







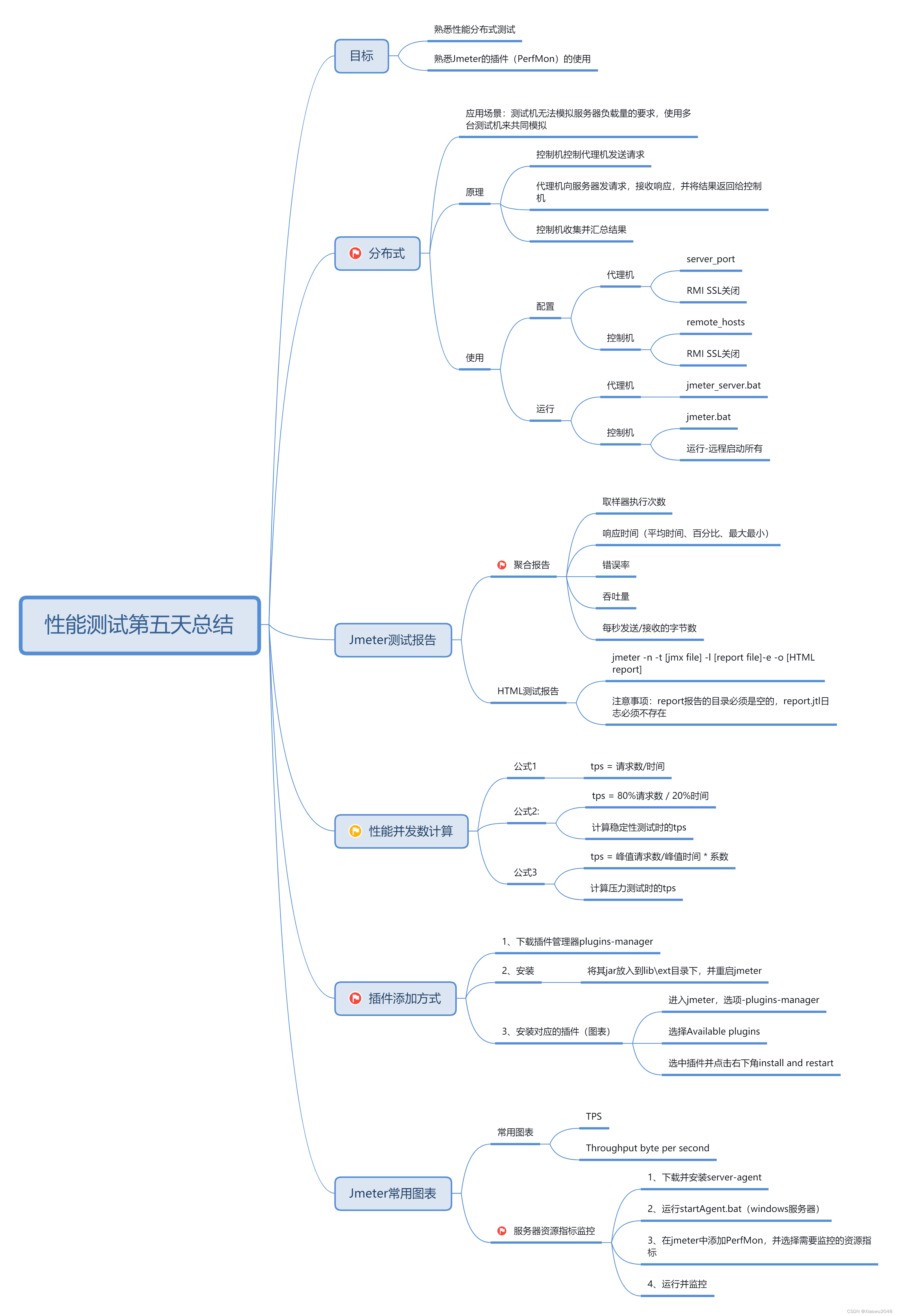
性能测试分类
基准测试
狭义上讲:单用户测试(单用户循环多次得到的数据)
广义上讲:建立基准线,当系统的软硬件环境发生变化之后再进行一次基准测试以确定变化对性能的影响
基准测试的用途:
基准测试不会单独存在
为多用户并发测试和综合场景测试等提供参考依据
为系统/环境配置、系统优化前后的性能提升/下降提供参考指标
负载测试
概念:通过逐步增加系统的负载,确定在满足系统的性能指标(如响应时间等)情况下,找出系统能够承受的最大负载量的测试
作用:系统最大负载量达到用户要求是,系统才能够正式上线使用
稳定性测试
概念:在服务器稳定运行的情况下长时间测试,并最终保证服务器能满足线上业务需求
作用:系统在用户要求的业务负载下运行达到规定的时间时,系统才能正式上线使用
其他分类:
压力测试
并发测试
性能测试的指标
响应时间
定义:从客户端发送请求,到客户端收到服务器响应的总时间
组成:网络传输时间+服务器处理时间

并发用户数
定义:同一时间向服务器发送请求的用户数
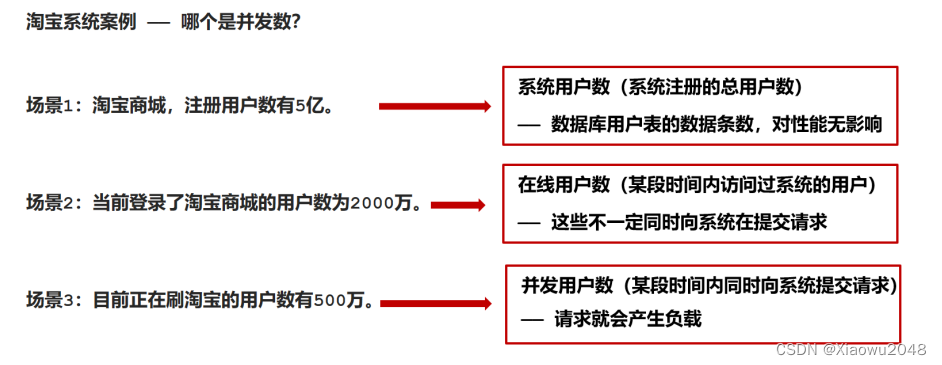
吞吐量
指的是单位时间内处理的客户端请求数量
吞吐量的单位
从业务角度:业务数/天,访问人数/天,页面访问量/天
从网络角度:字节数/小时,字节数/天
从技术角度:每秒钟查询数QPS,每秒事务数TPS
QPS和TPS有什么关系
事务,即业务。一个事务可以对应一个请求/多个请求
一个事务对应一个请求时:TPS=QPS
一个事务对应n个请求时: QPS=n*TPS
点击数:
所有的页面元素(如:图片、链接、框架等)的请求总数量
注意–点击数是请求书,不是页面上的一次点击
错误率:
指在负载情况下,业务失败的概率
资源利用率:CPU、内存,磁盘IO、网络
性能测试的流程
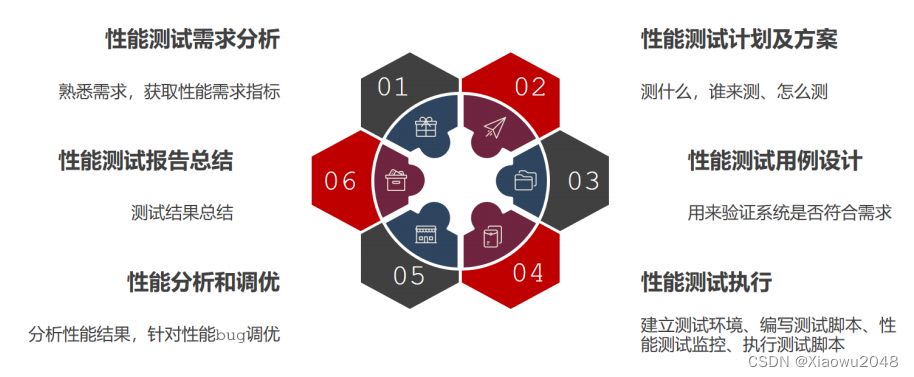
需求分析

性能测试计划:
测试的目的和范围
测试人员和分工
测试时间安排
测试的方法
性能测试用例;
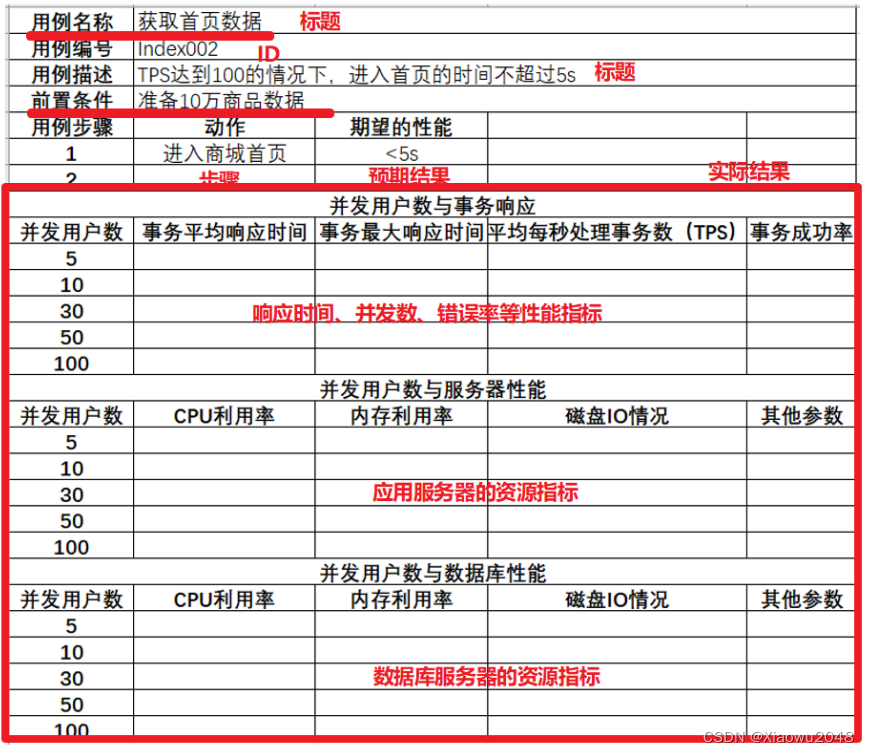
性能测试执行:
搭建性能环境
编写性能测试脚本
配置性能测试监控指标
执行脚本
Jmeter环境搭建
安装jdk:下载jdk-安装jdk–配置环境变量–验证
安装jmeter:下载jmeter–安装jmeter–配置环境变量–验证
jmeter的功能概要
jmeter文件目录结构

基本配置

jemeter主要元件即相关的作用域
基本元件
元件:多个类似于功能组件的容器(类似于类)

组件:容器中实现独立的某个功能(类似于方法)
作用域的原则
取样器:核心,没有作用域
逻辑控制器:只对其子节点中的取样器和逻辑控制器起作用
其他元件:
如果是某个取样器的子节点,则该元件只对其父节点起作用
如果其父节点不是取样器,则其作用域是该元件父节点下的其他所有后代节点(包括子节点,子节点的子节点等)
元件执行顺序
同一作用域下不同元件:
配置元件-前置处理程序-定时器-取样器-后置处理程序-断言-监听器
同一作用域下相同元件:
从上到下的顺序依次执行
案例:执行顺序
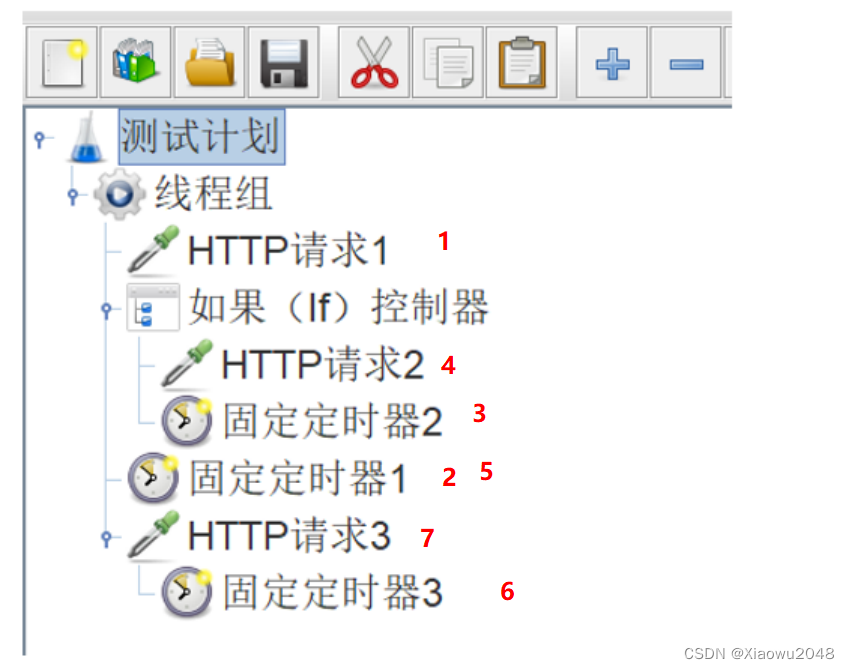
定时器1 - HTTP请求1 - 定时器1 - 定时器2 - HTTP请求2 - 定时器1 - 定时器3 - HTTP请求3
线程组、http请求的配置使用
线程组的介绍:
特点:模拟用户,支持多用户操作
多个线程组可以串行,也可以并行执行
线程组的分类:
setup线程组:前置处理,初始化
普通线程组:编写脚本
teardown线程组:后置处理,环境恢复等
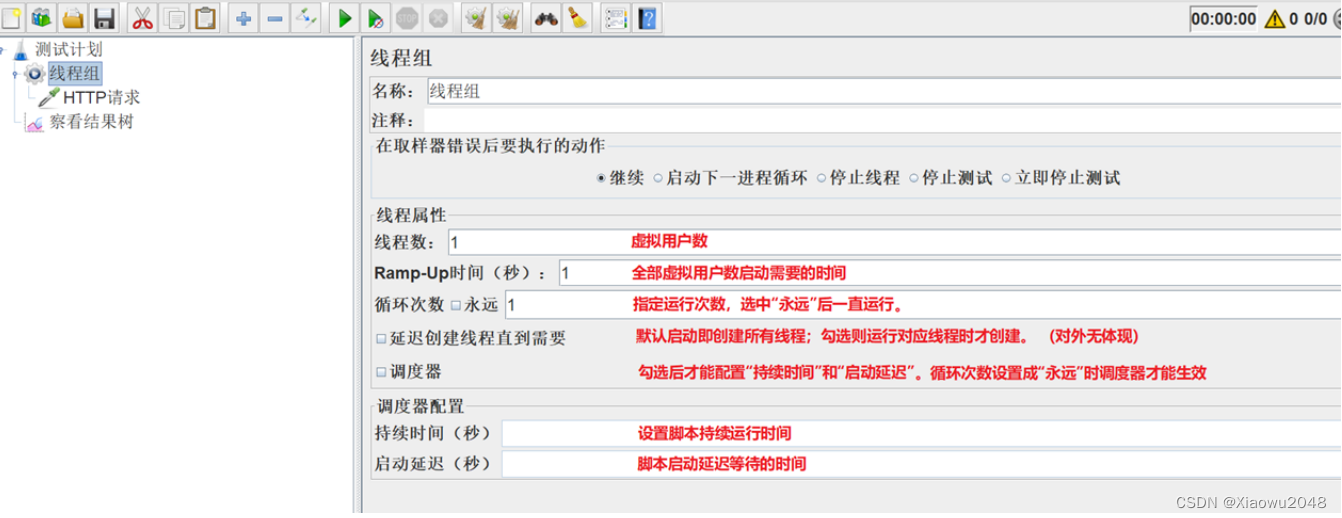
线程组的属性:
参数介绍:
案例:
使用1个线程组,添加HTTP请求(百度)
配置线程数为2,循环次数为3时,运行观察结果
配置线程数为3,循环次数为2时,运行观察结果,对比是否有不同
相同点:从请求数量来说,是完全相同的
不同点:场景不同
线程数:代表用户数,即性能测试时的负载量(线程数为2比线程数为3对应的负载量小)
循环次数:代表时间,即性能测试时的运行时间(循环次数3比循环次数2对应的时间长)
HTTP请求
参数介绍:
作用:向服务器发送http及HTTPS请求
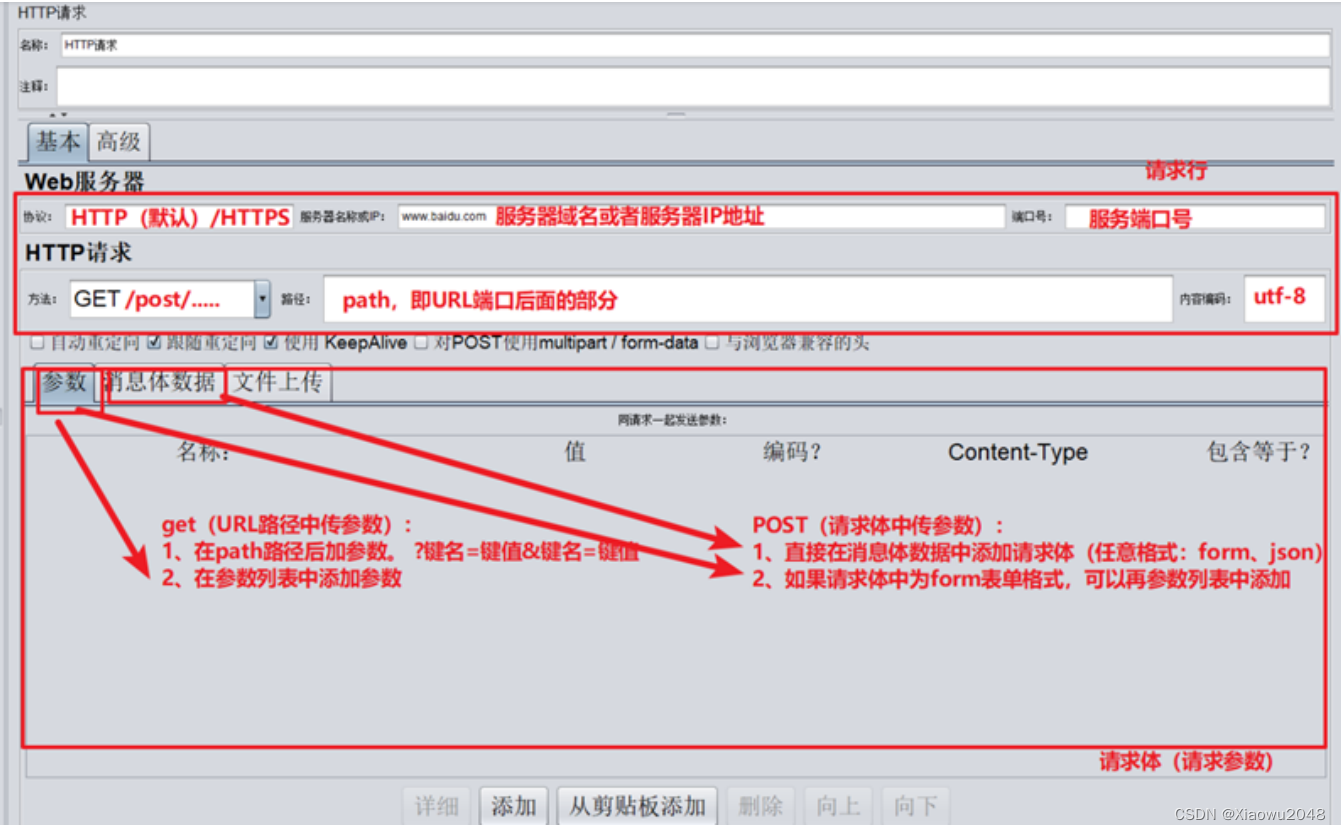
案例一(使用HTTP请求路径来传递get请求参数):
(1)使用1个线程组,添加HTTP请求(百度),路径为:/S
使用HTTP协议,GET请求方法,路径中添加参数为: wd = test,运行观察结果
案例二(使用参数列表来传递get请求的参数):
使用HTTPS协议,GET请求方法,路径中添加参数为: wd = test,运行观察结果
案例三(使用参数列表来传递POST请求的form格式参数):
使用HTTPS协议,POST请求方法,消息体数据中添加参数为: wd = test,运行观察结果
案例四:
使用HTTP协议,POST请求方法,消息体数据中添加参数为: wd = test,运行观察结果
查看结果树
案例1: 查看结果树中的HTTP请求中,有多个子的HTTP请求
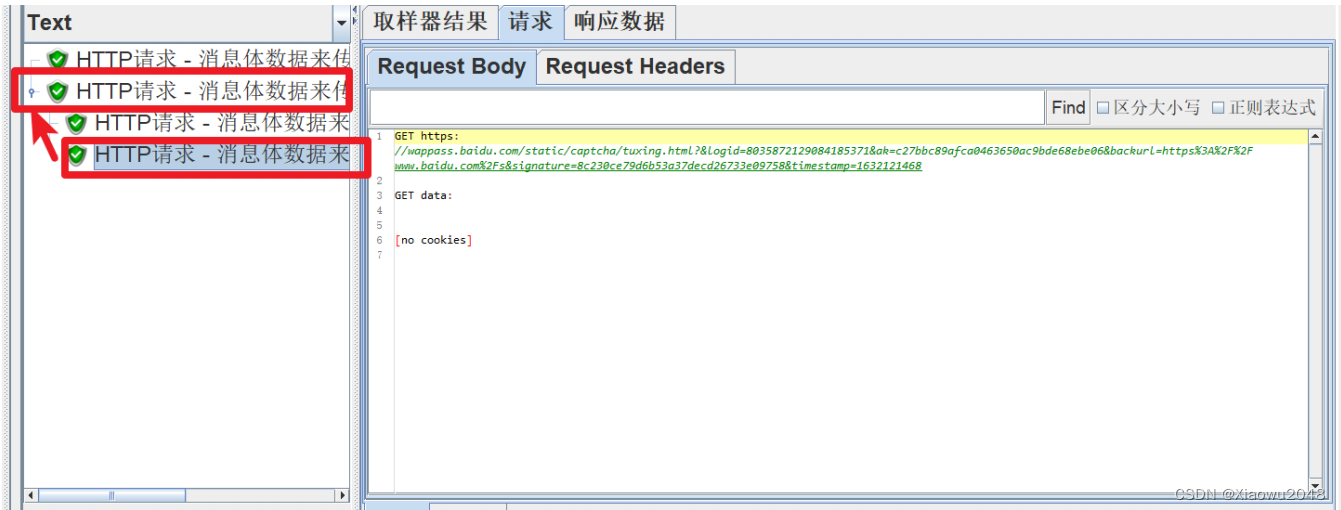
原因分析:
第一个HTTP请求中,URL错误,导致服务器产生了重定向,提供了新的URL路径
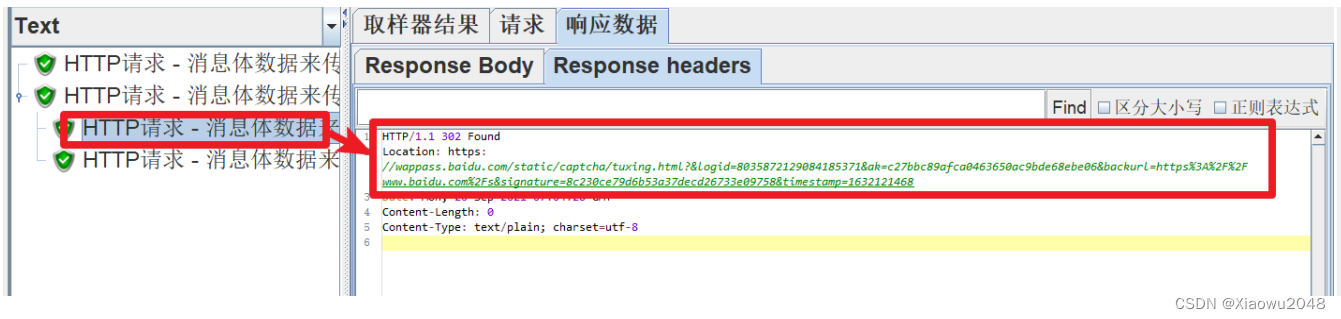
JMeter会自动发送第二个HTTP请求(使用第一个HTTP请求中返回的URL路径)
点击最外层HTTP请求时,显示的内容与最后一个HTTP请求的请求和响应数据一致
案例2:HTTP响应数据中存在乱码,需要修改取样器结果的编码格式

jmeter参数化的应用
本质:使用参数的方式来替代脚本中的固定的测试数据
实现方式:
定义变量(最基础)
文件定义的方式(所有测试数据都是固定的情况下)
数据库的方式(灵活,业务测试常用)
函数的方式(灵活,业务测试常用)
用户定义的变量
什么时候使用用户定义的变量:
定义全局变量
使用用户定义的变量进行参数化的步骤
1、添加线程组
2、添加用户定义的变量。格式:变量名-变量值
3、添加HTTP请求,引用定义的变量名,格式${变量名}
4、查看结果树
用户参数
什么时候使用用户参数:
针对同一组参数,当不同的用户来访问时,可以获取道不同的值
使用用户参数进行参数化的步骤
1、添加线程组,设置线程数为n(表示模拟的用户数)
2、添加用户参数
第一列添加多个变量名
后续的每一列为一组用户的数据
3、添加http请求,引用定义的变量名。格式${变量名}
4、查看结果树
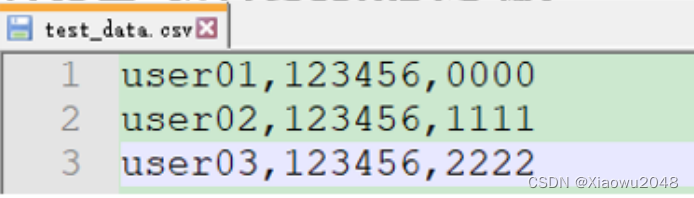
CSV数据文件设置
什么时候使用CSV数据文件设置
当不同的用户,或者同一个用户多次循环时,都可以获取到不同的值
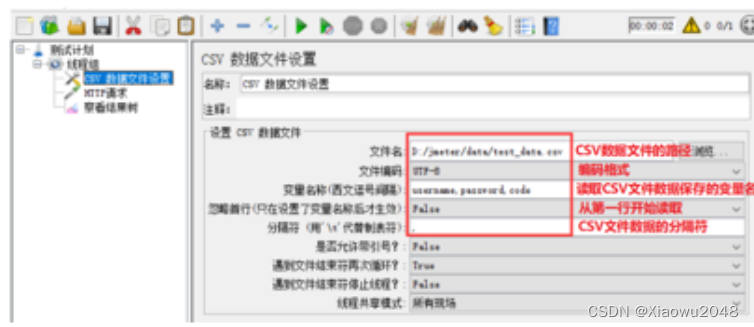
使用CSV数据文件设置进行参数化的步骤:
1、定义CSV数据文件
2、添加线程组
3、添加CSV数据文件设置
4、添加HTTP请求,引用定义的变量名,格式${变量名}
5、添加查看结果树
函数
什么时候使用_counter函数?
