







本文主要参考的文档:tutorial/lmdeploy/lmdeploy.md at main · InternLM/tutorial (github.com)
目录
编辑 2.3 核心功能——推理服务 (api server)
3.3 TurboMind 推理 + Python 代码集成
1 大模型部署背景
将训练好的模型在特定软硬件环境中启动的过程,使模型能够接收输入并返回预测结果
为了满足性能和效率的需求,常常需要对模型进行优化,例如模型压缩和硬件加速。产品的形态包括云端、边缘计算端、移动端等,计算设备包括CPU、GPU、NPU、TPU等。大模型的内存开销巨大,不光是模型本身占显存,在推理生过程中也会占用一定的显存资源。针对这个问题,研究提出了很多优化的方案,由于其较为灵活,很难做到精确地估算,这里给出一个参数量和显存占用换算的参考大模型参数量和占的显存怎么换算?由于大模型采用自回归生成token,需要缓存Attention的k/v,这也会带来巨大的内存开销。大模型结构虽然很深但是架构比较简单,主流的大模型均是Decoder-Only结构。
大模型的部署充满挑战,存储的需求给设备提出了很高的要求。算力即基础也决定了推理服务响应速度,如何在有限的设备条件基础上优化管理和利用内存,提高响应速度,是大模型部署需要解决的问题。具体的优化方案和策略将在接下来的内容中介绍。
