







写在最前面:
本篇内容是纯经验贴,没有宣传式的或者标题式的文字。只为记录科研小白的自己在解决问题的同时一些思考和真实经验,并奢望能帮你在困难面前以我搭桥,助你思考!
本篇内容仅包括:俺自己的实验收集了淡水、淡水沉积物、海水、海草附着微生物样品,测序所得的Fastq格式数据,在文章投稿发表时被要求数据需上传NCBI的SRA库,得到一个PRJNA2347899这样子的IDs。仅解决了这个上传过程!
1、数据库简单介绍
关于NCBI和SRA库,俺也还做不到科普,只能描述官方介绍和入口链接。目的只是为了能保证这篇内容完整操作整个数据上传流程。
NCBI:National Center for Biotechnology Information (National Center for Biotechnology Information), It advances science and health by providing access to biomedical and genomic information.
SRA: Sequence Read Archive (https://submit.ncbi.nlm.nih.gov/), is the largest publicly-available repository of high throughput sequencing data. The archive accepts data from all branches of life as well as metagenomic and environmental surveys.
本篇内容仅需要知道在哪找到入口就行!
2、目的描述
想必大家经常在相关的文献中看到类似这样的句子,好奇这个IDs怎么得来的,看起来很高大上的样子。All sequences used in this study are publicly available at the NCBI Sequence Read Archive (http://www.ncbi.nlm.nih.gov/Traces/sra) under accession IDs PRJNA488008 and PRJNA487989. 本篇内容仅能解决怎么得到这个IDs号码!!!
用俺实际举例:我们在淡水水体、沉积物(底泥)、海水水体以及海草叶面收集了微生物样品,经过高通量测序,得到16s测序结果,最后分析发表了一篇文章(开心脸)。文章中仅说明我们所用的原始数据上传至NCBI的SRA库,得到的IDs,要让想要复现我们文章分析的人能够拿到原始数据并进行后续分析。所以文章中标明了原始数据(fastq格式)在SRA库的IDs,这可以在NCBI中准确查找到我们的数据。
3、流程详解
大流程:注册NCBI账号→BioSample→BioProject→SRA上传。俺理解的流程:先搞个身份证(NCBI账号)能让自己在NCBI里面合法起来;然后搞个能描述自己样品的东西(BioSample),比如描述了俺的样品是从水里面来的,每个样品序号叫个啥……说白了俺的实验弄儿了个啥样品;然后搞个BioProject说明一下俺这个实验是想弄个啥,然后与BioSample连接起来,也就是按这个Project是通过上面这些个Sample完成的;最后,把这Project所能用到的所有详细数据、场景描述啥的都上传一下。
举个栗子:俺中午想急头白脸的吃一顿(BioProject),计划在餐厅买个包子(Sample)、门口买个鸡腿(Sample)、树上摘个西瓜(Sample)。老师说你这大项目啊,得汇报留档!!所以俺先弄个BioSample描述搁哪个餐厅买个啥包子,哪个门口买的鸡左腿还是右腿,树上这西瓜黑皮的花儿皮的;然后这些sample都是是用来完成这个BioProject的,完成这个BioProject的咱是用筷子啊还是用刀叉的,目的揍是想说明咱吃饭讲究啊;哎,最后俺把包子照片,西瓜子数量,鸡腿皮颜色(数据)都发到老师邮箱(SRA)保存留档!老师说你这个Project IDs是123456,以后师弟师妹也想这样急头白脸的吃一顿,那就用这个IDs下载一下你当时是怎么搞得。
注册NCBI个人账号
NCBI主页(National Center for Biotechnology Information)右上角Log in。

