域和跨模型子集的测试集文本嵌入应用UMAP进行降维。如图3(a)所示,如果直接使用预训练模型,无法很好地将不同类别的嵌入区分开。但经过用论文提出的方法微调后,UMAP无监督降维能够很好地对不同类别的特征进行聚类,如图3(b)所示。而在图3©和(d)中,使用UMAP有监督降维,模型进一步反映了模型家族之间或单个模型之间的多层次关系。这就像把不同颜色的珠子混在一起,一开始很难区分,但经过处理后,能清晰地把相同颜色的珠子聚在一起,并且还能看出不同颜色珠子之间的层次关系,从而证明了该方法能够有效地区分不同的写作风格。
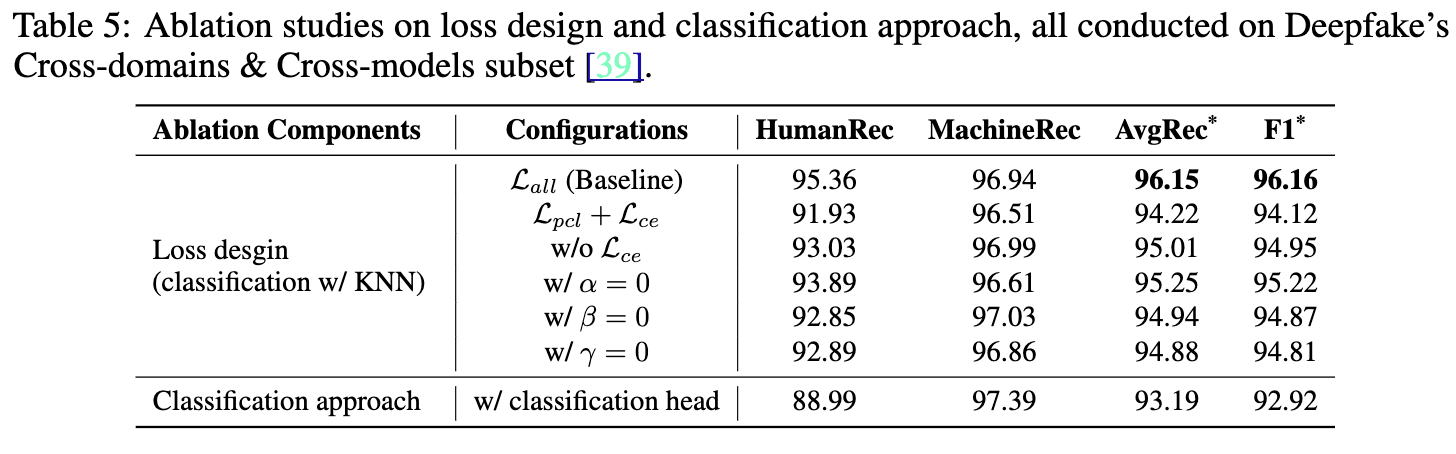
Table 5
该表展示了在Deepfake数据集中的跨领域和跨模型子集上,对损失设计和分类方法进行的消融研究结果。表格分为“消融组件”“配置”“人类撰写文本召回率(HumanRec)”“人工智能生成文本召回率(MachineRec)”“平均召回率(AvgRec*)”“F1分数(F1*)”几列。可以看到,当使用完整的损失函数
L
a
l
l
L_{all}
Lall(基线)时,各项指标表现较好。而当对损失函数进行调整,比如用普通对比损失
L
p
c
l
L_{pcl}
Lpcl 加上交叉熵损失
L
c
e
L_{ce}
Lce,或者去掉(L_{ce}),又或者将一些系数设为0时,模型性能都出现了不同程度的下降。在分类方法方面,与带有分类头的情况相比,使用基于相似度的KNN分类方案能让模型取得更好的性能指标。