2 LMDeploy 简介
LMDeploy简介如图,项目地址:
官方推理性能:
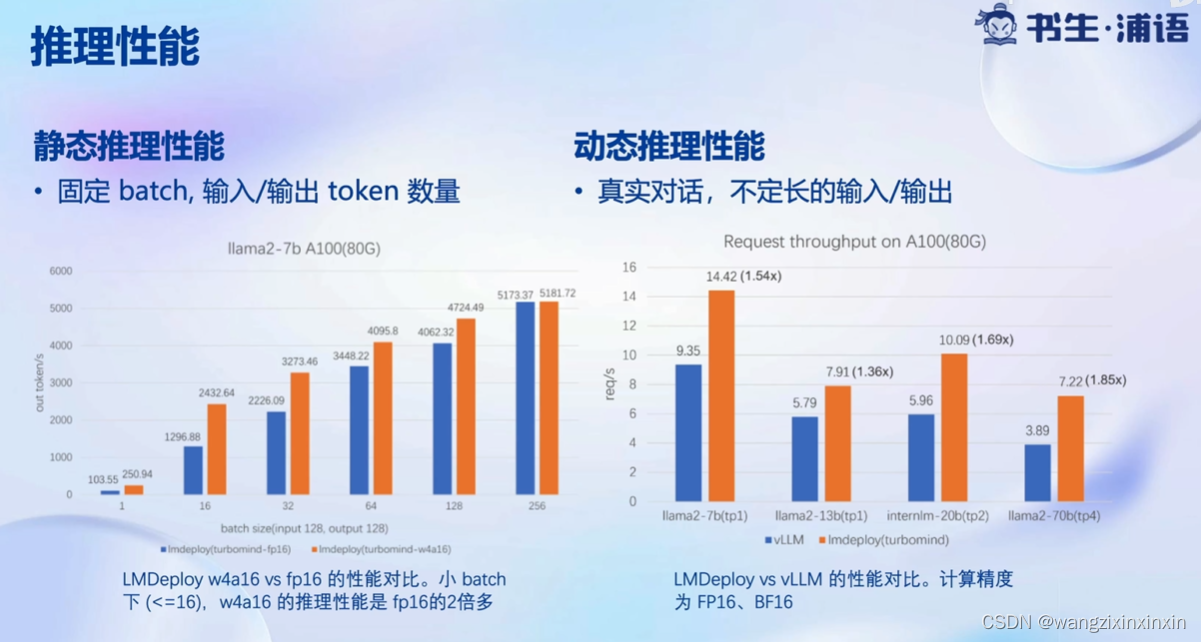
其中vLLM也是一个高通量、低资源占用的大模型推理服务引擎。

2.1 核心功能——量化
为什么要做Weight Only的量化?首先介绍两个基本概念:
计算密集 (compute-bound) : 推理的绝大部分时间消耗在数值计算上针对计算密集场景,通过使用更快的硬件计算单元来提升计算速度比如量化为 W8A8 使用 INT8 Tensor Core 来加速计算。
访存密集 (memory-bound) : 推里时,绝大部分时间消耗在数据读取上;针对访存密集型场景,一般是通过提高计算访存比来提升性能。
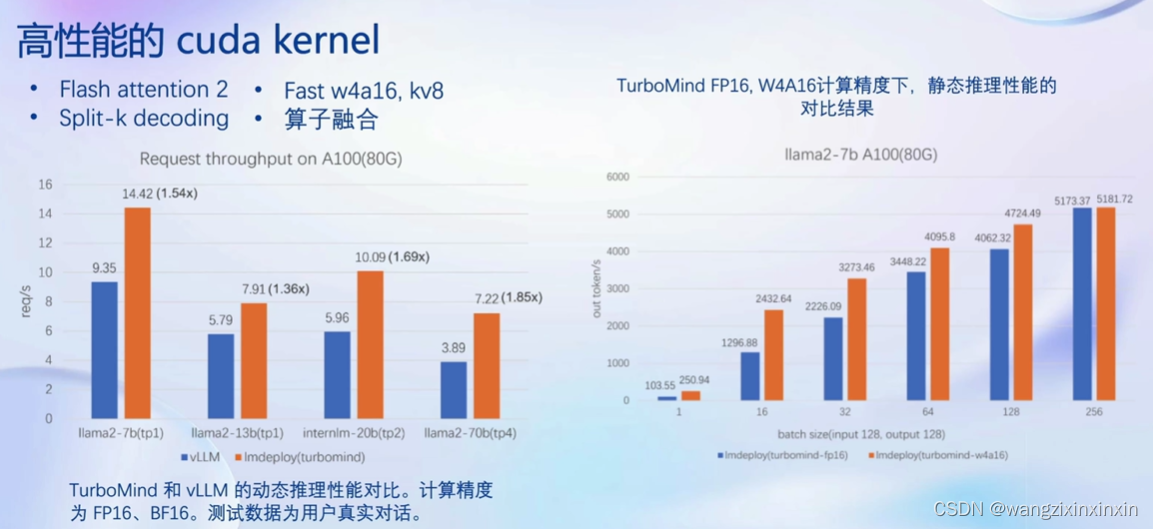
LLM 是典型的访存密集型任务常见的 LLM 模型是 Decoder Only 架构。推理时大部分时间消耗在逐Token 生成阶段 (Decoding 阶段) ,是典型的访存密集型场景。