别的不知道,反正俺用Microsoft账号是能注册成功使用,自行尝试

登陆成功后会返回NCBI主页,多了自己的账号显示。点submit,进入下一个流程
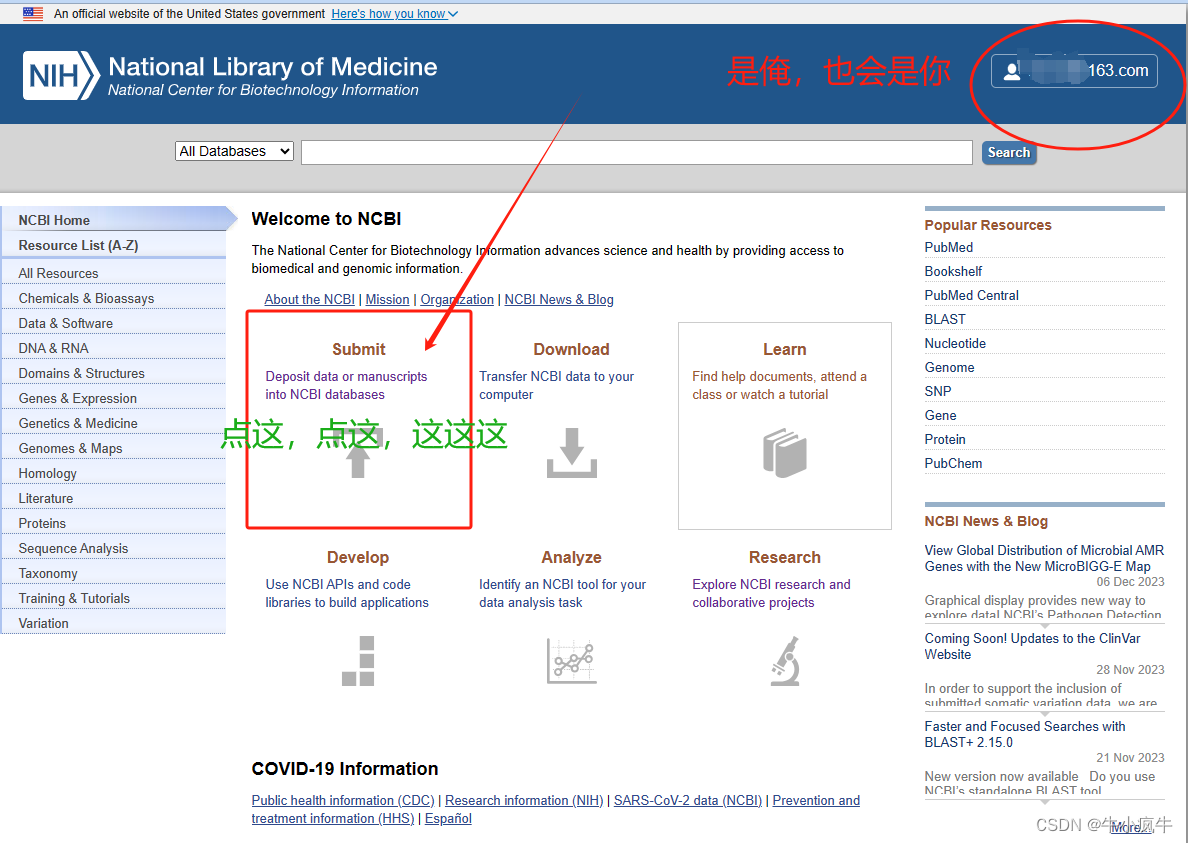
BioSample:详细说明自己样品的各种信息。
点My submissions, 这块儿是电梯;页面往下滑走楼梯,能自行学习探索的更清楚详细一些。楼梯自己走哈,俺走电梯……


点BioSample正式开始


BioSample之个人信息,填完点continue

BioSample之数据释放(就是啥时候大家能在网上搜到你的数据,个人理解:你不能说文章都online了,但别人还搜不到你的数据,那上传的有啥用)、样品多少(多个样品还是单个样品)

