







1 policy network VS value-based network

2 policy network的目标函数
记回报 U t 是从 t 从时刻开始的所有奖励之和。U t 依赖于 t 时刻开始的所有状态和动作:
动作价值函数把 t 时刻状态 st 和动作 at 看做已知观测值,把 t + 1 时刻后的状态和动作看做
未知变量,求期望:
状态价值函数把 t 时刻状态 st 看做已知观测值,t时刻的action是服从策略的随机变量,对其求期望
于是policy network的目标函数为:


和强化学习笔记:Policy-based Approach_UQI-LIUWJ的博客-CSDN博客一样,我们对目标函数进行梯度上升,更新参数
![]()
其中 被称为策略梯度
被称为策略梯度
其中通过推导,可以得到策略梯度为:
 但如果状态S服从马尔可夫链的话,前面这一项系数可以去掉,于是有:
但如果状态S服从马尔可夫链的话,前面这一项系数可以去掉,于是有:

注:这种形式和是一样的
2.1 稍为不严谨的证明


第二步可行是因为求导的对象θ和连加的对象a 不同
应用链式法则,公式7.1可以进一步写成:



根据目标函数的定义:

第二项影响不大,所以不严谨的证明中可以把他去掉
所以
2.2 策略梯度的近似
通过前面的推导和证明,我们知道:
解析求出这个期望是不可能的,因为我们并不知道状态 S 概率密度函数;即使我们知道 S 的概率密度函数,能够通过连加或者定积分求出期望,我们也不愿意这样做,因为连加或者定积分的计算量非常大。

我们可以用蒙特卡洛近似策略梯度中的期望:每次从环境中观测到一个状态 s ,它相当于随机变量 S 的观测值。然后再根据当前的策略网络(策略网络的参数必须是最新的)随机抽样得出一个动作: 计算随机梯度,作为
计算随机梯度,作为的无偏估计:

所以我们可以用随机梯度上升来更新θ:
但是这种方法仍然不可行,我们计算不出 g(s, a; θ), 原因在于我们不知道动作价值函数
在后面两节中,我们用两种方法对做近似:
- 一种方法是 REINFORCE,用实际观测的回报 u 近似
- 另一种方法是 Actor-Critic,用神经网络 q(s, a; w) 近似
3 REINFORCE
在2.2 中,我们推导出
但是其中的动作价值函数
REINFORCE进一步对
3.1 简化的推导
3.1.0 引理:策略梯度的连加形式

3.1.1 推导



我们对3.1.0的引理进行蒙特卡洛近似,有:
进一步对
近似,有:

3.2 训练流程




和强化学习笔记:Policy-based Approach_UQI-LIUWJ的博客-CSDN博客中所说的是一样的了:

采样的数据就只会用一次。你把这些数据采样起来,然后拿去更新参数,这些数据就丢掉了。接着再重新采样数据,才能够去更新参数
4 Actor-critic
在上一节中,我们使用实际的回报ut来近似
这一节中,我们使用神经网络来近似
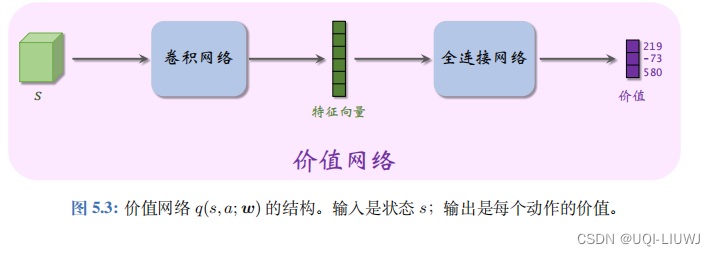
4.1 价值网络

价值网络q(s,a;w)和DQN有相同的结构,但是二者意义不同,训练方式也不同
- 价值网络是对动作价值函数
- 价值网络的训练使用的是 SARSA 算法,它属于同策略,不能用经验回放。对 DQN 的训练使用的是 Q 学习算法,它属于异策略,可以用经验回放。
4.2 算法推导
- 策略网络 π(a|s; θ) 相当于演员,它基于状态 s 做出动作 a。
- 价值网络 q(s, a; w) 相当于评委,它给演员的表现打分,量化在状态 s 的情况下做出动作 a 的好坏程度。

4.2.1 为什么不直接把奖励R反馈给策略网络?
- 原因是这样的。策略学习的目标函数 J(θ) 是回报 U 的期望,而不是奖励 R 的期望
- 注意回报 U 和奖励 R 的区别。
- 虽然能观测到当前的奖励 R,但是它对策略网络是毫无意义的;训练策略网络需要的是回报 U,而不是奖励 R。
- 价值网络能够估算出回报 U 的期望,因此能帮助训练策略网络
4.2.2 训练策略网络
- 在策略网络做出动作a之后,价值网络会给一个分数q(s,a;w)
- 策略网络利用当前状态s,自己的动作a,以及价值网络的打分q(s,a;w),计算近似策略梯度

- 然后用梯度上升更新参数

4.2.3 训练价值网络
- 我们需要让价值网络反应出真实的
- 可以使用SARSA更新w
- 每一次从环境中观测到一个奖励r,用这个r来校准价值网络的打分
- 在t时刻,价值网络输出
,这个是对动作价值函数
的估计
- 在t+1时刻,观测到的是
,所以可以计算TD目标
![]()
- 这也是对动作价值函数

- 进行梯度下降更新

不难看出,也就是强化学习笔记:Sarsa算法_UQI-LIUWJ的博客-CSDN博客_sarsa算法
中的流程
4.3 actor-critic整理训练流程
设当前策略网络参数是,价值网络参数是






- 8 执行
,进行下一轮更新
4.4 用目标网络改进训练
由于sarsa中也存在自举的问题,所以我们可以使用目标网络来缓解自举带来的偏差
那么此时,流程变成:
上面这几步和不用目标网络一样

这两步是引入目标网络后不一样的地方了

上面这几步和不用目标网络一样


这步是引入目标网络后不一样的地方

5 关于经验回放的一个疑问(欢迎讨论)
在学习了DPG确定策略梯度后,有一个小问题想和大家探讨一下:就是像SARSA这样的同策略,就算是用了经验回放,会有很大的影响嘛?
因为我更新sarsa的五元组里面,受到策略
影响的就是
,
是已知,
是和环境交互的结果,与策略
关系不大。
策略输出的是基于
的action的一个概率分布。换句话说,不管 策略
的参数是什么,某一个动作a都能取到,只不过是取到的概率的不同。
那么这样的话,我agent实时交互得到动作和使用过去的经验
,有什么区别嘛?(因为 策略
参数的变动,影响的也只是取到 动作
的概率,不代表
参数更新后,
取不到啊。。。)
那这样的话,我像SARSA这样的同策略模型,也不是不可以使用经验回放?















 2995
2995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











