







前言
本文来解析一下MACE中ARM代码的1*1卷积的实现。1*1卷积在CNN中是比较特殊的一种操作,不再强调领域操作,一般用到1*1卷积有以下几种情况(相互之间不独立)
1.单纯的加强非线性映射,不强调领域CNN的特征提取功能
2.bottleneck结构中进行特征图数量的改变
3.depthWise 卷积中组成部分
除了以上三点外其他情况欢迎补充
本文涉及的源代码文件:
mace/mace/kernels/arm/conv_2d_neon_1x1.cc
mace/mace/kernels/gemm.cc从卷积到矩阵乘法
// mace/mace/kernels/arm/conv_2d_neon_1x1.cc
#include "mace/kernels/arm/conv_2d_neon.h"
#include "mace/kernels/gemm.h"
namespace mace {
namespace kernels {
void Conv2dNeonK1x1S1(const float *input,
const float *filter,
const index_t batch,
const index_t height,
const index_t width,
const index_t in_channels,
const index_t out_channels,
float *output) {
for (index_t b = 0; b < batch; ++b) {
Gemm(filter, input + b * in_channels * height * width, 1, out_channels,
in_channels, height * width,
output + b * out_channels * height * width);
}
}
} // namespace kernels
} // namespace maceMACE中1*1卷积的代码如上,可以看到其实就是在每一个batch中调用了gemm矩阵乘法运算。这节简单说明卷积操作是如何变成矩阵乘法的。假设输入通道数为C1,输出通道数为C2。则一般卷积核参数为C1xC2xkhxkw,因此卷积核大小为1*1时,卷积核就从四维变成了两维矩阵K,大小为C1*C2。在单batch下,假设上一次输入数据大小为 C1*H*W,把它reshape成一个C1*(H*W)的矩阵F,这样多通道分别卷积再求和的过程就可以用这两个矩阵乘积来表示:
得到了大小为C2*(H*W)的矩阵Z。其实就是单通道的卷积运算退化成了一个矩阵和一个标量的点乘运算了。下图举了一个C1=2,C2=3,输入和输出特征图大小为2*3(1*6、3*2也一样)的例子。
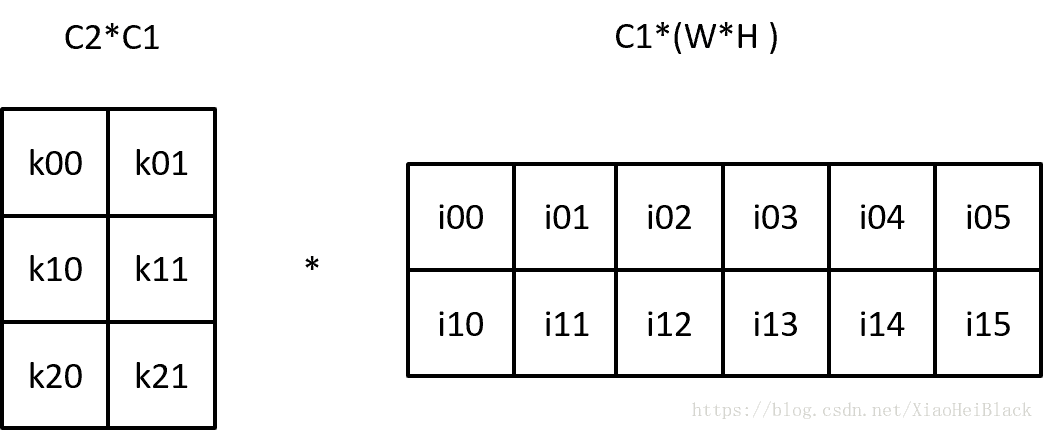
矩阵乘法做完后,就完成了单batch的1*1卷积运算。I0、I1f分别表示2通道的输入数据,在这里一个通道w*h个数据被拉成了一行。源码中没有reshape函数?因为内存排布并没有变,所以其实不需要额外的操作。
gemm的实现
那么转而来看gemm的实现。
/**
* Gemm does fast matrix multiplications with batch.
* It is optimized for arm64-v8 and armeabi-v7a using neon.
*
* We adopt two-level tiling to make better use of l1 cache and register.
* For register tiling, function like GemmXYZ computes gemm for
* matrix[X, Y] * matrix[Y, Z] with all data being able to fit in register.