BioSample之样品归类,每个人的样品都不一样,仔细阅读页面介绍,准确归类自己的样品。

BioSample之样品信息描述,建议选择下载模板excel,填好后再传上去就行。不是不建议使用第一个,而是俺只用了第二个而且挺好用。

BioSample之样品表格填写,上一步给样品选择的分类不同,这里下载的表格也会有不同。但关键内容和填写规则相似,如下所示

表格的填写是最关键的一步,填写不对会不断报错,上传不了!!!!
大原则:不能出现任意两行是一样的,如果两行内容只有sample name是不一样的,那仍然会被判定为两行内容一样而报错!
所有的样品都要在这里填写!!!
必填项必须写,但实在没有这些信息的按要求填写not applicable等!!!
*sample_name:自己给样品编写的编号,肯定不能有重复。
*organism:重点!这个选项有特定的内容,在Taxonomy browser (metagenomes)内选择自己样品对应的进行填写。如果自己的样品实在归类不到这里面任何一项(大概率是不会的),自己填写(规则是sth metagenome)。自己创造式的填写内容,提交之后需要等待官方人员审核,时间可能24h以上。但上述网页中选择的内容,提交就会立即通过。举个栗子:俺的样品S1是水中抽滤测序的微生物,网页中选择的话应该填写freshwater metagenome,但我没注意自己写了water metagenome(网页选项中没有这个),提交后就被审核了2天菜通过。当时是耽误了一定的进度的,况且官方给的选择更加准确细化。
*collection_date:注意格式就行,鼠标放在表格中这个标题上,就会提示你格式等要求(这句话后续不再讲,表格填写时通用。)
*env_broad_scale, *env_local_scale,*env_medium:本质上都是在描述你采集样品的环境分类等内容,可以参考官方推荐,若合适就写上就行,若不合适,自己又搞不清楚,可以填not applicable(这也是表格提示中给出的选填内容,仔细看表格的要求和提示,避免后面不断报错)。注意这些的填写规则是[ENVO:000000000],若想自己找这个分类,见网址https://www.ncbi.nlm.nih.gov/biosample/docs/attributes/。个人理解:*env_broad_scale这个选项填了推荐分类就行,其他两个not applicable.
*geo_loc_name:采样地点,格式China: Wuhan
*host:描述样品从什么地方采集的,可以是自己写的话。所以自己表达清楚准确就行!举个栗子:S1样品是microbes from A(拉丁名) seagrass leaf,S2样品是microbes from seawater
*lat_lon:采样点坐标,注意格式即可。
其他黄色标题的内容,根据提示,想填可以自行填写!举个栗子:description选项,仍然是可以自行组织语言填写,所以可以自己更详细的描述样品采集环境分类,目的都是更清晰准确的描述自己的样品。比如俺写的Microbial sample in water of a mesocosm that simulating shallow lake,Microbial sample in surface sediment of a mesocosm that simulating shallow lake等等。
BioSample之提交
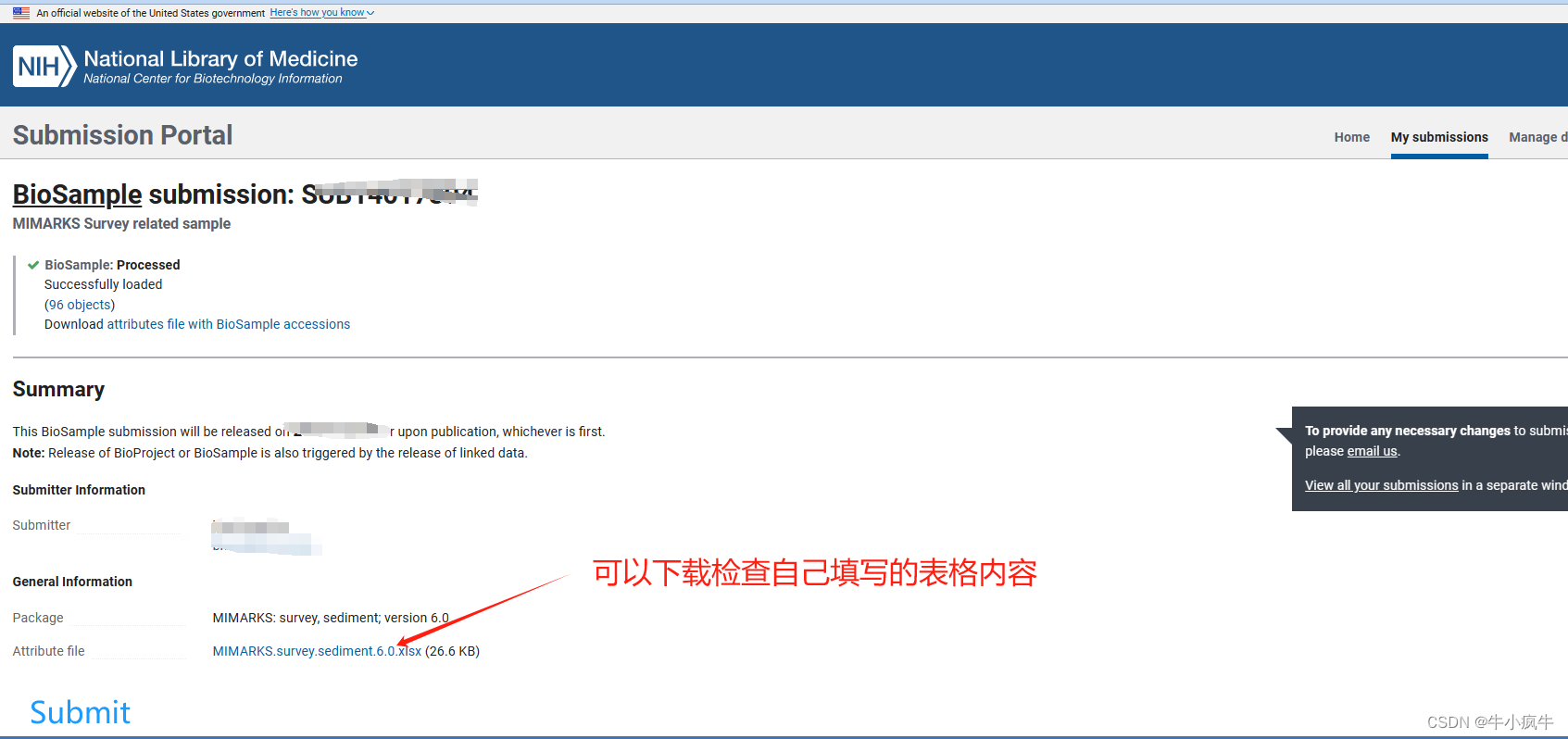

