







提示学习(Prompt Learning)综述
本文主要介绍一种首先在自然语言处理(Natural Language Processing)领域中出现的新的学习范式:提示学习(Prompt Learning)。
本文主要内容基于刘鹏飞的survey:Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing,这篇survey主要是在NLP的背景下介绍了提示学习(prompt learning)的基本概念及方法分类。
(一)prompt learning和prompt介绍
❓提示学习(Prompt Learning)是怎么出现的❓
我们知道目前已经出现了许多较为成功的预训练语言模型(Pre-trained Language Models),以下简称PLMs,比如GPT系列、BERT,T5等。它们的预训练方式各不相同,或是通过自回归式(将当前时刻之前模型的输出作为输入预测当前的输出)的续写,或是通过对一个不完整的(masked)句子进行完形填空(cloze),亦或是通过编码器、解码器的自编码器结构进行完整句子的重建。这些不同的预训练方式都给PLMs带来了较强的阅读理解和问答能力。
同时,相关研究发现,将下游任务的形式和PLMs预训练任务的形式对齐可以很好地将预训练语言模型的这种文本理解能力运用到下游任务中,在零样本(zero-shot)或少样本(few-shot)的场景中获得良好的效果。
❓如何将下游任务与预训练任务的形式进行对齐❓
为了将下游任务与预训练任务的形式进行对齐,我们需要对下游任务的形式进行改造。
通过人为设定的模板(Template)对下游任务进行改造,构造与预训练任务类似的提示(prompt)。
❓这个提示(prompt)的形式❓
我们举两个例子说明:
👉假如我们进行文本情感分类的任务:👈
判断以下表述的情感极性(positive or negative):

为了提示预训练语言模型进行情感的判断,我们可以在输入的后面加上提示信息,告诉模型我们要进行情感极性的判断。这个提示信息存在一个空位,需要PLMs填入一个能够表达情感极性的词,如fantastic:

我们将这个prompt输入到预训练的语言模型,让它在[ ]里面填入一个与情感相关的词。
👉假如我们进行文本翻译的任务:👈


这时,我们的提示(prompt)可以写成:

我们期望我们的PLMs可以在[ ]处直接填入一个中文的翻译。
我们可以发现,在构造prompt后,我们将原本的分类或翻译任务转化成了与PLMs预训练任务类似的填空或者续写的任务,这就实现了对齐。
通过构建合适的提示(prompt),我们可以操纵PLMs的行为,使得预训练的语言模型本身可以用来预测下游任务所需的输出,有时甚至不需要任何额外的下游任务训练数据的训练。这种方法的优势在于,通过一系列合适的提示(prompts),一个完全由无监督训练方式得到的单一语言模型可以用来解决各种各样的下游任务。
特别地,上面第一个任务中蓝色prompt的形式,我们称之为完形填空式(cloze prompt),它提示模型填补空缺;第二个任务中红色prompt的形式,我们称之为前缀式(prefix prompt)(prompt的其他信息整体全部在空位[ ]的前面),它提示模型进行续写。
🔥prompt更严谨的定义如下:
Prompt is the technique of making better use of the knowledge from the pre-trained model by adding additional texts to the input.
