






Compute Canada平台及其常见命令介绍
前言
大家好,笔者目前身处加拿大,在学习神经网络的过程中由于无法使用国内服务器进行网络的训练和学习,一度感到十分不便。然而,幸运的是,我发现了Compute Canada——这是一个专为科研和学术研究设计的高性能计算平台,非常适合需要进行大规模计算和数据处理的项目,尤其是神经网络的训练。在本文中,笔者将详细介绍这一计算平台的优势,并提供一些实用的操作指令,希望能帮助身处海外的研究人员有效利用该平台。
优势
-
高性能计算资源:Compute Canada 拥有多个节点,每个节点都配备了多个高性能GPU,这使得它非常适合进行神经网络的训练。这些GPU加速的计算节点可以大大缩短训练时间,提高研究效率。
-
广泛的数据管理选项:该平台提供的数据存储和管理服务确保了数据的安全和易于访问,支持复杂的数据分析任务。用户可以轻松地存储、访问和处理大量数据。
-
全面的软件支持:Compute Canada 提供了广泛的软件库,涵盖从机器学习到数据科学的各种工具,这些工具都是预先配置好的,可以直接使用,极大地方便了用户。
-
专业的技术支持和培训:除了硬件资源,Compute Canada 还拥有一支专业的支持团队,他们为用户解决技术问题提供帮助。此外,平台还定期举办培训和研讨会,帮助用户更好地利用这些资源。
使用方法
要开始使用Compute Canada,你首先需要通过其网站进行注册和申请访问权限。一旦获得批准,你就可以开始配置和运行你的计算作业了。关于该平台,有一份官方出具的详细的Wikipedia说明在该网址,是纯英文的,大家可自行阅读。笔者在这里主要介绍是一些常见的命令和操作,可以帮助你开始使用。
1. 检查模块
不带版本号
在加载任何模块之前,我们需要先确认该模块是否存在于 Compute Canada 平台上。我们可以使用以下命令来查询模块的详细信息。以 Python 和 CUDA 为例:
module spider python
module spider cuda
命令一执行结果:
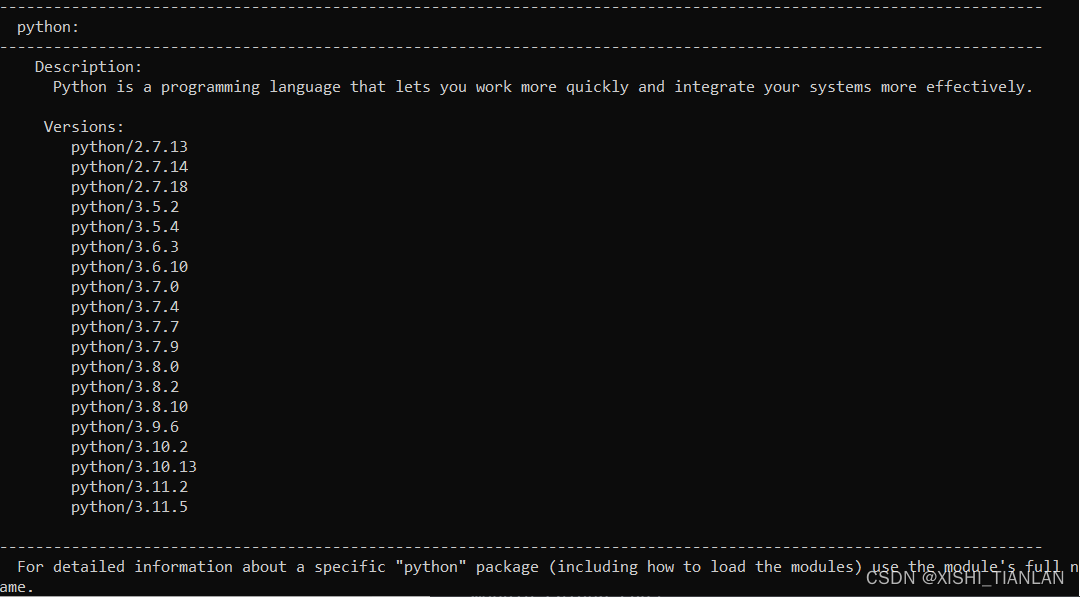
命令二执行结果: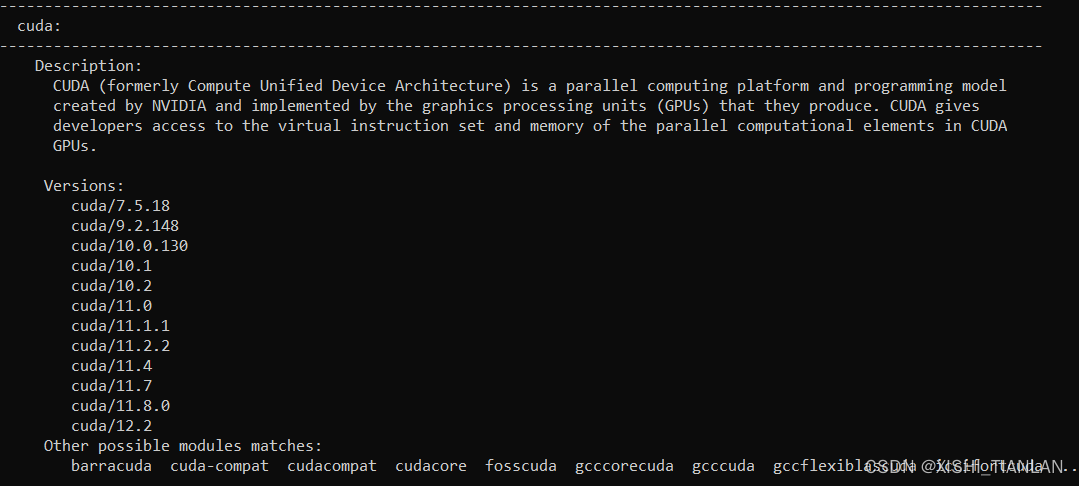
执行上述命令后,你会看到所有可用的模块版本,从中可以选择适合自己的版本进行加载。
带版本号
我们也可以在模块后方加上版本号来进行查询,这样就可以查到我们输入模块的一些安装提示:
module spider python/3.10.13
module spider cuda/12.2
命令一执行结果:
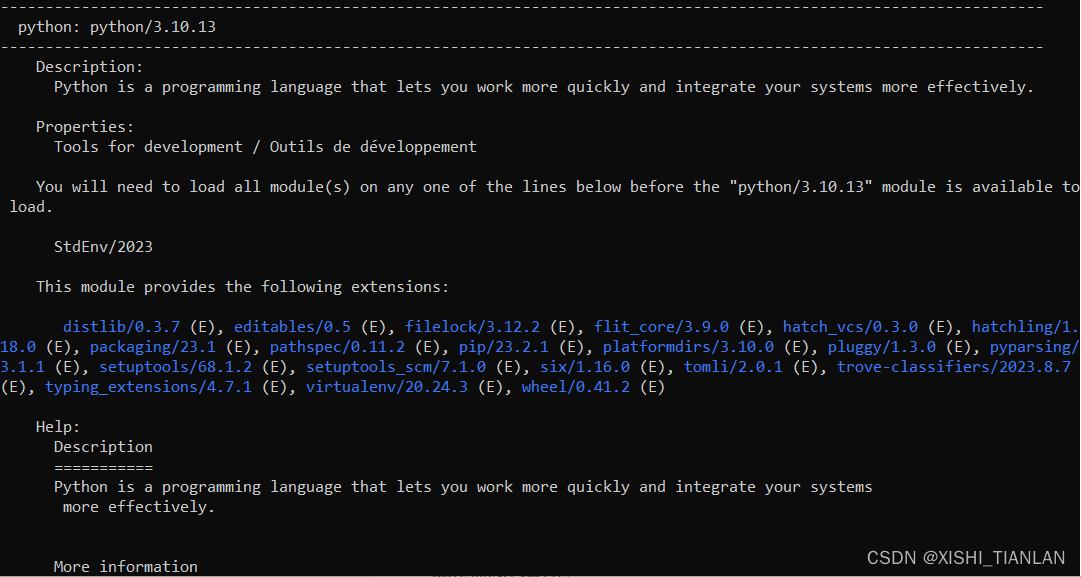
命令二执行结果:
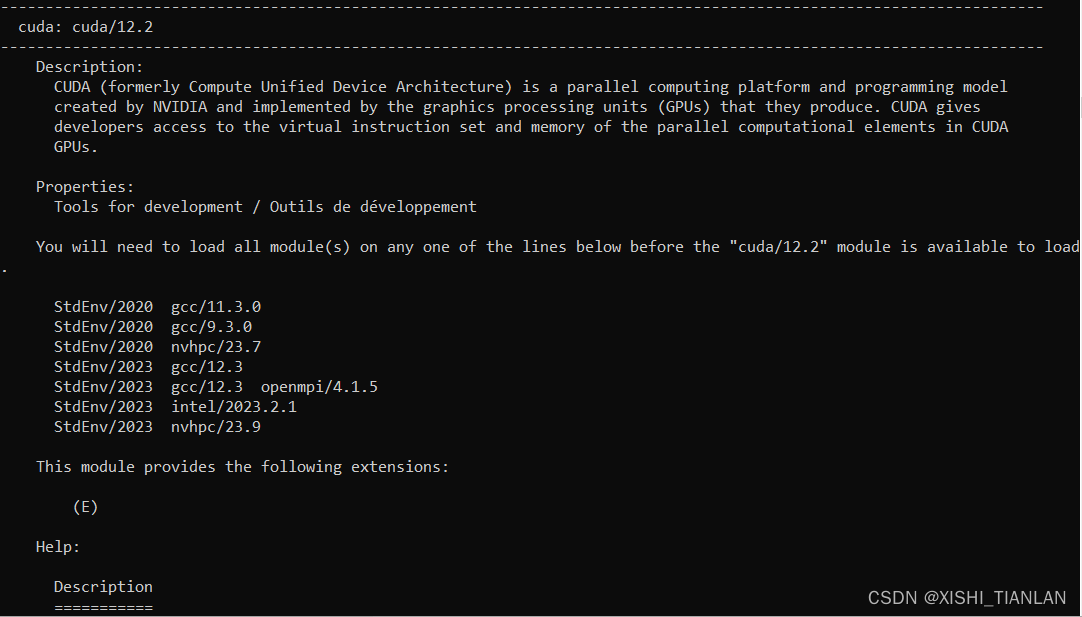
可以看到在加上版本号后执行命令,该命令输出了该模块的定义,属性和安装提示。比如这里就提到了在安装python/3.10.13和cuda/12.2之前需要被安装的一些依赖模块,所有这些模块都要用底下的加载模块命令来进行安装。
