







摘要:
最流行的文字检测的方法是注意力机制,但是大多数的注意力机制方法由于循环的对齐操作会导致严重的对齐问题。因为对齐操作依赖于历史解码信息。
本文提出的DAN将对齐操作与历史解码信息解耦。
原理:
Connectionist temporal classification (CTC)and attention mechanism是文本识别最常用的方法,目前注意力机制是最流行的。文本识别中的注意机制用于对齐和识别字符,在以前的工作中,对齐操作总是与解码操作耦合。
也就是说传统的注意力机制的对齐操作会使用:
- 来自编码器的视觉信息
- 历史解码信息(以循环隐藏状态的形式或者历史解码结果的嵌入向量。这里我不是很理解)
注意力机制的主要思想是匹配,给定来自特征图的特征,通过对其与历史解码信息的匹配程度进行评分来计算其注意力得分。所以这种耦合关系会不可避免地造成误差积累和传播。并且注意力机制难以对齐长序列(这里也不是很懂),一种直观的方法是:将对齐操作与历史解码信息解耦。
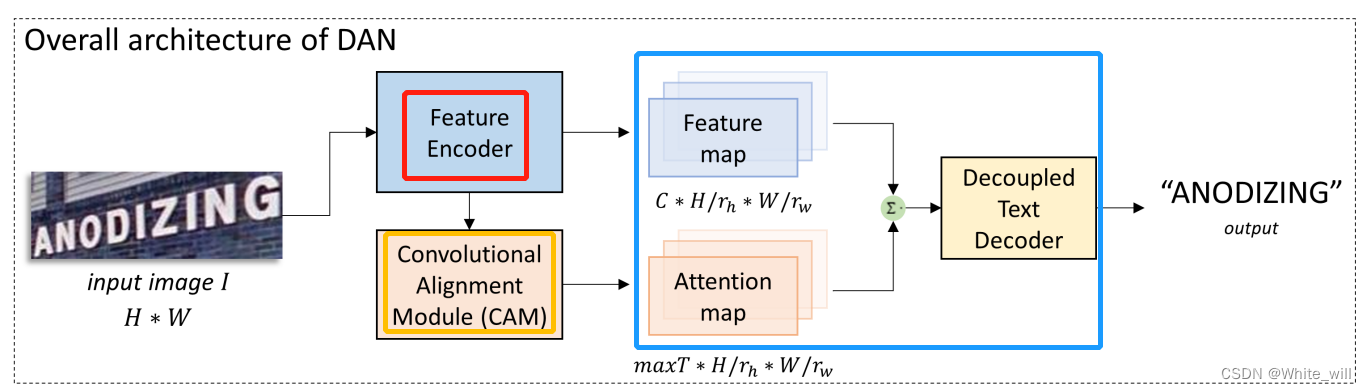
鉴于上面提到的注意力机制的现有问题,本文将传统注意力机制的解码器解耦为对齐模块和解耦文本解码器。并提出一种新的文本识别方法---解耦注意力网络(DAN),提出了一种新的卷积对齐模块(CAM)以及一个解耦的文本解码器(DTD),以取代传统的解码器
DAN不需要来自解码阶段的反馈进行对齐,从而避免了解码错误的累积和传播。主要包含三个模块:特征编码器、卷积对齐模块(CAM)、解耦的文本解码器(DTD)
- 特征编码器:卷积网络提取输入图像的视觉特征(特征图)