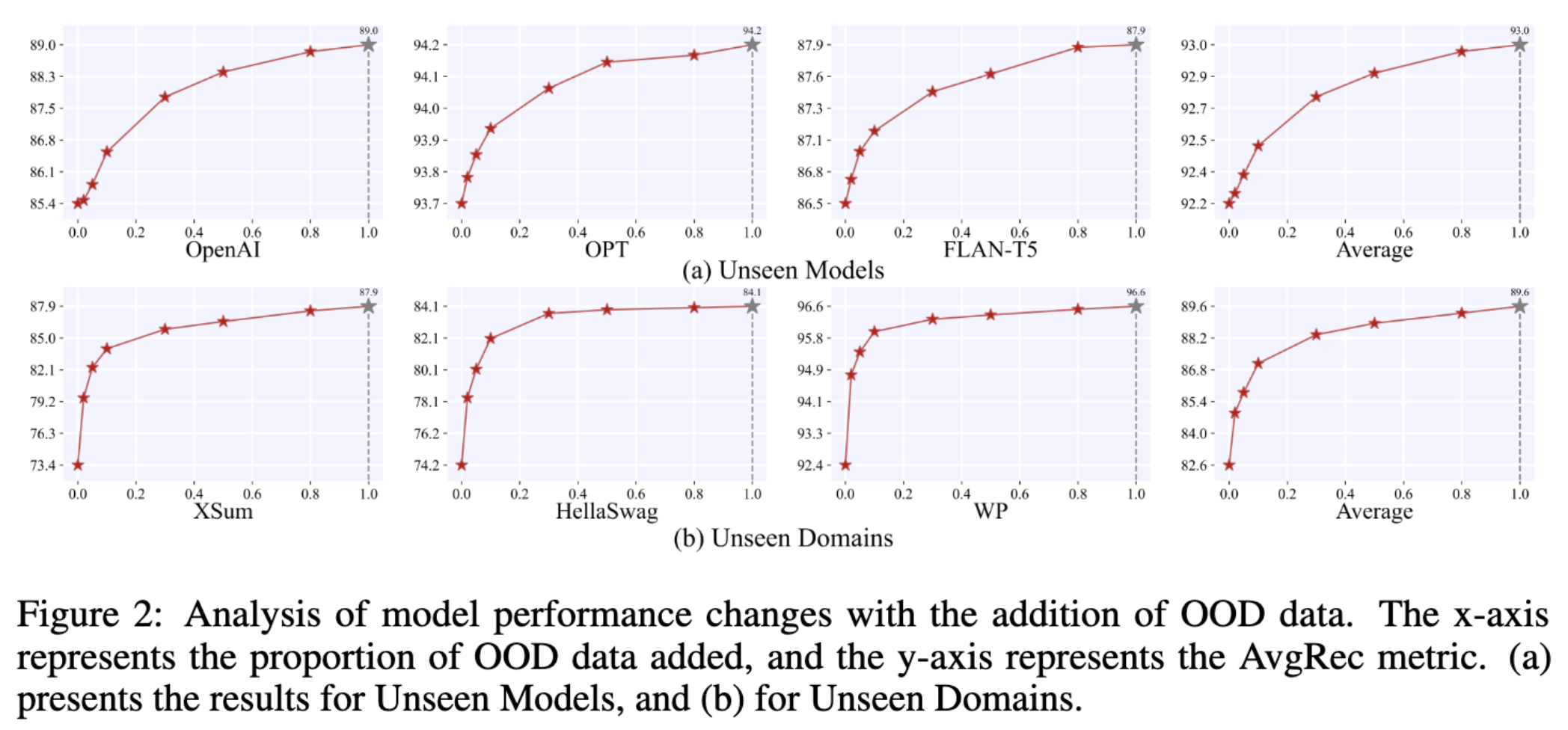
Figure 2
该图分析了随着添加OOD数据,模型性能的变化情况。横坐标表示添加的OOD数据的比例,纵坐标表示平均召回率(AvgRec)指标。图(a)展示了在未见模型场景下的结果,图(b)展示了在未见领域场景下的结果。从图中可以直观地看出,随着OOD数据比例的增加,AvgRec指标不断上升,说明添加OOD数据对模型在未见模型和未见领域场景下的性能提升有积极作用 。

Figure 3
该图是使用UMAP降维的可视化结果,其中UDR代表无监督降维,SDR代表有监督降维。图(a)显示了直接使用预训练模型时,不同类别的文本嵌入无法很好地分开;图(b)展示了用论文方法微调后,无监督降维能够对不同类别的特征进行有效聚类;图( c ) 和(d)则通过有监督降维,进一步体现了模型家族之间或单个模型之间的多层次关系,帮助理解模型对不同写作风格的区分能力。
5 结论
在这篇论文中,提出了DeTeCtive,一种用于检测人工智能生成文本的新方法,该方法基于多任务辅助多层次对比学习框架。通过大量实验,该方法在三个常用的基准数据集上都展现出了领先的性能。同时,通过消融研究验证了方法中每个组件的有效性。此外,还揭示了该方法的训练自由增量适应(TFIA)能力,并对其进行了丰富的实验分析。论文作者希望这项工作能为人工智能生成文本检测任务带来新的见解和发现,推动该领域的进一步发展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