Prompt 是一种为了更好的使用预训练语言模型的知识,采用在输入段添加额外的文本的技术。
- 目的:更好挖掘预训练语言模型
PLMs的能力 - 方式:在输入端添加文本,即重新定义任务(task reformulation)
(二)prompting的工作流程
❓prompting的工作流程是什么样的❓
其工作流程主要包括以下四个部分:
(1)提示的构造(prompt construction)。
(2)答案空间 Z \mathbb{Z} Z与输出空间 Y \mathbb{Y} Y之间映射(一般被称作verbalizer)的构建(这两空间将在后面解释)。
(3)答案的搜索(answer search,找到填入空白 [ ] 的词应该是什么比较好)。
(4)答案空间 Z \mathbb{Z} Z到输出空间 Y \mathbb{Y} Y的映射(answer mapping,利用(2)中构建的verbalizer)。
(1)提示的构造(prompt construction)
❓怎么构造一个提示(prompt)❓
我们知道提示的构造就是对输入进行修饰,通过添加额外的文本,引入能够提醒预训练语言模型我们在完成什么样的任务的信息。这里,我们将修饰过程抽象为一个prompting function
f
p
r
o
m
p
t
(
⋅
)
f_{prompt}(\cdot)
fprompt(⋅),其接受输入文本
x
\boldsymbol{x}
x作为输入,输出得到提示prompt
x
′
=
f
p
r
o
m
p
t
(
x
)
\boldsymbol{x}^{\prime}=f_{prompt}(\boldsymbol{x})
x′=fprompt(x)。具体地,这个函数主要包括两个部分:
-
使用一个模板(template),这个模板中有两个空位(slots):一个是留给输入 x \boldsymbol{x} x的输入空位(input slot)
[X],另一个是留给答案搜索阶段产生的中间答案 z \boldsymbol{z} z的答案空位(answer slot)[Z]。 -
将输入文本 x \boldsymbol{x} x填入输入空位
[X]。
如下图所示:
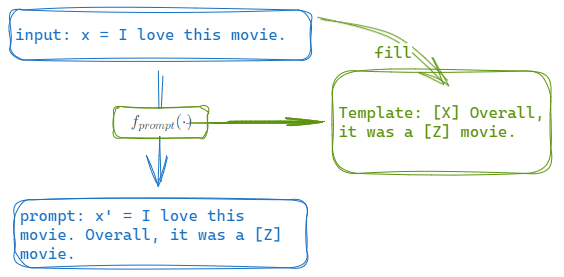
1️⃣得到的prompt仍有一个留给答案
z
z
z的空位。这个空位要么在一个prompt的中间,要么在一个prompt的末尾,分别对应我们(一)中提到的完形填空式(cloze)和前缀式(prefix)的提示(prompt)。
2️⃣在许多情况下,模板里的词汇不一定是人类可以理解的自然语言,它们可能是虚拟的词汇(比如说被表示为数值 ids(numeric ids)的词汇),也可能是通过某些方式产生的连续的一组词向量(vectors),这组词向量可能是由下游任务的训练数据通过更新prompt-revelant的参数得到的。大白话来说,就是下游任务的训练数据被用来推敲我们与PLMs对话时的措辞了,好的措辞能让PLMs产生更好的答案。
3️⃣另外,输入空位[X]和答案空位[Z]的数量并不是固定的一个,其数量与手中要解决的任务的形式直接相关。
(2)答案空间与输出空间映射(verbalizer)的构建
❓首先,什么是答案空间 Z \mathbb{Z} Z❓
