







该文章主要工作如下:
1.使用神经网络,直接在小波域内学习条纹噪声的特征,使之能够根据精确的和自适应的估计噪声的强弱和分布。
2.提出了一种directional regularizer(我在这里叫做定向正则化,是一个损失函数),能够避免模型产生不规则的条纹,以及将条纹噪声和图像中的细节更准确的分开。
3.利用小波分解将图像转换成四个小波子带。每个子带都代表着图像中的某一种特征。有利于提高计算效率和去条纹的能力
条纹噪声性质分
本文的目的是要得到去条纹性能更好的方法,首先对条纹噪声的性质进行了分析。
条纹噪声比较明显的性质就是方向性。

如图所示,对噪声图像进行梯度计算。对图像进行梯度运算,是捕获图像轮廓的一种方法,计算图像不同方向的梯度,可以加深图像中不同方向的轮廓线条。水平方向的梯度加强垂直方向的线条;垂直方向的梯度加强水平方向的轮廓线条。从图中可以看出,条纹噪声对图像垂直方向的轮廓线条有严重的干扰。所以,从方向梯度的视角来进行图像去噪或许是可行的。
哈尔离散小波变换能够较好的提取图像中的高频信息(从水平、垂直、对角方向),也能够在低频子带中维持图像的结构(说人话就是和原图像相差不大)。

这幅图就是对图像进行哈尔小波变换,(b)图就是低频子带,可以看出和原图像几乎没差。其余的三幅图像分别是提取到图像的水平、垂直、对角子带。
模型框架
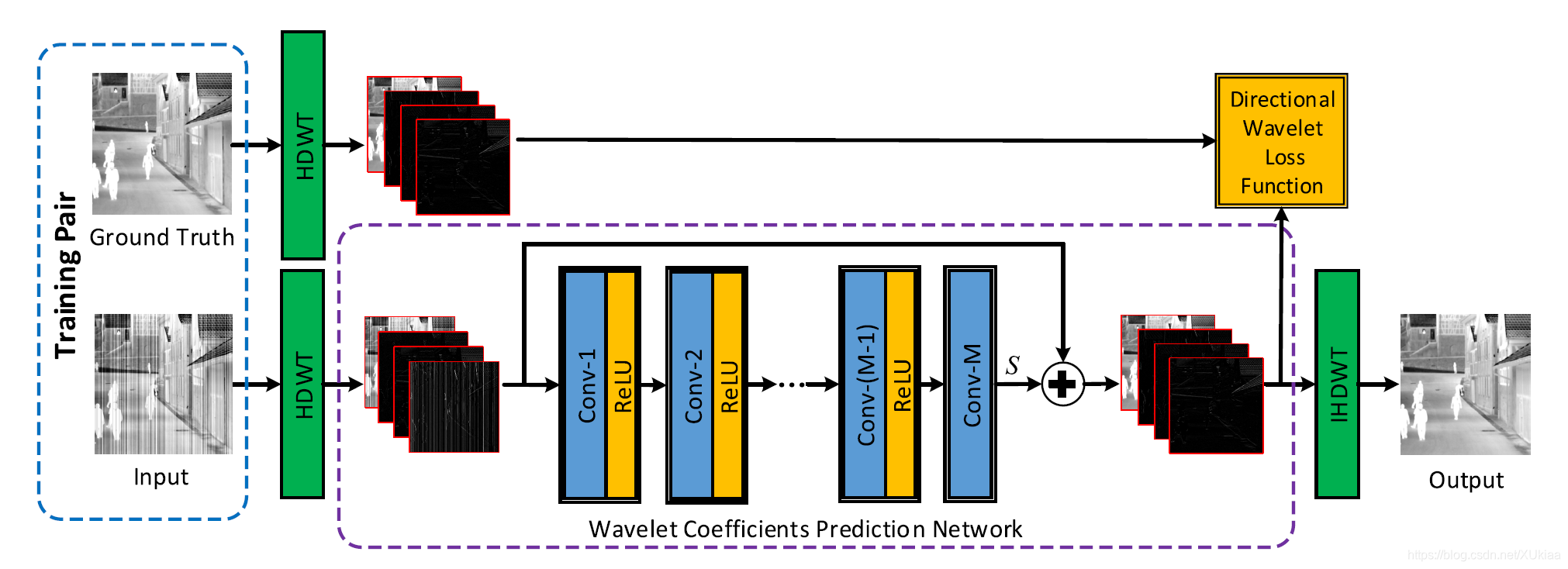 本文把去条纹看作是在小波域预测转换系数的问题(这里说的转换系数可能就是指不同的子带)。
