






目录
Analysis of the existing label correction methods
原文:https://arxiv.org/abs/2008.00627
code:GitHub - WuYichen-97/Learning-to-Purify-Noisy-Labels-via-Meta-Soft-Label-Corrector
知乎:Paper Reading: Meta-Weight-Net[NIPS'2019] - 知乎
如何理解Meta-learning
MW-Net:https://arxiv.org/pdf/1902.07379.pdf


这里的相当于
,
相当于
Meta-train


Meta-test


Abstract
现有方法的不足:当前校正损坏标签的方法通常需要某些预定义的标签校正规则或手动预设的超参数。这些固定的设置使其很难在实践中应用,因为准确的标签校正通常与具体问题、训练数据和隐藏在训练过程的动态迭代中的时间信息相关。
提出的方法:提出了一种元学习模型,可以在无噪声元数据的指导下通过元梯度下降步骤来估计软标签。通过将标签校正过程视为元过程并使用元学习器自动校正标签,我们可以根据当前的训练问题迭代地自适应地获得校正后的软标签,而无需手动预设超参数。
Introduction
Sample selection
样本重新加权方案
Typical methods include boosting and self-paced learning methods [9, 10]。最近,一些开创性的工作[11, 7]通过采用一小组干净的元数据来指导网络训练过程,进一步使这种加权方案更具适应性和自动化。
不足:所有这些方法都是建立在训练中剔除可疑噪声样本的基础上的。然而,这些损坏的样本包含有用的信息,可以提高网络的准确性和鲁棒性,特别是在大噪声比的情况下[12]。
Label correction
1. 估计噪声转移矩阵
主要存在两种估计噪声转移矩阵的方法。一种是通过使用锚点先验假设来预先估计噪声转移矩阵来训练分类器。另一种方法是在统一框架中联合估计噪声转移矩阵和分类器参数,而不使用锚点
不足:由于难以估计噪声转移矩阵或真实标签,网络训练很容易积累误差,特别是当类数或错误标记样本较多时
2. 利用网络的预测来直接纠正噪声标签
bootstrapping loss,Joint Optimization,U-correction,SELFIE
不足:这些方法的性能很大程度上依赖于生成的软标签的可靠性,这取决于在噪声数据集上训练的分类器的准确性。当分类器性能较差时,其提供的错误标签信息将进一步降低所获得的分类器的质量。此外,这些方法通常需要手动预设合适的超参数以更好地适应不同的训练数据。另一方面,这使得它们很难推广到实际案例中的各种不同场景。
3.提出MSLC
优点:
- 将输入标签映射到校正后的软标签,而不使用传统的预定义生成规则
- 在无噪声元数据的指导下,我们的方法可以自适应地利用模型的时间预测来生成更准确的伪标签,而无需手动预设组合系数。
- 我们提出的模型与模型无关,可以添加到手头任何现有模型的顶部
Analysis of the existing label correction methods
手动设置参数


不足: 此外,由于取代原始软标签的新软标签质量较低,这些方法可能会导致严重的错误累积。 Bootstrap [16] 和 U- Correction [6] 将观察到的标签 y 与当前预测 ^ y(t) 相结合,生成新的软标签。然而,基础模型的预测存在显着变化,特别是对于标签损坏的样本。Joint Optimization[18]方法使用早期网络的预测来缓解这个问题,但它使用新的软标签来替换所有标签,无论它是否干净,可能会导致干净的原始标签被错误纠正的问题。
Meta Soft Label Corrector
伪标签的生成
其中是我们提出的MSLC生成的软伪标签,y表示原始标签,I表示有助于进行此类标签校正的辅助信息,θ表示该函数中涉及的超参数。
现在的问题是如何指定I和g的函数参数格式,以及如何学习其涉及的参数θ。
经过上述分析,和
作为辅助信息
:


学习参数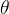
我们很容易采用[7]中使用的元数据驱动的学习机制,它利用一个小但无噪声的数据集(即元数据)来学习训练样本的超参数。元数据集包含干净样本的底层标签分布的元知识,因此可以合理地利用它作为合理的指南来帮助估计我们任务的 θ。

如何更新
·我们利用 SGD 技术通过以小批量更新方式近似解决问题来共同改善 θ 和 w 来加速算法。
流程图

公式解释


算法

Experimental Results
MW-Net 在不对称条件下性能较差,这可能是因为该方法中所有类共享一个权重函数,这在噪声不对称时是不合理的。
从图6(a)(c)可以看出,U-correction的校正标签精度略有下降,这可能是由于其大量的错误校正造成的。值得注意的是,U-correction保留了99%以上的干净样本,但我们通过实验发现,原因是它在训练过程中倾向于将大部分样本视为干净样本,这限制了它的校正能力噪声样本,如图5(b)右栏所示。

此外,虽然JointOptimization的准确率一直在提高,但其性能受到仅使用伪标签替换所有目标的策略的限制,这存在破坏原始干净标签的风险。
Future direction
In the future study, we will try to construct a new structure of meta soft label corrector, which input is not only the loss information, so that its well-trained model could transfer to other datasets under different noise level.















 5929
5929

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