对于文本情感分类任务的输入 x \boldsymbol{x} x 和提示(prompt) x ′ \boldsymbol{x}^{\prime} x′:


空位[Z]处可以填入的所有词汇构成答案空间
Z
\mathbb{Z}
Z。针对上述问题,答案空间
Z
\mathbb{Z}
Z可以写成:
Z = { ’good’ , ’great’ , ’bad’ , ’terrible’ , . . . } \mathbb{Z}=\{\text{'good'},\enspace\text{'great'},\enspace\text{'bad'},\enspace\text{'terrible'},\enspace ...\} Z={’good’,’great’,’bad’,’terrible’,...}
❓然后,什么是输出空间 Y \mathbb{Y} Y❓
仍以文本情感分类任务为例。一般来说,分类模型接受一个文本输入 x \boldsymbol{x} x,预测一个输出标签 y \boldsymbol{y} y,这个标签 y \boldsymbol{y} y来自一个固定的(fixed)标签集合 Y \mathbb{Y} Y。这个标签集合就构成我们这里所说的输出空间(或者被称为标签空间(label space))。
对于情感二划分的情况,这个标签集合可以写成:
Y = { ’positive’ , ’negative’ } \mathbb{Y}=\{\text{'positive'},\enspace\text{'negative'}\} Y={’positive’,’negative’}
上述答案空间与输出空间的映射(我们一般称之为verbalizer),可以表示为:
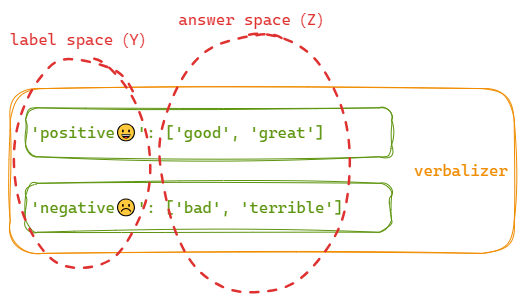
1️⃣这里映射关系的构建也就是将情感的标签(labels)映射到能够描述对应情感标签的词汇(answers)上去。
2️⃣另外,这个verbalizer并不是必须的,需要根据具体的任务进行具体的分析。例如,生成任务由于没有需要映射的标签,就没有这个verbalizer 。
(3)答案的搜索(answer search)
其实我们在完成提示的构造后就可以利用PLMs进行答案的搜索了,上述的答案空间与输出空间的映射是可选(optional)的步骤。
❓答案的搜索是什么样的❓
答案搜索主要是指从(2)中提到的答案空间
Z
\mathbb{Z}
Z中搜索prompt
x
′
\boldsymbol{x}^{\prime}
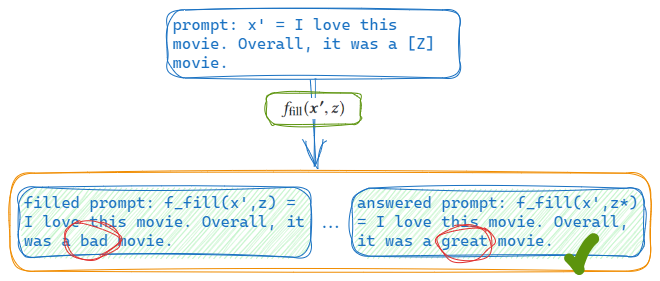
x′的答案的过程。具体地,就是将所有可能的答案依次填入提示的空位[Z]处,再分别对每一个结果进行评估,得到最好的答案或者答案的概率分布。
首先,我们需要将不同的答案填入到提示中去,这个填充过程我们抽象为一个填充函数
f
f
i
l
l
(
x
′
,
z
)
f_{fill}(\boldsymbol{x}^{\prime},\boldsymbol{z})
ffill(x′,z),它将潜在答案
z
\boldsymbol{z}
z填入到提示
x
′
\boldsymbol{x}^{\prime}
x′中的位置[Z]处。我们将经过了这个填充过程的任何提示称为filled prompt。特别地,如果提示的位置[Z]处被真实的答案(真实的答案可能不止一个)填充,我们将该提示称为answered prompt,如下图所示:
然后,我们通过使用预训练的语言模型
P
(
⋅