如右图,A100 的 FP16 峰值算力为 312 TFLOPS,只有在 Batch Size 达到128 这个量级时,计算才成为推理的瓶颈,但由于 LLM 模型本身就很大推理时的 KV Cache 也会占用很多显存,还有一些其他的因素影响 (如Persistent Batch) ,实际推理时很难做到 128 这么大的 Batch Size:

基于此,Weight Only 量化一举两得。4bit Weight Only 量化,将 FP16 的模型权重量化为INT4,访存量直接降为 FP16 模型的 1/4,大幅降低了访存成本,提高了 Decoding 的速度。加速的同时还节省了显存,同样的设备能够支持更大的模型以及更长的对话长度。即降低显存占用并提示了推理的速度。
LMDeloy使用MIT HAN LAB开源的AWQ算法AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration。相较于社区使用比较多的GPTQ算法,其推理速度更快,量化的时间更短。
2.2 核心功能——推理引擎 (TurboMind)
1)持续批处理:
推理请求首先先加入到请求队列中。Persistent 线程:
1. 若 batch 中有空闲槽位,从队列拉取请求,尽量填满空闲槽位。若无,继续对当前 batch 中的请求进行forward。
2. Batch每forward完一次判断是否有request 推理结束。结束的request,发送结果,释放槽位,转步骤 1。
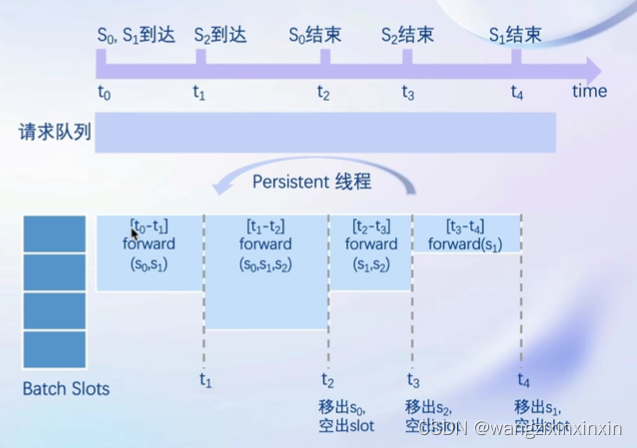
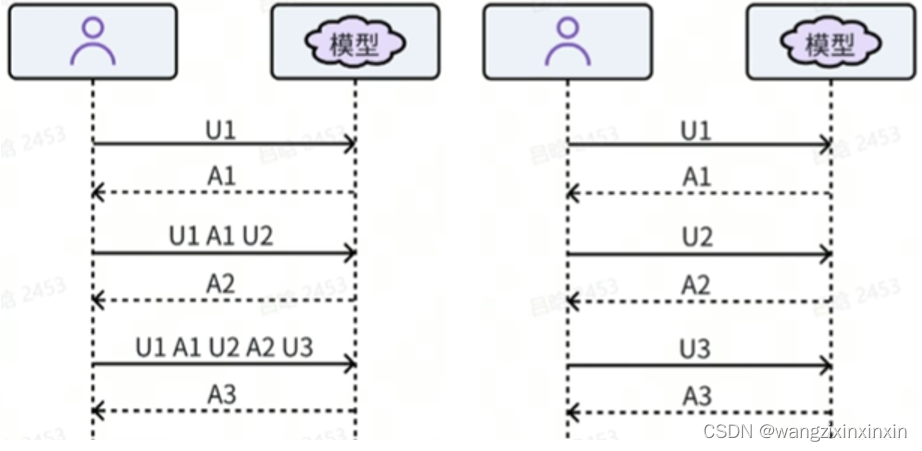
2)有状态推理
左图:无状态推理,每次用户请求均需要携带历史对话记录。
右图:有状态推理,请求不带历史记录,历史记录了推理侧缓存。
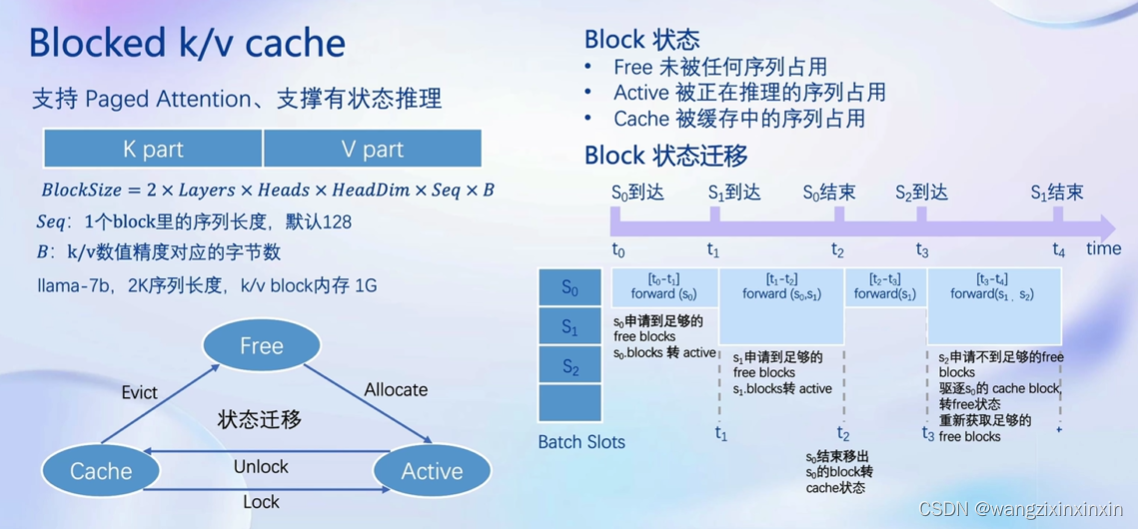
3)Blocked k/v cache
4)高性能的cuda kernel
 2.3 核心功能——推理服务 (api server)
2.3 核心功能——推理服务 (api server)

此部分的实践演示会在第三章完成。
3 LMDeploy实践演示
主要涉及本地推理和部署:
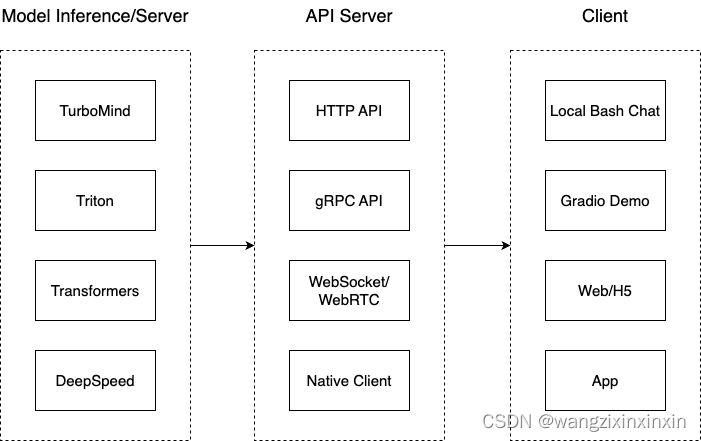
我们把从架构上把整个服务流程分成下面几个模块。 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。 Client。可以理解为前端,与用户交互的地方。 API Server。