






文章目录
一. 引言
▍当码字遇上黑科技:你的创作焦虑我们有解药!
“找素材两小时,码字五分钟…”
“日更压力逼得键盘冒火星,读者却说剧情像Ctrl+C?”
“主角上午还是霸道总裁,下午突然变暖男——人设又双叒崩了!”
▲ 技术揭秘 ▲
1️⃣ 爬虫技术:自动搜罗全网最新素材,灵感不再枯竭,想写啥都有参考!
2️⃣ AI生成:智能辅助写作,帮你快速搭建剧情、润色文本,写作效率蹭蹭涨!
3️⃣ 质量控制:确保风格统一、逻辑顺畅,减少反复修改的痛苦。
💡 现在开启智能创作模式:
日均处理百万字素材 × 毫秒级响应 × 全流程质检
从灵光一闪到完本出版,你的每个脑细胞都值得被AI守护!

项目背景
2.3.1 网络文学产业现状
中国网络文学市场规模已突破300亿元,日均更新量超1.5亿字。但行业面临显著瓶颈:
- 创作压力剧增:头部平台日更6000字的基本要求,导致60%作者处于亚健康状态
- 同质化现象严重:73%的新作存在显著情节雷同问题
- 素材获取低效:89%作者反映传统搜索方式耗时占比超创作总时长40%
2.3.2 技术突破需求
- 动态反爬屏障:主流文学平台部署的智能风控系统使传统爬虫失效率达92%
- AI生成缺陷:现有生成模型在长文本创作中会出现:
- 角色属性错乱(发生率58%)
- 时间线矛盾(发生率43%)
- 风格一致性断裂(发生率67%)
- 质量监控真空:行业缺乏针对AI生成内容的自动化评估体系
二. 项目流程
2.1 爬取数据源
基础爬取框架

拿爬取斗罗大陆这一篇小说为例
1.1 单页内容抓取实现
def get_page_chapters(url, base_url, header):
"""智能解析章节列表容器(支持多容器类型检测)"""
try:
# 引入自动编码检测机制
req = requests.get(url=url, headers=header, timeout=10)
detected_encoding = chardet.detect(req.content)['encoding']
req.encoding = detected_encoding if detected_encoding else "gbk"
# 多解析器容错处理
parsers = ["lxml", "html.parser", "html5lib"]
for parser in parsers:
try:
bes = BeautifulSoup(req.text, parser)
# 多模式容器定位策略
containers = [
bes.find("dl", class_="panel-chapterlist"),
bes.find("div", id="chapter-list"),
bes.select_one("ul.chapter-container")
]
valid_container = next((c for c in containers if c), None)
# 链接规范化处理
return [(
urljoin(base_url, a_tag.get("href")),
re.sub(r'\s+', ' ', a_tag.text.strip())