自动生成不重复的数据,让每个用户每次循环都能取到不同的数据,且不需要提前定义
使用counter函数进行参数化的步骤
1、添加线程组,设置虚拟用户数和循环次数
2、生成_counter函数
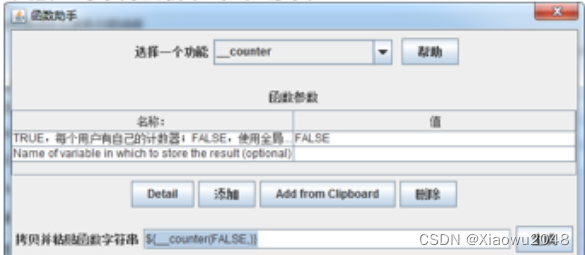
3、添加http请求,使用_counter函数。格式:${_counter(FALSE,)}
4、添加查看结果树
jmeter断言使用
jmeter断言
定义:检查实际的返回结果是否与预期结果保持一致
自动校验机制:自动判断响应状态码(2xx:成功,4xx/5xx:失败)
Jmeter断言:
响应断言:对任意格式的响应数据进行断言
json断言:对json格式的响应数据进行断言
持续时间断言:对响应时间进行断言
响应断言
什么时候可以使用响应断言:
任意http请求的响应结果,都可以使用响应断言
使用响应断言的操作步骤
1、添加线程组
2、添加http请求
3、添加响应断言
测试字段:要检查的项(实际结果)
模式匹配规则:比较方式
测试模式:预期结果
4、添加查看结果树
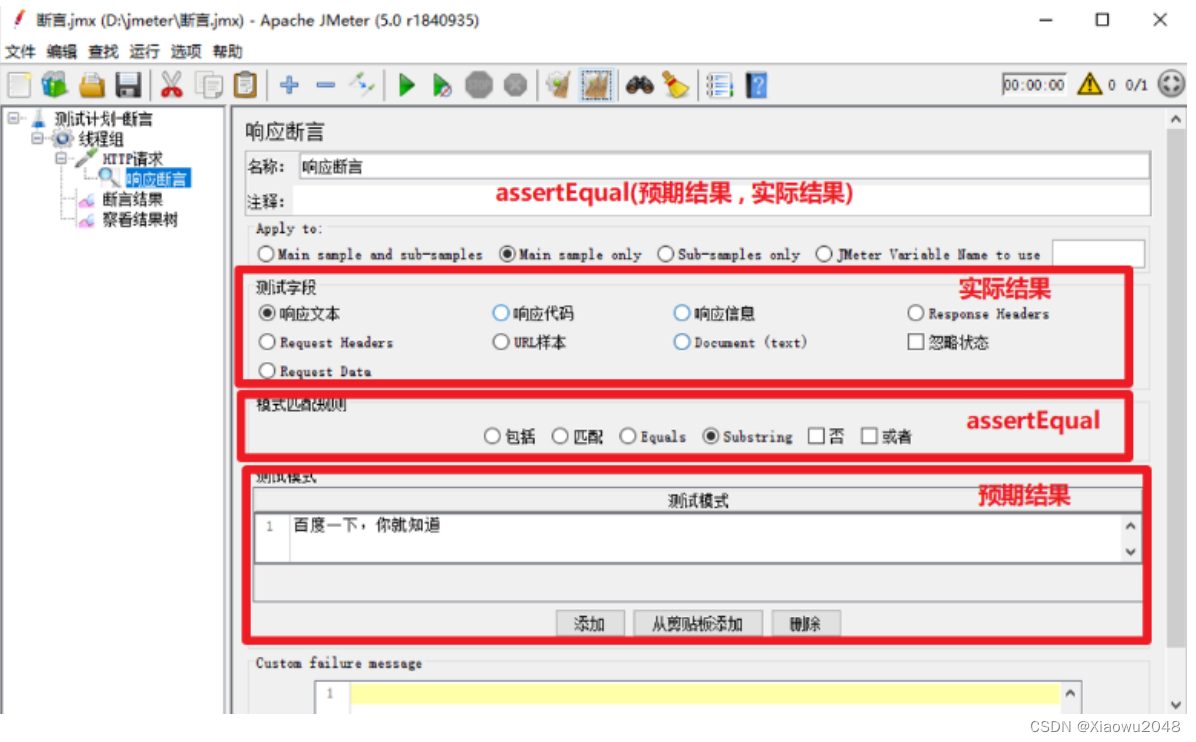
参数详细介绍
测试字段:要检查的项(实际结果)
响应文本:来自服务器的响应文本,即主体
响应代码:响应的状态码,例如:200
响应信息:响应的信息,例:OK
response header:响应头部
request header:请求头部
request data:请求数据
URL样本:请求URL
document(text):响应的整个文档
忽略状态:忽略返回的响应状态码
模糊匹配规则:比较方式
包括:文本包含指定的正则表达式
匹配:整个文本匹配的正则表达式
Equals:整个返回结果的文本等于指定的字符串(区分大小写)
substring:返回结果的文本包含指定的字符串(区分大小写)
否:取反
或者:如果存在多个测试模式,勾选代表逻辑或(只要有一个模式匹配,则断言OK),不勾选代表逻辑与(所有都必须匹配,断言才是ok)
注意:equals和substring模式是普通字符串,而包括和匹配模式是正则表达式
测试模式:预期结果
即填写你指定的结果(可填写多个),按钮【添加】、【删除】是进行指定内容的管理
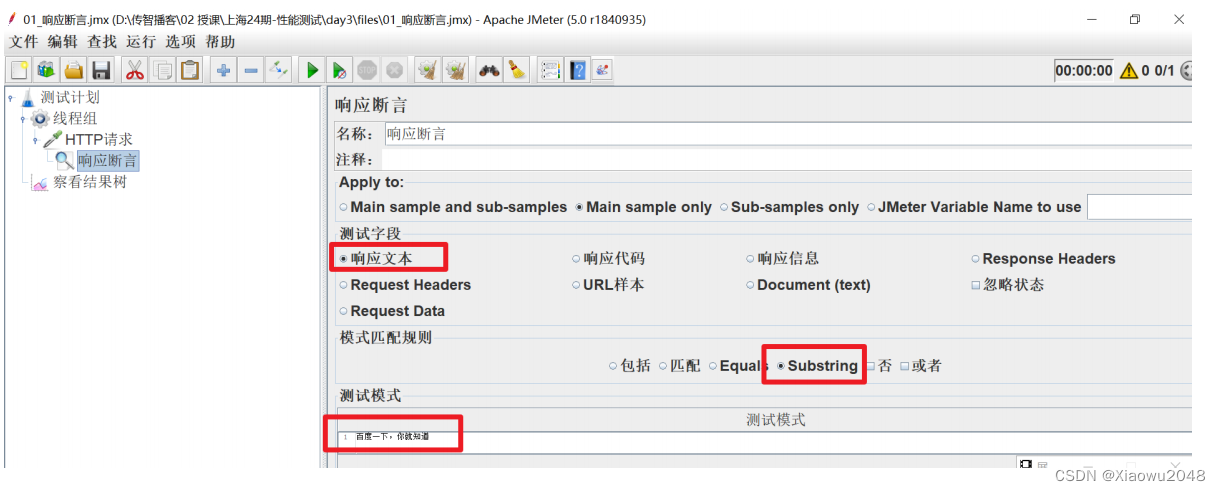
案例1:检查百度首页的接口响应中包含“百度一下,你就知道”
json断言
什么时候可以使用json断言:
对http请求的响应结果是json格式时,可以使用json断言
使用json断言的操作步骤
1、添加线程组
2、添加http请求
3、添加json断言
填写Assert JSON Path exists(实际结果-json路径)
勾选 Additionally assert value
填写expected Value(期望结果)
4、添加查看结果树
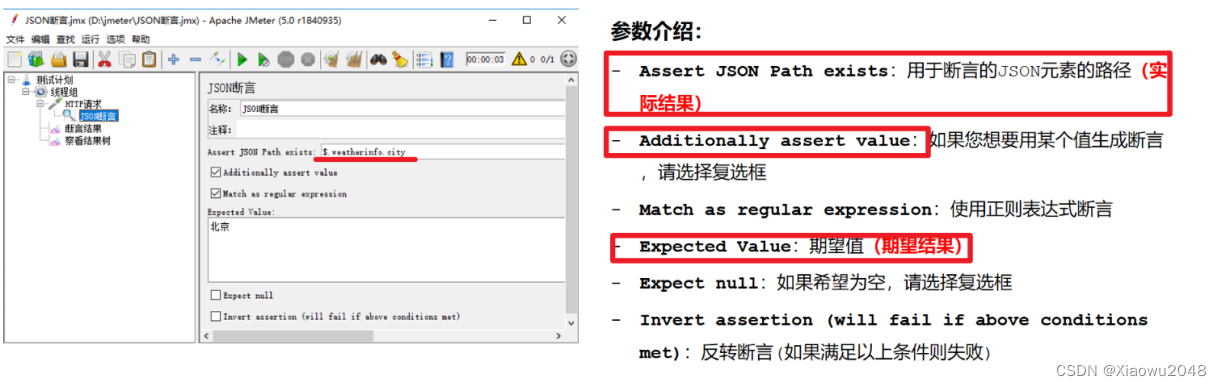
请求: http://www.weather.com.cn/data/sk/101010100.html
检查:让程序检查响应的JSON数据中,city对应的内容是否为“北京”
断言持续时间
什么时候可以使用断言持续时间:
测试http请求响应时间是否满足要求时,可以使用断言持续时间
使用断言持续时间的操作步骤;
1、添加线程组
2、添加http请求
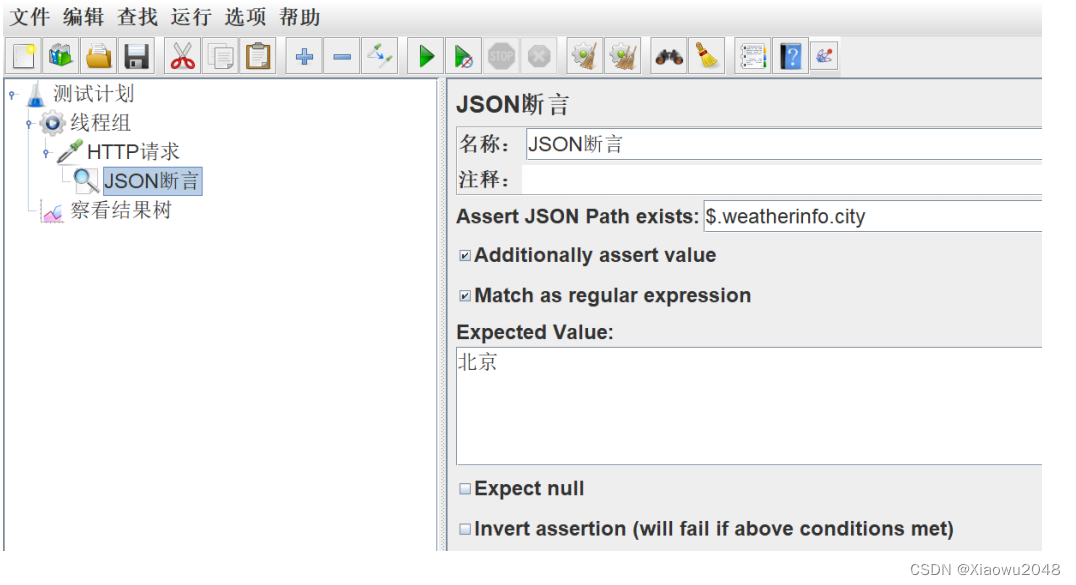
3、添加断言持续时间
填写持续时间(允许的最大响应时间,单位:ms)
4、添加查看结果树
请求: https://www.jd.com
检查:让程序检查响应时间是否大于100毫秒
jmeter关联使用
定义:请求之间有依赖关系,一个请求的响应数据作为另一个的请求参数来传递
JMeter关联:
正则表达式提取器:提取任意格式的响应数据
Xpath提取器:提取HTML格式的响应数据
JSON提取器: 提取JSON格式的响应数据
正则表达式介绍
正则表达式:就是一个公式,或者说一套规则,使用这套规则可以从任意字符串中提取出想要的数据内
容
公式格式:左边界(匹配符号)右边界:可以提取出想要获取的数据内容
.:是通配符,可以代表任意字符(除换行回车)
: 代表前面的字符出现0次或者多次
.匹配规则:找到左边界值后,往右查找有边界,找到最后面的右边界,中间的所有数据都被记录下来
?: 代表非贪婪匹配,找到左边界后,往右查找匹配右边界,只要有匹配的右边界就停止继续查找;再次查找
左边界和右边界
公式格式:左边界(.?)右边界
< title>百度一下,你就知道< /title>< title>百度一下,你就知道< /title>
< title>(.?)< /title>
案例二:
原始文本:
021-1234-1234
022-1234-1235
023-1234-1236
024-1234-1237
025-1234-1238
026-1234-1239
027-1234-1230
要求:匹配出 城市号、地区号、个人号码三组
(.* ?)-(.* ?)-(.* ?)\n
结论:
通过一个正则表达式可以提取出多组数据,每组数据设置对应的左边界和右边界即可
每一组数据都可以有一个或者多个值
正则表达式提取器
什么时候可以使用正则表达式提取器
任意格式的响应数据,都可以使用正则表达式提取器进行提取
使用正则表达式提取器的操作步骤:
1、添加线程组
2、添加http请求
3、添加正则表达式提取器
引用名称:存放提取出的值的参数名称,如填写title
正则表达式:左边界(.*?)右边界
模板:用$$引用起来,表示解析出第几个()的值
匹配数字:1表示第一个值,-1表示所有取值
4、添加http请求-百度
引用正则表达式中的引用名称。如:用 ${title}引用它
5、添加查看结果树
案例1:获取传智播客首页的title,并作为参数传递
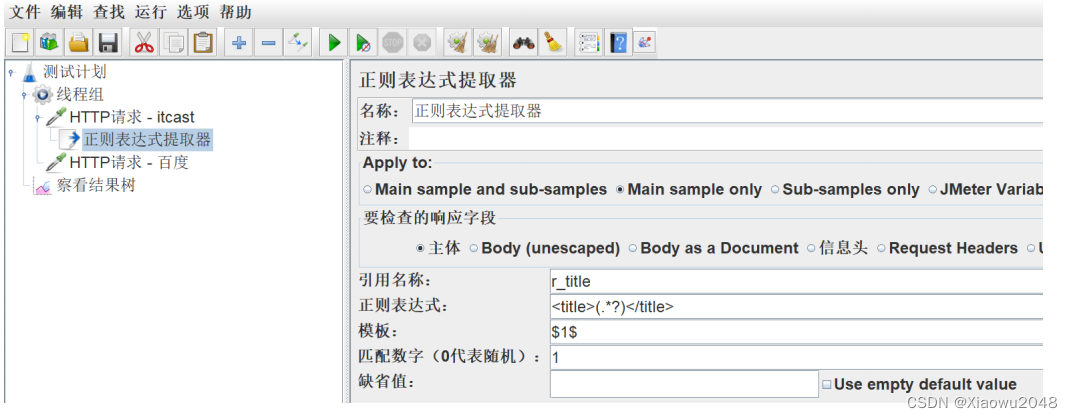
案例2:获取传智播客首页的地址,把第5个校区地址作为参数传递(span为地址的校区)
响应中的地址格式显示: < p>< span>地址</ span>上海市浦东新区航头镇航都路18号万香创新港
添加线程组
添加HTTP请求 - itcast
添加正则表达式 —— 获取第5个地址
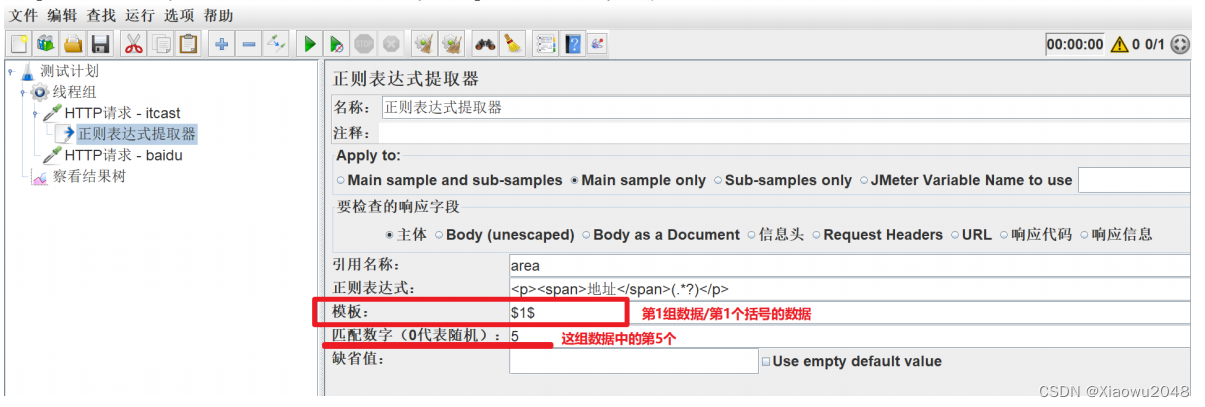
添加HTTP请求 - 百度
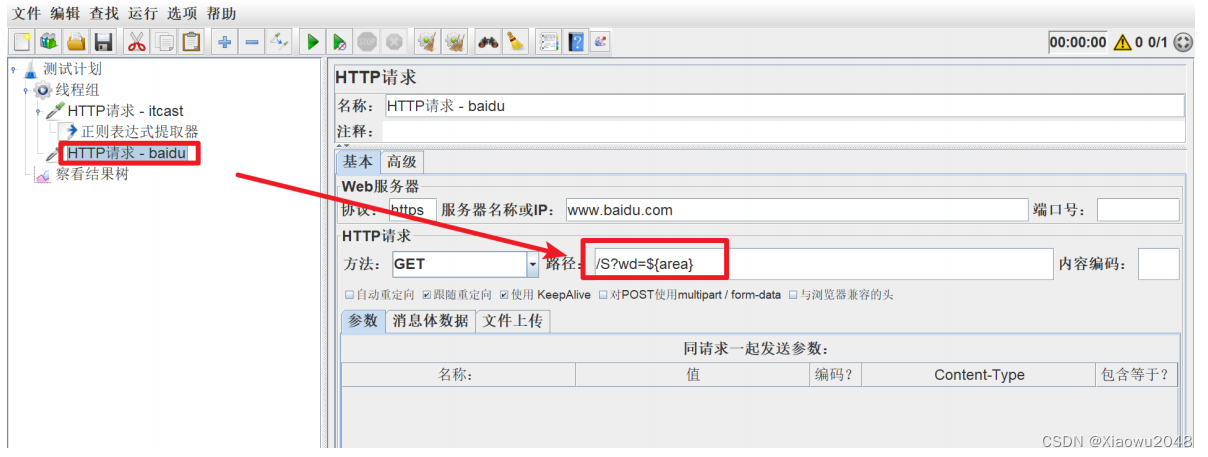
查看结果树
方法2:
添加线程组
添加HTTP请求 - itcast
添加正则表达式 —— 获取所有匹配的地址数据
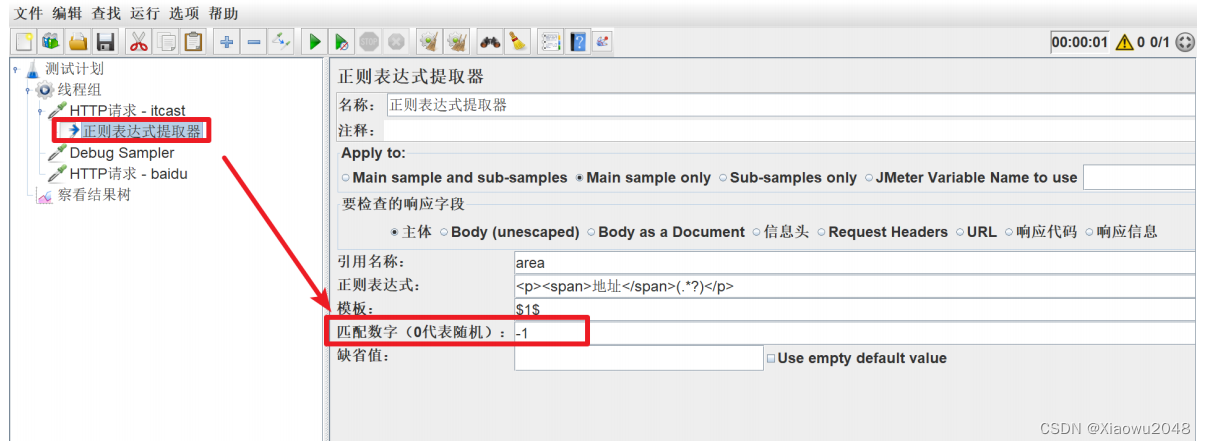
添加Debug Sample
添加HTTP请求 - 百度,引用第5个地址信息,格式:${变量名_索引},索引从1开始
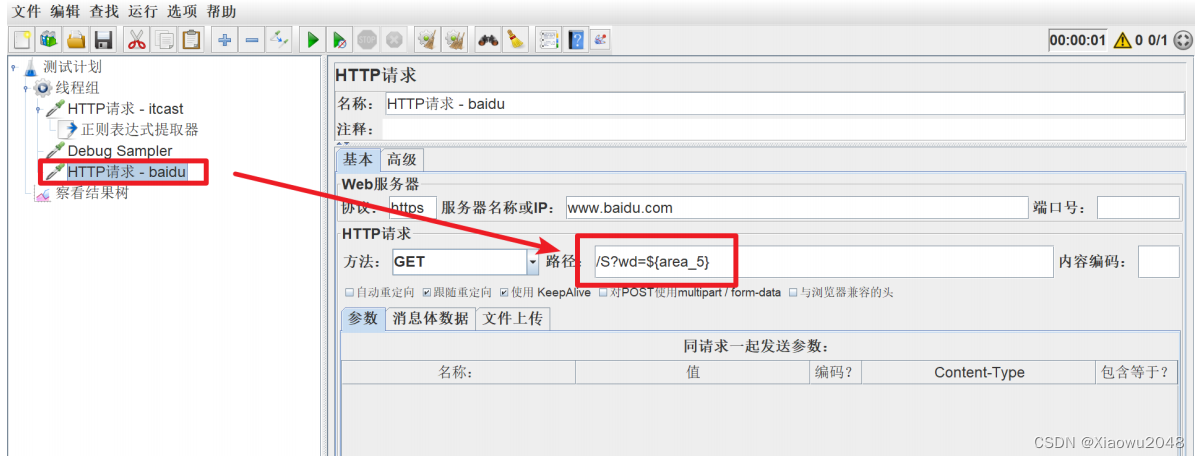
查看结果树
案例3:获取传智播客首页的地址,把第5个校区地址作为参数传递(span为地址/后面带一、二、三)
地址格式1:< p>< span>地址一< /span>昌平区建材城西路金燕龙办公楼一层< /p>
地址格式2:< p>< span>地址< /span>上海市浦东新区航头镇航都路18号万香创新港< /p>
添加线程组
添加HTTP请求 - itcast
添加正则表达式提取器 - 地址信息
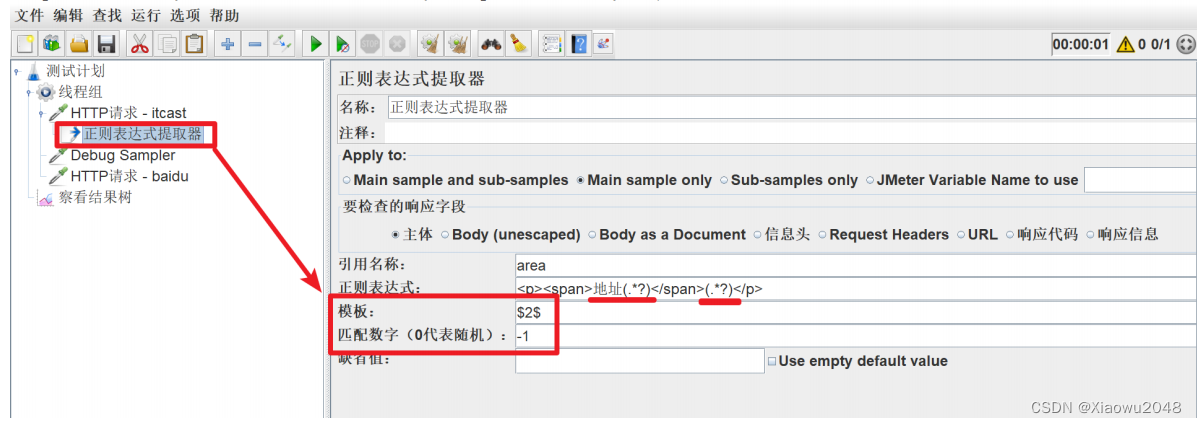
添加HTTP请求 - 百度
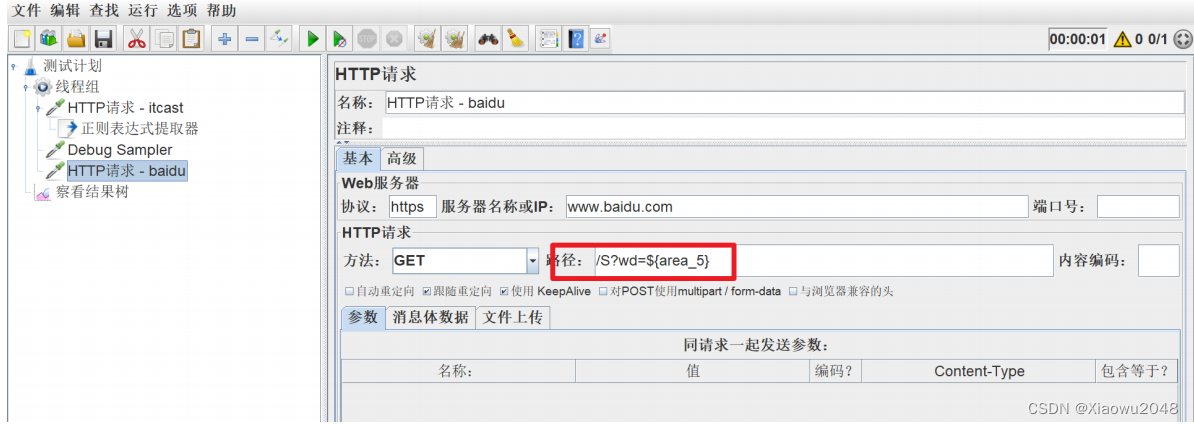
添加查看结果树
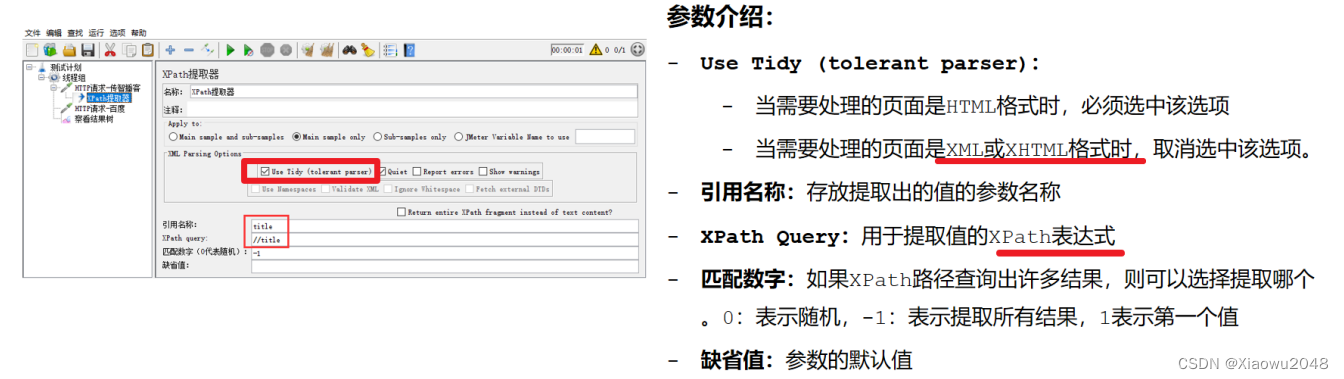
xpath提取器
案例:
//a : 找出所有的a标签
//a[@id=‘kw’]: 在HTML页面中,找出a标签(有一个属性为id,且id的值为kw)
//b[@name=‘kw’]: 在HTML页面中,找出b标签(有一个属性为name,且name的值为kw)
案例2:获取itcast中的title标签,
使用://title
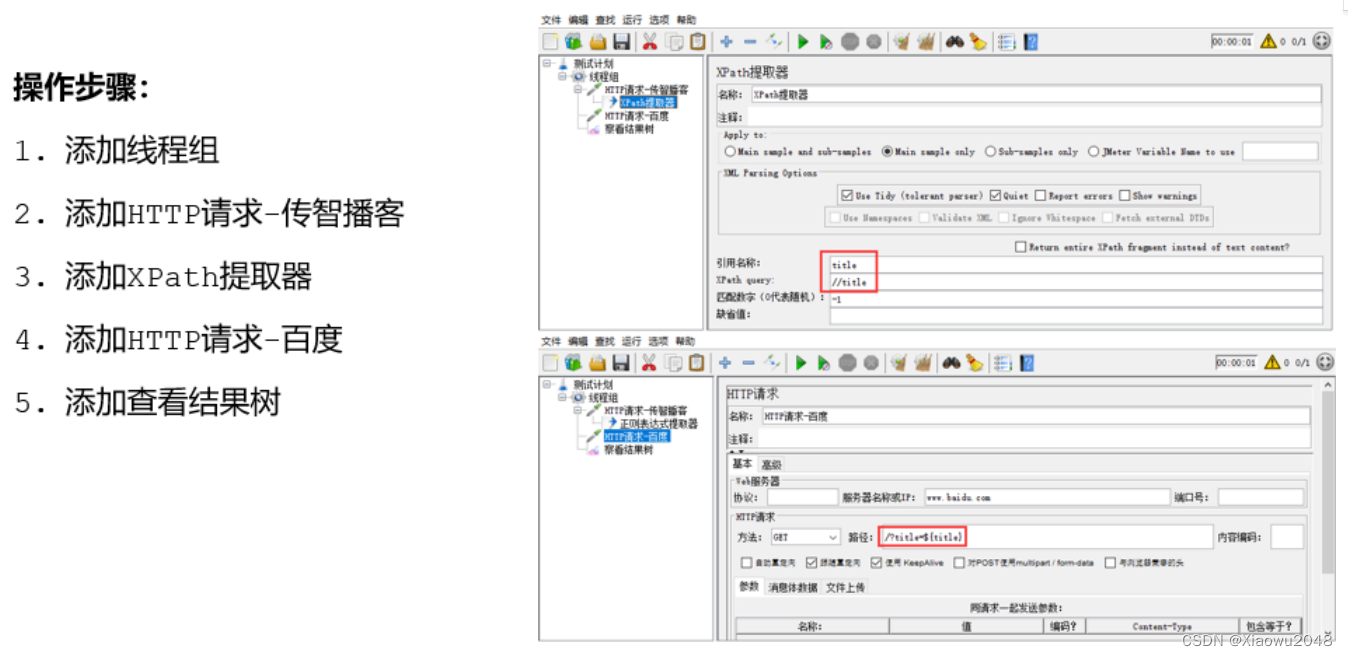
案例:获取传智播客首页的title,并作为参数传递
json提取器

案例:提取天气接口中的城市信息,作为参数在访问百度首页时传递
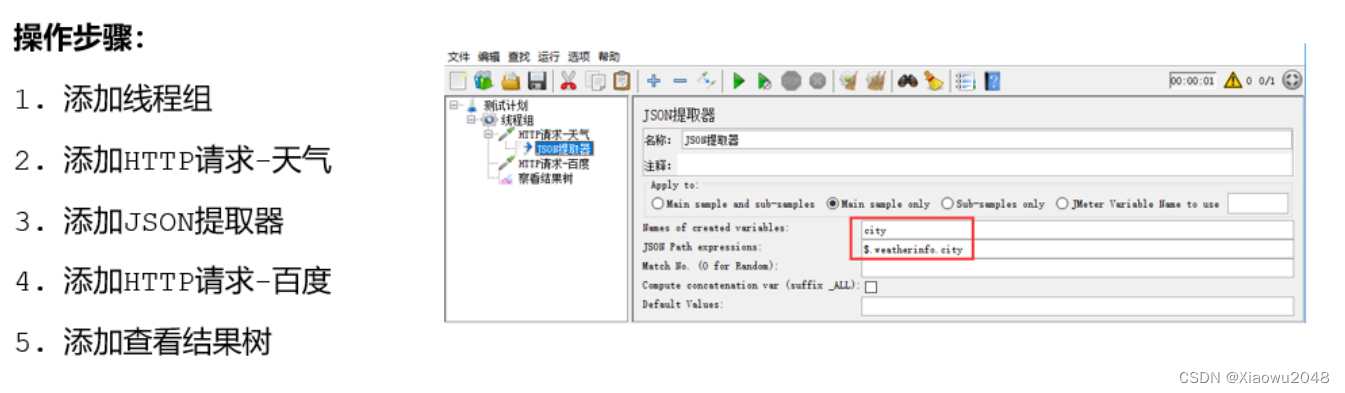
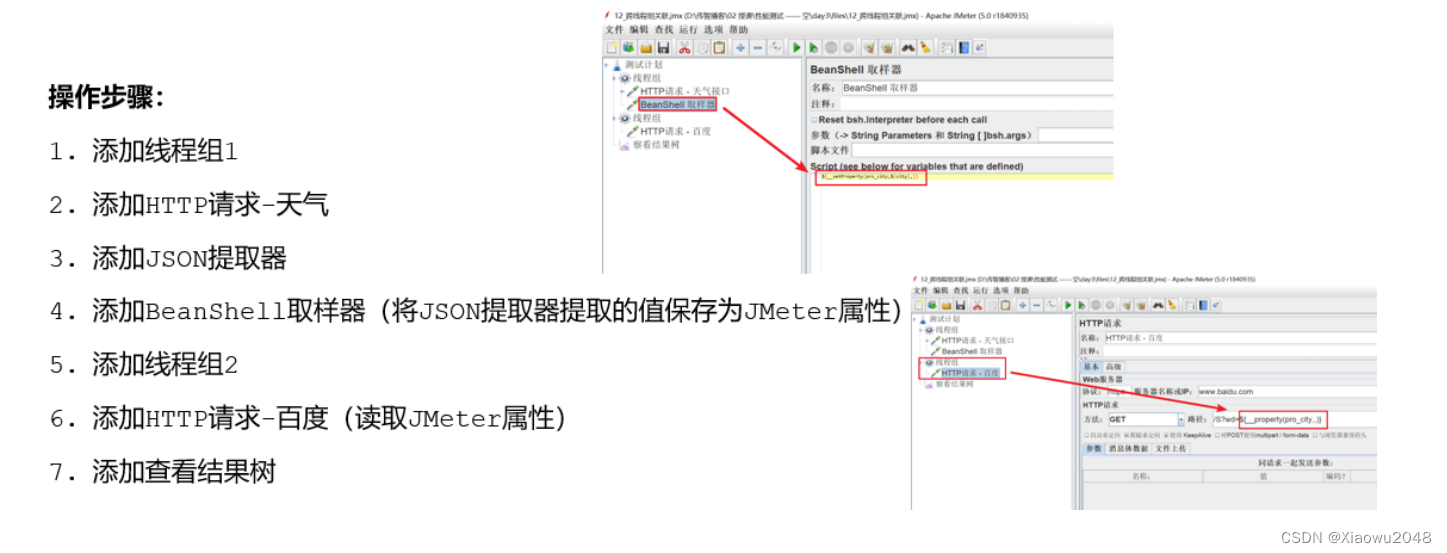
jmeter属性
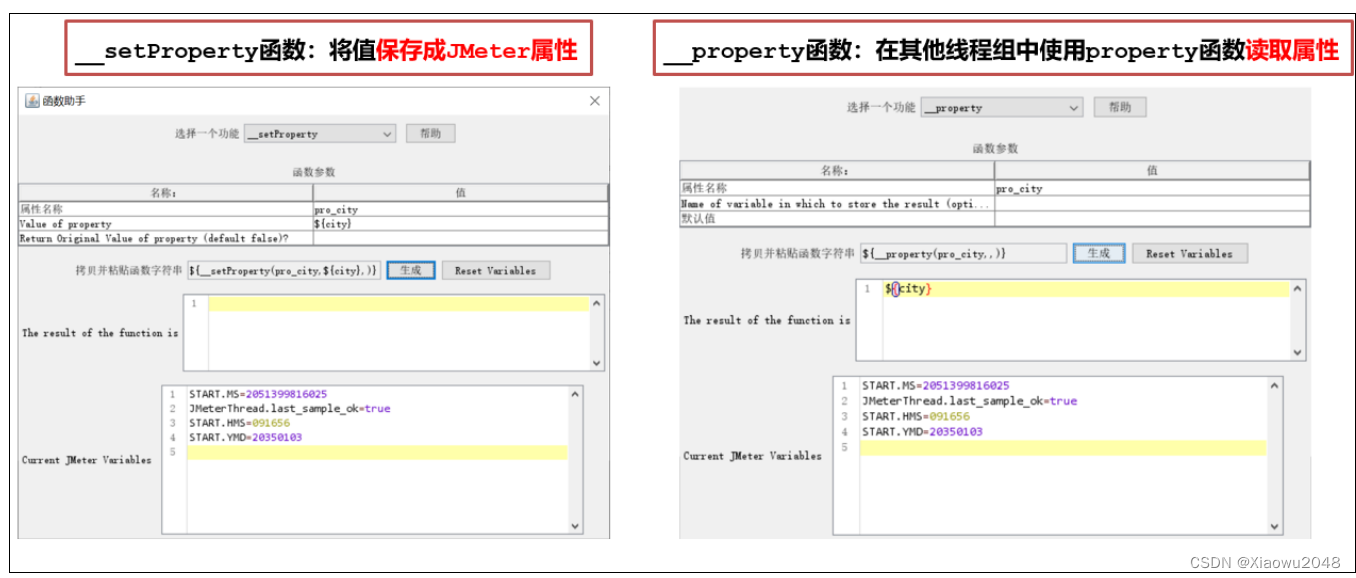
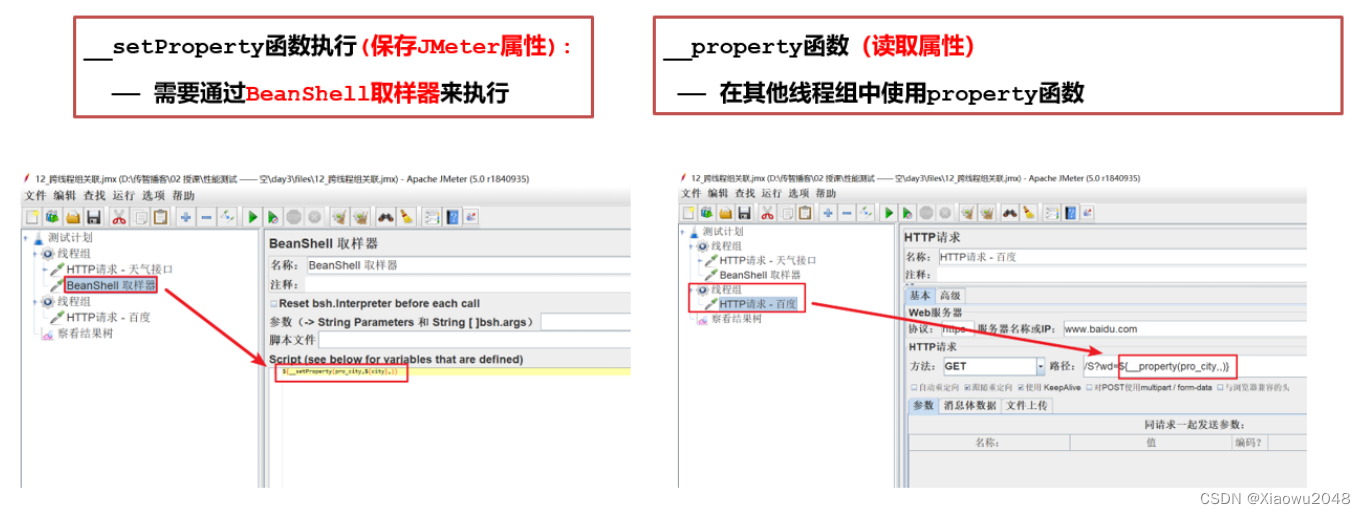
案例:
1、线程组1:请求获取天气的接口,http://www.weather.com.cn/data/sk/101010100.html,获取返
回结果中的城市名称“北京”**
2、线程组2:请求https://www.baidu.com/s?wd=北京 ,把获取到的城市名称作为请求参数**
jmeter自动录制脚本
原理:
录制时,jmeter作为代理服务器来拦截和转发请求与响应数据
jmeter脚本录制:
1、添加HTTP代理服务器,并进行配置
加http代理服务器:测试计划(右键)->非测试元件->http代理服务器
配置代理服务器参数:
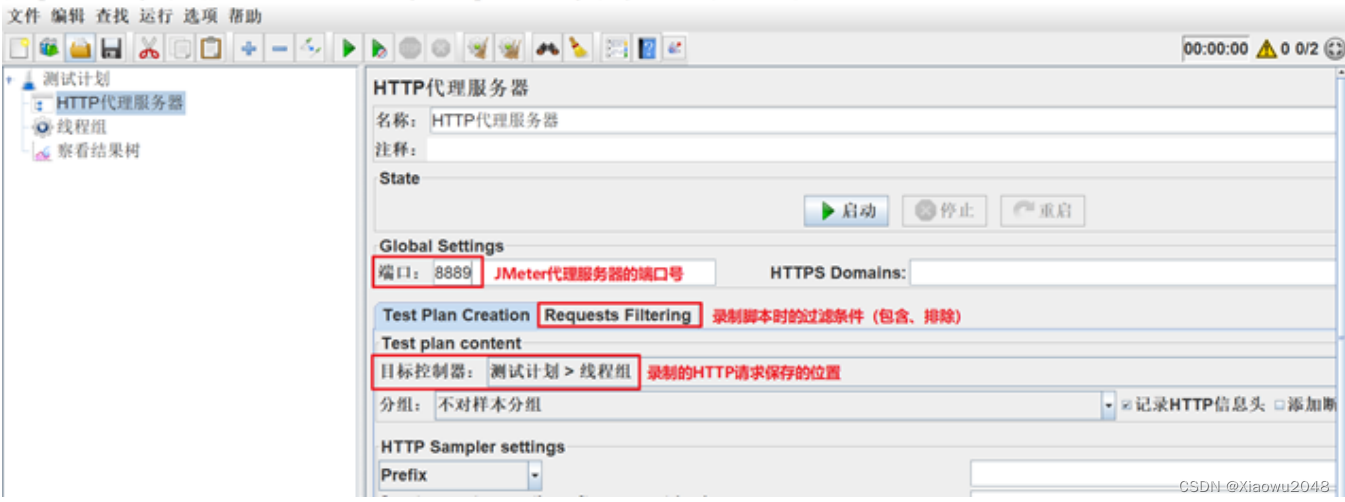