本文把去条纹看作是在小波域预测转换系数的问题(这里说的转换系数可能就是指不同的子带)。
该框架由三部分组成:哈尔离散小波变换、转换系数预测、哈尔离散小波逆变换。
首先,利用哈尔离散小波变换得到四个子带系数。
然后利用神经网络估计残差,也就是图像噪声部分。这部分使用了残差学习,能够加快网络的训练速度。然后将输入的四个子带与网络的输出结果做运算,生成去条纹的四个子带系数。
最后使用小波逆变换得到去噪后的图像。

这一段描述的是神经网络的结构,懒得翻译了。
损失函数
在基于深度学习的图像去噪算法中,大多使用
MSE
(
最
小
均
方
误
差
)
\textbf{MSE}(最小均方误差)
MSE(最小均方误差)作为损失函数。本文也采用这种方法,但是本文的神经网络训练的是小波子带的残差,而不是图像的,所以需要对这个函数进行改进,使其能够适用于本文。
该损失函数被叫做小波最小均方误差损失(wavelet MSE loss),函数形式如下:
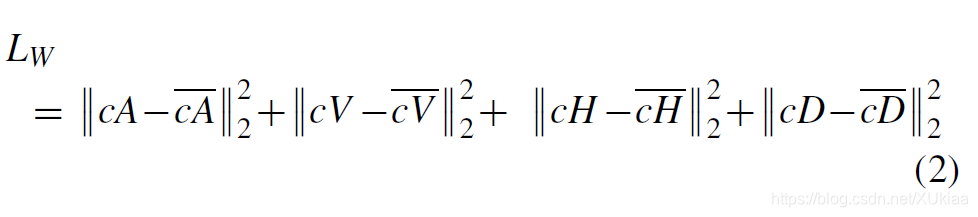
c A , c V , c H , c D cA,cV,cH,cD cA,cV,cH,cD分别为无噪声图像的近似、垂直、水平、对角系数子带。 c A ˉ , c V ˉ , c H ˉ , c D ˉ \bar{cA},\bar{cV},\bar{cH},\bar{cD} cAˉ,cVˉ,cHˉ,cDˉ为想对应的估计系数。