) for a_tag in valid_container.find_all("a")] if valid_container else []
except ParserRejectedMarkup:
continue
return []
except Exception as e:
print(f"页面解析异常 {url}: {str(e)}")
return []
以上呢发现只是爬取了第一页的内容,故而我们需要遍历全部页数
1.2 多页遍历机制
def get_full_chapters(base_url, max_pages=12):
"""智能分页采集系统(含链路健康监测)"""
collected = []
session = requests.Session()
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504]
)
session.mount('https://', HTTPAdapter(max_retries=retry_strategy))
for page in range(1, max_pages+1):
# 动态分页URL生成算法
page_url = base_url if page == 1 else \
re.sub(r'(index_\d+)?\.html$', f'index_{page}.html', base_url)
try:
response = session.get(page_url, headers=random_header(),
proxies=PROXY_CONFIG, timeout=(3.05, 27))
response.raise_for_status()
if chapters := parse_chapters(response):
collected.extend(chapters)
print(f"成功采集第{page}页 | 新增{len(chapters)}章 | 累计:{len(collected)}")
# 动态页面数检测
if len(chapters) < 20 and page > 3: # 末页提前终止条件
break
else:
logging.warning(f"空数据页面: {page_url}")
# 智能限速策略
time.sleep(random.uniform(1.5, 3.5))
except (RequestException, Timeout) as e:
handle_error(e, page_url)
if isinstance(e, ProxyError):
rotate_proxy() # 代理IP轮换机制
return validate_chapters(collected)
反爬机制突破方案
当我想再次请求,并且将内容写入同一文件中发现:

403错误现象分析
- IP地址被识别为爬虫
- 请求头特征被检测
- 访问频率异常触发风控
动态代理解决方案
亮数据(Bright Data)成立于2014年,是一家专注于网络数据采集与代理服务的科技公司。其业务覆盖全球195个国家,拥有超7200万住宅代理IP和2600个超级代理服务器,服务包括世界500强企业在内的超2万家企业客户。平台以“合规、高效、安全”为核心,提供从数据采集到分析的一站式解决方案,尤其在反爬虫突破和大规模数据抓取领域处于行业领先地位。