一般作为前端的后端,提供与产品和服务相关的数据和功能支持。 值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“API Server”合并,有的甚至是三个流程打包在一起提供服务。
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式。结构如图所示:
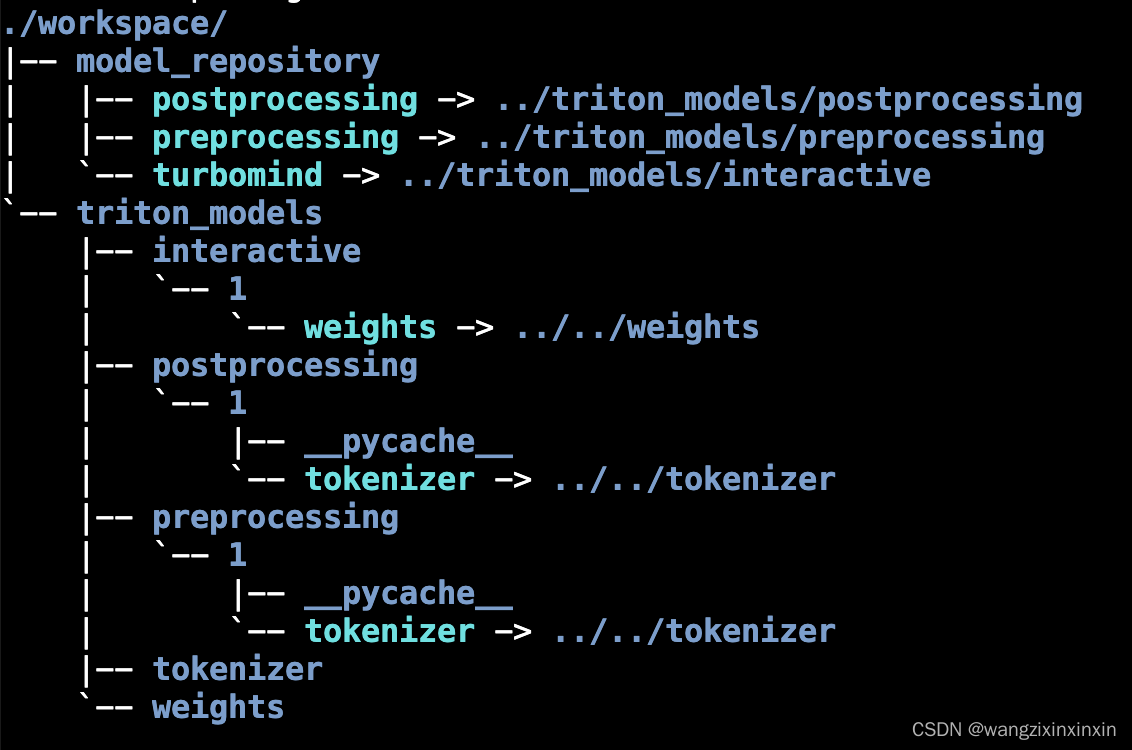
weights 和 tokenizer 目录分别放的是拆分后的参数和 Tokenizer。如果我们进一步查看 weights 的目录,就会发现参数是按层和模块拆开的,如下图所示:
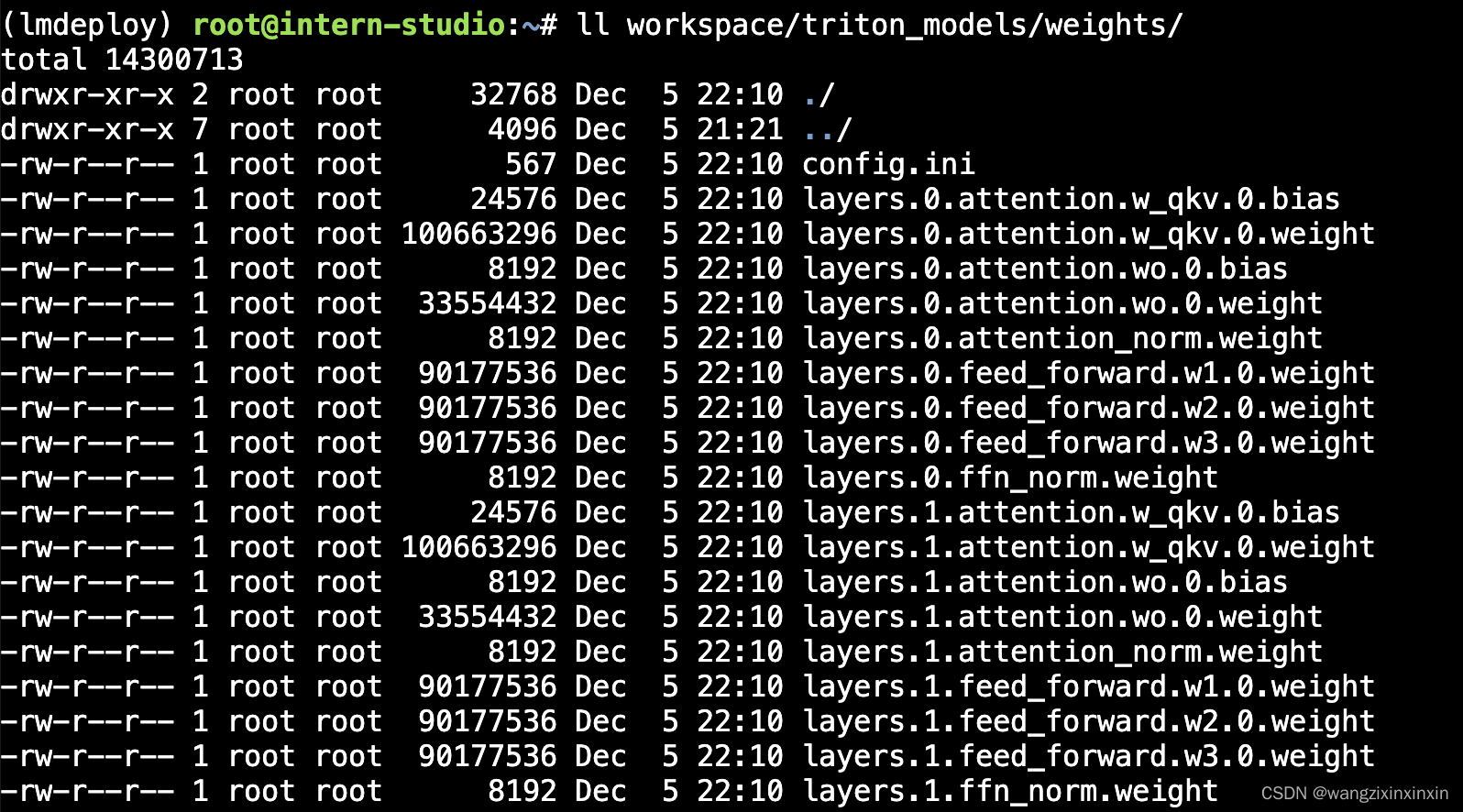 每一份参数第一个 0 表示“层”的索引,后面的那个0表示 Tensor 并行的索引,因为我们只有一张卡,所以被拆分成 1 份。如果有两张卡可以用来推理,则会生成0和1两份,也就是说,会把同一个参数拆成两份。比如 layers.0.attention.w_qkv.0.weight 会变layers.0.attention.w_qkv.0.weight 和 layers.0.attention.w_qkv.1.weight。