;
θ
)
P(\cdot;\theta)
P(⋅;θ)来计算潜在答案
z
\boldsymbol{z}
z形成的filled prompt的概率,并根据概率进行搜索:
z ^ = s e a r c h z ∈ Z P ( f fill ( x ′ , z ) ; θ ) \hat{\boldsymbol{z}}=\mathop{\mathrm{search}}_{\boldsymbol{z}\in\mathbb{Z}}P(f_{\text{fill}}(\boldsymbol{x}',\boldsymbol{z});\theta) z^=searchz∈ZP(ffill(x′,z);θ)
这个搜索函数search可以是一个argmax搜索,argmax根据输出分布直接找到最高得分的输出;或者是一个sampling函数,sampling根据语言模型输出的概率分布随机生成输出。
上述过程大白话来说就是你将prompt丢给一个语言模型,让它帮你填空,最后得到答案的过程。
(4)答案映射(answer mapping)
在得到最高分的输出或者采样到的输出 z ^ \hat{\boldsymbol{z}} z^后,我们希望将答案 z ^ \hat{\boldsymbol{z}} z^转变为最终的输出 y ^ \hat{\boldsymbol{y}} y^。
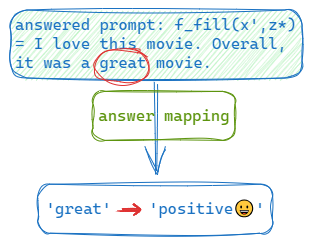
在某些情况下,答案 z ^ \hat{\boldsymbol{z}} z^本身就是输出(例如在语言生成任务中,如文本翻译),这个映射过程是不需要的。
对于其他情况,往往有多个答案
z
^
\hat{\boldsymbol{z}}
z^对应相同的输出
y
^
\hat{\boldsymbol{y}}
y^。例如,一个情感类别(例如'positive')可能使用多个不同的带情感的词(例如“excellent”,“good”,“great”)来表示。在这种情况下,我们就需要用到(2)中构建好的映射关系将搜索到的答案
z
^
\hat{\boldsymbol{z}}
z^映射为输出值
y
^
\hat{\boldsymbol{y}}
y^。
🔥综上,prompting的整体流程如下:
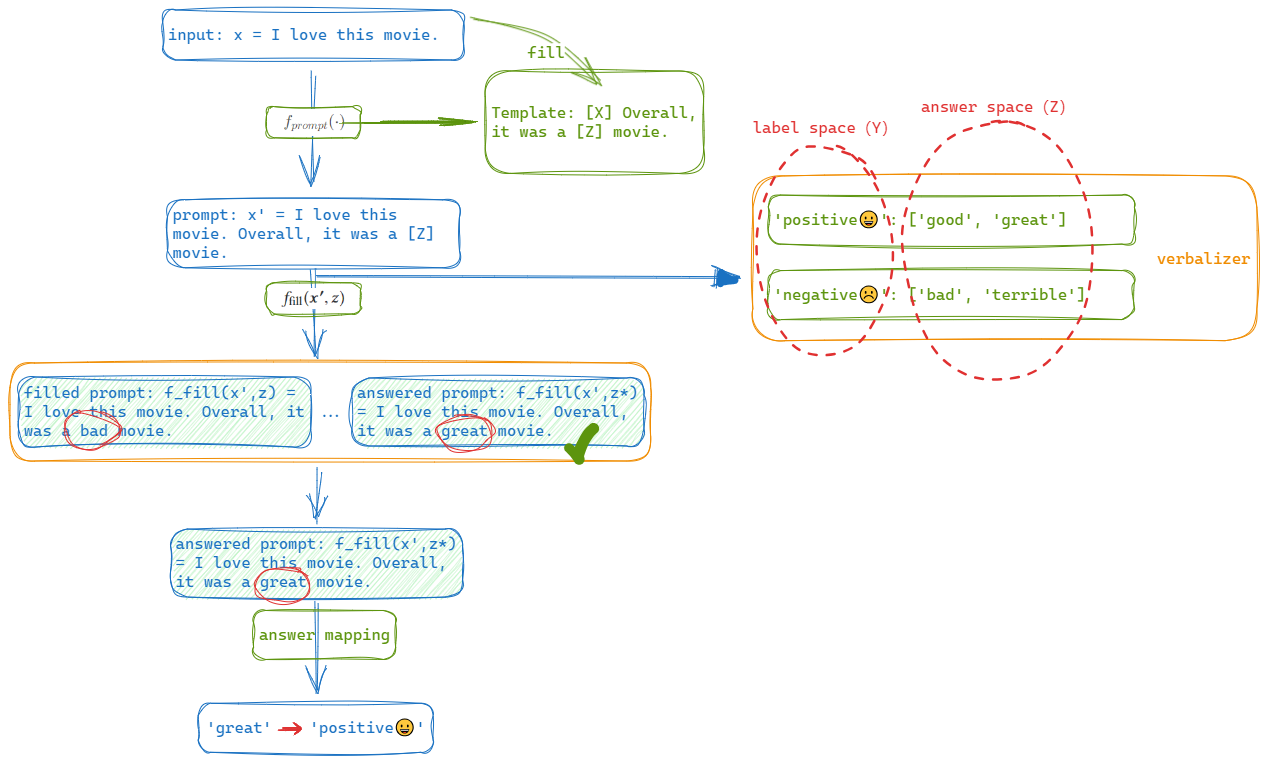
其中最为重要的是第一步prompt的构建(或者说prompt模板(template)的构建),其形式将深刻影响prompting methods的性能。
(三)prompting流程中的一些实现细节
(1)预训练语言模型的选择
在定义完模版以及答案空间后,我们需要选择合适的预训练语言模型对prompt进行预测,如何选择一个合适的预训练语言模型也是需要人工经验判别的。
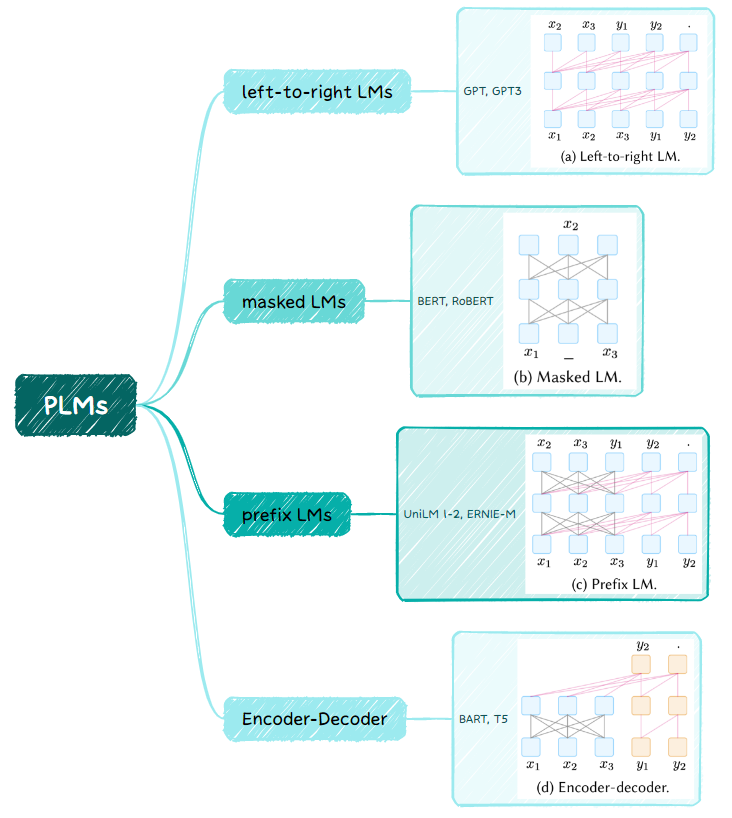
left-to-right LMs:适用于NLU(Natural-Language Understanding)和NLG(Natural Language Generation)任务(注:链接跳转到维基百科);
masked LMs:适用于NLU任务;
prefix LMs:适用于NLU和NLG任务;
Encoder-Decoder:适用于NLU和NLG任务。
(2)prompt模板(template)的设计
prompt模板的设计,其实就是针对下游任务,设计合适的prompting function
f
prompt