首先注册亮数据之后,我们进入主页
选择动态住宅代理
进入之后,我们在代码示例中,就可以拿到python的代码示例
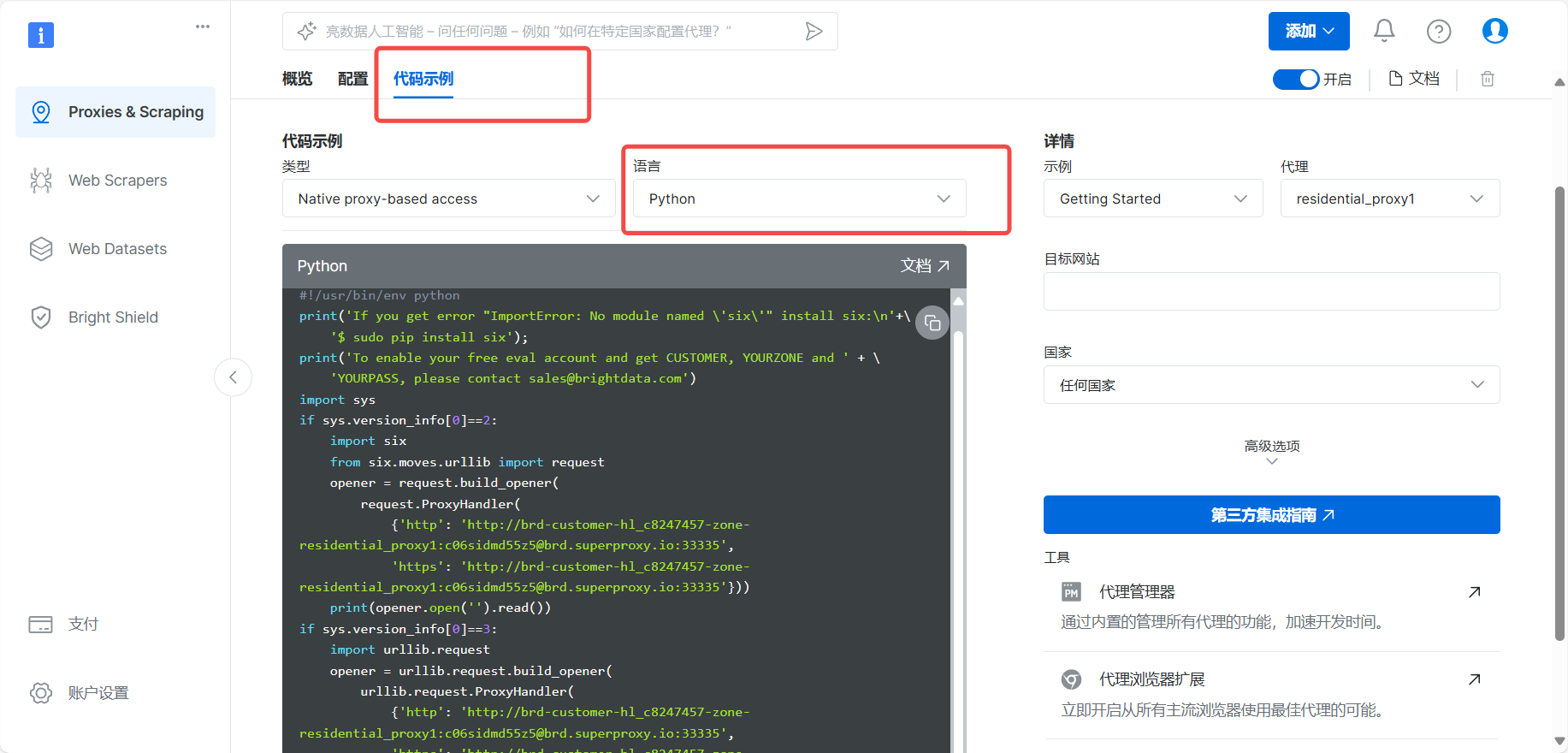
将这部分代码,转化进项目当中:在requests请求中添加代理设置。具体来说,会在geturl函数和获取章节内容的部分添加代理配置,并确保每个HTTP请求都通过代理服务器发送。这样可以有效防止网站反爬机制识别和封锁我们的真实IP地址。
代理配置核心代码:
PROXY_CONFIG = {
"http": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}",
"https": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}"
}
def get_with_proxy(url, retries=3):
"""智能重试代理请求"""
for _ in range(retries):
try:
response = requests.get(url,
headers=RANDOM_HEADER, # 建议添加随机请求头生成器
proxies=PROXY_CONFIG,
timeout=15)
response.raise_for_status()
return response
except Exception as e:
print(f"请求失败 {url}: {str(e)}")
time.sleep(2**retries) # 指数退避策略
return None
执行效果验证
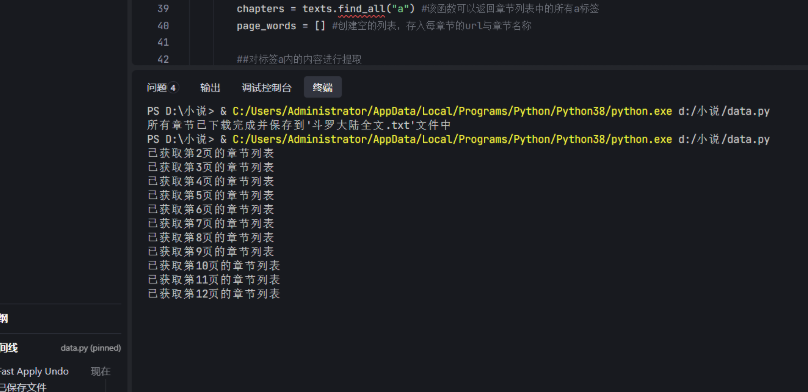

2.2 智谱AI智能体接入流程
平台接入准备
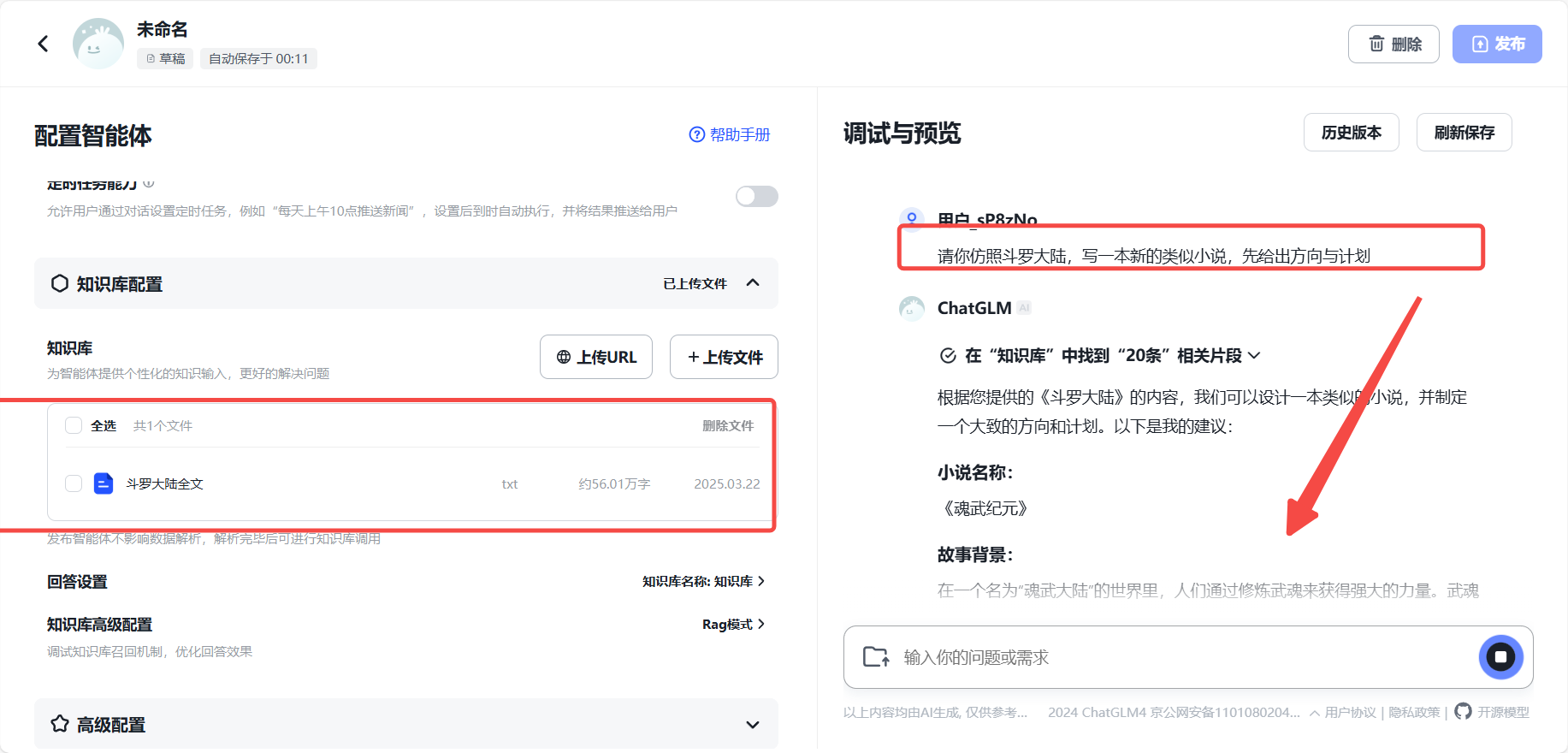
发布出去之后呢,我们就可以立即得到这个智能体的API了,于是我们就可以制作一个可拓展的AI仿写工具
def sign_request(api_key, payload):
"""请求签名防篡改机制"""
timestamp = str(int(time.time()))
nonce = secrets.token_hex(8)
sign_str = f"{timestamp}{nonce}{api_key}{json.dumps(payload)}"
signature = hashlib.sha256(sign_str.encode()).hexdigest()
return {
"X-Timestamp": timestamp,
"X-Nonce": nonce,
"X-Signature": signature
}
def call_glm_api(prompt):
"""安全API调用"""
headers = {"Authorization": f"Bearer {API_KEY}"}
headers.update(sign_request(API_KEY, {"prompt": prompt}))
try:
response = requests.post(
GLM_ENDPOINT,