2、开启Windows操作系统的浏览器代理

3、启动代理服务器,开始录制
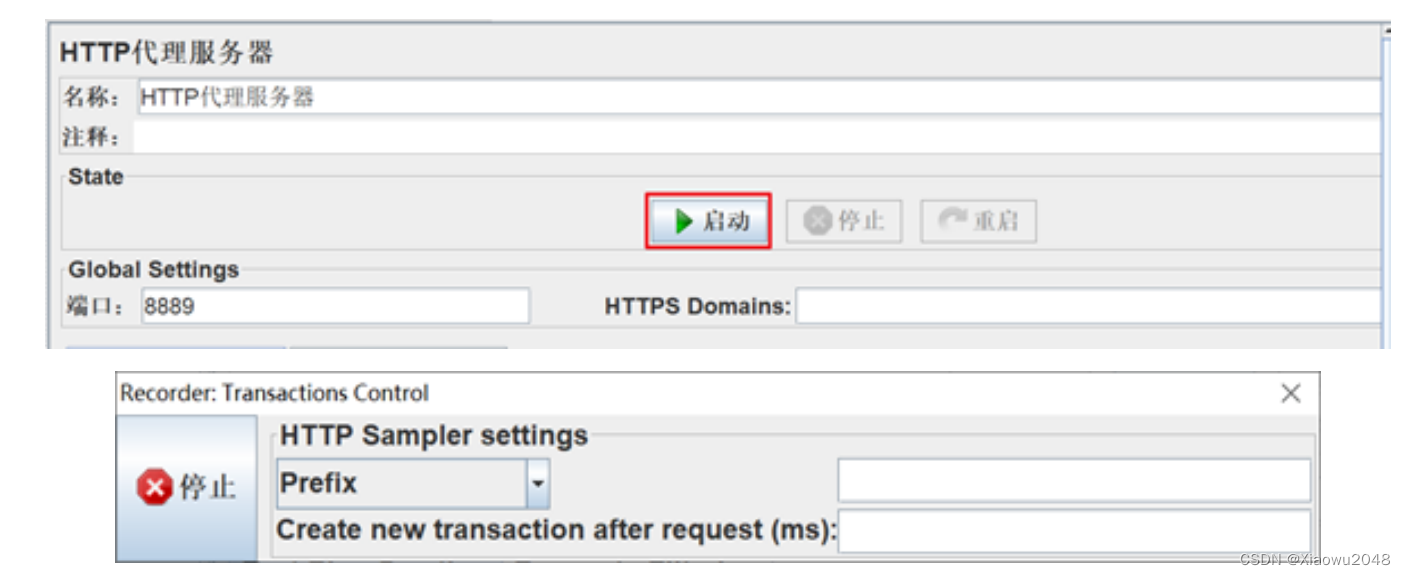
4. 在浏览器页面中进行操作,成功后,就能在JMeter当中看到抓取到的接口请求了
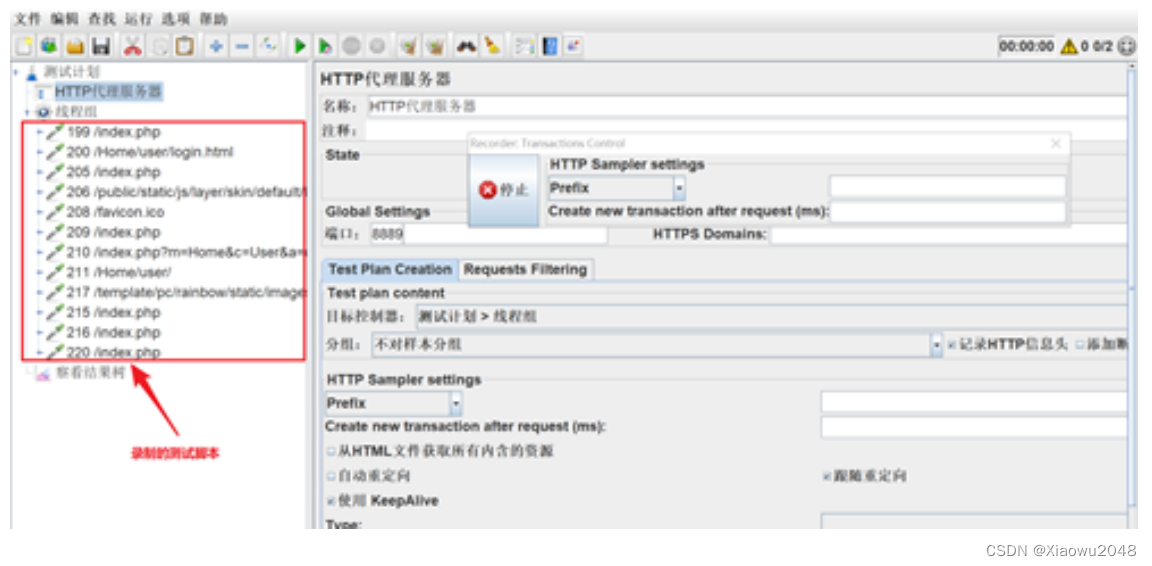
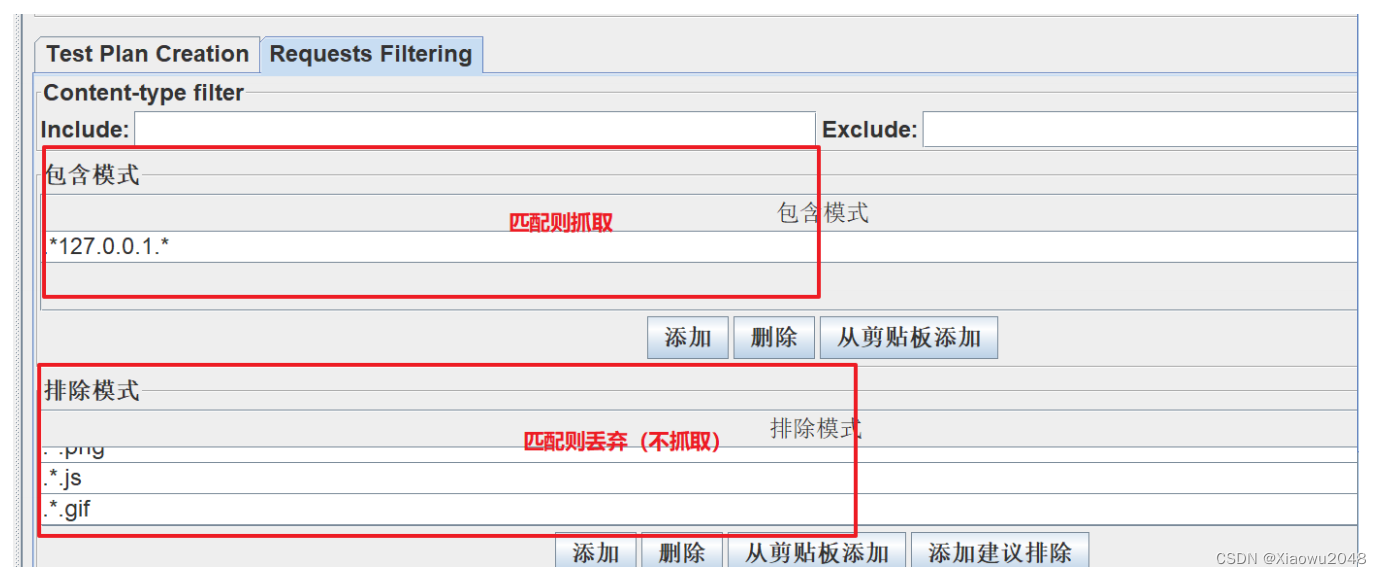
当使用代理的过程中,发现抓不到包,几个可能的情况:
过滤规则设置有问题
重启Jmeter代理服务器或者重启Jmeter
换浏览器来使用(Chrome、IE)
检查PC机中的代理设置是否处于可用状态
拔掉网线,抓包
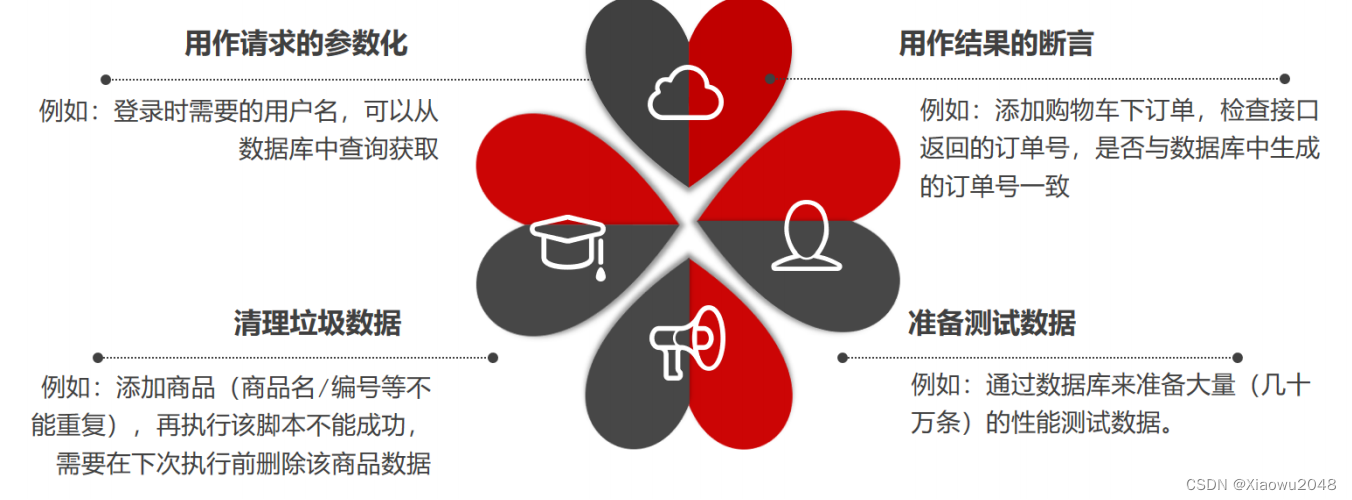
jmeter直连数据库
直连数据库的作用
直连数据库
步骤:
•添加MySQL驱动jar包
-方式一:在测试计划面板点击“浏览…“按钮,将你的JDBC驱动添加进来
-方式二:将MySQL驱动jar包放入到lib/ext目录下,重启JMeter
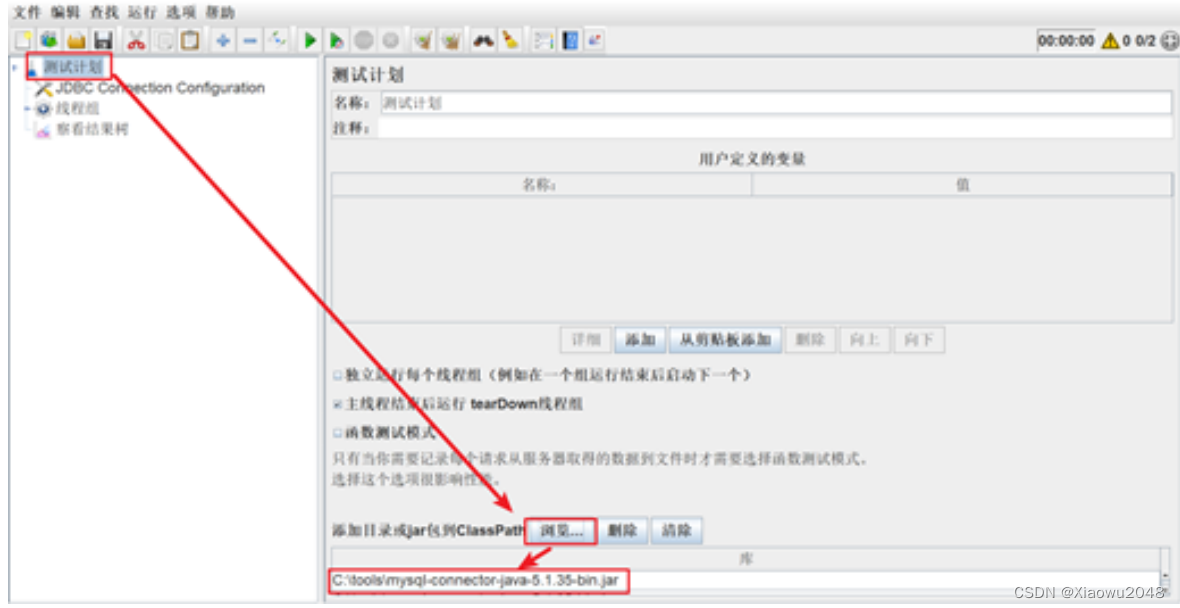
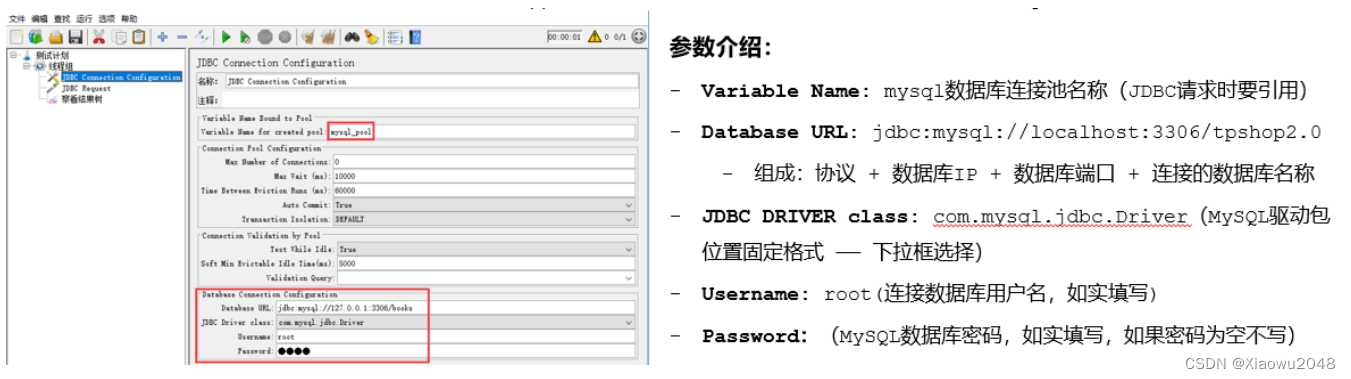
配置数据库连接信息
-添加方式:测试计划 --> 线程组–> (右键添加) 配置元件 --> JDBC Connection Configuration
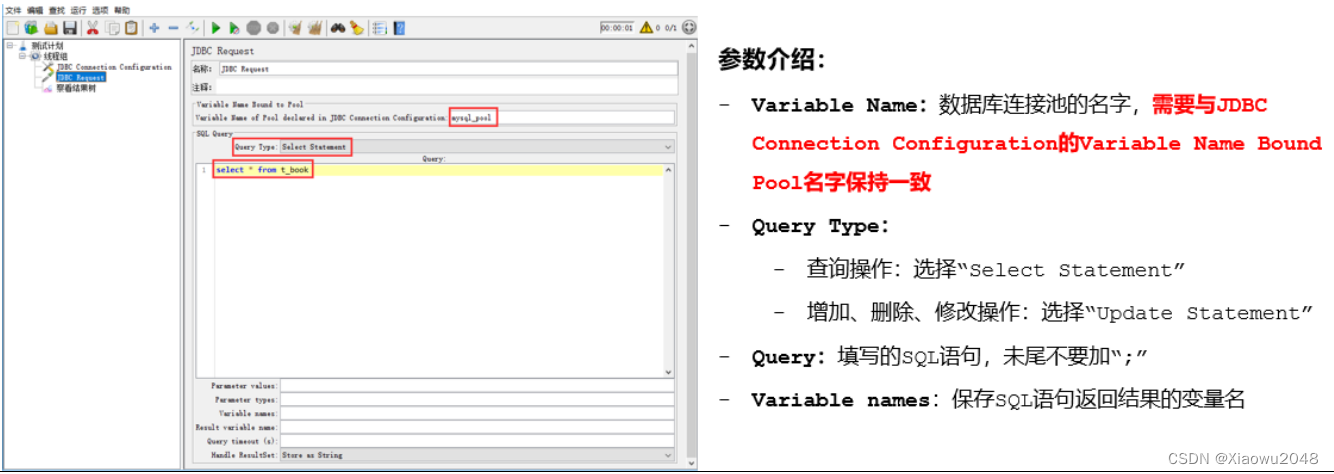
添加JDBC请求:
添加方法:测试计划–线程组–取样器–JDBC Request
案例1:
连接tpshop商城数据库获取商品名包含:小米手机5的商品id
1、添加MySQL驱动的jar包
在测试计划面板点击“浏览”按钮,将你的JDBC驱动添加-本脚本可用
将mysql驱动jar包放入lib/ext目录下,重启jmeter -所有脚本可用
2、配置数据库连接信息
数据库连接池名称、数据库URL(协议+数据库IP+数据库端口+连接的数据库名称)、数据库驱动包(下拉框选择)、数据库用户名密码
3、添加JDBC请求
数据库连接池名称、Query Type、SQL语句、查询结果保存的变量名
需求:
1、在tpshop首页中搜索商品名称“长虹(CHANGHONG) 49A1U 49英寸双64位4K超清智能网络LED液晶
电视”,
请求URL:http://127.0.0.1/Home/Goods/search.html
请求方法:GET
请求参数:q=
2、在搜索的响应数据中检查是否有该商品对应的商品链接:/Home/Goods/goodsInfo/id/65.html
(id:65需要通过数据库查询返回,才保证每次都是有效的)
编写JDBC脚本步骤(搜索指定商品,在返回结果中检查是否包含指定商品的ID的详情URL):
1.添加线程组
2.添加 JDBC Connection Configuration
3.添加 JDBC request
4.添加 HTTP请求 - 搜索商品
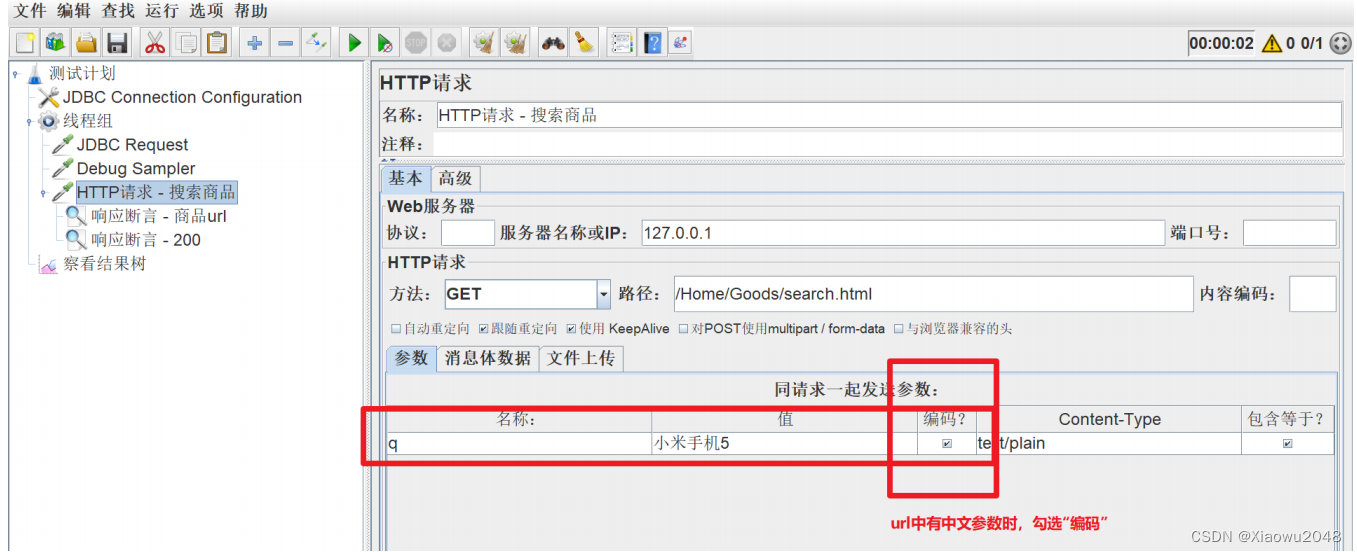
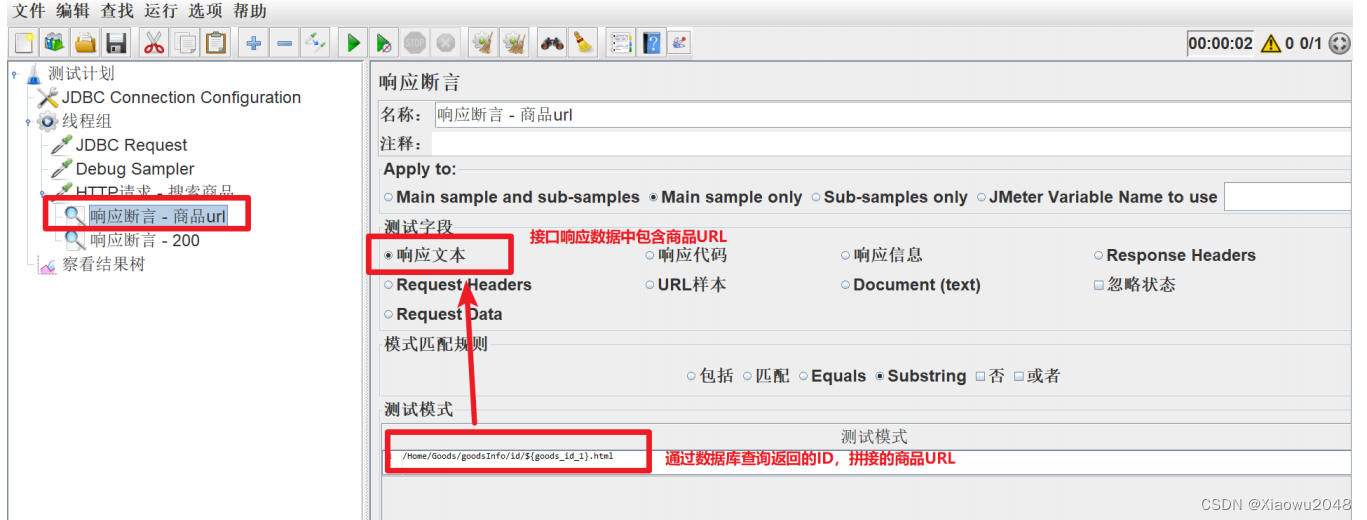
5.在搜索HTTP请求下,添加响应断言,检查响应结果中的字符 是否包含 **商品URL。引用格式:${变
量名_索引}
6.添加查看结果树
jmeter逻辑控制器
如果(if)控制器
作用:if控制器用来控制它下面的测试元素是否运行
位置:测试计划-线程组-(右键添加)逻辑控制器-如果(if)控制器
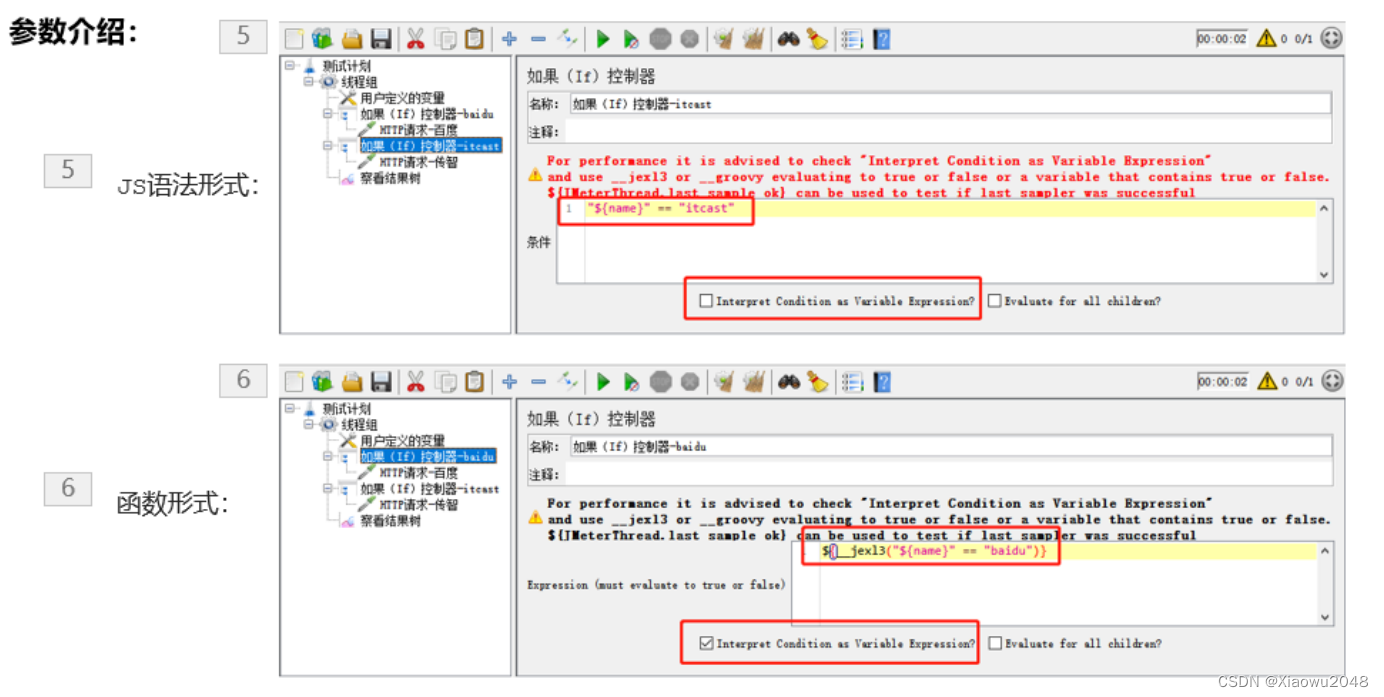
案例:
1、使用‘用户定义的变量’定义一个变量name,name的值可以是baidu或itcast
2、根据name的变量值实现对应网站的访问
1、添加线程组
2、用户定义的变量
3、添加if控制器,判断name是否等于baidu
不勾选interpret condition,‘$ {name}’ == ‘baidu’
勾选,$ {_jex13(‘$ {name}’ == ‘baidu’,)}
4、添加http请求,用来访问百度
5、添加if控制器,判断name是否等于itcast
6、添加http请求,用来访问传智
7、添加查看结果树
循环控制器
位置:测试计划-线程组-(右键添加)逻辑控制器-循环控制器
参数介绍:
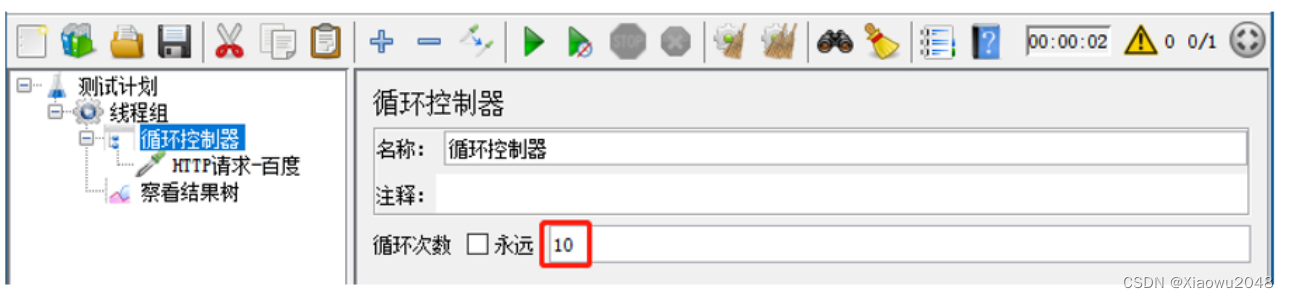
案例:
1、循环访问百度10次
使用循环控制器的操作步骤:
1、添加线程组
2、添加循环控制器-设置循环次数
3、添加HTTP
4、添加查看结果树
(3)思考:线程组属性可以控制循环次数,那么循环控制器有什么用?