从局部的角度来看,单个条纹内像素强度的变化较小,说明在沿着条纹方向上有较好的平滑性。
通过最小化条纹相关子带中估计条纹分量方向上的偏差来描述平滑度,在本文中构建了方向正则化方法。
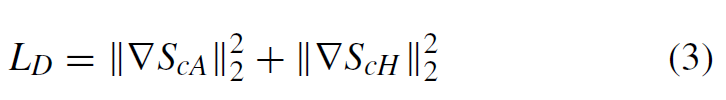 ∇
S
c
A
\nabla{S_{cA}}
∇ScA和
∇
S
c
H
\nabla{S_{cH}}
∇ScH是近似子带系数和水平子带系数在估计的子带系数和无噪声子带系数之间的差异。
∇
S
c
A
\nabla{S_{cA}}
∇ScA和
∇
S
c
H
\nabla{S_{cH}}
∇ScH是近似子带系数和水平子带系数在估计的子带系数和无噪声子带系数之间的差异。
综上,该网络的损失函数定义为
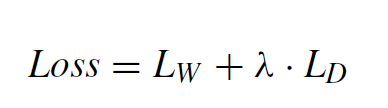
λ
\lambda
λ为超参数。
可以对损失函数做一个解释:因为条纹噪声对图像近似和水平子带影响较大。在损失函数中额外增加这两个子带的损失,能够使这两个子带有更好的预测效果。(好像感觉越解释越乱)
训练策略
训练数据集:BSDS5001,通过对图像的裁剪,翻转,镜像等方法来扩大数据集。最后得到的数据集含有230,000个尺寸为64x64的图像。利用标准差范围为(0,0.25)的噪声来合成含条纹噪声的图像,最后生成了训练图像对集合。
网络层数:10层
λ
=
0.05
\lambda=0.05
λ=0.05
