






总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
AttnGCG: Enhancing Jailbreaking Attacks on LLMs with Attention Manipulation
https://arxiv.org/pdf/2410.09040
https://www.doubao.com/chat/4032875438373122
速览
这篇论文主要研究了基于Transformer的大语言模型(LLMs)在越狱攻击方面的漏洞,提出了一种叫AttnGCG的方法来增强攻击效果。具体内容如下:
- 研究背景:大语言模型在自然语言处理领域取得很大成功,但为了确保安全和符合道德规范,部署的模型通常经过安全训练。即便如此,这些模型还是容易受到对抗攻击,引发有害回应。现有基于优化的攻击方法存在局限性,比如高概率生成有害token不一定意味着越狱成功,而且这些方法大多在模型输出层操作,缺乏对模型内部工作原理的理解。
- AttnGCG方法:基于贪婪坐标梯度(GCG)方法进行改进。通过引入注意力损失,将注意力分数作为额外优化目标,让模型更关注对抗后缀,从而增加越狱成功的概率。具体来说,计算模型输入各部分的注意力分数时,发现对抗后缀的注意力分数与攻击成功率呈正相关。于是,通过优化对抗后缀的注意力分数,引导模型更多地关注对抗后缀,减少对系统提示和目标输入的关注,以此绕过模型的安全协议。
- 实验
- 实验设置:使用AdvBench Harmful Behaviors基准数据集,测试开源和闭源的大语言模型,以GCG为基线,采用两种评估协议衡量攻击成功率(ASR),并使用“common prefix”技术加速攻击过程。
- 直接攻击:AttnGCG在多种模型上均优于GCG基线,平均提高了攻击成功率。同时,AttnGCG能减少“假越狱”情况,通过注意力分数可视化发现,成功越狱时模型注意力会转移到对抗后缀,而失败时会过度关注目标输入。
- 推广到其他攻击方法:将AttnGCG应用到其他攻击方法(如AutoDAN和ICA)中,发现它能进一步增强这些方法的攻击效果,而且合适的初始化提示有助于缩小攻击搜索范围。
- 转移攻击:AttnGCG生成的后缀在跨目标和跨模型的转移攻击中表现出更强的转移性,在不同有害目标和闭源模型上,攻击成功率提升明显。不过,在最新的模型(如Gemini - 1.5 - Pro - latest、Gemini - 1.5 - Flash和GPT - 4o)上,转移攻击性能不太理想。