(
⋅
)
f_{\text{prompt}}(\cdot)
fprompt(⋅)的过程。这一步对于PLMs在下游任务上的性能具有重要的影响。即使是一个词的不同,也会造成巨大的性能差异。论文GPT Understands, Too中给出了如下的结果:

prompt模板的影响可见一斑。
❓如何构造合适的prompt模版❓
对于同一个任务,不同的构造方式可能形成不同的template。
对于不同的template,可以从以下两种角度进行区分:
- 根据空位(slot)的形状或者说位置区分
-
1️⃣完形填空式(Cloze),即留给答案的空位
[Z]在template中间的位置; -
2️⃣前缀式(Prefix),即留给答案的空位
[Z]在template的末尾,需要对prompt进行续写。
- 根据模板是否人为指定来区分
-
1️⃣人为设计的template
-
2️⃣自动学习的template
-
离散的prompts(hard prompts)
此时的
prompt为PLMs的字典(vocabulary)中的离散字符。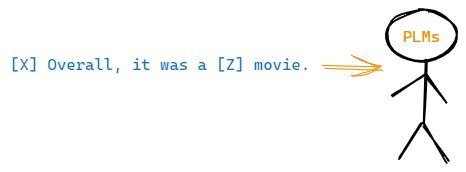
-
✯连续的prompts(soft prompts)✯
此时的
prompt为连续的一组字符embedding。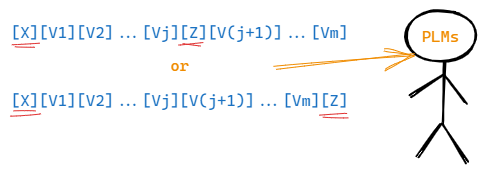
图中 [ V 1 ] , [ V 2 ] , ⋯ , [ V m ] [V_{1}],[V_{2}],\cdots,[V_{m}] [V1],[V2],⋯,[Vm]为同一维度的词向量,其在非
zero-shot的任务(存在下游任务训练样本)中可以被训练优化。
-
(3)prompt答案空间的设计
❓给定一个任务,如何设计答案空间到输出空间的映射,也就是上文提到的verbalizer如何设计❓

在上图中,我们的答案空间
Z
\mathbb{Z}
Z可以是任何表示positive或者negative的词,例如"good/great/fantastic/bad/boring/terrible/dull"等,具体的答案空间
Z
\mathbb{Z}
Z的选择范围由我们指定。
(4)prompting范式的扩展
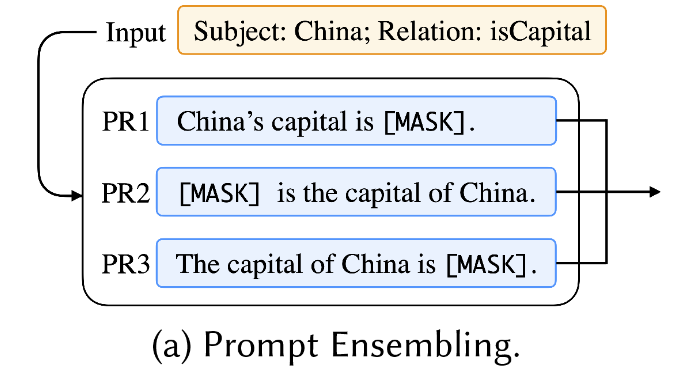
- prompt ensembling(
prompt集成)
🔥prompt集成指的是在模型推理阶段综合多个未回答的(unanswered)的prompts的输出结果。
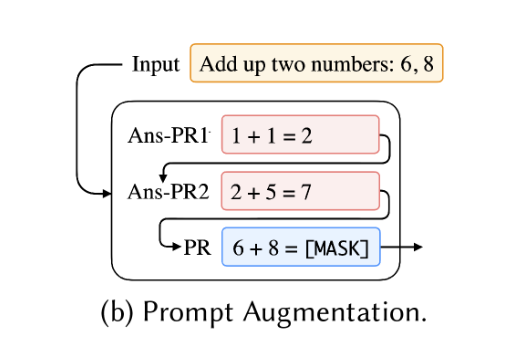
- prompt augmentation(
prompt增强)
🔥prompt增强,有时也被称作demonstration learning(通过示例进行学习),通过给预训练模型PLMs提供一系列的已经回答的(answered)prompts来告诉PLMs我们在完成什么样的任务以及怎样完成该任务。就类似于我们人在考试时通过试卷上提供的一系列例题来思考如何解题一样。
- prompt composition(
prompt组合)
🔥对于那些可通过更基本的子任务进行组合的而成的复杂任务,我们还可以进行prompt组合。针对复杂任务可以分解成的多个子任务,我们给每个子任务一个子提示(sub-prompts),然后组合这些子提示(sub-prompts)定义一个复合提示。
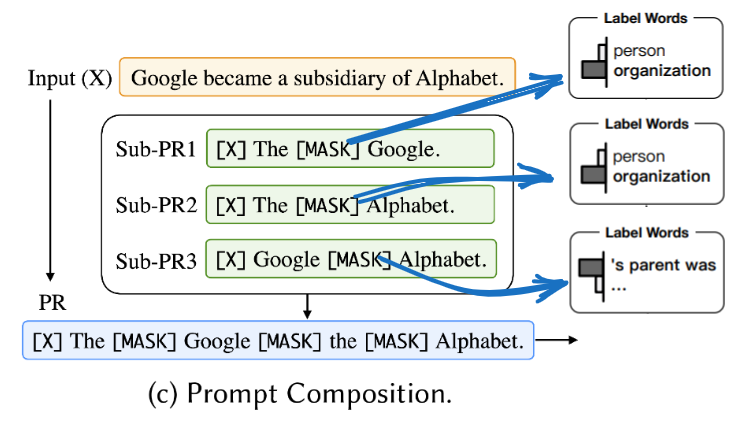