* For cache tiling, we try to compute one block of multiplication with
* two input matrices and one output matrix fit in l1 cache.
*/源码中开始的注释如是说。为了更好的优化,MACE应用了矩阵分块乘法,所以看这部分代码前建议先停下来复习一下矩阵分块乘法的公式。
MACE把大矩阵运算分为两级的矩阵分块乘法。第一级的实现名字都是GemmXYZ这种形式,表示大小为[X,Y]和[Y,Z]的矩阵相乘,主要的NEON优化也是在这些函数中。这一级的矩阵计算大小都很小,最大也就Gemm688,所以大部分情况下变量都可以保持在寄存器上,避免寄存器变量溢出到栈上带来的时间开销。这一级的分块矩阵乘法运算称为register tiling。
第二级优化则是把若干register tiling组成一个block,保证一个block内的内存需求(2个矩阵输入+1个矩阵输出)不会超出L1 cache的大小,提高cache命中率。称为cache tiling。MACE为了内存搬运优化做了两级的分块矩阵乘法。
register tiling
#define MACE_GEMM_PART_CAL_8(RC, RA, RAN) \
c##RC = vmlaq_lane_f32(c##RC, b0, vget_low_f32(a##RA), 0); \
c##RC = vmlaq_lane_f32(c##RC, b1, vget_low_f32(a##RA), 1); \
c##RC = vmlaq_lane_f32(c##RC, b2, vget_high_f32(a##RA), 0); \
c##RC = vmlaq_lane_f32(c##RC, b3, vget_high_f32(a##RA), 1); \
c##RC = vmlaq_lane_f32(c##RC, b4, vget_low_f32(a##RAN), 0); \
c##RC = vmlaq_lane_f32(c##RC, b5, vget_low_f32(a##RAN), 1); \
c##RC = vmlaq_lane_f32(c##RC, b6, vget_high_f32(a##RAN), 0); \
c##RC = vmlaq_lane_f32(c##RC, b7, vget_high_f32(a##RAN), 1);
#define MACE_GEMM_PART_CAL_4(RC) \
c##RC = vmlaq_lane_f32(c##RC, b0, vget_low_f32(a##RC), 0); \
c##RC = vmlaq_lane_f32(c##RC, b1, vget_low_f32(a##RC), 1); \
c##RC = vmlaq_lane_f32(c##RC, b2, vget_high_f32(a##RC), 0); \
c##RC = vmlaq_lane_f32(c##RC, b3, vget_high_f32(a##RC), 1);子矩阵运算关键就是这两个宏,分别为8(4)个浮点向量和8(4)个标量的累乘和,,也就是我们矩阵运算中的基本操作。MACE_GEMM_PART_CAL_4(RC) 的一次调用实现的是1*4(A)和4*4(B)矩阵的乘法。
inline void Gemm144(const float *a_ptr,
const float *b_ptr,
const index_t stride_a,
const index_t stride_b,
const index_t stride_c,
float *c_ptr) {
#if defined(MACE_ENABLE_NEON)
MACE_UNUSED(stride_a);
MACE_UNUSED(stride_c);
float32x4_t a0;
float32x4_t b0, b1, b2, b3;
float32x4_t c0;
a0 = vld1q_f32(a_ptr);
b0 = vld1q_f32(b_ptr);
b1 = vld1q_f32(b_ptr + 1 * stride_b);
b2 = vld1q_f32(b_ptr + 2 * stride_b);
b3 = vld1q_f32(b_ptr + 3 * stride_b);
c0 = vld1q_f32(c_ptr);
MACE_GEMM_PART_CAL_4(0);
vst1q_f32(c_ptr, c0);
#else
GemmBlock(a_ptr, b_ptr, 1, 4, 4, stride_a, stride_b, stride_c, c_ptr);
#endif
}以Gemm144为例,输入矩阵A,B分别可以装载到1个和4个1*4的浮点向量中去。再通过乘累加指令把计算结果存入1*4的结果向量中。而类似Gemm884这样的函数,只不过是A矩阵每行多取一个向量。
所以在使用MACE_GEMM_PART_CAL_8计算时需要多2个参数,这两个参数组成A矩阵的一行。调用代码长成这样:
MACE_GEMM_PART_CAL_8(0, 0, 1);
MACE_GEMM_PART_CAL_8(1, 2, 3);
MACE_GEMM_PART_CAL_8(2, 4, 5);
MACE_GEMM_PART_CAL_8(3, 6, 7);
MACE_GEMM_PART_CAL_8(4, 8, 9);
MACE_GEMM_PART_CAL_8(5, 10, 11);
MACE_GEMM_PART_CAL_8(6, 12, 13);
MACE_GEMM_PART_CAL_8(7, 14, 15);第一级的矩阵乘法就是这一系列GemmXYZ组成,而他们的调用则组成了第二级,继续向下看。
cache tiling
这一部分的主体在GemmTile、Gemm这两个函数上。毕竟是工程代码,需要对边界进行处理,对不同编译和设备环境进行优化。所以代码显得比较庞杂。为了理清逻辑我把aarch64 和clang 宏控制的部分代码删除、并暂时把边界处理的代码也给删掉,现在代码看上去是这样的:
GemmTile(const float *A,
const float *B,
const index_t height,
const index_t K,
const index_t width,
const index_t stride_a,
const index_t stride_b,
const index_t stride_c,
float *C) {
index_t h = 0;
index_t w = 0;