执行 lmdeploy convert 命令时,可以通过 --tp 指定 (tp 表示 tensor parallel),该参数默认值为1 (也就是一张卡) 。
每一份参数第一个 0 表示“层”的索引,后面的那个0表示 Tensor 并行的索引,因为我们只有一张卡,所以被拆分成 1 份。如果有两张卡可以用来推理,则会生成0和1两份,也就是说,会把同一个参数拆成两份。比如 layers.0.attention.w_qkv.0.weight 会变layers.0.attention.w_qkv.0.weight 和 layers.0.attention.w_qkv.1.weight。执行 lmdeploy convert 命令时,可以通过 --tp 指定 (tp 表示 tensor parallel),该参数默认值为1 (也就是一张卡) 。
3.1 TurboMind 推理+命令行本地对话
一个运行结果的示例如下,可以直观感受到推理速度的提升,几乎可以做到秒级。这对于7b量级模型的部署推理是相当可观的,显存占用约14G:

3.2 TurboMind推理+API服务

 将端口信息转发到本地后,接口文档如图:
将端口信息转发到本地后,接口文档如图:
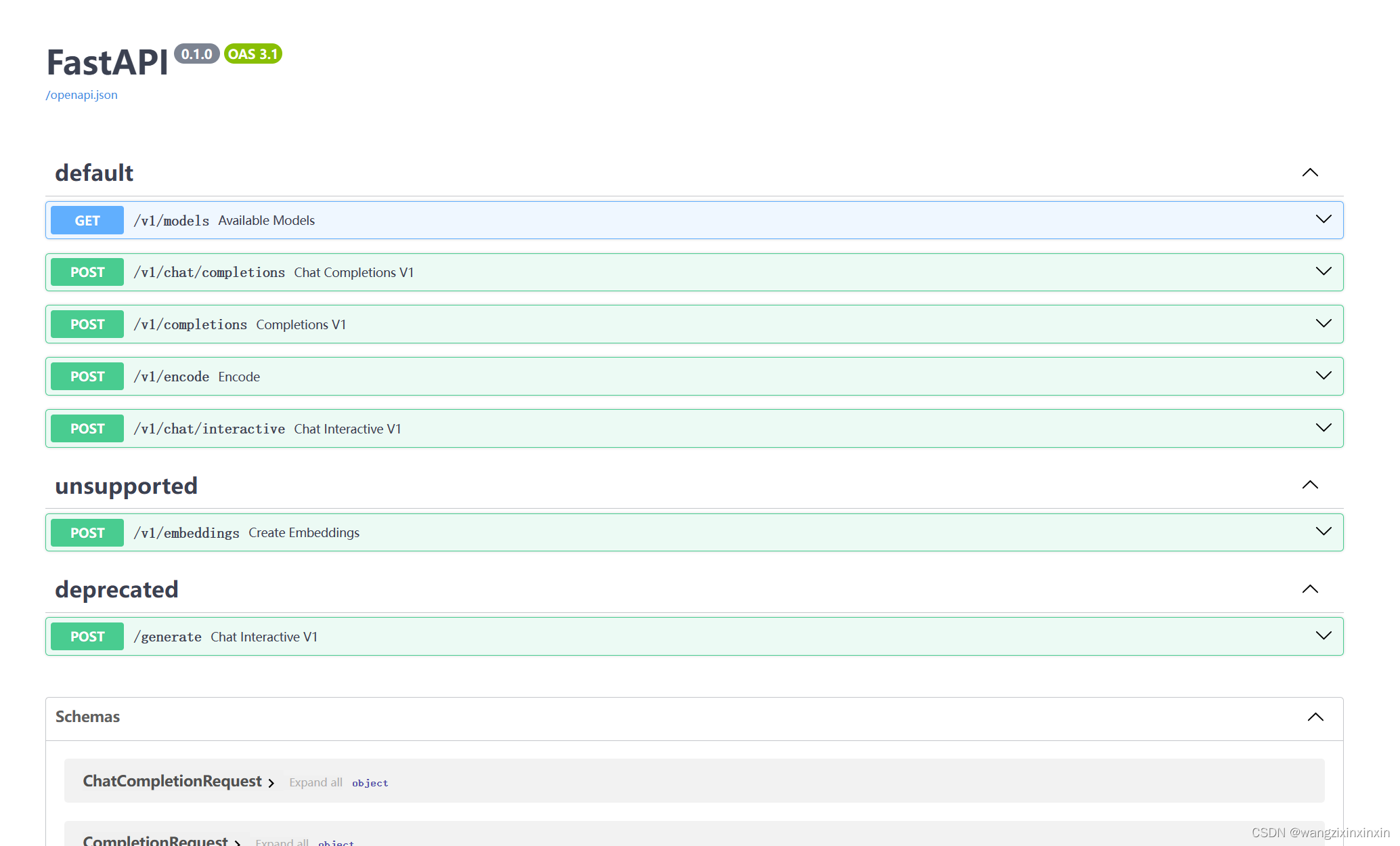 例如其中对话端口的使用示例:
例如其中对话端口的使用示例:
3.3 网页 Demo 演示
3.2.1 TurboMind 服务作为后端

具体效果和3.2.2一致。
3.2.2 TurboMind 推理作为后端
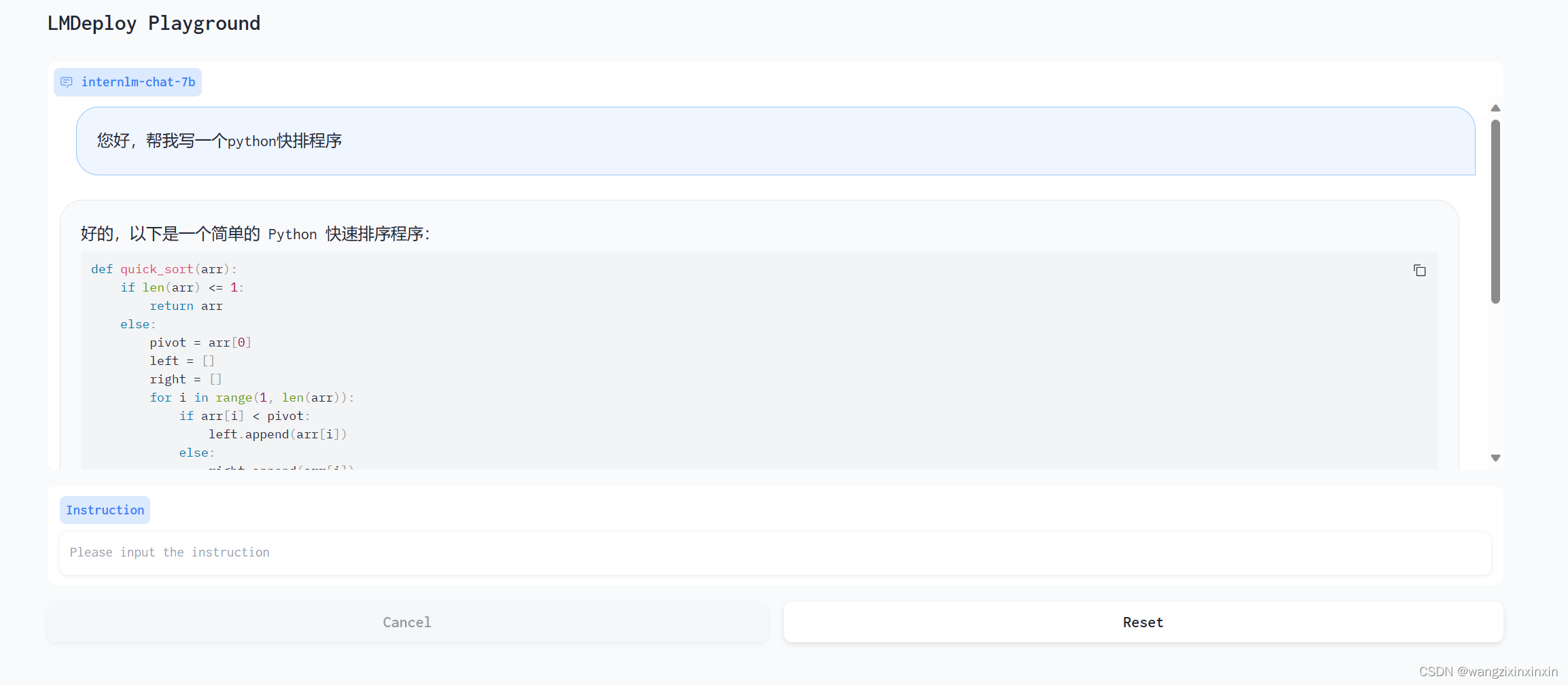
3.3 TurboMind 推理 + Python 代码集成
前面介绍的都是通过 API 或某种前端与”模型推理/服务“进行交互,lmdeploy 还支持 Python 直接与 TurboMind 进行交互,如下所示:
from lmdeploy import turbomind as tm
# load model
model_path = "/root/share/temp/model_repos/internlm-chat-7b/"
tm_model = tm.TurboMind.from_pretrained(model_path, model_name='internlm-chat-20b')
generator = tm_model.create_instance()
# process query
query = "您好!"