控制的作用域不同:线程组控制是线程组下的所有请求,循环控制器控制逻辑控制器下的所有请求
如果线程组循环次数为M,循环控制器循环次数为N:
循环控制器下的HTTP请求运行:M*N次
线程组下的其他HTTP请求运行:M次
ForEach控制器
作用:一般和用户自定义变量或正则表达式提取器一起使用,读取返回结果中一系列相关的变量值,该控制器下的取样器都会被执行一次或多次,每次读取不同的变量值
位置:测试计划–线程组–(右键添加)逻辑控制器–ForEach控制器
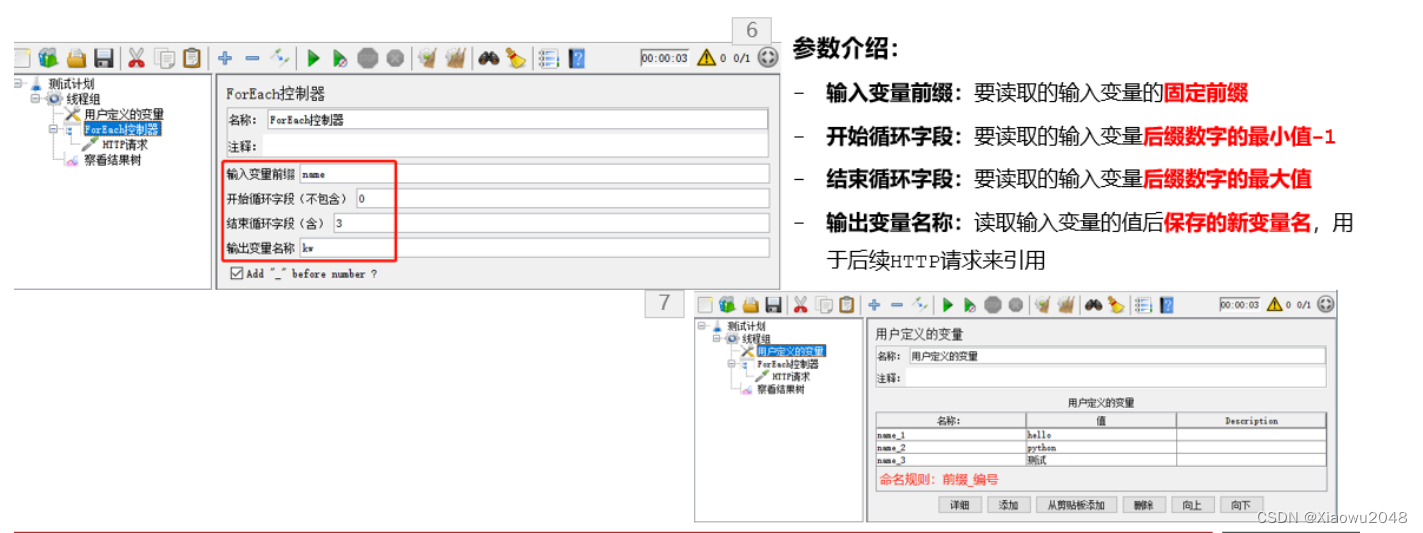
与用户定义的变量配合使用(案例1):
案例1需求
- 有一组关键字 [hello,python,测试],使用用户定义的变量存储
- 要依次取出关键字,并在百度搜索,例如:https://www.baidu.com/s?wd=hel
步骤:
1.添加线程组
2.添加用户定义的变量
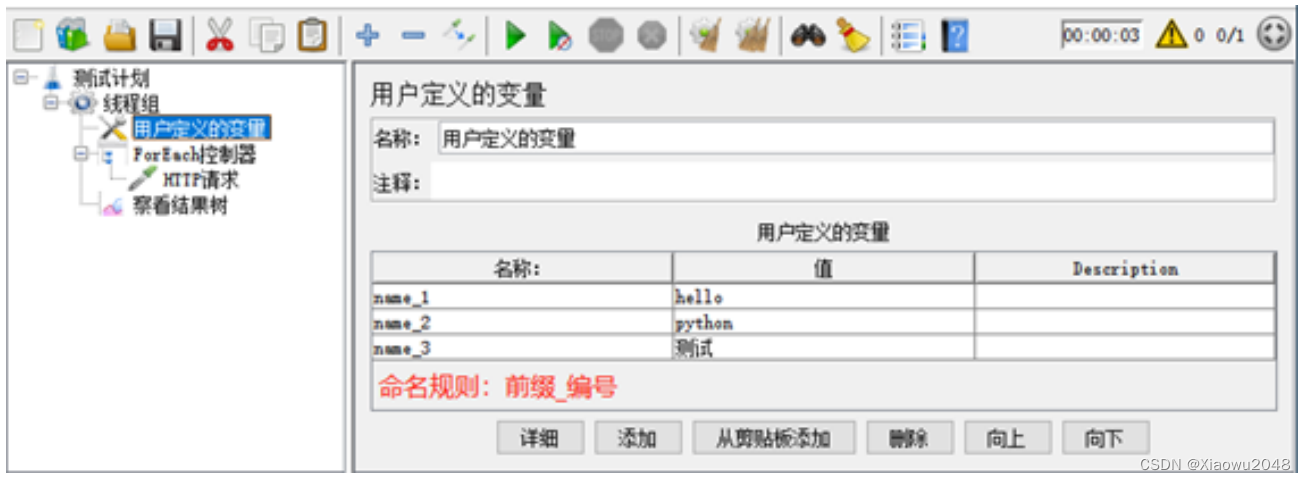
3.添加ForEach控制器
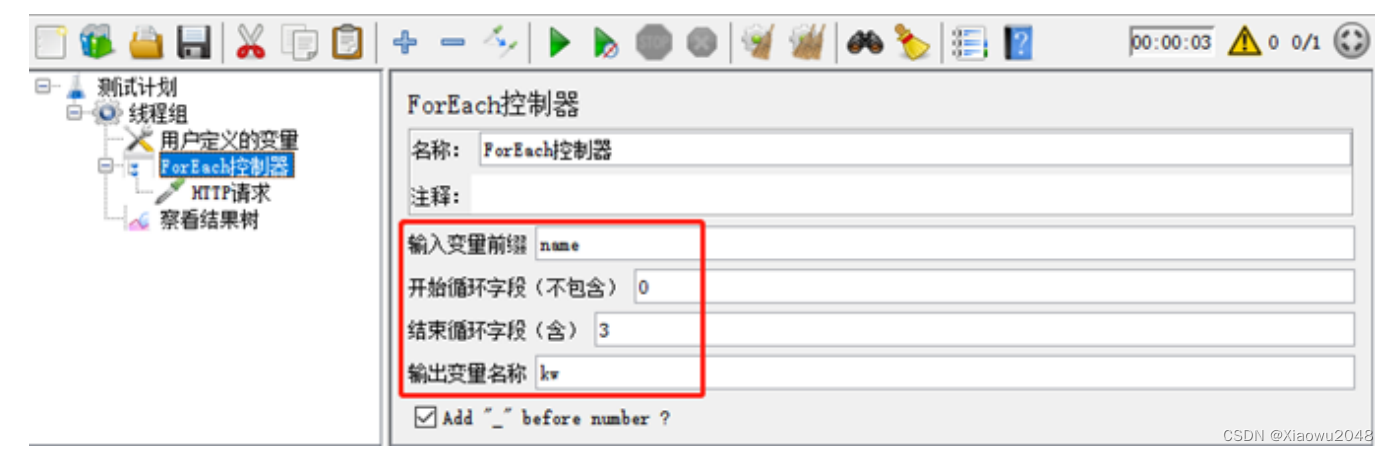
4.添加HTTP请求-百度
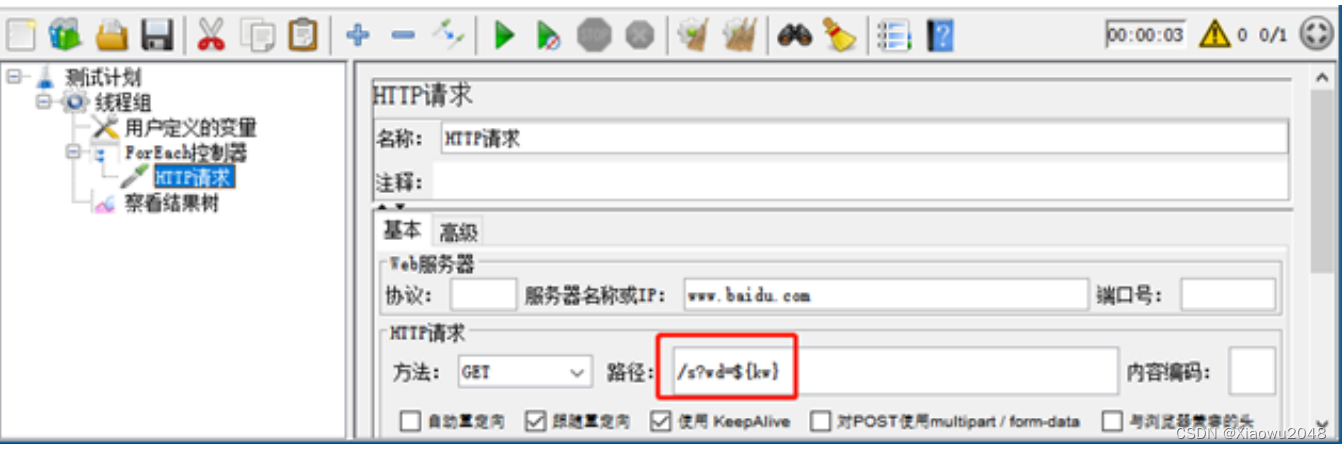
5.添加查看结果树
与正则表达式配合使用(案例2):
案例2:
- 访问传智播客首页http://www.itcast.cn,获取首页中的地址信息,并全部保存下来
- 要依次取出地址关键字,并在百度搜索,例如:https://www.baidu.com/s?wd=地址
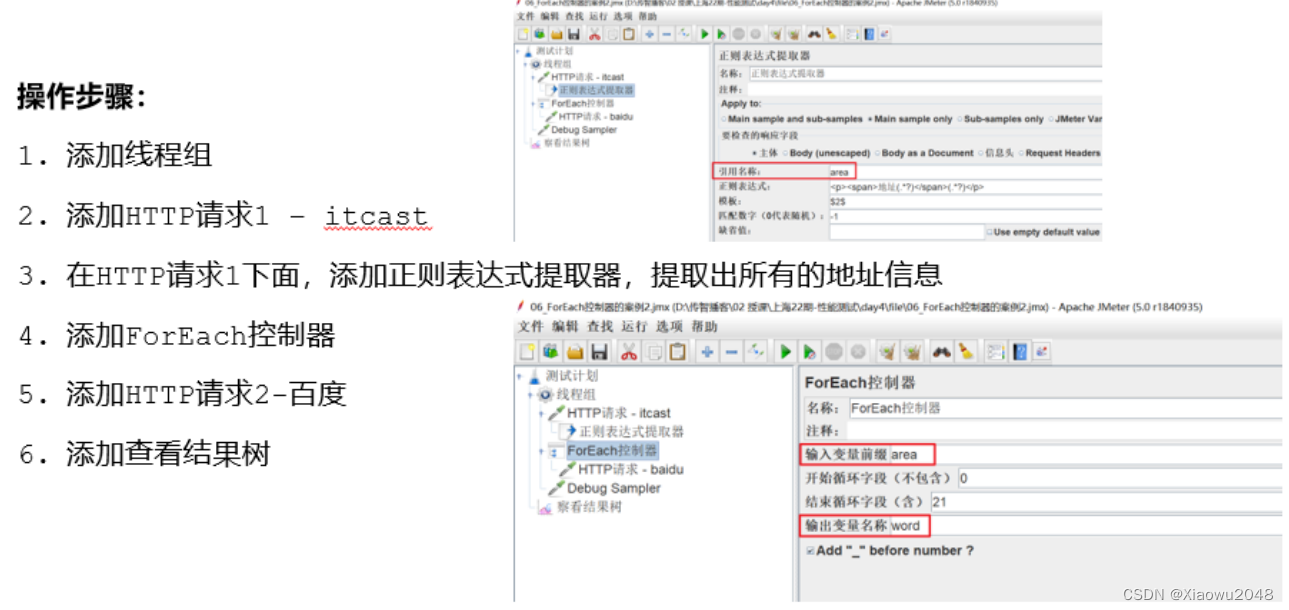
注意:结束循环字段可以设置为空,自动读取到最后一个
jmeter常用定时器
同步定时器
阻塞线程(累积一定的请求),当在规定的时间内达到一定的线程数量,这些线程会在同一个时间点一起释放,瞬间产生很大的压力
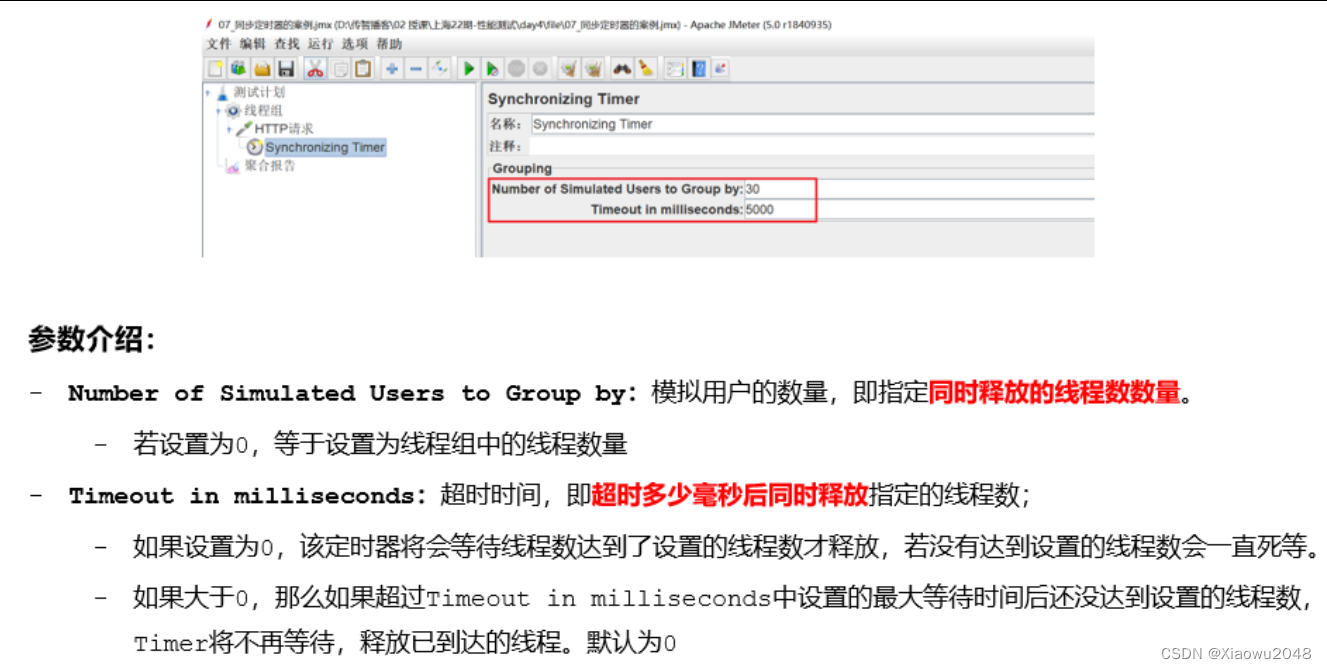
案例:1、模拟100个用户同时访问百度首页,统计各种高并发情况下运行情况
使用同步定时器的操作步骤?