index_t k = 0;
int reg_height_tile = 8;
int reg_K_tile = 8;
for (h = 0; h < height - reg_height_tile + 1; h += reg_height_tile) {
for (k = 0; k < K - reg_K_tile + 1; k += reg_K_tile) {
const float *a_ptr = A + (h * stride_a + k);
for (w = 0; w + 3 < width; w += 4) {
const float *b_ptr = B + (k * stride_b + w);
float *c_ptr = C + (h * stride_c + w);
Gemm884(a_ptr, b_ptr, stride_a, stride_b, stride_c, c_ptr);
}
}
}
}第一级的矩阵运算放在Gemm884中,此时可以把Gemm884看做单个元素看待。这样这里的三层循环就和普通的矩阵乘法一致了(回忆下分块矩阵乘法的公式,其实就是一个递归的过程)。
我们再把边界处理的代码加上去
inline void GemmTile(const float *A,
const float *B,
const index_t height,
const index_t K,
const index_t width,
const index_t stride_a,
const index_t stride_b,
const index_t stride_c,
float *C) {
index_t h = 0;
index_t w = 0;
index_t k = 0;
int reg_height_tile = 6;
int reg_K_tile = 4;
for (h = 0; h < height - reg_height_tile + 1; h += reg_height_tile) {
for (k = 0; k < K - reg_K_tile + 1; k += reg_K_tile) {
const float *a_ptr = A + (h * stride_a + k);
for (w = 0; w + 3 < width; w += 4) {
const float *b_ptr = B + (k * stride_b + w);
float *c_ptr = C + (h * stride_c + w);
Gemm884(a_ptr, b_ptr, stride_a, stride_b, stride_c, c_ptr);
}
if (w < width) {
const float *b_ptr = B + (k * stride_b + w);
float *c_ptr = C + (h * stride_c + w);
GemmBlock(a_ptr, b_ptr, reg_height_tile, reg_K_tile, width - w,
stride_a, stride_b, stride_c, c_ptr);
}
}
if (k < K) {
const float *a_ptr = A + (h * stride_a + k);
const float *b_ptr = B + k * stride_b;
float *c_ptr = C + h * stride_c;
GemmBlock(a_ptr, b_ptr, reg_height_tile, K - k, width, stride_a, stride_b,
stride_c, c_ptr);
}
}
if (h < height) {
index_t remain_h = height - h;
for (k = 0; k < K - reg_K_tile; k += reg_K_tile) {
const float *a_ptr = A + (h * stride_a + k);
index_t w;
for (w = 0; w + 3 < width; w += 4) {
const float *b_ptr = B + (k * stride_b + w);
float *c_ptr = C + (h * stride_c + w);
GemmX44(a_ptr, b_ptr, stride_a, stride_b, stride_c, c_ptr, remain_h);
}
if (w < width) {
const float *b_ptr = B + (k * stride_b + w);
float *c_ptr = C + (h * stride_c + w);
GemmBlock(a_ptr, b_ptr, remain_h, reg_K_tile, width - w, stride_a,
stride_b, stride_c, c_ptr);
}
}
if (k < K) {
const float *a_ptr = A + (h * stride_a + k);
const float *b_ptr = B + k * stride_b;
float *c_ptr = C + h * stride_c;
GemmBlock(a_ptr, b_ptr, remain_h, K - k, width, stride_a, stride_b,
stride_c, c_ptr);
}
}
}对比一下可以看到一个block把3个维度上不足步长的部分用GemmBlock计算了。aarch64 和clang宏包中的代码,内嵌了NEON的汇编代码,可以更好的安排指令排布以及寄存器的使用,可参考GemmXYZ解读,不赘述了。
Gemm
我们至下而上的终于讲到了矩阵乘法最上层接口函数。和GemmTile函数一样先去掉细枝末节:
// A: height x K, B: K x width, C: height x width
void Gemm(const float *A,
const float *B,
const index_t batch,
const index_t height,
const index_t K,
const index_t width,
float *C,
const bool transpose_a,
const bool transpose_b) {
memset(C, 0, sizeof(float)* batch * height * width);
// It is better to use large block size if it fits for fast cache.