上图所示的方法来自PTR: Prompt Tuning with Rules for Text Classification这篇文章,其使用多个手动创建(multiple manually created)的子提示进行实体识别(entity recognition)(Sub-PR1和Sub-PR2用于实体识别)和关系分类(relation classification)(Sub-PR3用于关系分类),然后根据逻辑规则(logic rules)将它们组合成一个完整的提示PR,用于实体间关系的提取任务(relation extraction)。
- prompt decomposition(
prompt分解)
🔥对于那些需要在一个样本上执行多个预测的任务(例如序列标注),直接针对整个输入文本
x
\boldsymbol{x}
x定义一个完整的提示有时是比较困难的。解决这个问题的一个直观方法是将整体提示分解为不同的子提示,然后让PLMs分别回答每个子提示。

(5)基于prompt的训练策略
-
与任务相关的训练数据的情况
1️⃣
zero-shot:在许多情况下,提示方法可以在不对语言模型进行任何明确的下游任务训练的情况下使用,只需使用已经训练过的语言模型PLMs,并使用完形填空式(cloze)或前缀式(prefix)的提示,用以指定我们正在完成的具体任务即可。这通常被称为zero-shot,因为对于感兴趣的任务我们没有任何训练数据。2️⃣
few-shot:存在少量与下游任务有关的训练样本。3️⃣
full-data:存在足够多的与下游任务有关的训练样本。 -
参数更新方法(存在哪些参数;哪些参数更新,哪些参数不更新)
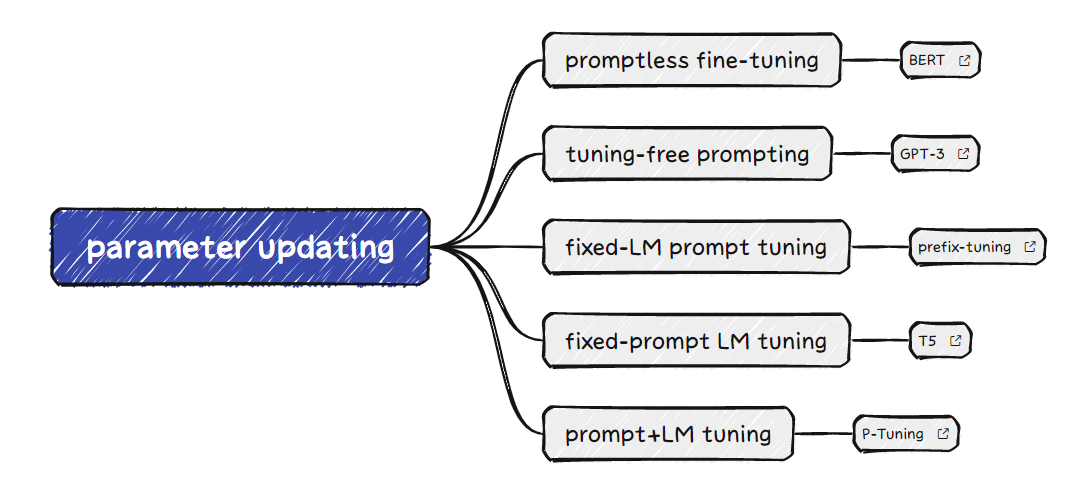
更新策略 LM参数更新? prompt相关参数存在? prompt相关参数更新? 描述 promptless fine-tuning ✔️ ❌ ❌ 传统的预训练+fine-tuning方法,没有prompts tuning-free prompting ❌ ❌ ❌ 依靠prompts的设计使LM直接给出答案 fixed-LM prompt tuning ❌ ✔️ ✔️ 借助下游任务训练数据更新prompts相关参数(优化prompts) fix-prompt LM tuning ✔️ ❌ ❌ 微调LM的参数,在使用prompts时LM具有固定的参数 prompt+LM tuning ✔️ ✔️ ✔️ prompts相关的参数和LM的参数都被更新 具体的例子如下图所示:
(四)与prompting相关的一些技术
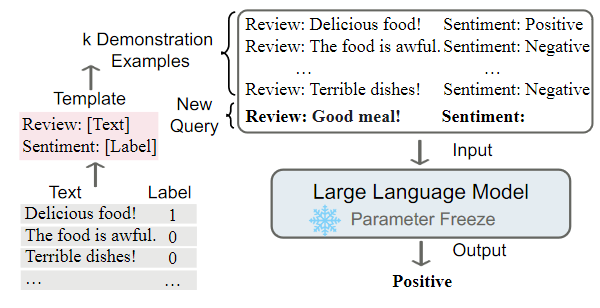
(1)In-Context Learning(ICL)
ICL就是上文(三).(4).2中提到的prompt增强(prompt augmentation)和tuning-free prompting训练策略的结合。ICL需要一系列的示例(demonstrations)来启动PLMs,告诉其我们在完成什么任务以及如何完成。无需调整任何参数(tuning-free),PLMs接收输入的query prompt,直接预测输出。如下图所示:
许多研究对ICL中示例(demonstrations)的作用以及ICL为什么有用进行了研究:
1️⃣Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?