1.添加线程组,设置线程数为n
2.添加HTTP请求
3.添加同步定时器
•设置并发线程数:同时发送请求的虚拟用户数
•设置超时时间:
Ø建议设置:不设置的话,若没有达到设置的线程数会一直死等
Ø不能设置太小:等待时间后还没达到设置的线程数,会释放已到达的线程
4.添加查看结果树
5.添加监听器-聚合报告
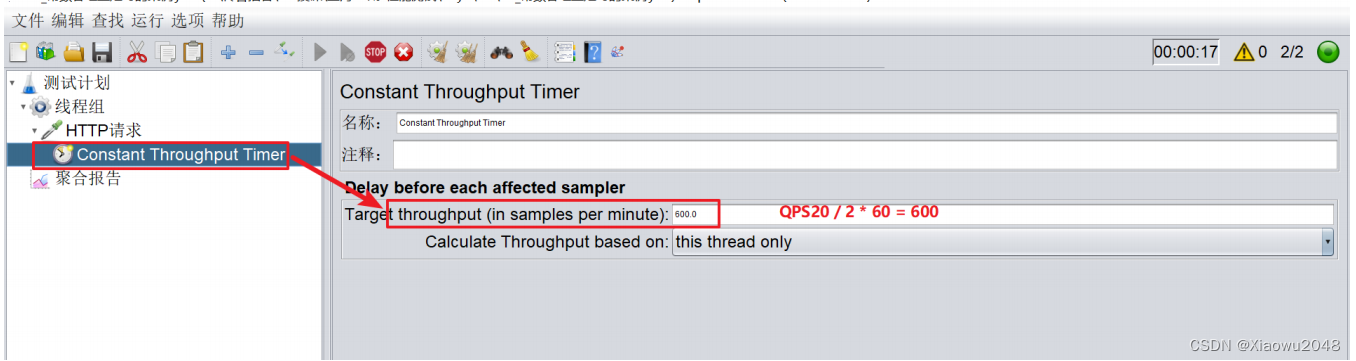
常数吞吐量定时器
案例:
(1)一个用户以 20QPS (20 次/s) 的频率访问百度首页,持续一段时间,统计运行情况
案例:1、模拟100个用户同时访问百度首页,统计各种高并发情况下运行情况
(2)2个用户针对 (服务器的QPS要求:20QPS (20 次/s)) 的频率访问百度首页,持续一段时间,统
计运行情况
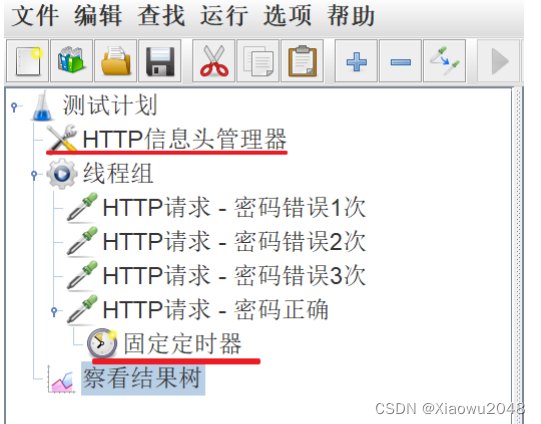
固定定时器
案例:
(1)IHRM系统登录错误3次后,锁定1分钟,等待1分钟后重新输入正确的用户名密码登录成功
请求方法:POST
请求URL:http://ihrm-test.itheima.net/api/sys/login
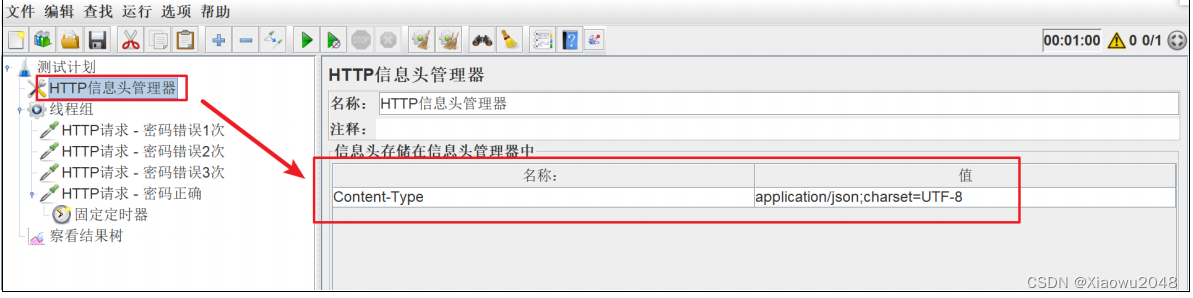
请求头:Content-Type: application/json;charset=UTF-8
请求体:{“mobile”:“13800000002”,“password”:“123456”}
步骤:
添加线程组
添加HTTP请求1 - 错误1次
添加HTTP请求2 - 错误2次
添加HTTP请求3 - 错误3次
添加HTTP请求4 - 正确用户名密码
在HTTP请求4下,添加固定定时器
添加查看结果树
注意:
固定定时器,必须添加在需要等待的HTTP请求的子节点下
在HTTP信息头管理器中,修改HTTP请求的头域
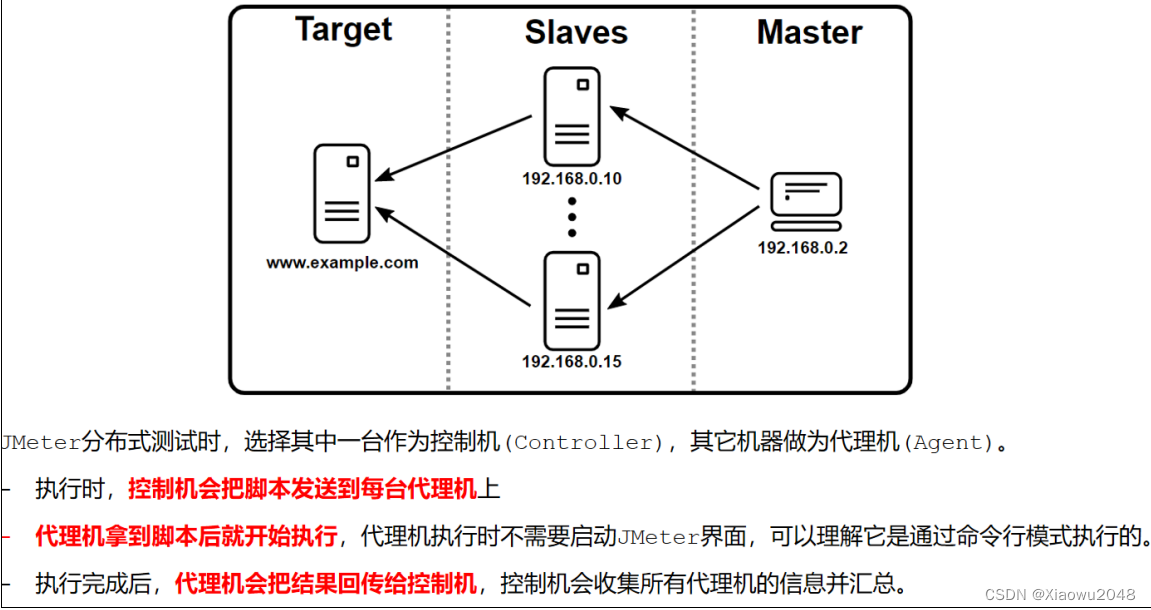
jemter分布式
应用场景:
当单个测试机无法模拟用户要求的业务场景时,可以使用多台测试机进行模拟,就是Jmeter的分布
式测试
原理:
 ## 分布式相关注意事项
## 分布式相关注意事项
关闭防火墙
所有的控制机、代理机、服务器都在同一个网络上
所有机器的Jmeter和JAVA版本必须一致
关闭RMI SSL开关
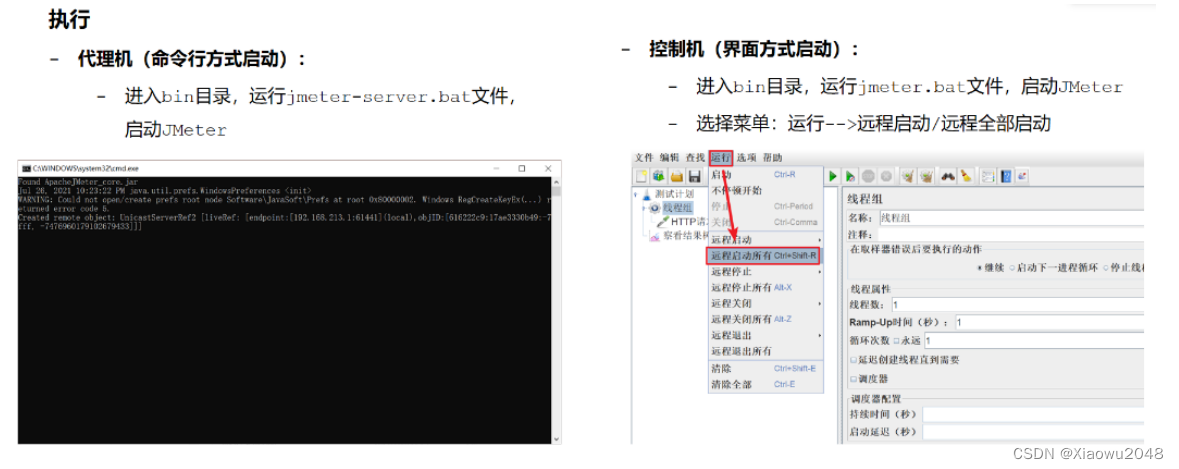
分布式配置与运行
配置 -修改bin/jmeter.properties文件:
代理机:
修改服务端口:保证每个代理机都能正常启动。如果在同一台机器上演示需要使用不同的端口,多台机器可以不修改,例如:server_port =2999
将RMT SSL设置为禁用。例如:server.rmi,ssl.dissable =true
控制机:
配置代理机远程地址:配置每个代理机的IP+port,多个代理机之间用,连接
将RMT SSL设置为禁用。例如:server.rmi,ssl.dissable =true
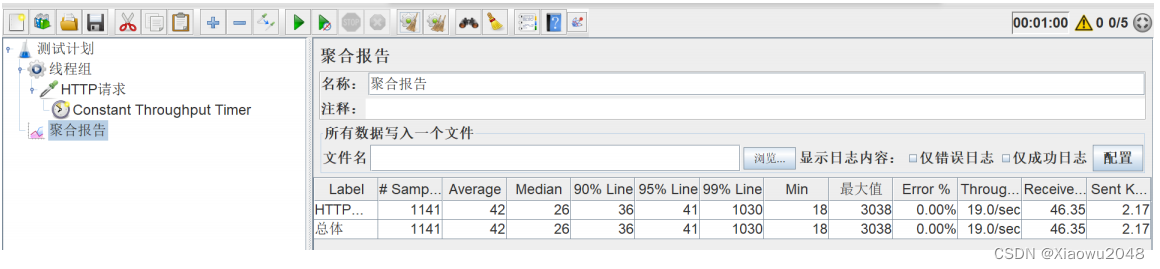
jmeter报告
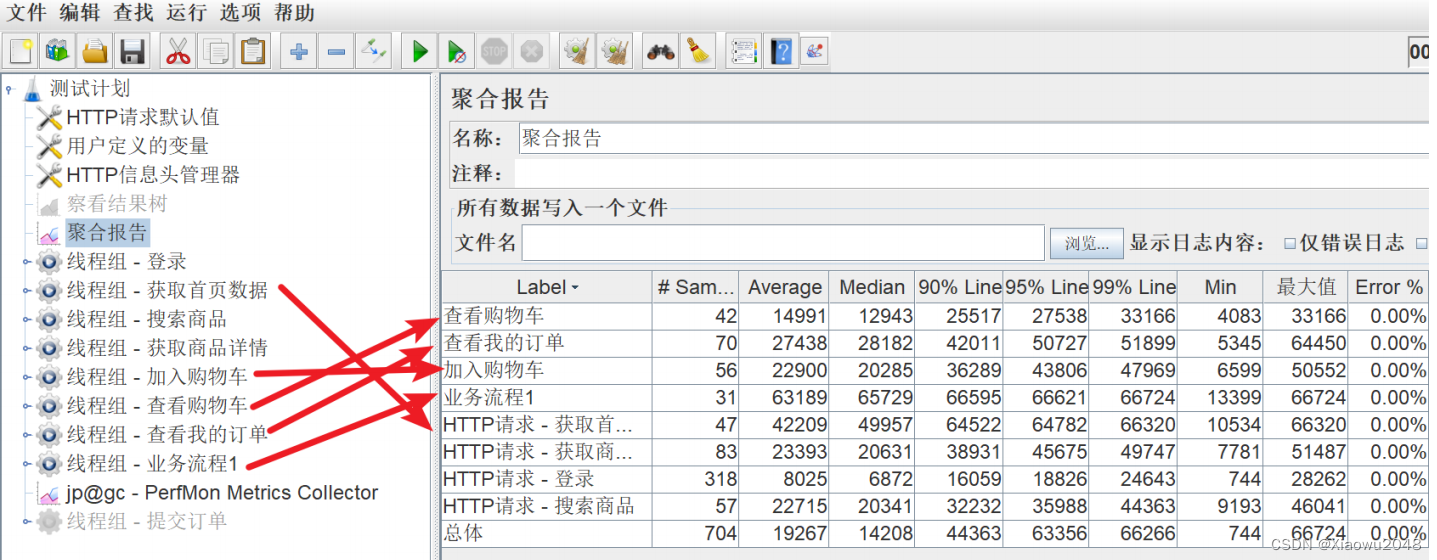
聚合报告
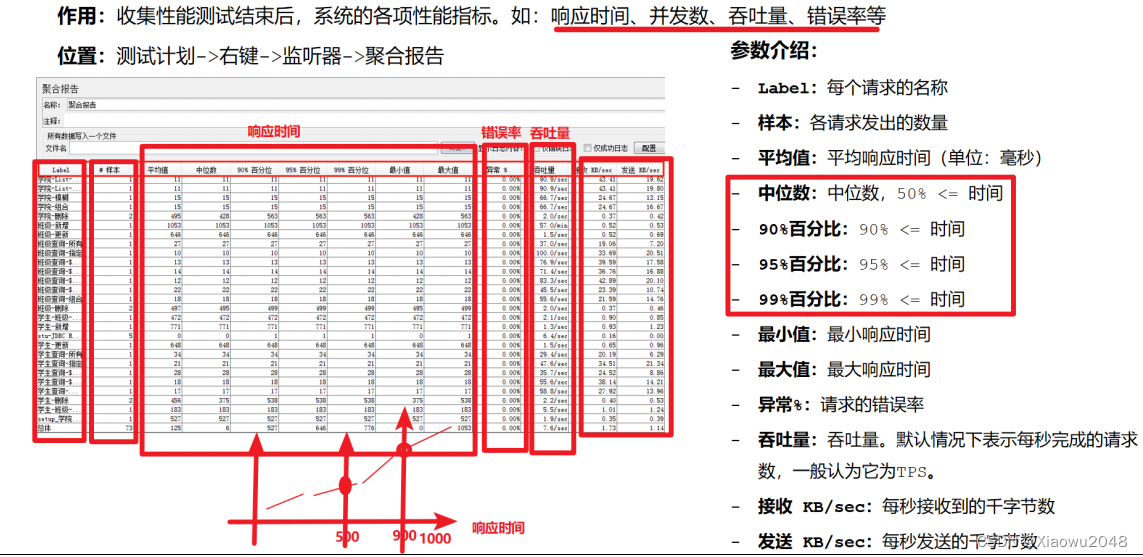
补充:
正常情况下,响应时间的结果取平均值
当响应时间最大值特别高(超出平均水平特别多),导致平均值不能代表正常/大部分水平时,可
以使用百分比时间
案例:
1、请求:https://www.baidu.com
2、模拟5个用户并发,控制服务器QPS为20,运行时长设置为10分钟
3、添加聚合报告,收集系统性能指标:响应时间、吞吐量、错误率、网路速率
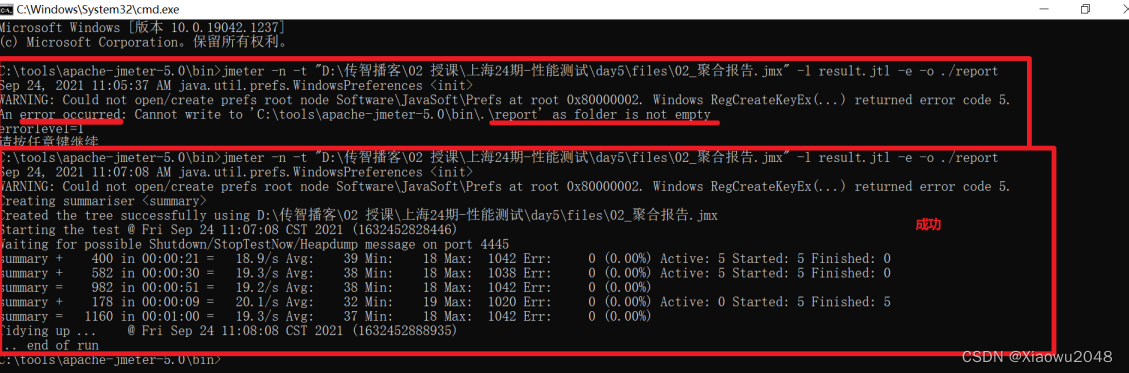
HTML报告
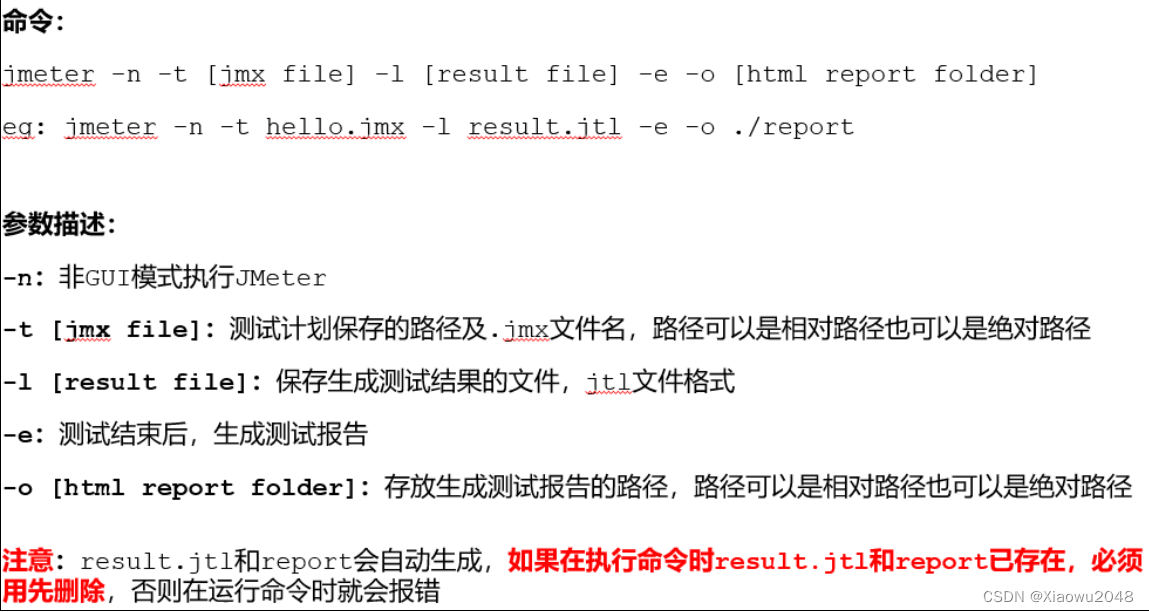
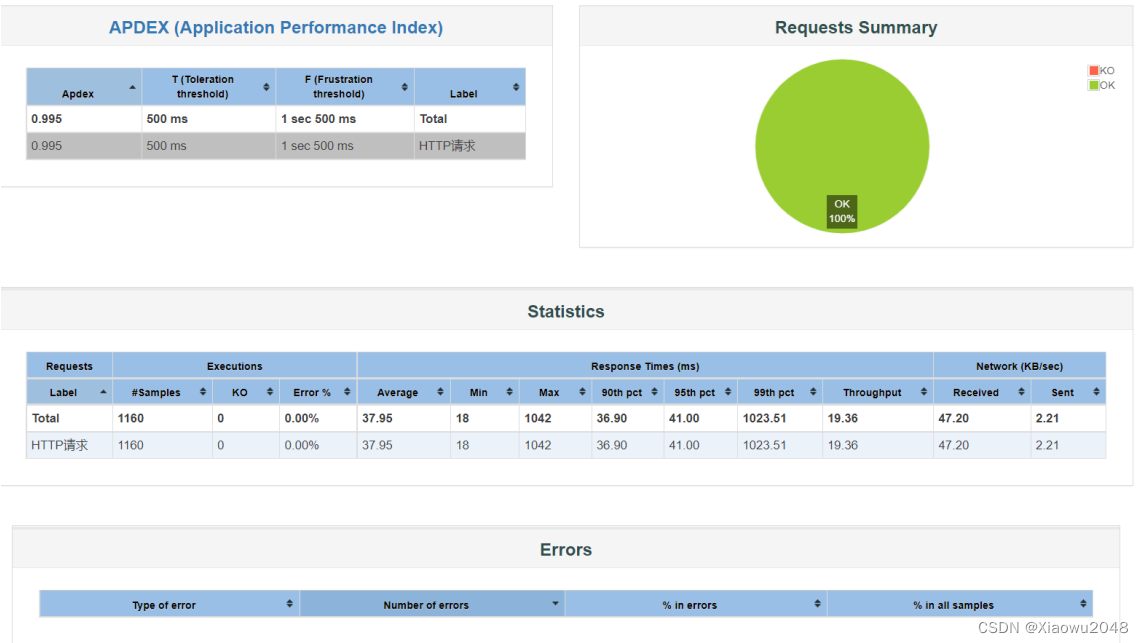
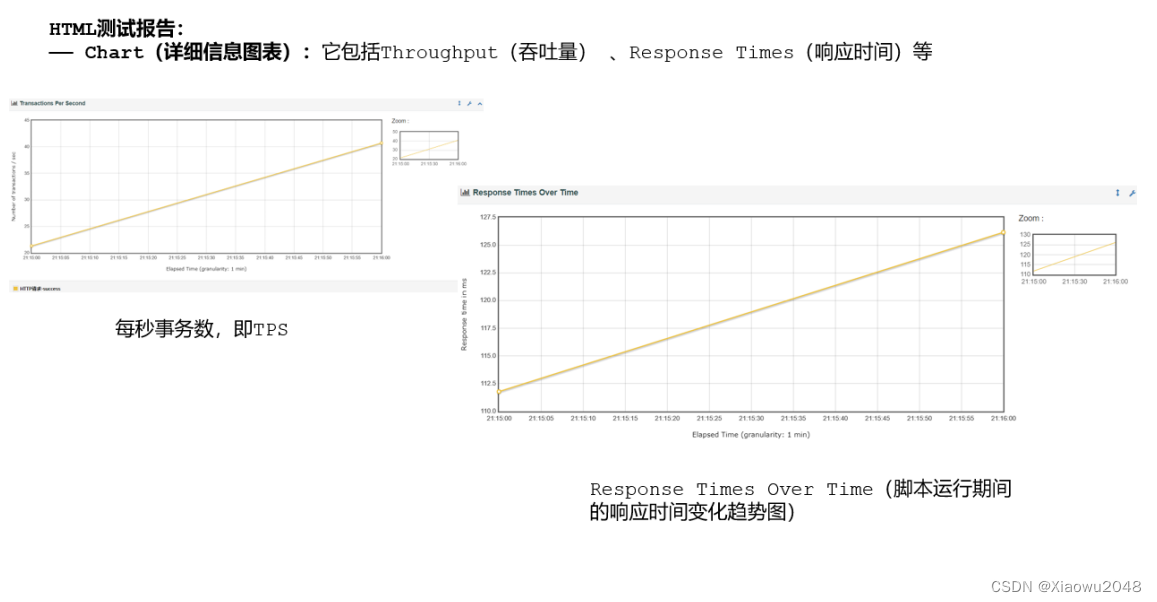
Jmeter测试报告的内容介绍:
仪表盘统计:
详细信息:
注意:在执行时,需要删除对应目录下的report文件和report.jtl文件,否则运行生成html报告的命令
会报错。
并发数计算:
普通方法:
并发tps = 总请求数/总时间
只能满足最基本的要求,但是不能很好覆盖系统正常的使用情况
二八原则:
并发tps = 总请求数 * 80% / 总时间 * 20%
满足系统绝大多数情况下的应用场景的需要
根据业务运营数据的统计计算(通常用来做稳定性测试)
并发TPS = 有效请求数 * 80% / 有效时间 * 20%
当运营数据统计越精确时,计算出的并发TPS与实际的越接近
根据用户峰值业务操作来计算(通常用来做压力测试)
并发TPS = 峰值请求数 / 峰值时间 * 系数
满足峰值请求时间段内的负载量,系数取决于项目组对于未来业务量的评估
安装jmeter性能测试需要的组件
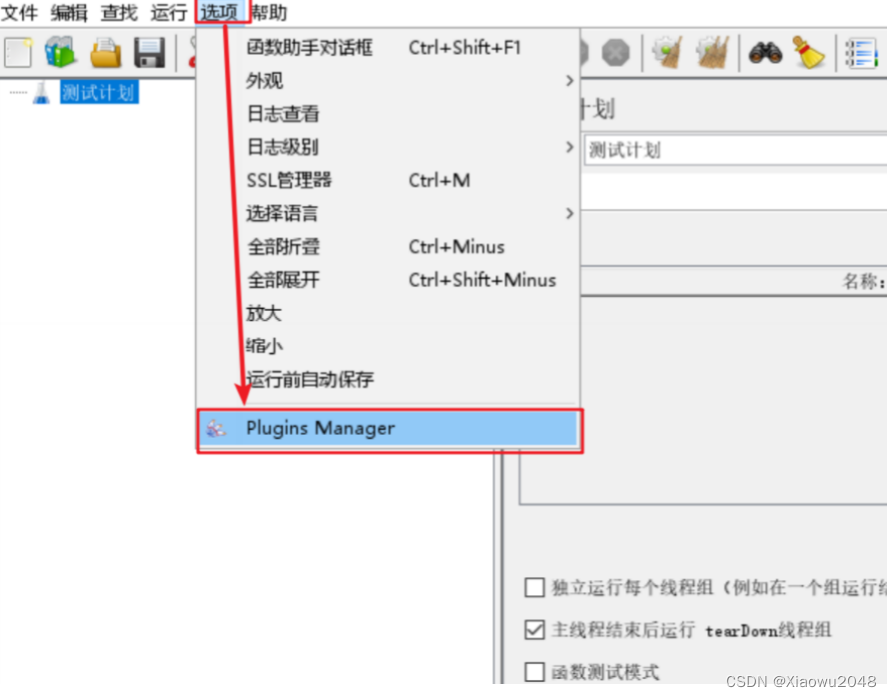
(1)安装插件管理器
在Jmeter官网上下载插件管理器Plugins-manager-1.3.jar
将JAR包放入到lib\ext目录下
重启Jmeter,可以在选项下看到Plugins Manager选项
(2)安装指定的插件
打开Plugins Manager插件管理器
选择Available Plugins,当前可用的插件
选择需要下载的插件(等待右方文本内容展示出来)
下载右下角的下载按钮,自动的完成下载,Jmeter会自动重启
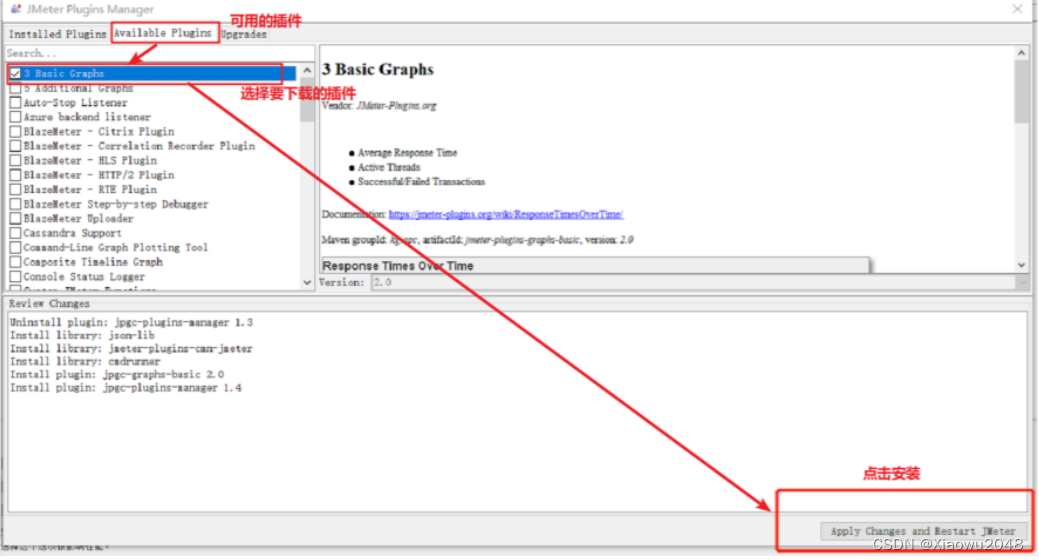
需要下载的插件:
并发数及Jmeter性能测试常用图表
性能测试常用图表:
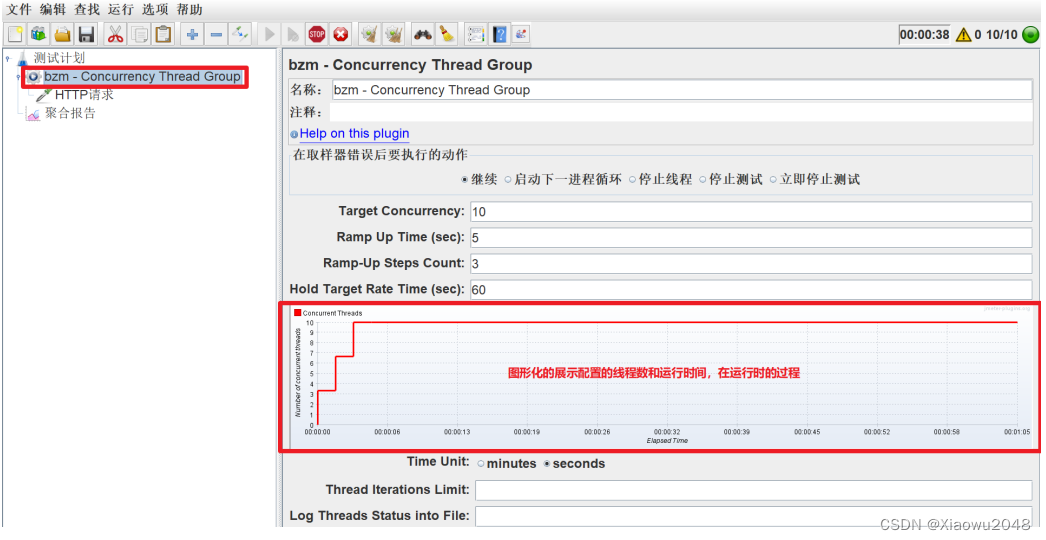
Concurrency Thread Group线程组:
作用:
线程数阶梯上升
图形化的展示
添加方式:测试计划 --> 线程(用户)–> Concurrency Thread Group
每秒性能指标统计:

作用:
•性能测试的结果统计,以聚合报告的结果为准
每秒性能指标的作用是:查看系统长时间运行过程中是否有异常出现,有则进一步分析
基于jmeter客户端监控服务器 硬件资源:
原理
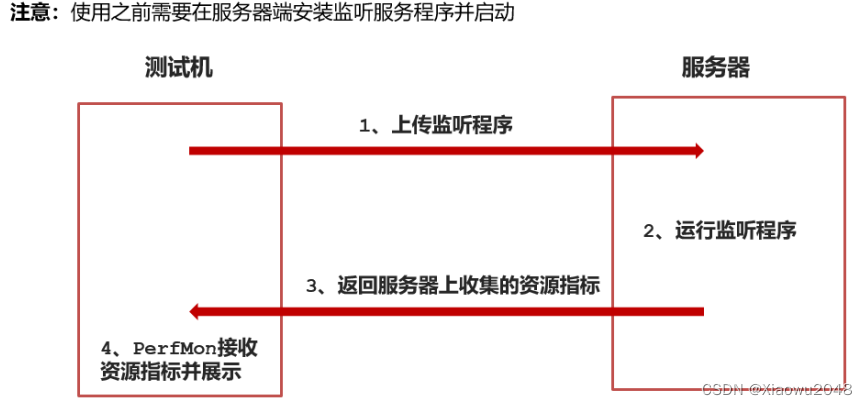
监控性能指标的步骤(windows服务器):
下载ServerAgent程序,并上传到服务器上
手动启动ServerAgent程序,windows服务器startAgent.bat,linux服务器startAgent.sh