// Assume l1 cache size is 32k, we load three blocks at a time (A, B, C),
// the block size should be sqrt(32k / sizeof(T) / 3).
// As number of input channels of convolution is normally power of 2, and
// we have not optimized tiling remains, we use the following magic number
const index_t block_size = 64;
const index_t block_tile_height = RoundUpDiv(height, block_size);
const index_t block_tile_width = RoundUpDiv(width, block_size);
const index_t block_tile_k = RoundUpDiv(K, block_size);
const index_t block_tile[3] = { block_tile_height, block_tile_width,
block_tile_k };
const index_t remain_height = height % block_size;
const index_t remain_width = width % block_size;
const index_t remain_k = K % block_size;
const index_t remain[3] = { remain_height, remain_width, remain_k };
#pragma omp parallel for collapse(3)
for (index_t n = 0; n < batch; ++n) {
for (index_t bh = 0; bh < block_tile[0]; ++bh) {
for (index_t bw = 0; bw < block_tile[1]; ++bw) {
const float *a_base = A + n * height * K;
const float *b_base = B + n * K * width;
float *c_base = C + n * height * width;
const index_t ih_begin = bh * block_size;
const index_t ih_end =
bh * block_size +
(bh == block_tile[0] - 1 && remain[0] > 0 ? remain[0] : block_size);
const index_t iw_begin = bw * block_size;
const index_t iw_end =
bw * block_size +
(bw == block_tile[1] - 1 && remain[1] > 0 ? remain[1] : block_size);
for (index_t bk = 0; bk < block_tile[2]; ++bk) {
const index_t ik_begin = bk * block_size;
const index_t ik_end =
bk * block_size + (bk == block_tile[2] - 1 && remain[2] > 0
? remain[2]
: block_size);
Tensor trans_a;
Tensor trans_b;
const float *real_a = nullptr;
const float *real_b = nullptr;
float *real_c = c_base + (ih_begin * width + iw_begin);
index_t stride_a;
index_t stride_b;
index_t stride_c = width;
real_a = a_base + (ih_begin * K + ik_begin);
stride_a = K;
real_b = b_base + (ik_begin * width + iw_begin);
stride_b = width;
// inside block:
// calculate C[bh, bw] += A[bh, bk] * B[bk, bw] for one k
GemmTile(real_a, real_b, ih_end - ih_begin, ik_end - ik_begin,
iw_end - iw_begin, stride_a, stride_b, stride_c, real_c);
} // bk
} // bw
} // bh
} // n
}主体依然是矩阵乘法的三层循环,只是这次基础元素从一个register tiel计算变成了一个整个block计算,正如上面说的。这么做是为了该block涉及的内存可以存在L1 cache中,减少计算时的cache miss。默认的block大小为64,此外Gemm把尾部不足64的部分丢给GemmTile去处理了。在循环的尾部传入的block大小是可能不足64的。
总结
- 本文介绍了MACE的1*1卷积实现,实际上是调用矩阵乘法来完成单个batch内的卷积操作。在其gemm算法中,使用了两级矩阵分块乘法的方案。尽量避免寄存器变量溢出到栈上和cache miss这两种情况。原始矩阵运算为了计算一个结果对输入的访存跨度是很大的(取整行和整列),cache miss和寄存器溢出是必然比较频繁。
- 可以看到实现上不足步长部分,一是会导致逻辑分支,二是没有NEON优化,所以网络设计的时候不管长宽还是通道数都尽量取4、64的整数倍,会得到更好的计算性能。















 2969
2969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









