









softmax:(取得正数)
θ为神经网络结构的参数
策略网络pi(a|S,θ)
概率总和为1

2.状态价值state-value:

3.judge通过J(θ)(即为状态价值函数的期望)来评测网络决策

4.策略梯度(研究θ和通过梯度上升来优化θ)
上升梯度(policy gradient ascent)
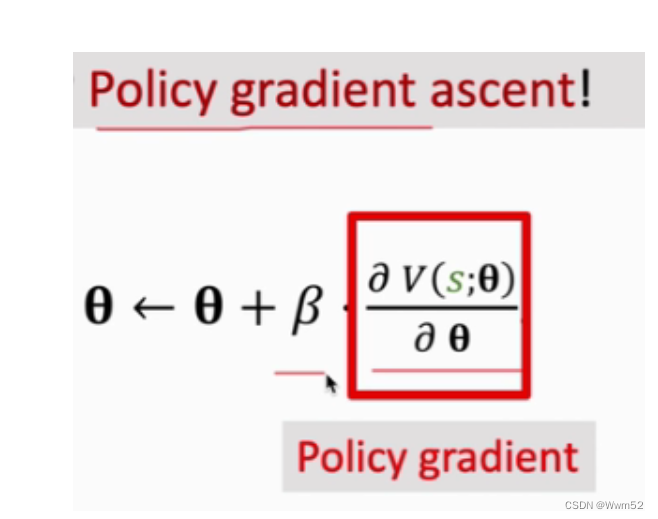
策略梯度两种求算公式:

第一种是用于求可以数的清楚的actions,把每个action算出来再相加;
例如: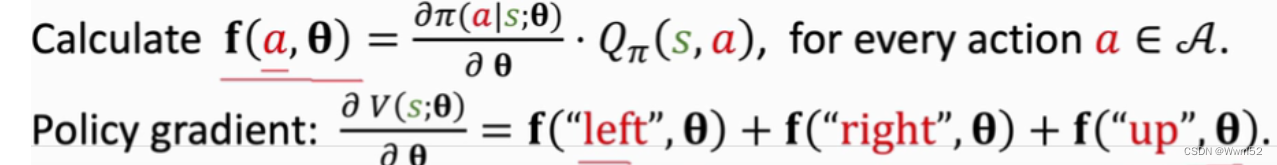
第二个是连续的动作
5.总结梯度

β是学习率;
此外:(alpha和sarsa里有用到)
Loss里的变量也就是TDerror=真实值-测量值;
















 5480
5480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