在Jmeter中添加PerfMon监控组件,并配置
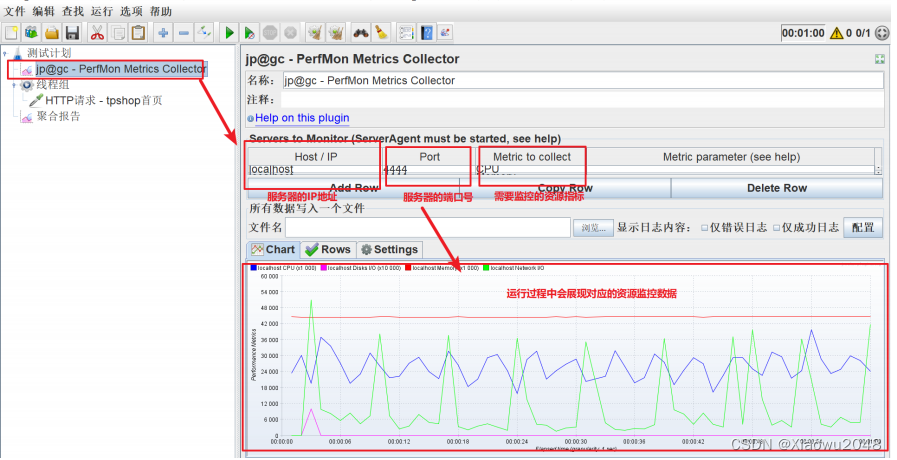
添加线程组及HTTP请求脚本,并配置,运行即可监控资源指标
监控性能指标的步骤(linux服务器):
下载ServerAgent程序,并上传到服务器上
通过finalshell工具上传到指定的目录下
手动启动ServerAgent程序,windows服务器startAgent.bat,linux服务器startAgent.sh
(1)解压缩: unzip ServerAgent2.2.3.zip
(2)进入ServerAgent目录,赋权限:
cd
ServerAgent-2.2.3 chmod -R 777 *
(3)启动ServerAgent程序 ./startAgent.sh
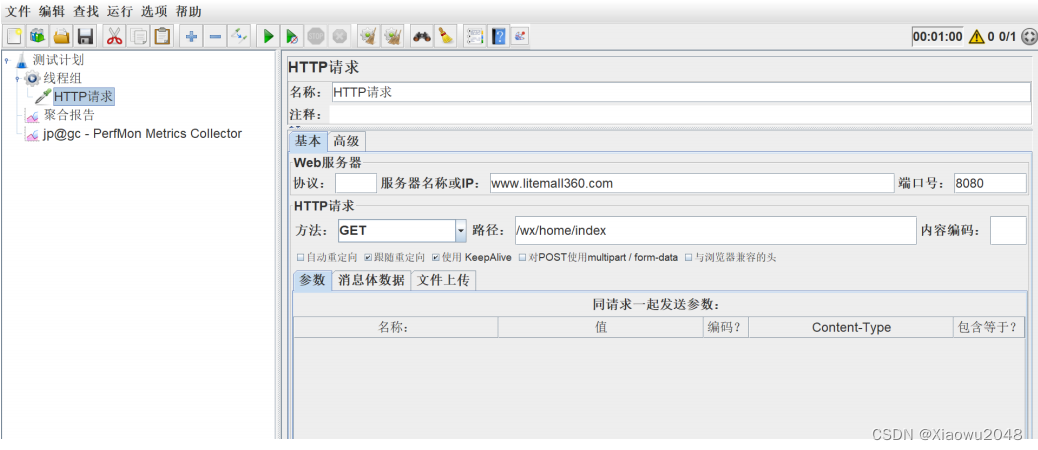
添加HTTP请求 - 请求litemall首页
在Jmeter中添加PerfMon监控组件,并配置
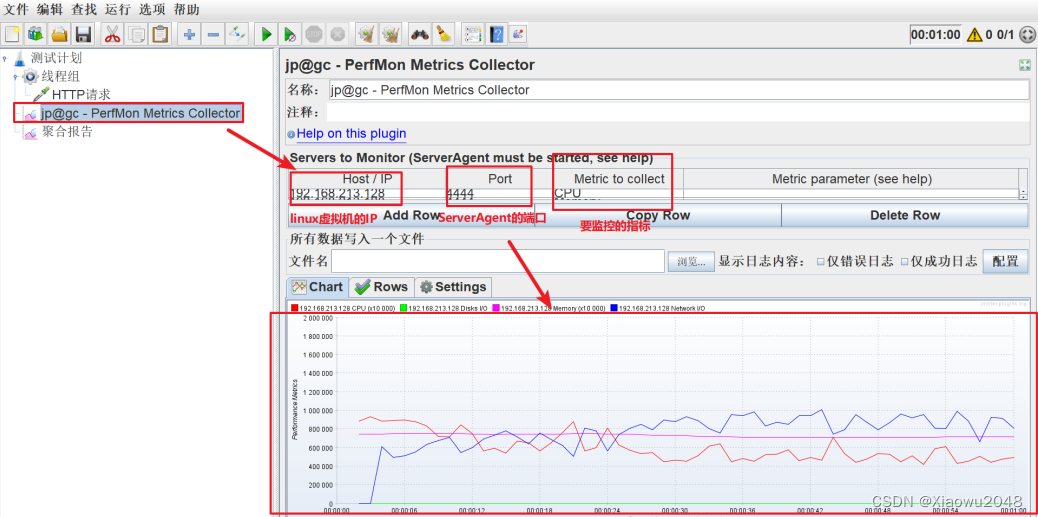
案例练习
项目介绍和部署:
微商城功能介绍:
前台商城:购物车、订单、支付、优惠券等
后台管理系统:商品管理、会员管理、商场管理、推广管理等
微商城项目的技术介绍:
前端:页面代码
后端:业务逻辑处理程序,外加数据库
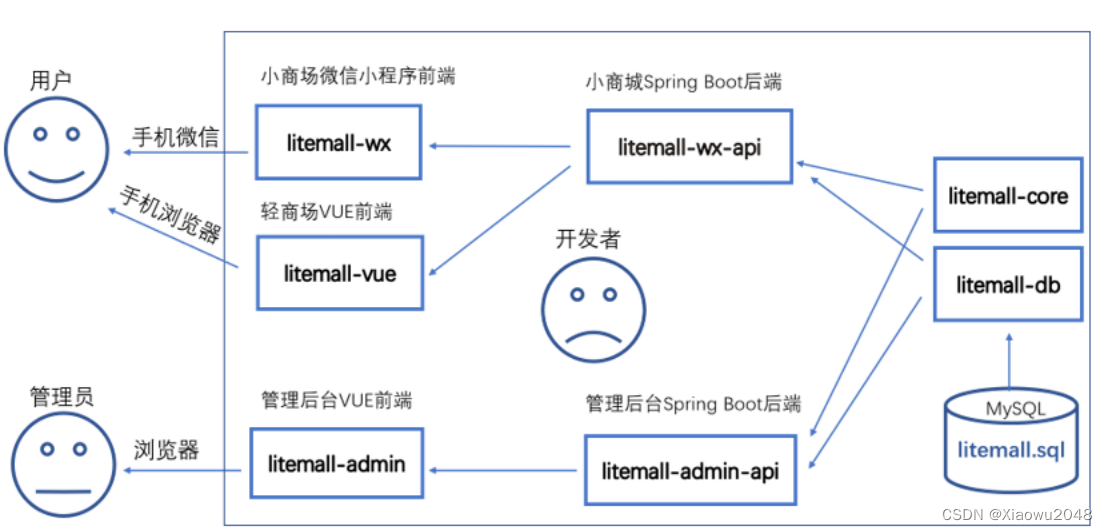
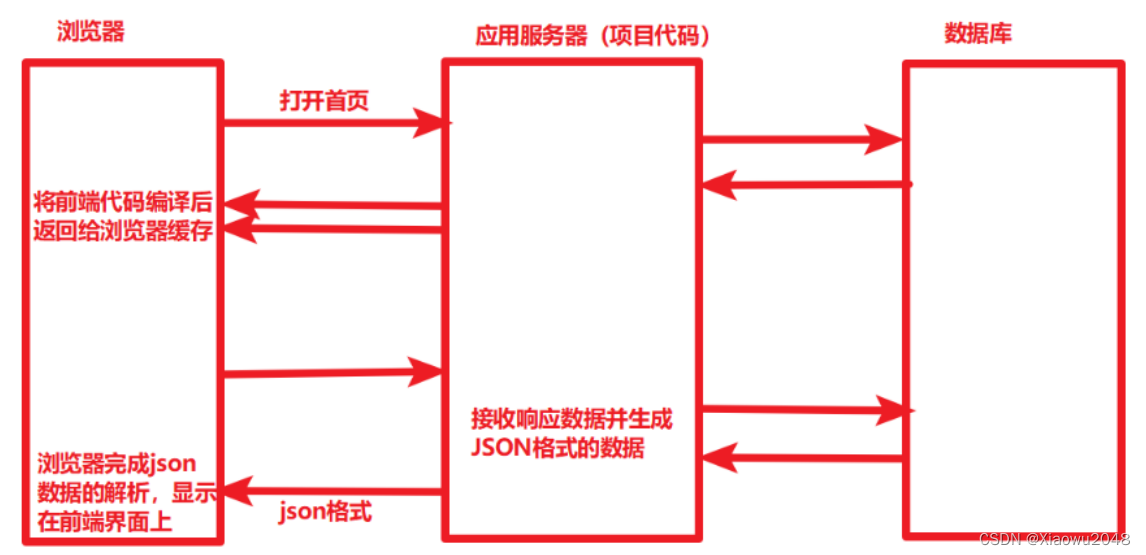
前后端分离的项目:
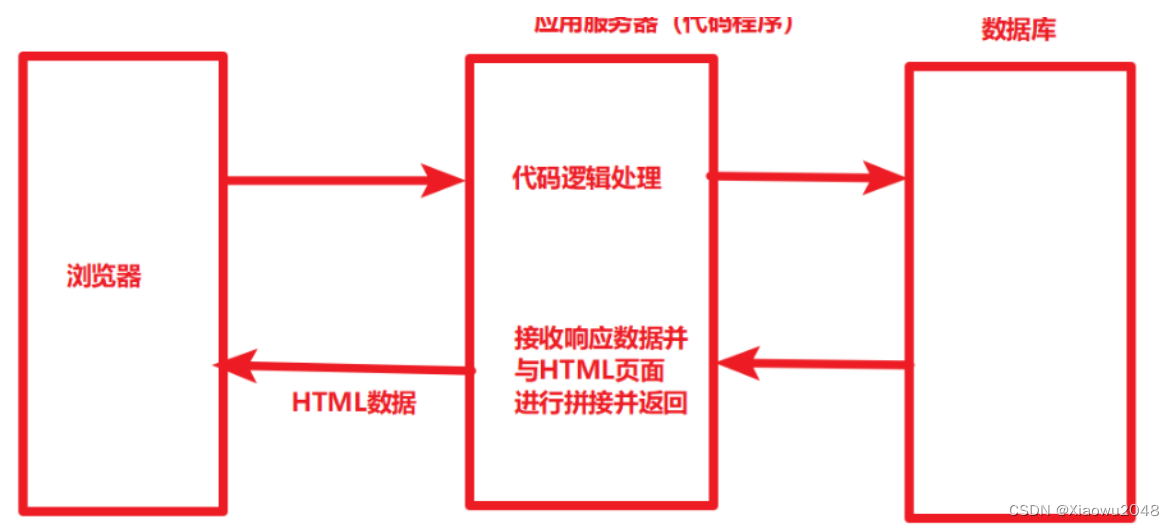
前后端不分离的项目:
对比这两种方式:
前后端分离的形式,数据传输的效率要高很多(JSON数据格式远小于HTML页面格式)
前后端分离的形式,服务器不需要处理HTML页面逻辑,由浏览器自己完成,减轻服务器的压力
在实际项目中,主要是使用前后端分离的形式
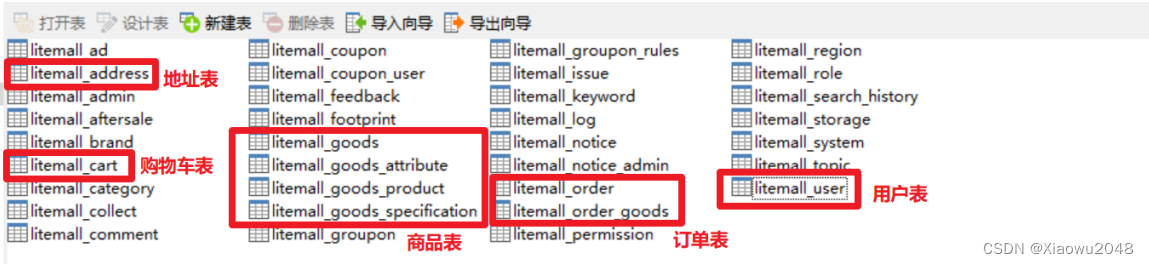
熟悉数据库设计:
作用:
性能测试时,监控数据库的性能指标,定位bug
构造测试数据
微商城项目的部署过程:

性能测试需求分析:
性能需求的获取:
客户方给出(传统行业)
根据运营数据来计算(互联网行业)
根据竞品分析(新上线的产品无历史数据的情况)
需求分析:
确定测试点/功能:
业务角度(用的多的,重要的,核心的)
技术角度(问开发技术复杂度高的)
确定测试目标:
每个功能需要支持的TPS
业务流程(多个功能组合)需要支持的TPS
所有脚本放在一起,稳定运行一段时间
性能测试计划:
测什么
测试目的,测试范围
谁来测
测试的人工、进度、时间安排
怎么测
使用什么方法来进行
性能测试用例编写:
根据测试点逐条进行细化:
性能测试数据,有明确要求,需要达到一定的业务量
从接口维度来描述测试步骤
如果两个接口强绑定(结算、下订单),放在一个用例中间测试
性能测试脚本开发
常用的测试元件
编写脚本的要点:
单接口测试脚本:
(1)登录脚本
添加HTTP请求默认值:设置HTTP请求中的默认部分(协议、域名、端口、编码格式)
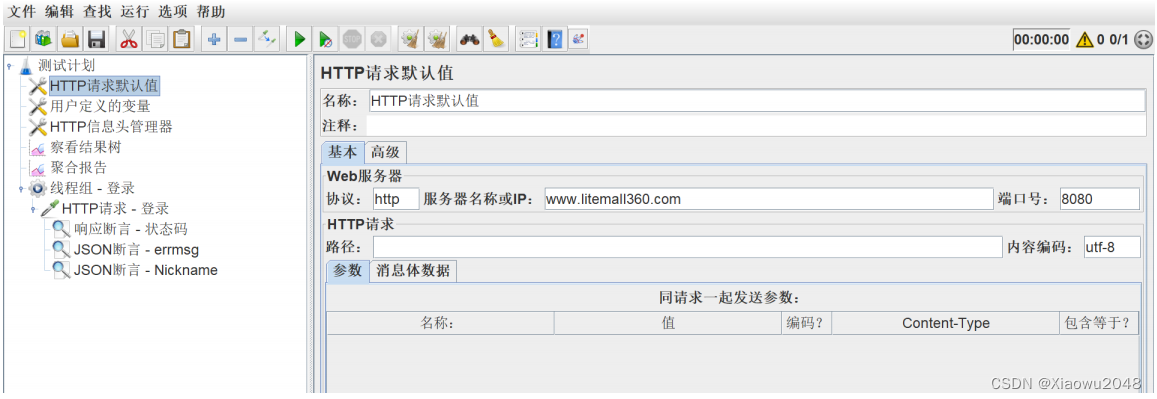
添加HTTP信息头管理,设置HTTP请求的头域
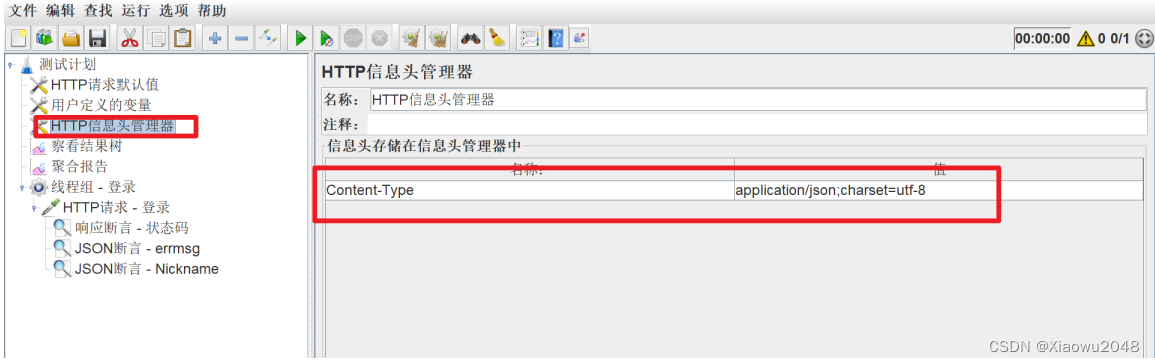
添加线程组 - 登录
添加HTTP请求 - 登录,填写路径和请求参数
在HTTP请求下添加断言:
如果做接口测试,必须断言 响应中的业务数据,可以加上 状态码和描述信息
如果做性能测试,可以只 添加状态码和描述信息 断言
(2)进入首页、搜索商品、获取商品详情
进入首页:
请求:
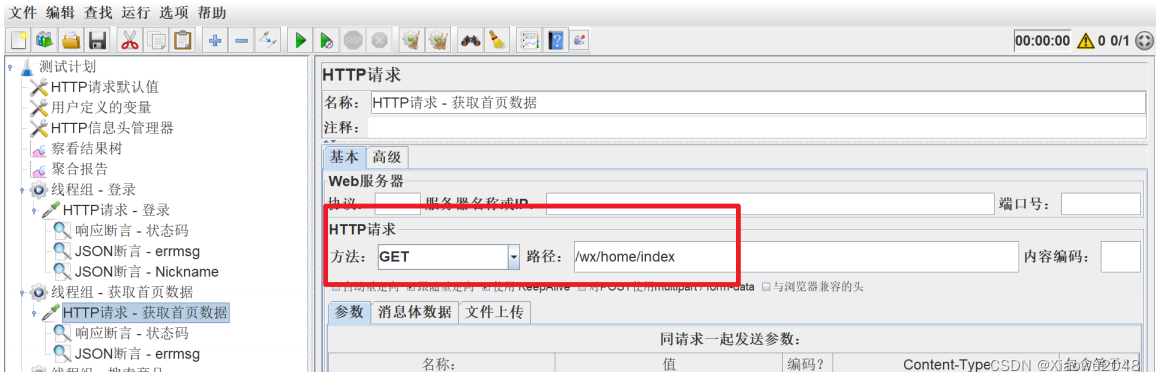
断言:状态码、errmsg
搜索商品:
请求:

断言:
状态码、errmsg
如果是接口测试脚本,必须针对响应中的商品数量进行断言(数据库)
获取商品详情:
请求:

断言:
状态码、errmsg
如果是接口测试脚本,需要针对响应中的商品的详细数据进行对比(数据库)
(3)加入购物车的脚本
添加请求1:登录
添加JSON提取器,提取token
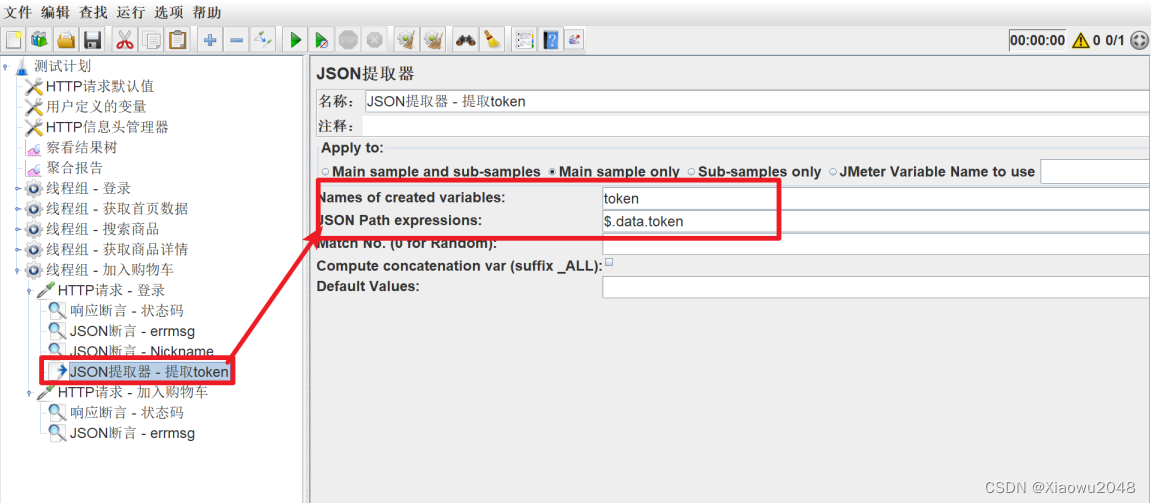
将token设置在HTTP信息头管理器中
添加请求2:加入购物车
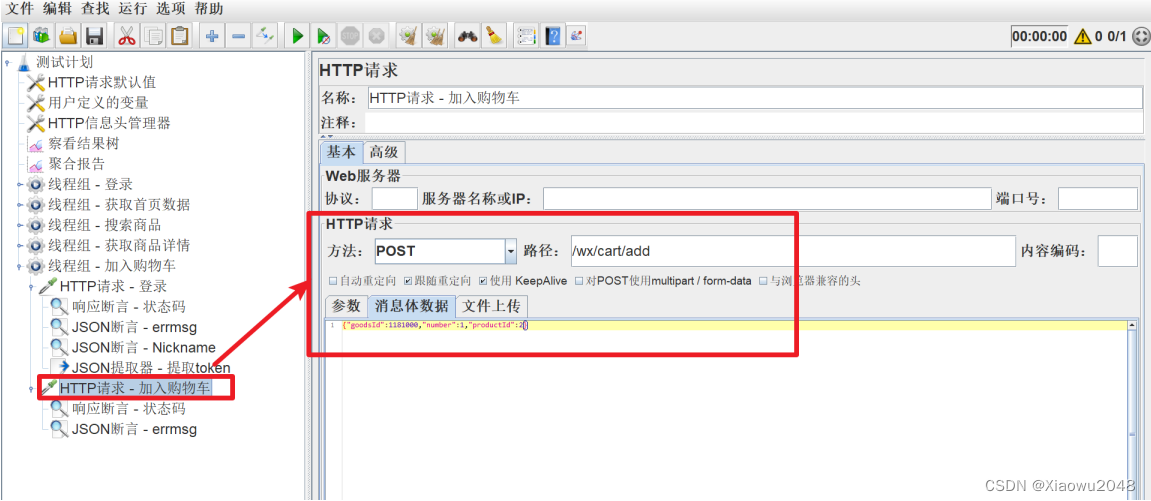
添加断言:
状态码、errmsg
如果是接口测试脚本, 需要再查询我的购物车,检查我的购物车返回的数据是否与加入购物
车返回的数据一致
(4)查看我的购物车、结算下订单、查看我的订单
查看我的购物车:
请求:先发送登录请求,提取token信息,添加查看购物车请求,将token信息赋值为X-litemallToken头域,填写请求路径和参数
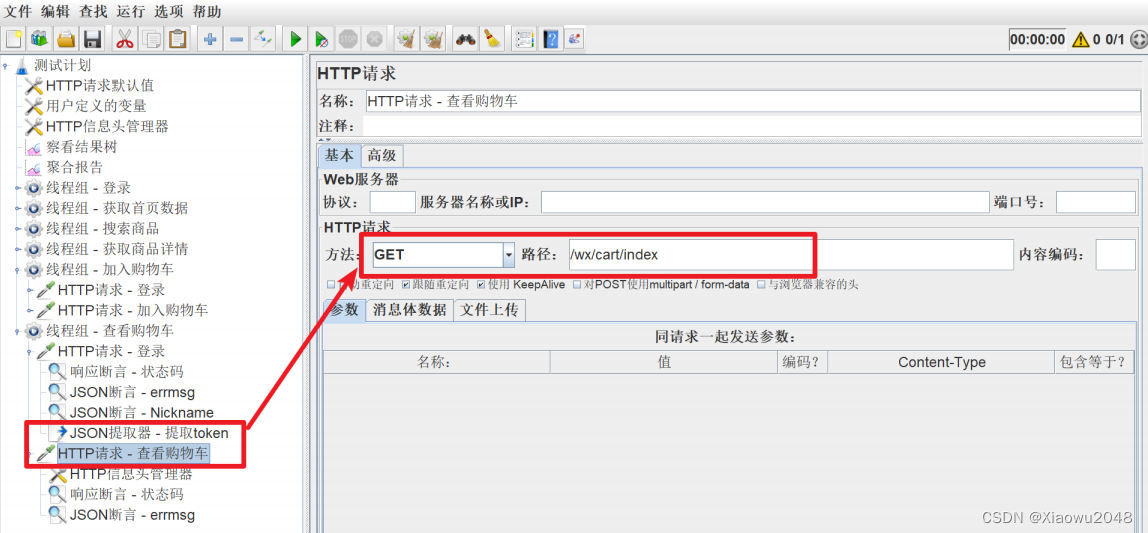
响应:
状态码、errmsg
如果脚本为接口测试脚本,需要断言响应报文中的购物车中的商品总数量或者商品总价值
提交订单:
请求:(1)先发送登录请求,提取token信息,(2)添加结算请求,将token信息赋值为Xlitemall-Token头域,填写请求路径和参数(3)添加下订单请求,将token信息赋值为X-litemallToken头域,填写请求路径和参数(注意地址ID必须与用户ID匹配)
响应:
状态码、errmsg
如果脚本为接口测试脚本,需要断言响应报文中的订单数据,与数据库中订单表中我的订单数
量一致
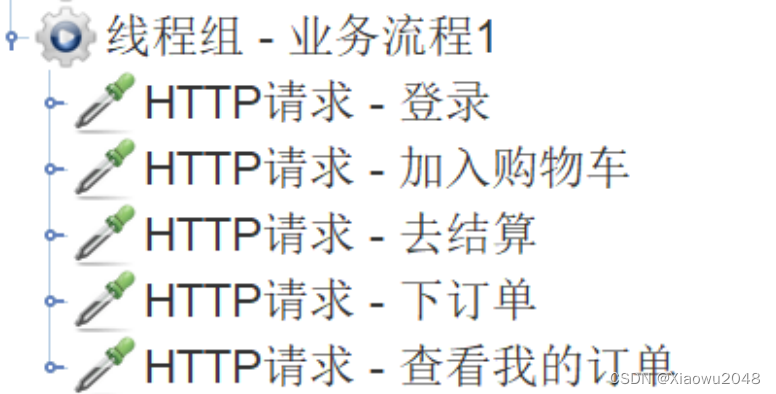
业务流程的测试脚本:
将业务流程中的所有单接口的脚本组装在一起
注意所有的脚本组装在一起时,数据是否一致
性能测试环境准备:
特点:

测试数据的准备(插入10万条数据):
目的:压测环境中的数据量尽量与生产环境中数据量一致
方法:为了快速创建大量数据,可以直接操作数据库进行添加
•准备插入数据的SQL语句
•循环执行SQL语句来插入数据
Ø导包
Ø连接数据库
Ø创建游标
Ø执行SQL语句
将SQL语句中唯一的字段,使用占位符{}来替换,方便在脚本中传递不同的值
编写脚本,循环执行sql语句插入对应的商品记录
Ø关闭游标
Ø关闭连接
select * from litemall_goods where id = ‘1166008’
在插入数据前的查询时间:
在插入数据后的查询时间:
构造用户数据:
#导包
import pymysql
#创建连接
conn = pymysql.connect(host="192.168.91.134",user="litemall",password="litemall123456",database="litemall",port=3306,charset='utf8')