这样BioSample就搞完了,我们已经详细准确的描述了我们实验的样品信息。之后,建立BioProject,说明我们用这些sample做了些什么,让两者建立连接!
BioProject正式开始

BioProject之个人信息,和之前BioSample填写一样,参考之前
BioProject之项目类型,只知道微生物16s选什么,其他的朝纲了,自己查


BioProject之项目目标,
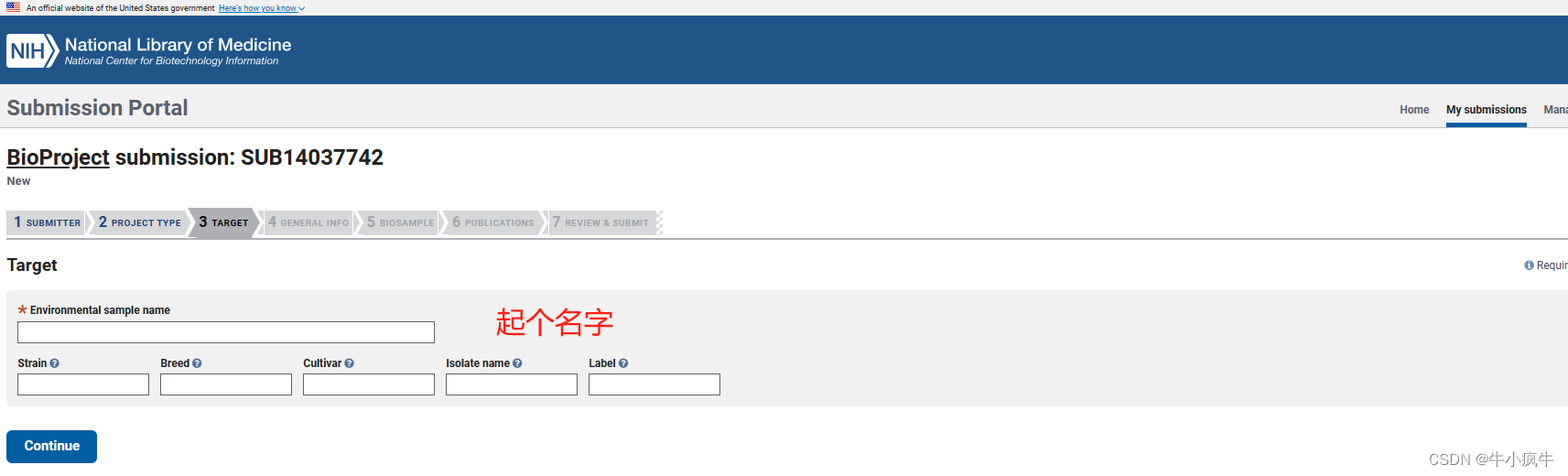
BioProject之释放日期:参照BioSample的释放日期说明
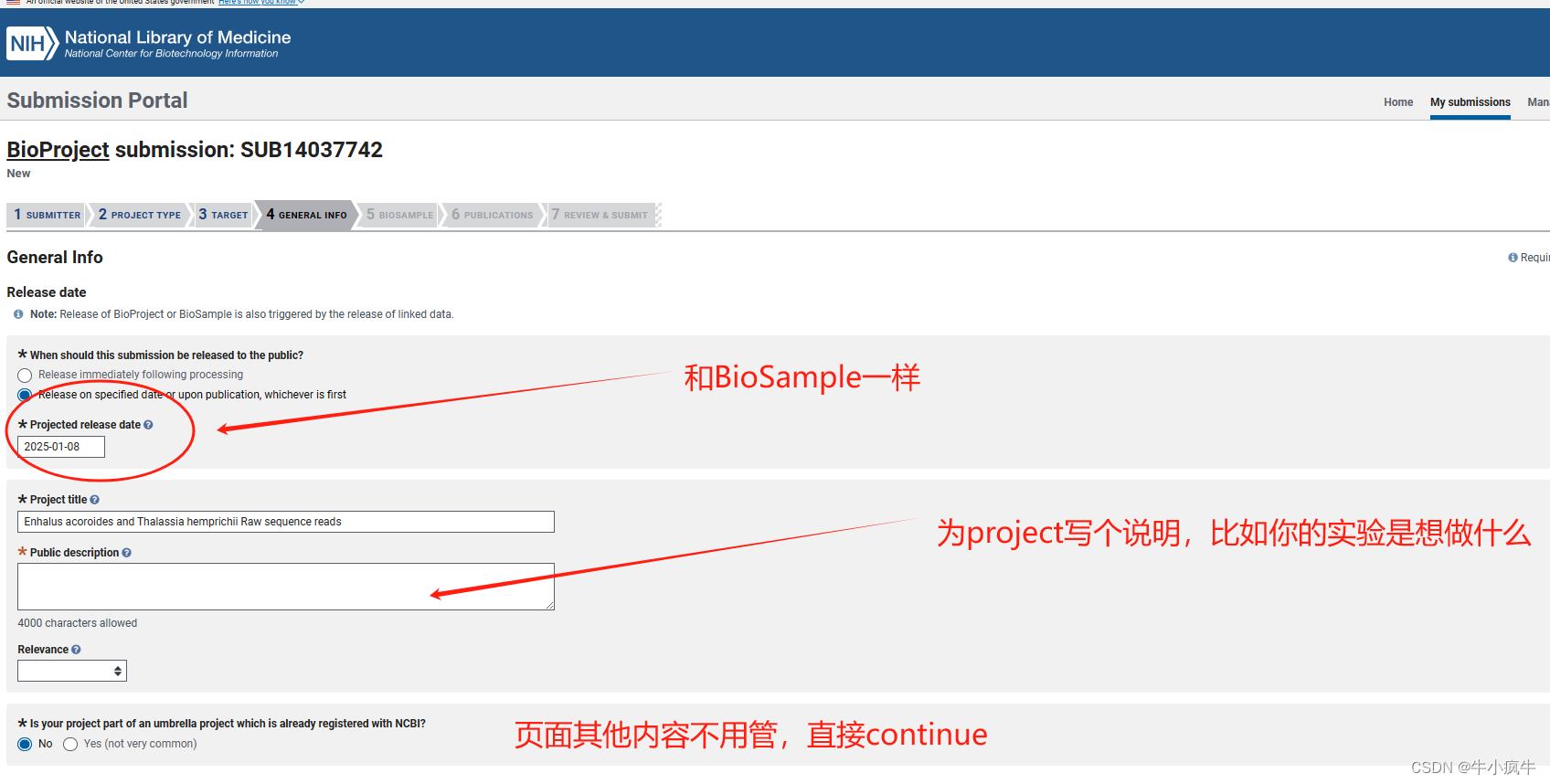
BioProject之填写BioSample的编号

