




LMDeploy 大模型量化部署实践
视频地址:https://www.bilibili.com/video/BV1iW4y1A77P
文档:https://github.com/InternLM/tutorial/blob/vansin-patch-4/lmdeploy/lmdeploy.md
LMDeploy Repo: https://github.com/InternLM/lmdeploy.git
主要内容
包括三个部分,1. 背景,2. LMDeploy 简介,3. 动手实践

大模型部署背景

7B 模型参数内存:7 * 1B * 2 (fp16) = 7 * 1G * 2 Byte = 14G Byte

LMDeploy 简介

下图中,左边主要对比 LMDeploy 自身在量化前后的性能;右边主要对比 vLLM 和 LMDeploy 的性能对比。
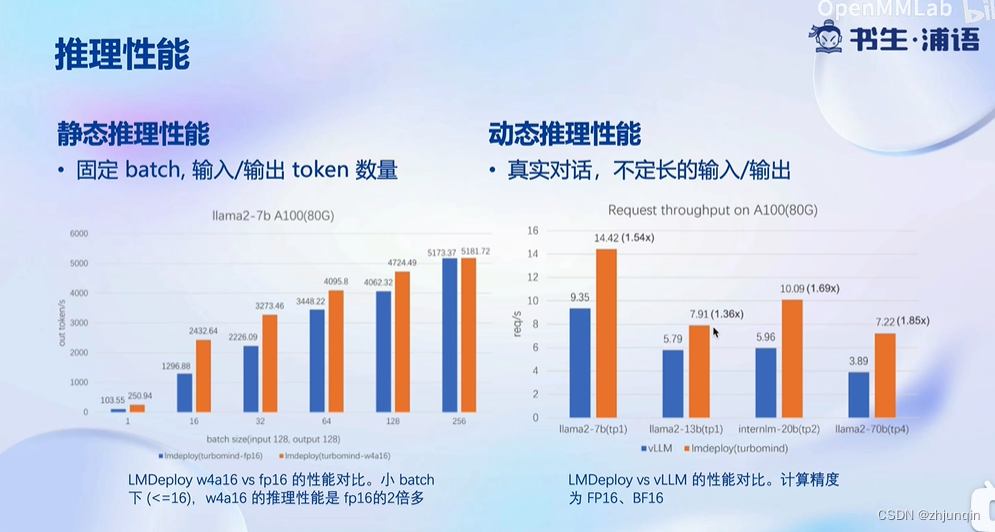
量化后,显存占用量显著减少,其中包括权重和 KV Cache。
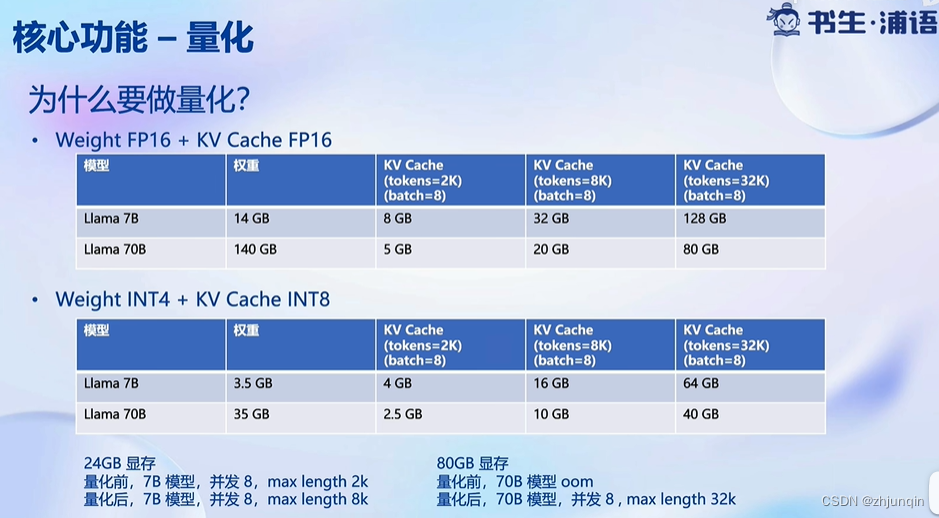
由于 GPU 的计算需要将权重从 GPU 主存 -> GPU 共享内存,因此量化显著减少了数据的传输量,提高了整体效率。

AWQ 算法全称:Activation-aware Weight Quantization
GPTQ 算法全称:Accurate P
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2029
2029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









