







DataFrame是按照列名来组织数据的分布式数据集,是SparkSQL最重要的抽象。由于基于DataFrame的算法在性能和优化的余地上(Tungstun和Catalyst)有更大的空间,因此,现在Spark里基于DataFrame的机器学习库ml及Structured Streaming都采用这种数据结构。而且未来spark基于RDD的机器学习库mllib不会再更新,最新的算法都采用基于DataFrame来实现。
pyspark.sql.DataFrame(jdf,sql_stx)的一个DataFrame对象,在SparkSQL里面可以简单的理解为一张关系型数据库的表,并且是可以通过SparkSession上的很多个接口读取外部数据生成DataFrame对象.例如通过读取parquet格式文件的形式得到DataFrame.
df=spark.read.paarquet('路径/文件名.parquet')当然,可以通过类似表名.列名的方式来得到表中的内容,语法如: df.列名
下面介绍一些DataFrame的常用方法:(按照方法名称的字典序排列)
首先通过读取csv文件来创建一个df.这个df的结构如下:
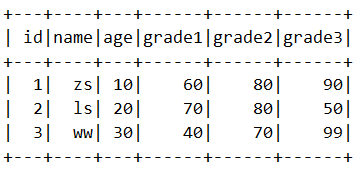
1.agg(*exprs)
Aggregate on the entire :class:`DataFrame` without groups(shorthand for ``df.groupBy.agg()``)
传入要聚合的字段及聚合的方式,以字典的方式进行组合
df.agg({"grade1":"max","grade2":"sum"}).show()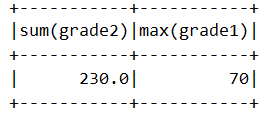
注意:如果对同一个列,做多次聚合操作,只保留最后的聚合操作,如下:
df.agg({"grade2":"sum","grade2":"avg","grade2":"min"}).show()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2592
2592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