优化方法:Adam。深度学习网络训练中经常使用的一种方法。

翻译不下去了,大家自己看看吧。
实验分析
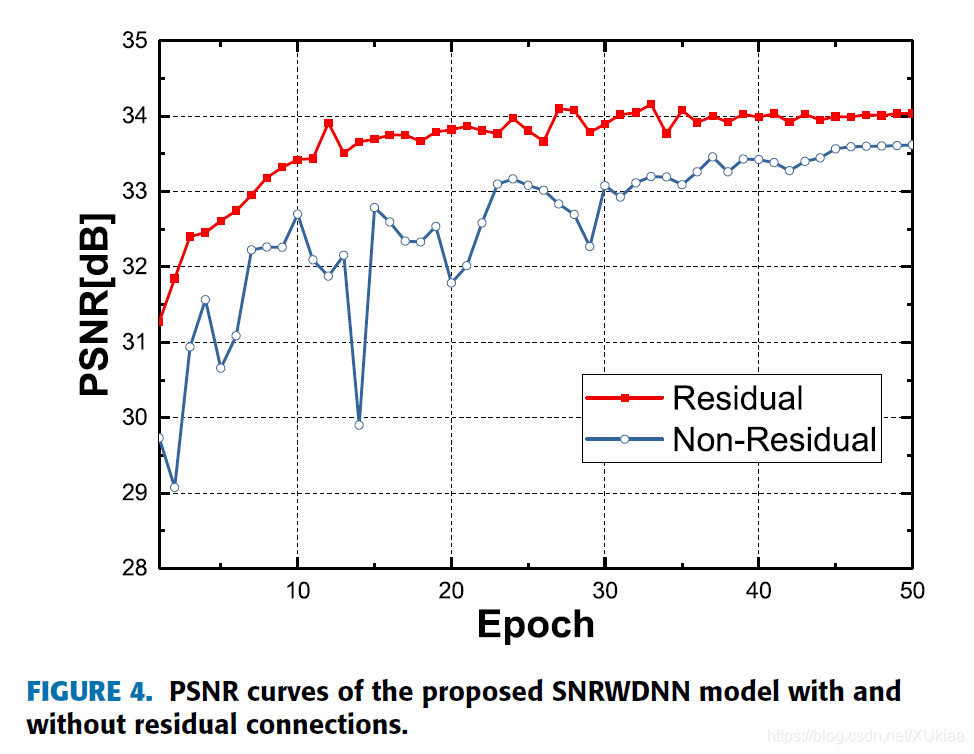
该网络使用了残差学习,本文也做了一个实验来证明使用残差学习对提高网络的去条纹能力有极大的影响。会获得PSNR更大的图像。
本文提出了一种定向正则化方法。在此,分析了该方法对图像去条纹的影响。
在其它条件相同的情况下,一个模型使用定向正则化,一个模型不使用。得到了如下的结果。
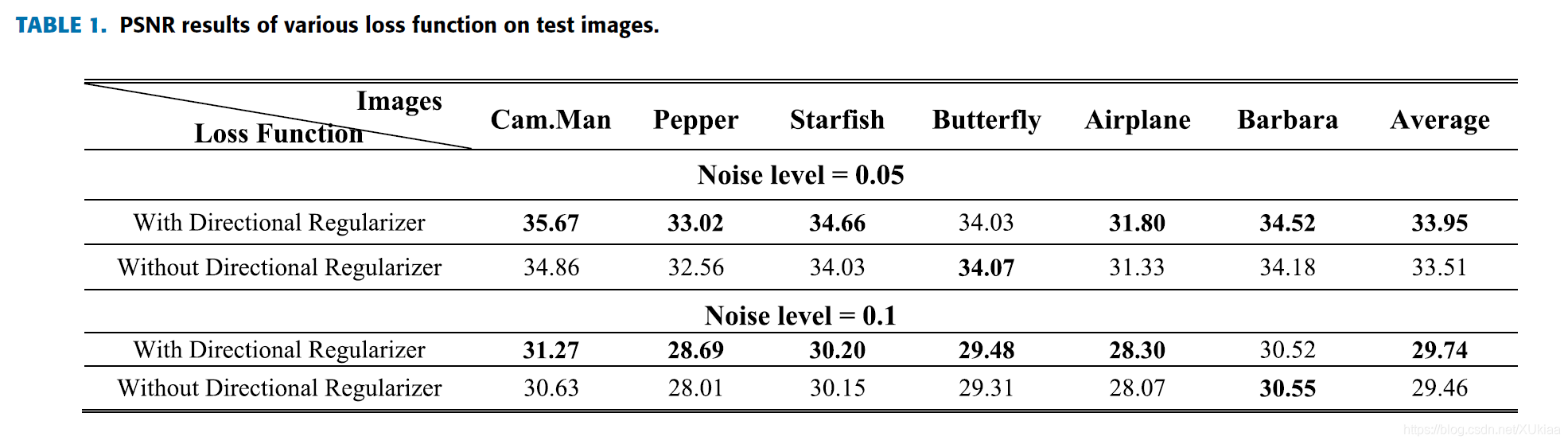
在大多数例子下,使用定向正则化在PSNR水平上会稍高一些。是不是也说明没有什么太大用?但是使用还是比较好一些。

从上图可以看出,只有在一些细节上才有一些改善。在整体上,我们用肉眼实际上看不出太大的差别。
小波子带之间的信息互补性
为了进一步分析,训练了两个模型:一个仅使用
c
A
cA
cA和
c
H
cH
cH子带;一个使用四个子带。两个模型的去噪结果如下:

通过肉眼看不出什么差别。为了能更清晰的看出差别,计算出图像每一列的均值,
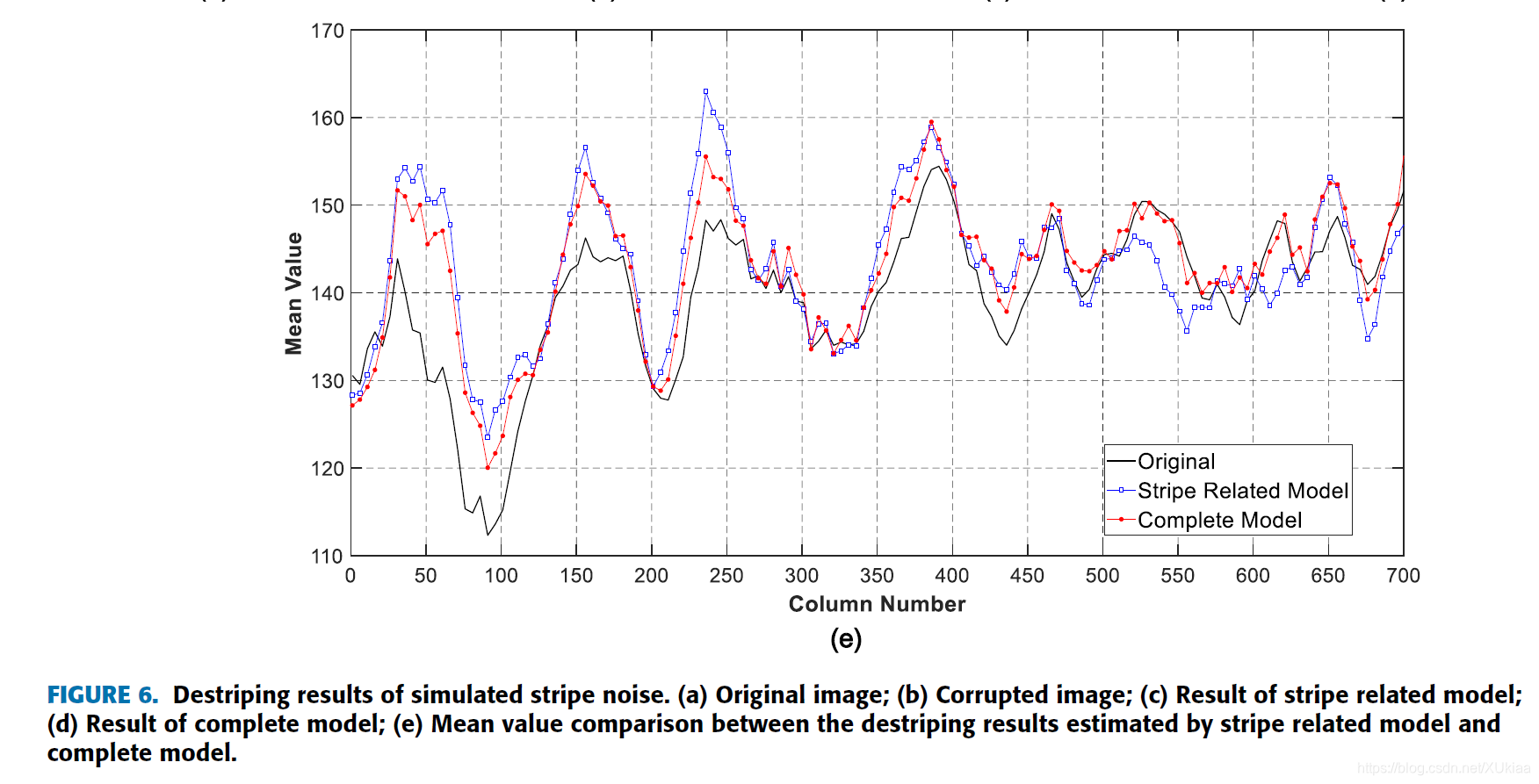
从改图可以看出,使用四个子带训练的模型,在每一列上的均值,与原图像更接近。这说明,通过利用各子带之间信息的补充性,我们能够更好的进行去噪和保留图像中的细节。
与经典去噪方法比较
对各种方法的去条纹效果进行定量和定性评估,使用两个指标:PSNR和SSIM.
