





https://blog.csdn.net/mao_feng/article/details/78939864
现实生活中,我们会遇到少量有标签的样本,而大量无标签的样本,怎么去做这个处理呢?
方法1:迁移学习的finetune
找类似的通用数据集(在图像领域:imagenet,电商领域:淘宝电商数据)训练网络,通过修改后面2层或者3层网络,做迁移学习,来微调网络的参数,从而训练模型。
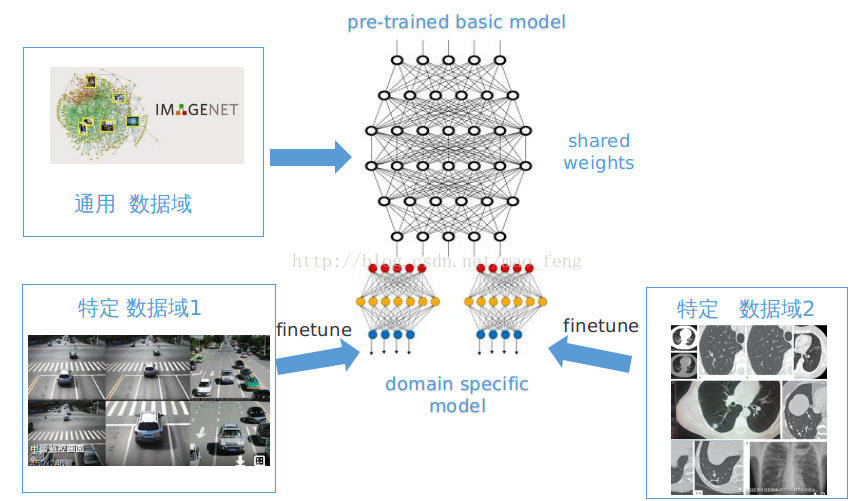
方法2:元学习(meta learning)

https://blog.csdn.net/mao_feng/article/details/78939864
现实生活中,我们会遇到少量有标签的样本,而大量无标签的样本,怎么去做这个处理呢?
方法1:迁移学习的finetune
找类似的通用数据集(在图像领域:imagenet,电商领域:淘宝电商数据)训练网络,通过修改后面2层或者3层网络,做迁移学习,来微调网络的参数,从而训练模型。
方法2:元学习(meta learning)
转载于:https://www.cnblogs.com/ivyharding/p/11455996.html
 5395
2881
4204
5395
2881
4204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