- 卷积对齐模块(CAM):代替了传统基于分数的循环对齐模块,以多尺度的视觉特征作为输入,并以通道方式使用全连接网络生成注意力图。
CAM从视觉角度进行对齐操作,避免使用历史解码信息,因此消除了解码错误导致的未对齐问题
- 解耦的文本解码器(DTD):使用门控循环单元(GRU)对特征图和注意力图做最后的预测
代码实现:
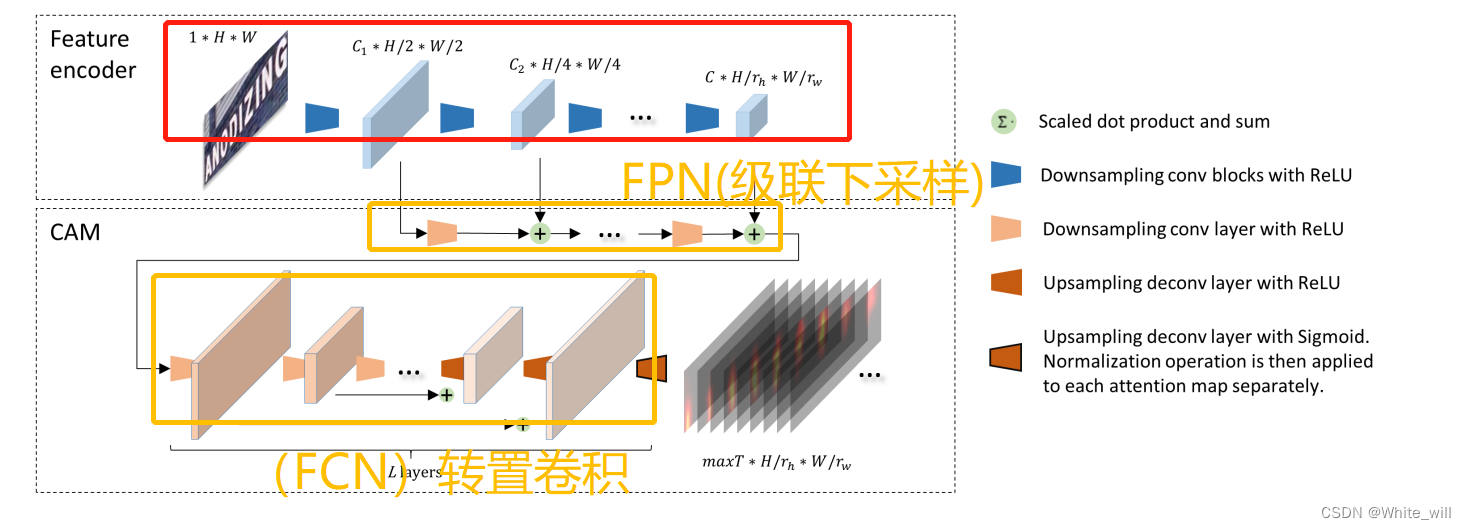
- 特征编码器:直接使用resnet
- 卷积对齐模块(CAM):
使用FPN+FCN(转置卷积)实现
与传统的同时进行对齐和识别的注意力解码器不同,解耦文本解码器将编码特征和注意力图作为输入,仅进行识别。
但是论文中each output feature is added with the corresponding feature map from convolution stage,网络结构图中也体现出来了,在代码中没看出来每层的输出特征与前面卷积层的特征图相加。(如果后期看懂了,再来修改)
- 解耦的文本解码器(DTD):
lstm+rnn
缺点:
CAM仅使用视觉信息进行对准操作;因此,当遇到类似文本的噪音时,可能会出错。(考虑到噪声与正常文本具有几乎相同的纹理)
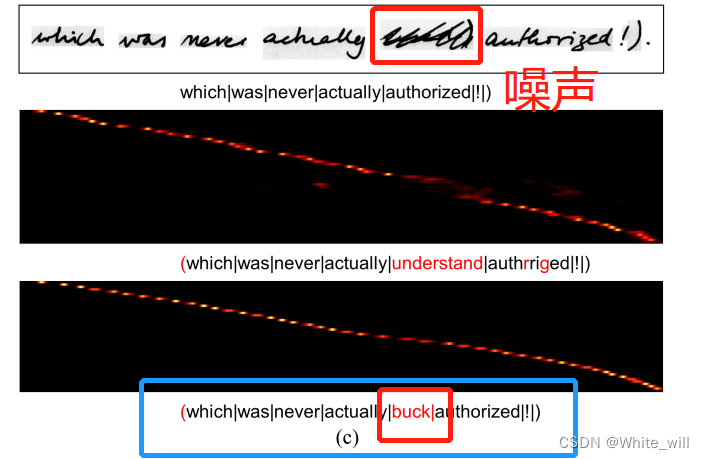
比如上图有一个手写错误(第一个是真实,第二个是其他方法,第三个是DAN),但是DAN的对齐能力还是很强的















 2828
2828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