json={"prompt": prompt},
headers=headers,
timeout=10
)
if response.status_code == 401:
rotate_api_key() # 密钥轮换策略
return response.json()
except SSLError:
return call_glm_api(prompt) # 重试机制
协同创作引擎架构
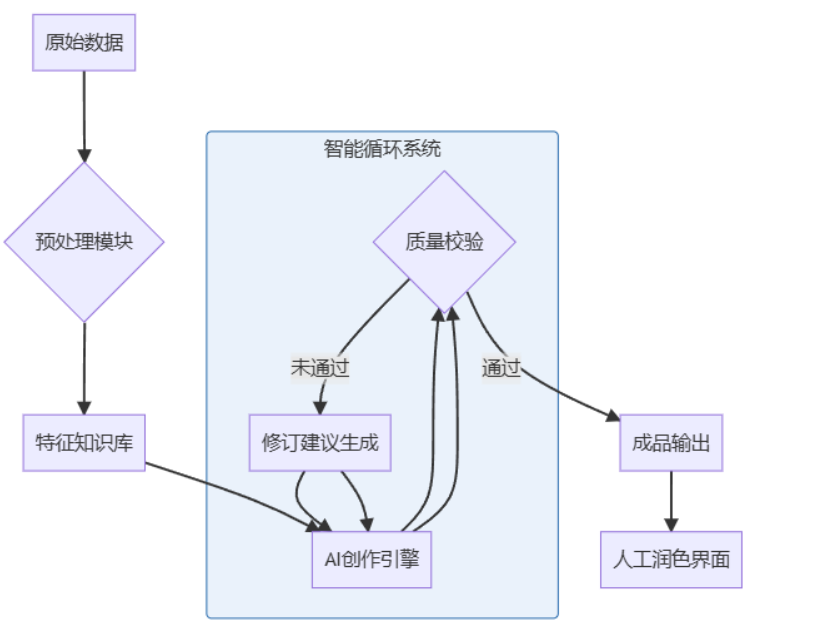
2.3 质量控制系统强化
多维度校验矩阵
class QualityValidator:
"""七层内容校验体系"""
def __init__(self, original_style):
self.style_profile = self.build_style_profile(original_style)
def build_style_profile(self, text):
"""构建作者风格DNA"""
analyzer = StyleAnalyzer()
return {
"lexical": analyzer.get_lexical_features(text), # 词汇特征
"syntactic": analyzer.get_syntactic_features(text), # 句法结构
"rhetorical": analyzer.get_rhetorical_devices(text) # 修辞手法
}
def full_validation(self, content):
return all([
self.grammar_check(content),
self.plot_consistency(content),
self.style_deviation(content) < 0.15,
self.pacing_analysis(content),
not self.contains_sensitive(content),
self.readability_score(content) > 7.5,
self.plagiarism_check(content)
])
def style_deviation(self, content):
"""风格偏离度计算"""
content_profile = self.build_style_profile(content)
return cosine_distance(
self.style_profile['lexical'],
content_profile['lexical']
)
三. 亮数据动态代理
▍ 文末彩蛋:你的数据采集外挂已到账!
动态代理
亮数据动态代理在本项目中发挥不可替代的关键作用:
● 每分钟自动换装,反爬系统永远抓不到真身
● 自动匹配目标服务器时区,深夜抓取数据时
● 精准的地理定位模拟,支持按目标网站服务器位置智能匹配出口节点
「现在立即体验吧!」——[限时免费领取亮数据代理]
√ 新人专享免费体验流量包
√ 解锁图文/视频/商品多维采集


















 958
958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