比较的其它算法如下:

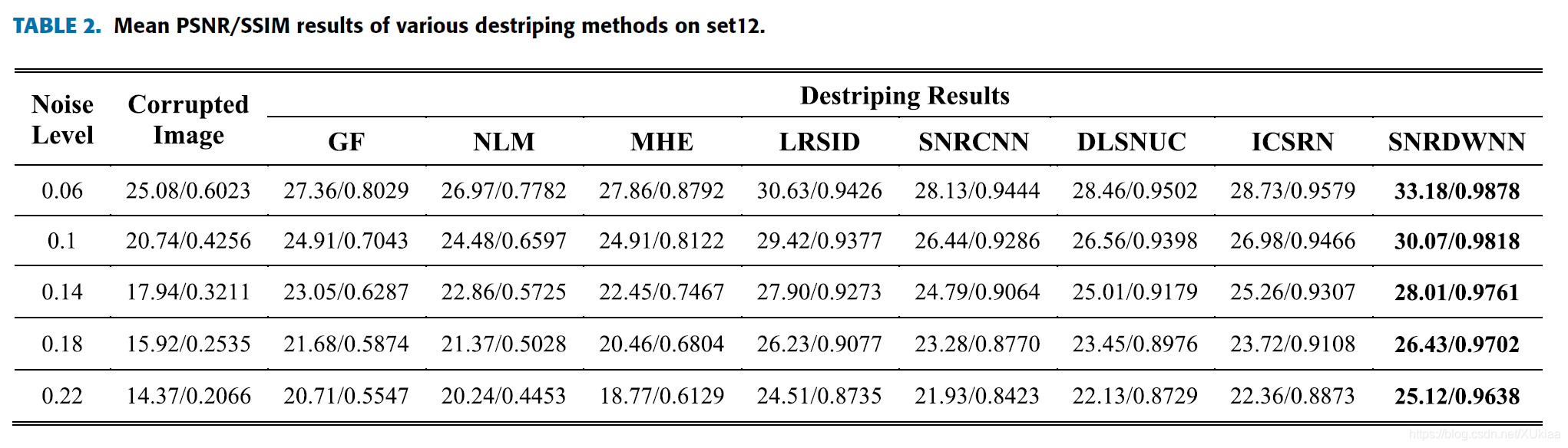

不管是用PSNR和SSIM定量评估,还是从直观上观察,与其它的方法相比,都取得了较好的结果。
在真实图像上验证算法的有效性
在这部分,只使用基于深度学习的方法来进行比较。

从图中很明显的看出,随着噪声水平的增加,每种方法的去噪效果都有所下降;对于每个水平的噪声,该算法都表现出了较好的性能。
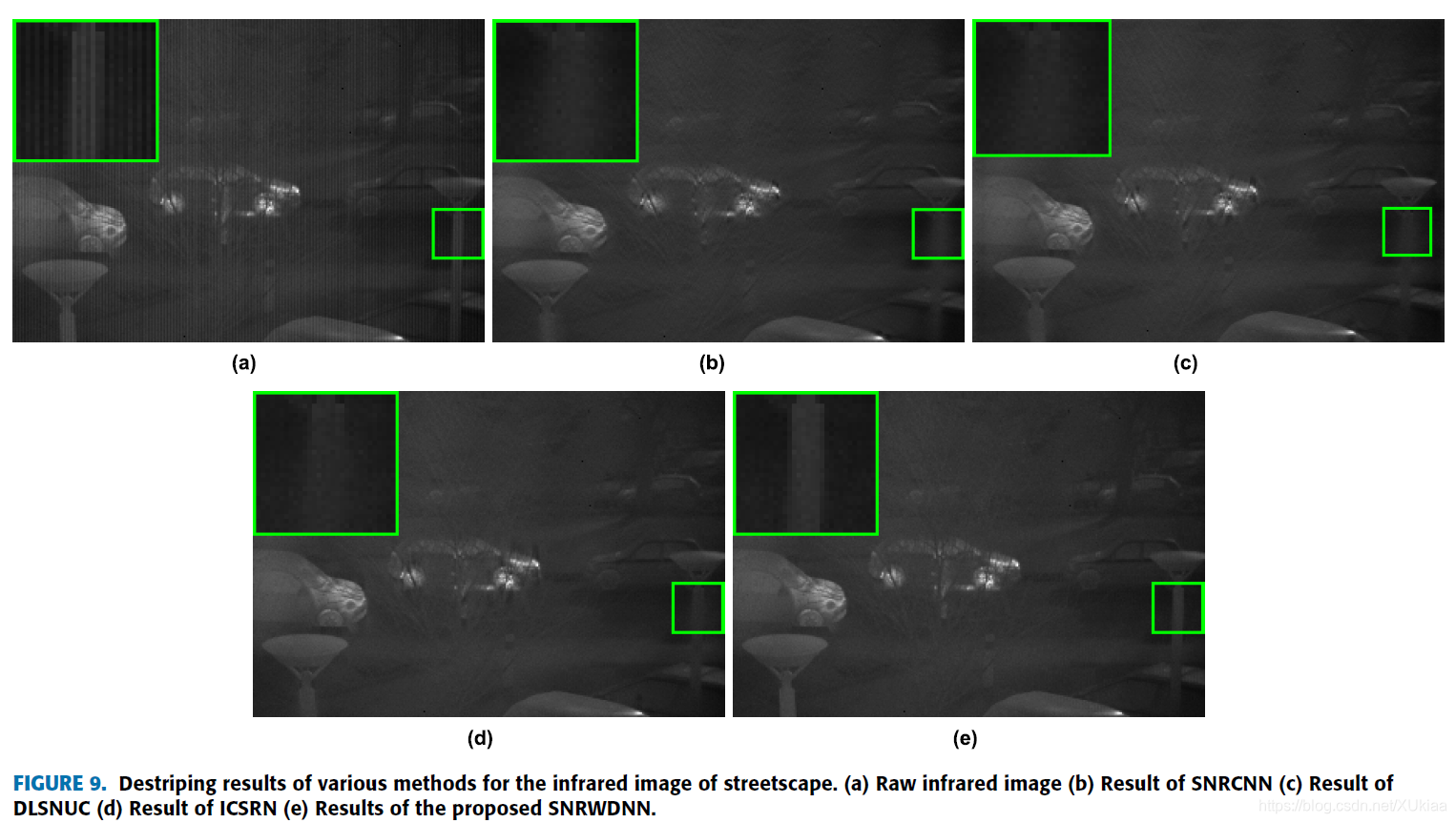
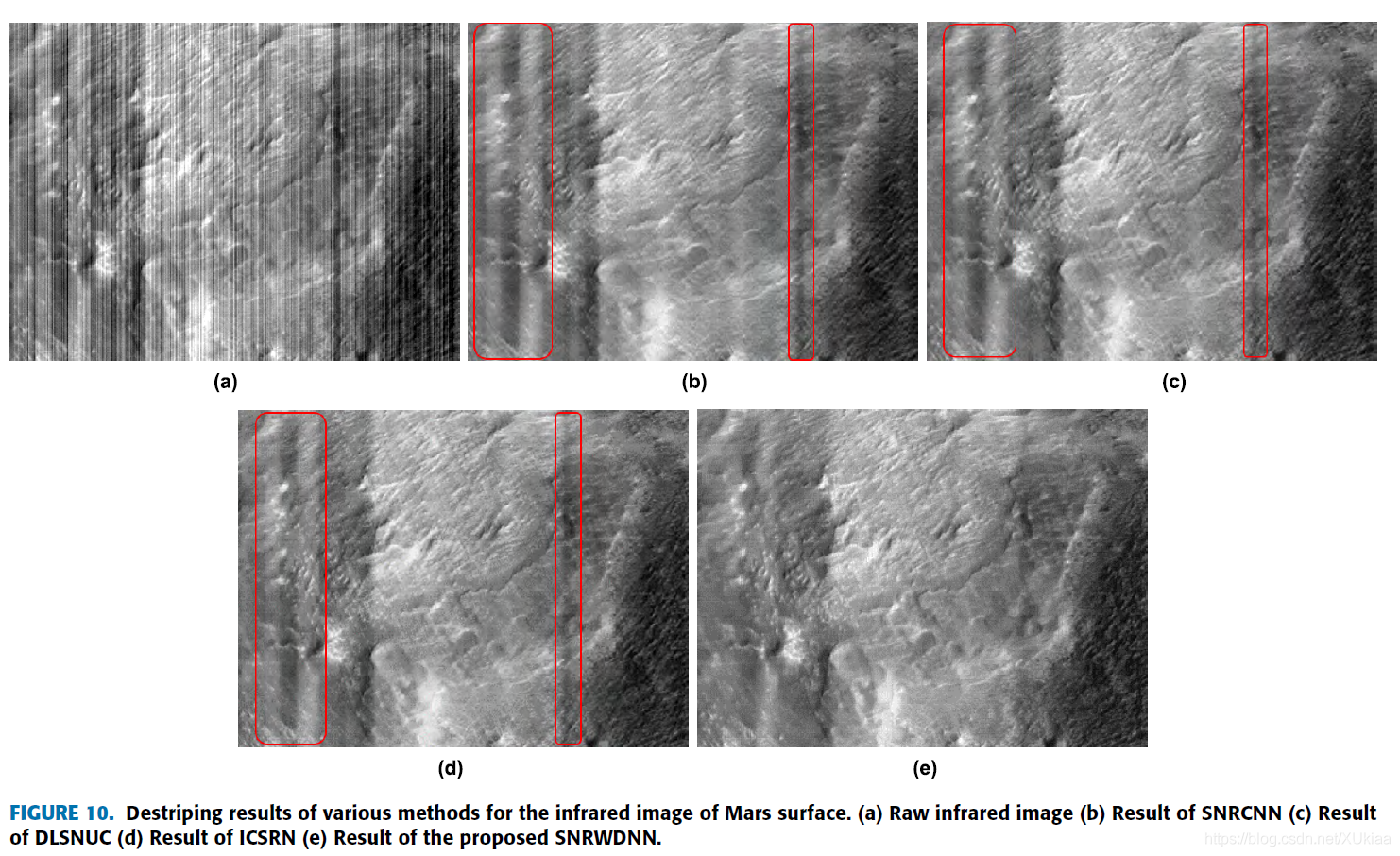