2. 加载模块
Compute Canada使用模块环境来管理软件,在检查完模块后你可以使用以下命令来加载你需要的软件模块:
module load python/3.10.13
module load cuda/12.2
3. 检查模块是否加载成功
加载模块后,你可以使用以下命令确认它们已经被正确加载:
module list
执行结果:
会发现我们之前输入的python/3.10.13和cuda/12.2以及所需的依赖项都已经安装在该平台环境下。
4. 创建虚拟环境
在Compute Canada计算平台上也可以添加虚拟环境,,避免版本冲突和依赖问题。但是在该平台上不可以用Anoconda,需要用virtualenv工具创建并启动虚拟环境,命令如下:
virtualenv --no-download <env_name>
source <env_name>/bin/activate
说明:
- virtualenv 是一个工具,用于创建独立的 Python 环境。每个环境都可以有自己的 Python 版本和一组库。
- –no-download 选项阻止 virtualenv 从外部源下载任何包。这在 Compute Canada 上非常重要,因为它确保所有安装都使用本地可用的资源,符合系统的网络限制。
- <env_name> 是你希望给你的虚拟环境命名的名称。你需要替换 <env_name> 为实际的环境名,例如 yolov5_env。
- source 是一个 shell 命令,用于读取指定的 shell 脚本(这里是激活虚拟环境脚本)并在当前环境中执行。
- <env_name>/bin/activate 是虚拟环境中的脚本路径,执行后,所有的 python 和 pip 命令都将指向这个虚拟环境,而不是全局环境。
5. 编写作业脚本
在Compute Canada计算平台山使用了Slurm作业调度系统,需要先编写一个作业脚本,该脚本包括你对运行环境的设置,比如请求多少内存,需要多少GPU等等,还有你需要执行的命令。以下是一个作业脚本的例子:
#!/bin/bash
#SBATCH --job-name=yolov5s
#SBATCH --gres=gpu:1 # 请求 1 个 GPU
#SBATCH --cpus-per-task=4 # 每个 GPU 请求 4 个 CPU 核心
#SBATCH --mem=5G # 请求 5 GB 内存
#SBATCH --time=04:00:00 # 预计运行时间 4 小时
#SBATCH --output=%x-%j.out # 标准输出和错误输出的文件名
module load python/3.10.13 cuda/12.2
source <env_name>/bin/activate
# 运行 YOLOv5 训练脚本
python train.py --img 640 --batch 16 --epochs 3 --data dataset.yaml --weights yolov5s.pt