PLMs通过示例(demonstrations)中的input-label pairs进行In-Context Learning,这种输入标签对如下:

该研究认为输入的input-label pairs中的真实标签(ground-truth label)其实没有那么重要,即使label是随机赋予的标签(并不正确),PLMs在许多任务上的性能下降并不明显。
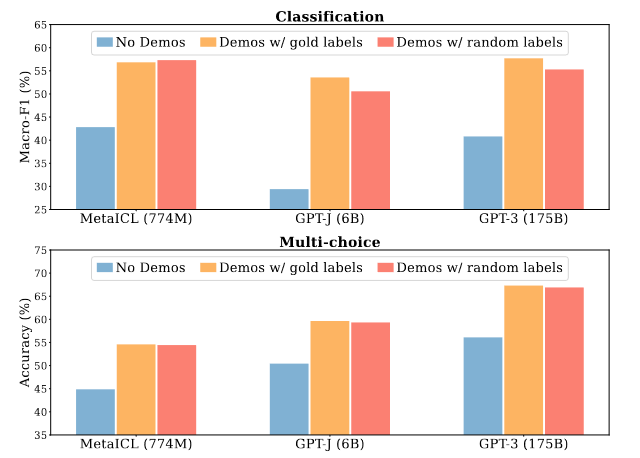
上图中gold labels表示正确标签,random labels表示随机的标签。该研究认为示例的作用仅仅是告诉PLMs标签长什么样子(positive或negative这种形式)、输入长什么样子(input distribution)和输入序列的形式,PLMs不会从示例中学到什么语义的信息。
2️⃣Why Can GPT Learn In-Context? Language Models Implicitly Perform Gradient Descent as Meta-Optimizers
3️⃣Larger language models do in-context learning differently
该研究对1️⃣的结果进行了修正,认为PLMs还是可以从示例中学习到语义信息的,只不过这种学习能力是较大模型的特权。也就是说,PLMs从示例中学习语义信息的能力是随着模型规模的增大才逐渐显现出来的,只有较大的模型才能从示例中获得足够的语义信息从而覆盖(override)掉PLMs预训练阶段的语义先验(semantic priors)。
(2)Instruction Tuning
Instruction Tuning的出现主要源自于我们对PLMs在zero-shot场景下性能的期望。我们希望PLMs不仅在单一的下游任务上拥有好的表现,更希望PLMs在没有见过的其他任务上,改善在zero-shot场景下的性能,使得模型具有一定的任务泛化(task generalization)的能力。
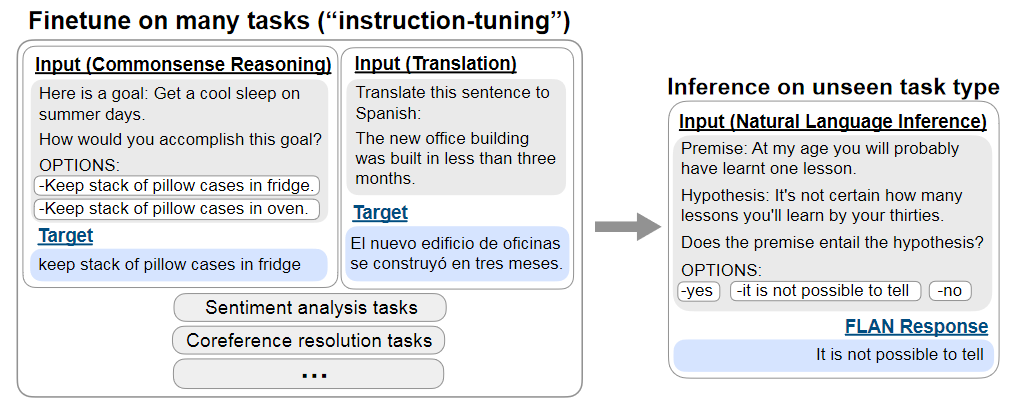