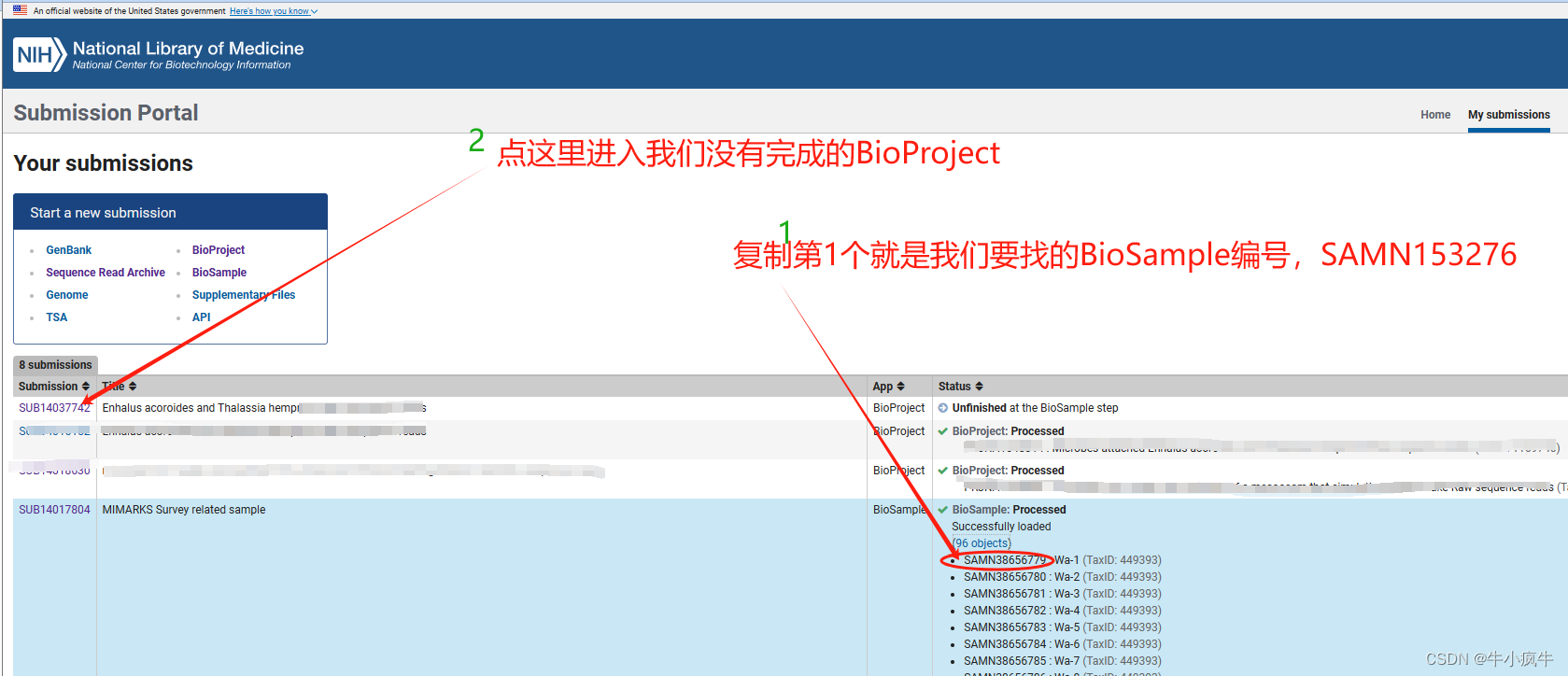
找BioSample编号



BioProject之提交


SRA之开始


SRA之个人信息

SRA之数据释放和bioproject编号

找数据编号:回到my submission就能看到刚才自己提交的,同时你的邮箱也会收到对应的确认邮件。这些地方都能找到。

SRA之原始序列上传
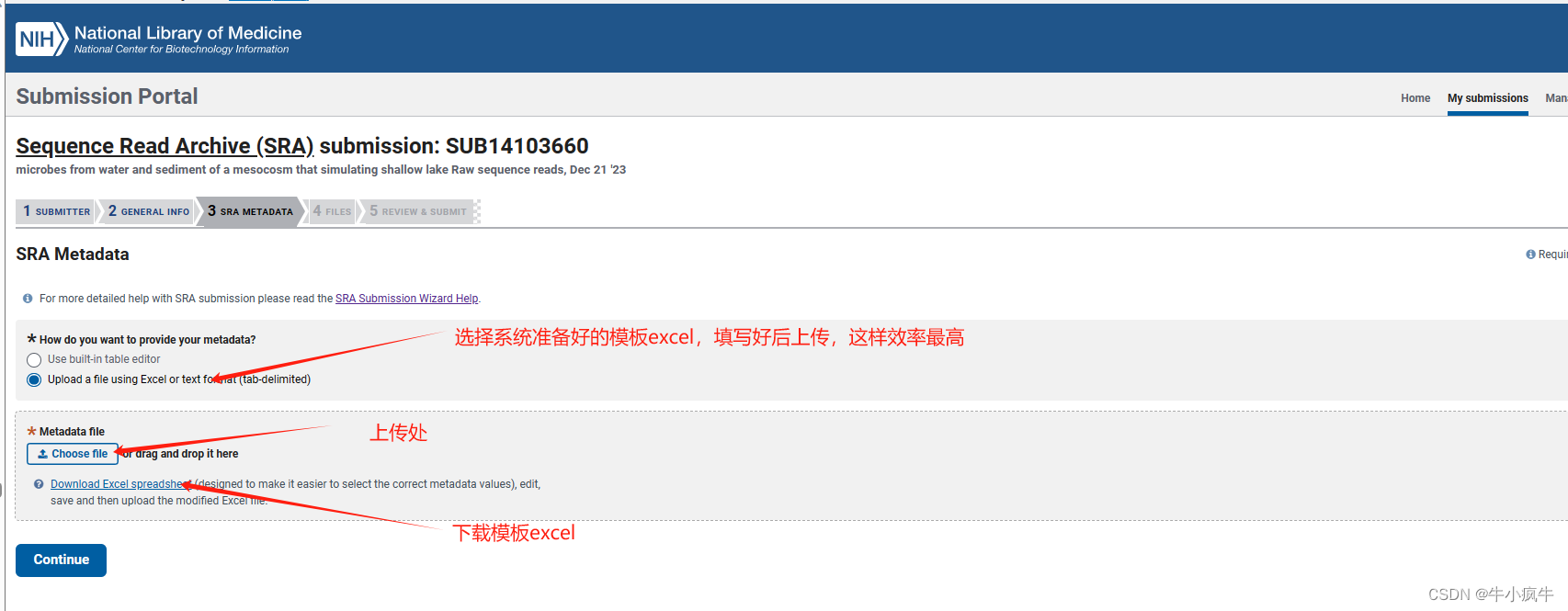
SRA之模板excel填写


SRA之原始序列压缩包上传


上传之后这里会显示你已经上传的数据

完了之后,下一步直接提交即可!!!
完美了
Submit之后,1-2天差不多就能收到NCBI的确认邮件,证明咱们已经完美了。PRJNA格式的号码就是咱们在文章中需要呈现的IDs。在咱们之前选择的数据释放日期之后,别人就可以通过这个Ids,在NCBI上面查询并且下载我们这篇文章的原始测序数据,并且重复我们文章中的分析。
4、一丢丢想法
首先明确的是这篇笔记仅仅解决了我们公所关注的问题----来自水、沉积物和附着的等微生物的16s测序结果如何上传至NCBI的SRA中。但有多种类型的数据均能上传至此数据库,诸位所遇到的问题也许不是完全一致。故不可一概而论,照搬操作。
这个问题中最关键之处在于NCBI所提供的模板excel该如何填写,其余流程NCBI所设计的程序式步骤非常完善,无需担心。即便同是微生物16s测序数据,我们将自己的数据归类不同,模板excel所提供的内容也不尽相同。自我审视,较之诸多参考流程,这篇笔记更详细的解释了数据上传过程中模板excel的填写,以及可能遇到的问题和解决办法!!
其次,经过这次的探索。清晰深刻的认识到一些事情:
无论是16s还是相似类型的数据上传,BioSample到BioProject再到原始序列的上传,是一个流程式的过程,也是相似问题的解决大思路;
每个人的实际数据,包括测序过程、方法、平台等均有细微差别。所以,任何流程都会有不尽详细和相同之处。我们解决自己问题的方式,应该是一个类比的过程。即参考别人的方法,对照别人的数据,理解过程并类比自己数据,正确真实的解决自己所遇到的实际问题;
最后,希望这些文字可以帮助到正在困惑或者烦于查找方法的你……














 5892
5892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