说明:
- #!/bin/bash - 这行指明了脚本应该使用 Bash shell 来执行。
- #SBATCH --job-name=yolov5s - 这行为作业设置了一个名称 “yolov5s”,这有助于在作业监控时识别该作业。
- #SBATCH --gres=gpu:1 - 请求 1 个 GPU 设备。gres 表示“通用资源”(Generic RESource),用来请求特定类型的资源,这里是 GPU。
- #SBATCH --cpus-per-task=4 - 为作业请求 4 个 CPU 核心。通常,每个 GPU 需要足够的 CPU 核心来支持其运算。
- #SBATCH --mem=5G - 请求 5 GB 的内存。内存请求应根据作业的需求来定。
- #SBATCH --time=04:00:00 - 设置作业的预期运行时间为 4 小时。这有助于调度器管理资源。
- #SBATCH --output=%x-%j.out - 指定了标准输出和标准错误输出的文件名。%x 是作业名称,%j 是作业 ID。
- module load python/3.10.13 cuda/12.2 - 加载必要的模块。
- source <env_name>/bin/activate - 激活一个指定的 Python 虚拟环境。替换 <env_name> 为你创建的虚拟环境的名称。
- python train.py --img 640 --batch 16 --epochs 3 --data dataset.yaml --weights yolov5s.pt - 运行 YOLOv5s 的训练脚本。参数包括图像尺寸(640x640 像素),批量大小为 16,训练 3 个周期,使用 dataset.yaml 文件指定的数据集,以及从 yolov5s.pt 权重文件开始训练。
注意:脚本文件中必须要有一个#SBATCH --account=xxxxxx,这通常与学术或研究环境中的担保人或主要研究者有关。相关的介绍放在“注意”部分。
另外,还可以在脚本中添加邮箱地址来设置作业结束邮件通知。这样在作业完成或出错时,你会收到通知:
#SBATCH --mail-type=END,FAIL
#SBATCH --mail-user=your_email_address
6. 提交作业
编写完作业脚本job_script.sh,确认无误后就可以使用sbatch命令提交你的作业:
sbatch job_script.sh
执行结果为submitted则代表执行成功,job后面就是提交的作业id:

7. 监控作业状态
提交作业后,你可以使用squeue命令查看你的作业状态,[your-username] 代表目前使用该平台的账户名:
squeue -u [your-username]
执行结果:

说明:
- JOBID: 作业的唯一标识号。这个编号用于管理作业,如取消、暂停或重新提交。
- USER: 提交作业的用户的用户名。
- ACCOUNT: 作业使用的账户或项目标识,表明作业是在这个项目账户下运行。