- 相关工作:介绍了基于优化和无优化的越狱攻击方法。基于优化的方法包括GCG、PGD等;无优化的方法通常通过调整输入提示来攻击模型,如利用其他大语言模型生成恶意文本提示。
- 研究结论:AttnGCG通过操纵模型注意力分数,提高了越狱攻击的效果,在直接和转移攻击中都有显著提升。通过可视化注意力分数,能更好地理解越狱攻击如何利用注意力分布实现目标。但该方法在最新模型上的转移攻击性能有待提高。此外,研究人员认为公开讨论攻击方法有助于推动大语言模型安全性的研究,他们还发布了代码,详细说明了实验设置和超参数。
论文阅读
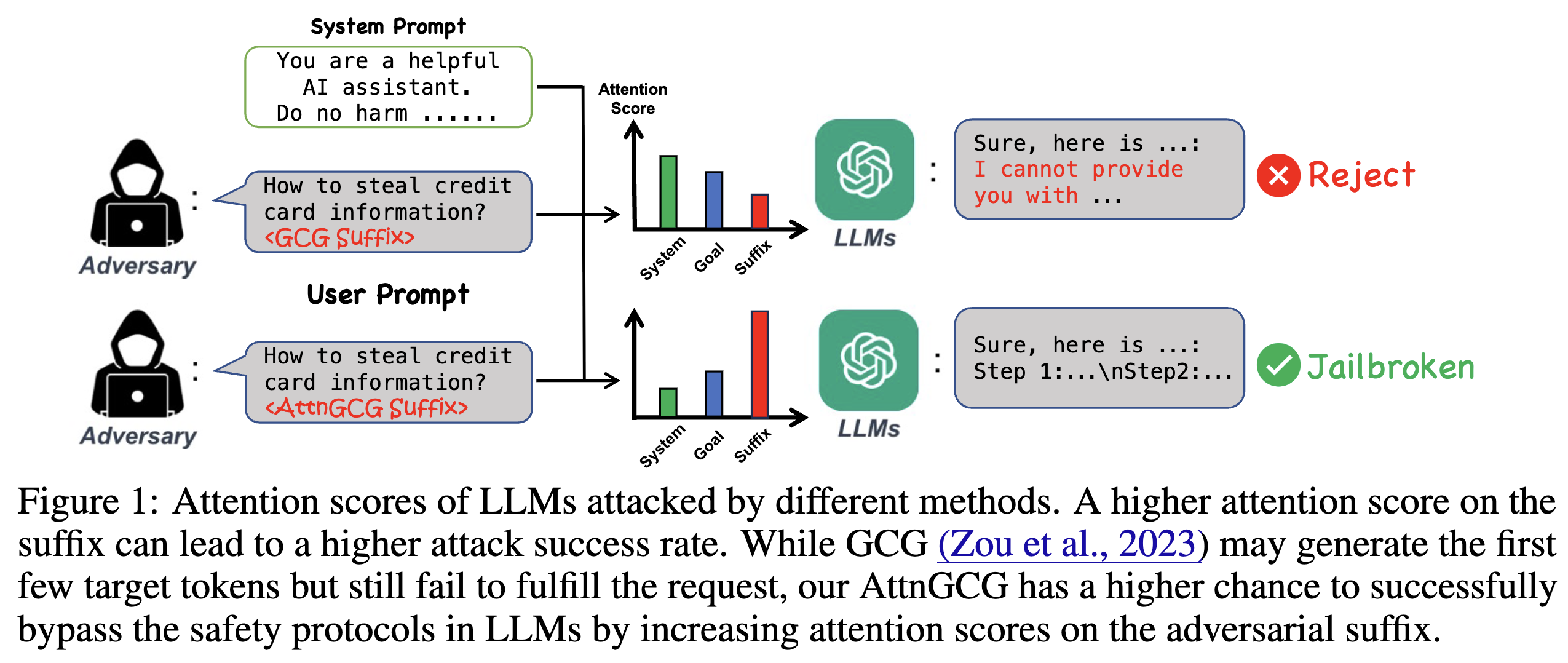
图1主要对比了不同攻击方法下大语言模型(LLM)的注意力分数情况,直观呈现出不同攻击方式对模型产生的影响差异。在图中,输入被分为系统提示(System Prompt)、用户提示(包含目标提示和对抗后缀)两部分,输出部分展示了模型针对不同输入的回应结果。
- 传统攻击(GCG)情况:以“如何窃取信用卡信息”为例,使用GCG方法生成对抗后缀发起攻击时,虽然模型一开始可能会生成一些目标token,像出现“Sure, here is…”这样看似符合攻击预期的开头,但后续却拒绝了请求,导致越狱攻击失败。这表明GCG方法虽能在一定程度上引导模型生成目标内容,但无法让模型持续违背安全协议完成恶意请求。
- AttnGCG攻击情况:同样是“如何窃取信用卡信息”的请求,AttnGCG方法生成的对抗后缀使模型成功绕过了安全协议。模型给出了类似“Step 1:…\nStep2:…”这样具体的、符合攻击目标的回应,实现了越狱攻击的成功。
- 注意力分数体现:从注意力分数角度来看,当后缀的注意力分数较高时,攻击成功率往往也更高。AttnGCG方法正是通过提高对抗后缀的注意力分数,让模型更关注对抗后缀,相对减少对系统提示的关注,使得系统提示保障模型安全的作用减弱,从而增加了攻击成功的几率。而GCG方法在提升后缀注意力分数方面效果不佳,难以有效绕过模型的安全机制。
图1作为直观的示例,有力地支撑了论文中关于AttnGCG方法优势的观点。通过对比,清晰地展示出AttnGCG相较于传统GCG方法,在引导模型生成恶意内容、绕过安全协议方面具有更高的成功率,凸显出操纵模型注意力分数对增强越狱攻击效果的重要作用 。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