文章中还有两个例子对各种方法进行比较,一个是比较黑的图。另外一个是云图。同样地,该方法都表现出了比较好的去条纹效果。
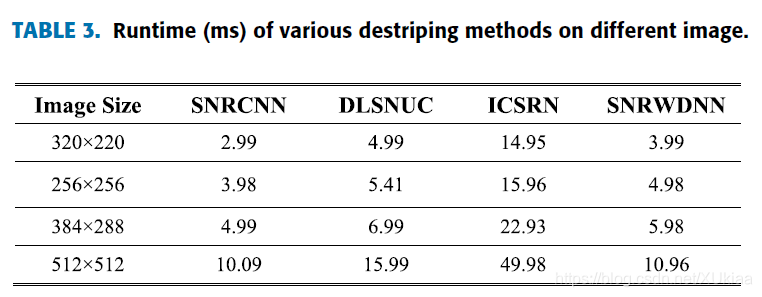
运行时间比较
总结
该方法具有较好的去条纹效果。
但是在噪声水平比较高的情况下,去条纹的性能会有所下降。
我在运行这个程序的时候,发现作者在训练集上添加的噪声范围在
(
σ
=
0
−
0.25
)
(\sigma=0 - 0.25)
(σ=0−0.25).在测试时,如果输入的噪声水平小于0.25。都会获得较好的结果。说明该方法比较不错
W. Luo, J. Li, W. Xu, and J. Yang, ``Learning sparse features in convolu-tional neural networks for image classification,’’ in Proc. Int. Conf. Intell.
Sci. Big Data Eng., Suzhou, China, 2015, pp. 2938. ↩︎















 1181
1181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