prompt = tm_model.model.get_prompt(query)
input_ids = tm_model.tokenizer.encode(prompt)
# inference
for outputs in generator.stream_infer(
session_id=0,
input_ids=[input_ids]):
res, tokens = outputs[0]
response = tm_model.tokenizer.decode(res.tolist())
print(response)3.4 具体实践
3.4.1 方案实践
后面的 API 服务和 Client 就得分场景了。
我想对外提供类似 OpenAI 那样的 HTTP 接口服务。推荐使用 TurboMind推理 + API 服务。 我想做一个演示 Demo,Gradio 无疑是比 Local Chat 更友好的。推荐使用 TurboMind 推理作为后端的Gradio进行演示。
我想直接在自己的 Python 项目中使用大模型功能。推荐使用 TurboMind推理 + Python。
我想在自己的其他非 Python 项目中使用大模型功能。推荐直接通过 HTTP 接口调用服务。也就是用本列表第一条先启动一个 HTTP API 服务,然后在项目中直接调用接口。
3.4.2 模型配置实践
这部分具体参看tutorial/lmdeploy/lmdeploy.md at main · InternLM/tutorial。
3.5 模型量化
3.5.1 KV Cache 量化
KV Cache 量化是将已经生成序列的 KV 变成 Int8,使用过程一共包括三步:
第一步:计算 minmax。主要思路是通过计算给定输入样本在每一层不同位置处计算结果的统计情况。 对于 Attention 的 K 和 V:取每个 Head 各自维度在所有Token的最大、最小和绝对值最大值。对每一层来说,上面三组值都是 (num_heads, head_dim) 的矩阵。这里的统计结果将用于本小节的 KV Cache。 对于模型每层的输入:取对应维度的最大、最小、均值、绝对值最大和绝对值均值。每一层每个位置的输入都有对应的统计值,它们大多是 (hidden_dim) 的一维向量,当然在 FFN 层由于结构是先变宽后恢复,因此恢复的位置维度并不相同。这里的统计结果用于下个小节的模型参数量化,主要用在缩放环节。
第二步:通过 minmax 获取量化参数。主要就是利用下面这个公式,获取每一层的 K V 中心值 (zp) 和缩放值 (scale) 。
第三步:修改配置。也就是修改 weights/config.ini 文件,只需要把 quant_policy 改为 4 即可。这一步需要额外说明的是,如果用的是 TurboMind1.0,还需要修改参数 use_context_fmha,将其改为 0。接下来就可以正常运行前面的各种服务了,只不过咱们现在可是用上了 KV Cache 量化,能更省 (运行时) 显存了。官方量化效果如图:

3.5.2 W4A16 量化
W4A16中的A是指Activation,保持FP16,只对参数进行 4bit 量化。使用过程也可以看作是三步。
第一步:不再赘述。
第二步:量化权重模型。利用第一步得到的统计值对参数进行量化,具体又包括两小步: 缩放参数。主要是性能上的考虑。
最后一步:转换成 TurboMind 格式。
量化效果:
















 1377
1377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