每一个NLP任务可以通过自然语言的指令(instruction)来描述,比如 “Is the sentiment of this movie review positive or negative?” 或者 “Translate ‘how are you’ into Chinese.”,分别对应情感分类和文本翻译任务。Instruction Tuning就是在大量数据集上,给模型下不同的任务指令来微调模型的参数。
(3)Chain of Thought(C.o.T)
Chain of Thought的出现源自于我们对于PLMs的推理能力(reasoning abilities)的期望。
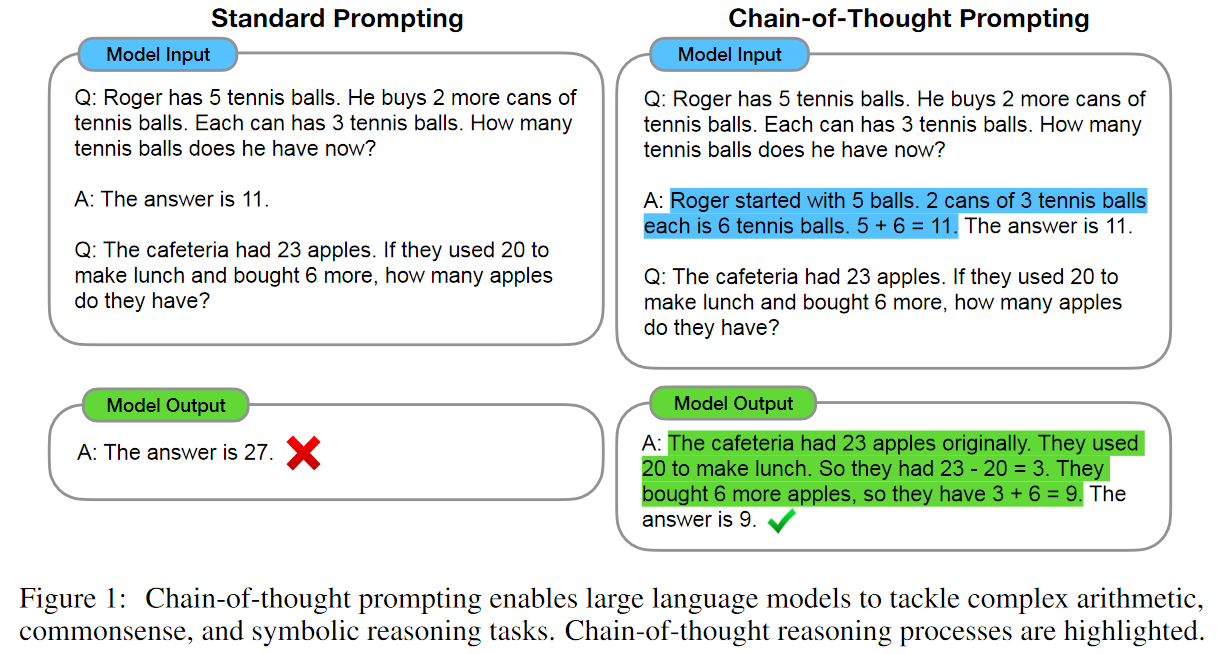
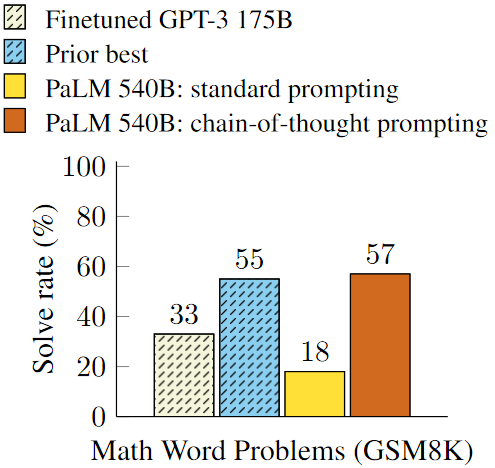
其思想非常的简单,就是在prompting的时候不但给出问题答案,还给出问题答案的推理过程。就这么一个简单的改变,模型的推理能力就起飞了,如下图。
甚至还有更加离谱的在zero-shot场景下的C.o.T,仅仅通过告诉模型Let's think step by step.,模型的推理能力都能获得较大的提升。

具体论文参见Large Language Models are Zero-Shot Reasoners。
(4)Least-to-Most prompting
least-to-most prompting也是为了提升PLMs的推理能力。其基本思想就是将一个复杂的问题拆分成一系列简单的子问题,然后分别解决每一个子问题。
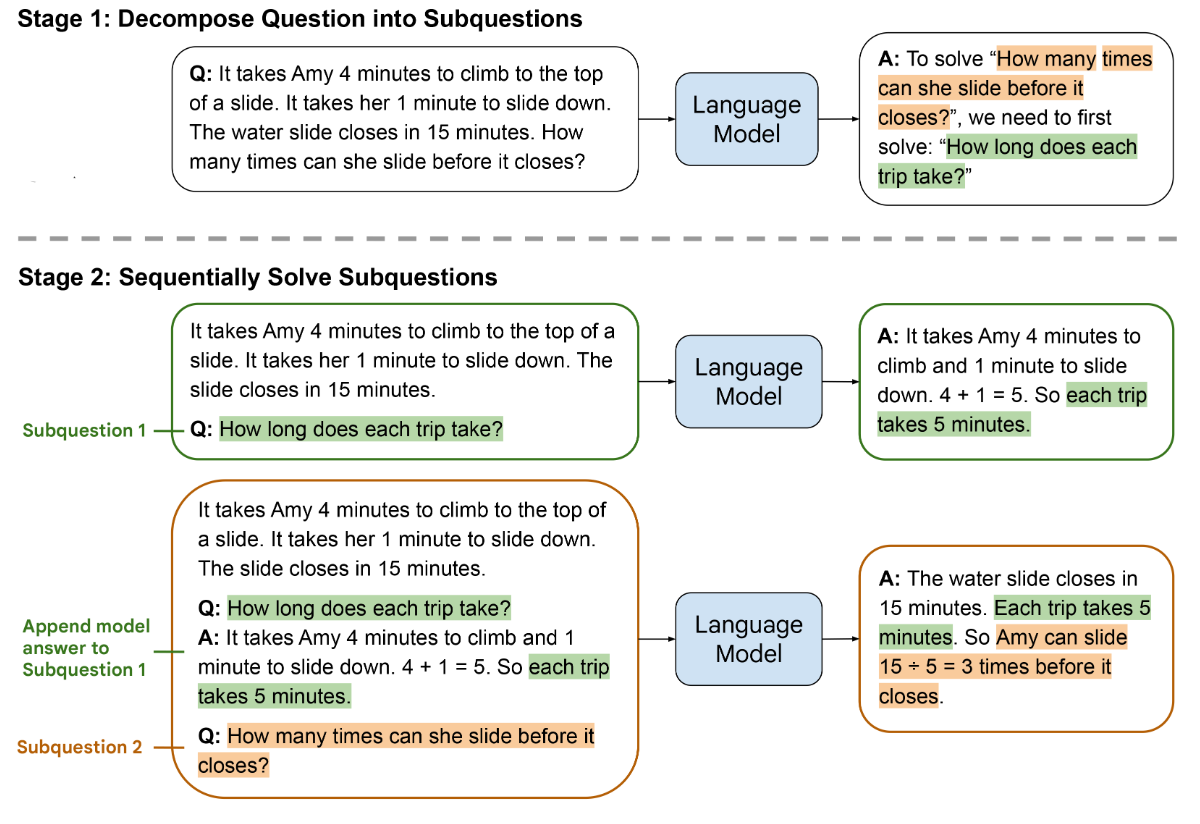
第一步的拆分过程的实现其实就是In-Context Learning的过程,通过一组已拆分的示例(demonstrations)来告诉模型如何拆分。
具体论文参见Least-to-Most Prompting Enables Complex Reasoning in Large Language Models。
over.


















 1299
1299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