- NAME: 作业的名称,这里是 yolov5_training。这个名称是在作业脚本中通过
#SBATCH --job-name参数设置的。 - ST (State): 表示作业的当前状态。PD 表示作业处于挂起(Pending)状态,等待资源分配。作业会在资源(如CPU、GPU、内存)可用时开始运行。
- TIME_LEFT: 作业预计剩余的运行时间。这里显示为 4:00:00,表示作业还有最多4个小时的时间可以运行。
- NODES: 作业请求的节点数。这里是 1,表示作业需要1个计算节点。
- CPUS: 作业请求的CPU核数。这里是 4,表示作业分配到了4个CPU核。
- TRES_PER_N: 表示作业请求的其他计算资源,这里的 gres:gpu:t 是一个格式问题,通常应该显示为如 gres:gpu:1,表明请求了1个GPU。
- MIN_MEM: 作业请求的最小内存。这里是 5G,表示作业至少需要5GB内存。
- NODELIST (REASON): 显示分配给作业的节点列表或作业未运行的原因。这里的 (Priority) 表示作业正在等待队列中,根据调度策略等待被调度运行。通常,这与作业的优先级和资源的可用性有关。
8. 查看作业开始预计时间
在作业提交后需要排队,此时可以用以下命令查看可能的开始时间:
squeue --start -j <job_id>
9. 查看作业的详细输出
可以用以下命令查看作业的输出信息:
sacct -j <job_id> --long
sacct -j job_id --format=JobID,JobName,State,ExitCode
10. 取消作业
使用 scancel 命令加上你的作业 ID 来取消作业,再次sbatch可以重新提交脚本。
scancel <job_id>
注意
在Compute Canada注册账户通常需要有一个担保人(sponsor)。这里的担保人通常是指一个已经在Compute Canada系统中注册并具有资格的研究人员,如大学教授或研究机构的科研人员。担保人负责验证用户的身份和研究需求的合法性,并在某种程度上对使用者使用Compute Canada资源的行为负责。这也就对应了必须出现在slurm执行脚本里的account。
因此,如果你计划注册Compute Canada并使用其资源,最好提前与可能的担保人讨论并获得其同意,确保注册流程顺利进行。如果你没有直接联系人,可以考虑联系你所在机构的信息技术部门或研究支持部门,他们可能能提供帮助或建议合适的担保人。
结语
通过有效地利用Compute Canada的资源,你可以为你的神经网络训练提供强大的计算支持,加快研究进度,提高学习效率。希望这个介绍能帮助你开始在Compute Canada上进行你的研究工作。希望大家在深度学习上的学习和研究之路都一切顺利!














 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