#创建游标
cursor = conn.cursor()
#添加用户的SQL语句
user_sql = "INSERT INTO `litemall`.`litemall_user` (`id`, `username`, `password`, `gender`, `birthday`, `last_login_time`, `last_login_ip`, `user_level`, `nickname`, `mobile`, `avatar`, `weixin_openid`, `session_key`, `status`, `add_time`, `update_time`, `deleted`) VALUES ('{}', '{}', '$2a$10$SrnVvS/D6N0XNd4MHNjQR.W3VUfJhOdBylPC3Ika0zTvmxyiJ52AS', '0', NULL, '2020-08-14 12:00:58', '192.168.91.1', '0', 'xiaoh', '{}', 'https://yanxuan.nosdn.127.net/80841d741d7fa3073e0ae27bf487339f.jpg?imageView&quality=90&thumbnail=64x64', '', '', '0', '2020-08-12 14:14:37', '2020-08-14 12:00:58', '0');"
#循环插入数据
user_start = 100000
for i in range(100000):
user_id = user_start + i
username = "test" + str(user_id)
mobile = "13012" + str(user_id)
print("插入第{}条数据ID为{}".format(i+1,user_id))
sql = user_sql.format(user_id,username,mobile)
cursor.execute(sql)
conn.commit()
#关闭游标
cursor.close()
#关闭连接
conn.close()
执行性能测试用例
执⾏测试脚本:
性能测试脚本执⾏
登录脚本:
1、准备数据
# 导包
import pymysql
# 建⽴连接
conn =
pymysql.Connect(host='www.litemall360.com',port=3306,user='root',password='123456',dat
abase='litemall',charset='utf8')
# 获取游标
cursor = conn.cursor()
# 执⾏sql语句
sql1 = "INSERT INTO `litemall`.`litemall_user` (`id`, `username`, `password`,
`gender`, `birthday`, `last_login_time`, `last_login_ip`, `user_level`, `nickname`,
`mobile`, `avatar`, `weixin_openid`, `session_key`, `status`, `add_time`,
`update_time`, `deleted`) VALUES ('{}', 'user{}',
'$2a$10$lTu9qi0hr19OC800Db.eludFr0AXuJUSrMHi/iPYhKRlPFeqJxlye', '1', NULL, '2021-09-26
16:24:33', '192.168.213.1', '0', 'user{}', '{}', '', '', '', '0', '2019-04-20
22:17:43', '2021-09-26 16:24:33', '0');"
sql2 = "INSERT INTO `litemall`.`litemall_address` (`id`, `name`, `user_id`,
`province`, `city`, `county`, `address_detail`, `area_code`, `postal_code`, `tel`,
`is_default`, `add_time`, `update_time`, `deleted`) VALUES ('{}', 'user{}', '{}', '北
京市', '市辖区', '⻄城区', '⻓安街10000号', '110102', '', '{}', '1', '2021-09-26
16:14:25', '2021-09-26 16:14:25', '0');"
user_start= 100000
for i in range(100000):
user_id = user_start + i
mobile = "13011" + str(user_id)
addr_id = user_start + i
print("插⼊第{}条⽤户数量,⽤户ID为{}".format(i+1,user_id))
cursor.execute(sql1.format(user_id,user_id,user_id,mobile))
cursor.execute(sql2.format(addr_id,user_id,user_id,mobile))
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
2、修改脚本
使⽤random函数,来保证每次运⾏登录时,使⽤不同的⽤户名进⾏登录
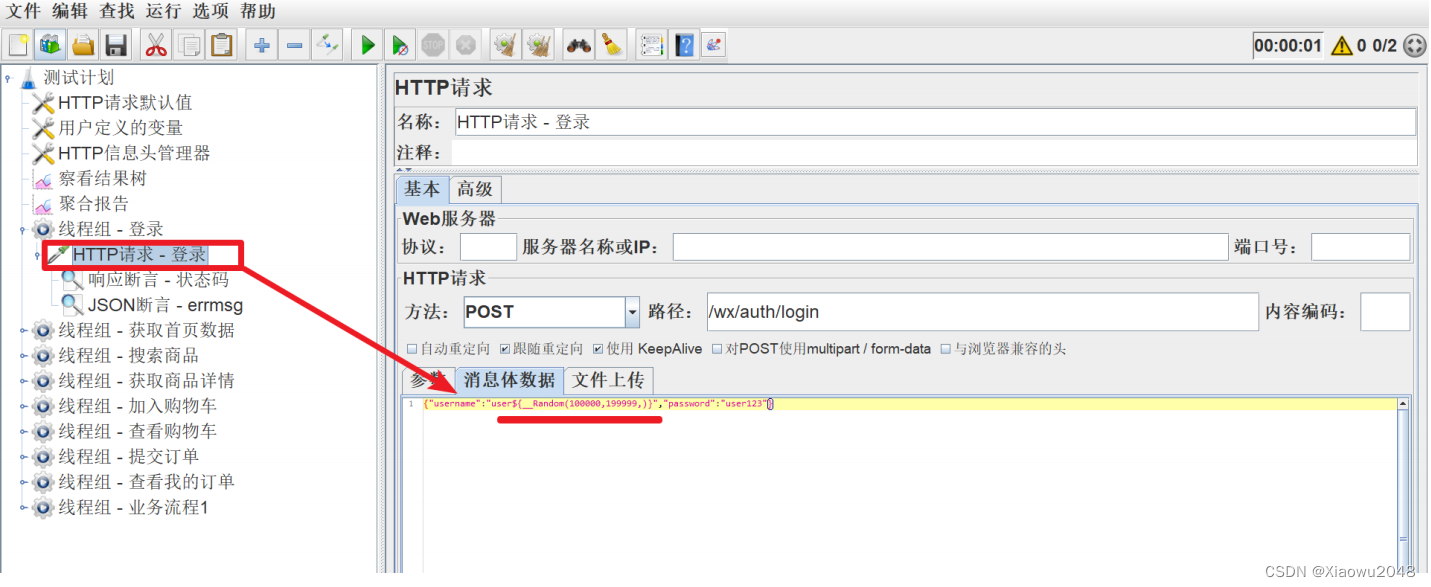
3、监控性能指标
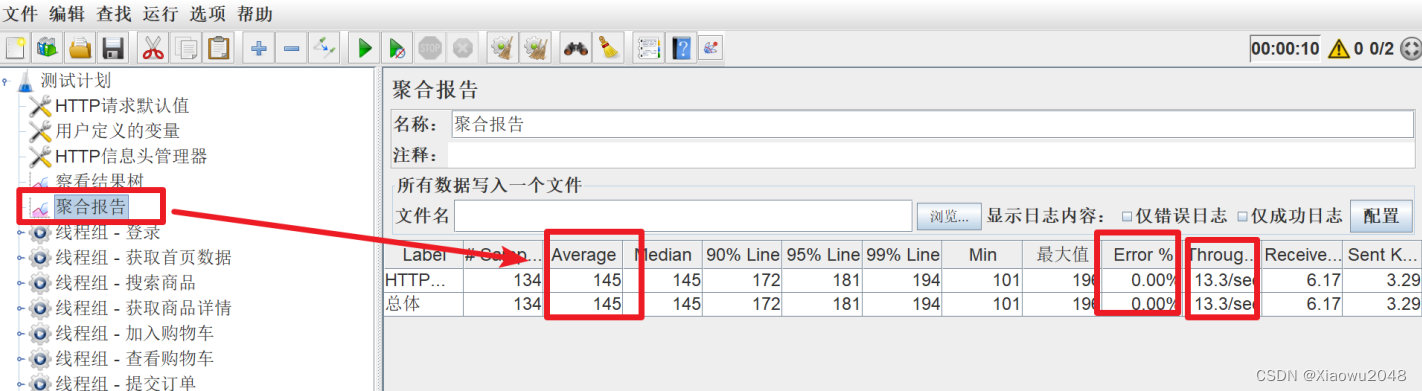
系统指标:响应时间、吞吐量、错误率、并发数
聚合报告
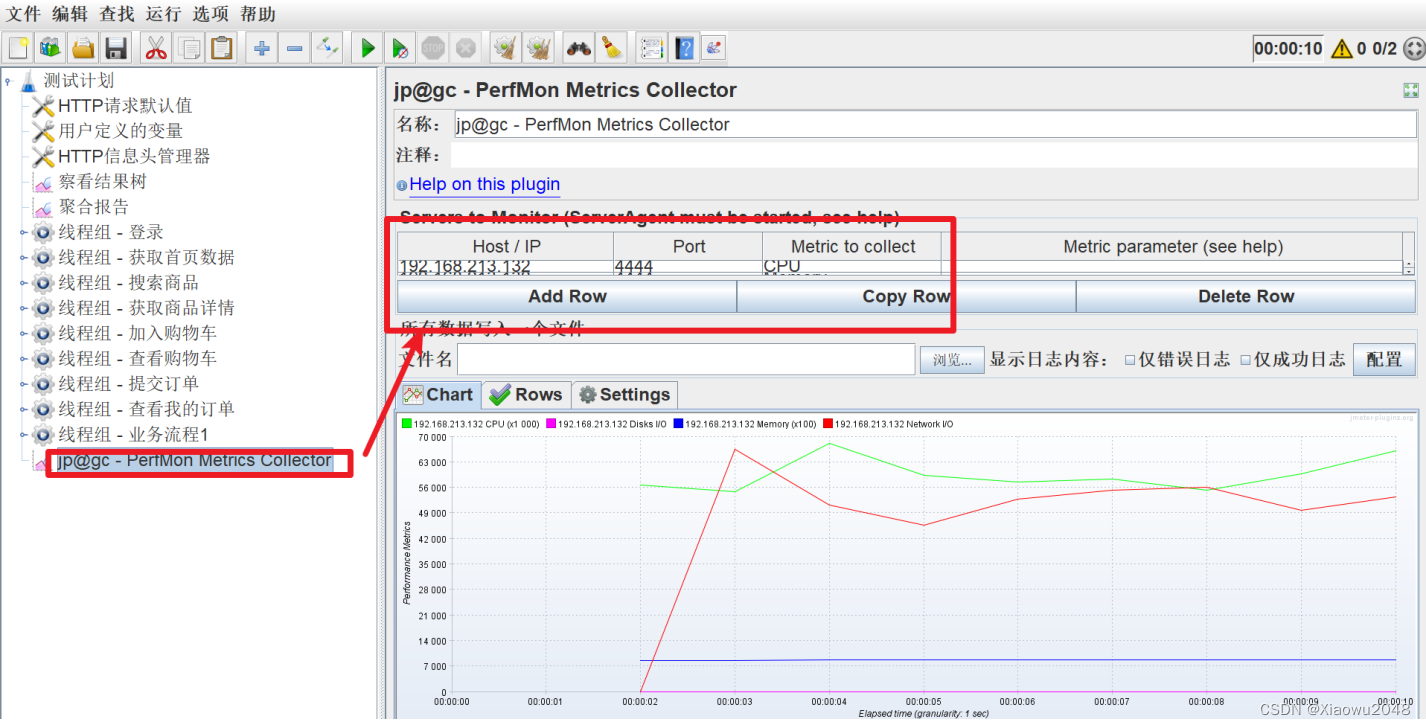
资源指标:CPU、内存、磁盘、⽹络
PerFMon
4、模拟并发
如果系统之前进⾏过性能测试,直接模拟TPS20的场景,进⾏性能测试,并监控指标
如果系统之前未进⾏过性能测试,按照负载测试的原则,逐步增加负载量,观察性能的指标。 —— 采
⽤该⽅法
执⾏:
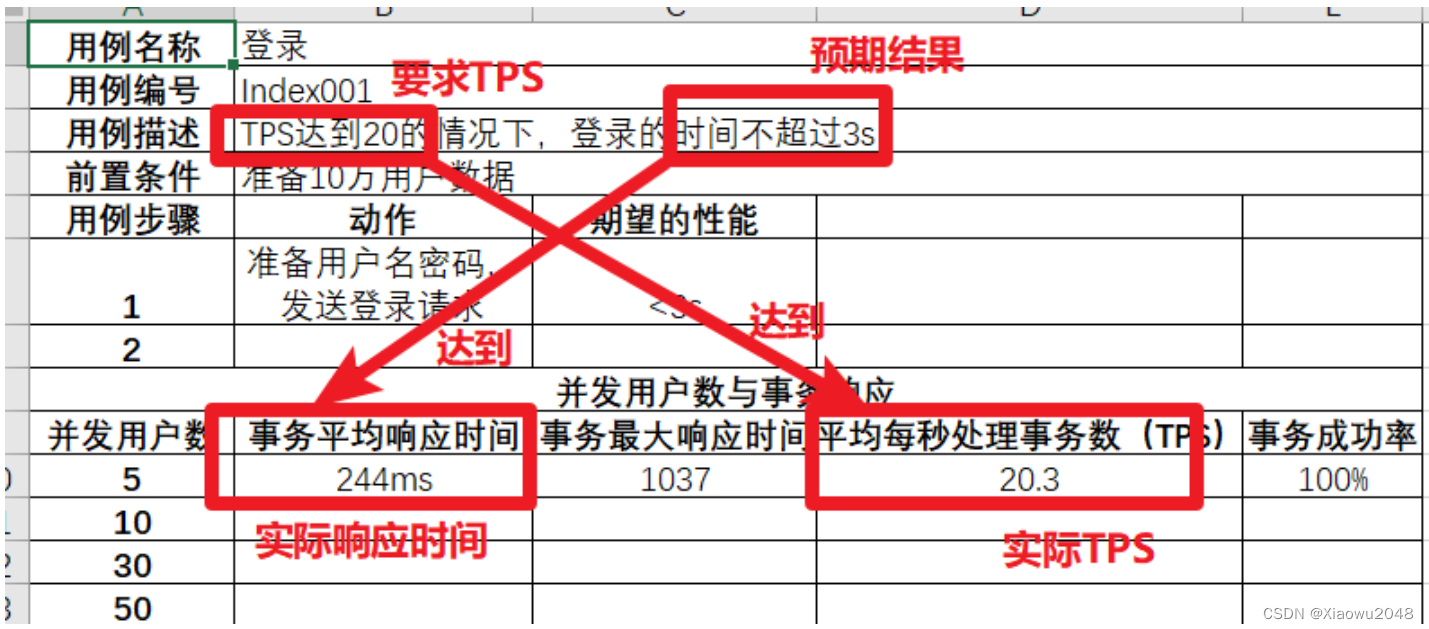
模拟5个⽤户并发,观察吞吐量TPS和响应时间
结果分析:
⽤例要求登录TPS为20,要求响应时间不超过3s
实际执⾏登录TPS为20.3(达到要求),实际执⾏的响应时间为244ms(达到要求),因此⽤例通
过
补充:
当前⽤例测试时CPU利⽤率为98%,内存利⽤率为85.62%,超出正常的范围
如果在公司进⾏性能测试时,该⽤例不能算通过,因为资源使⽤率也是⼀个重要指标
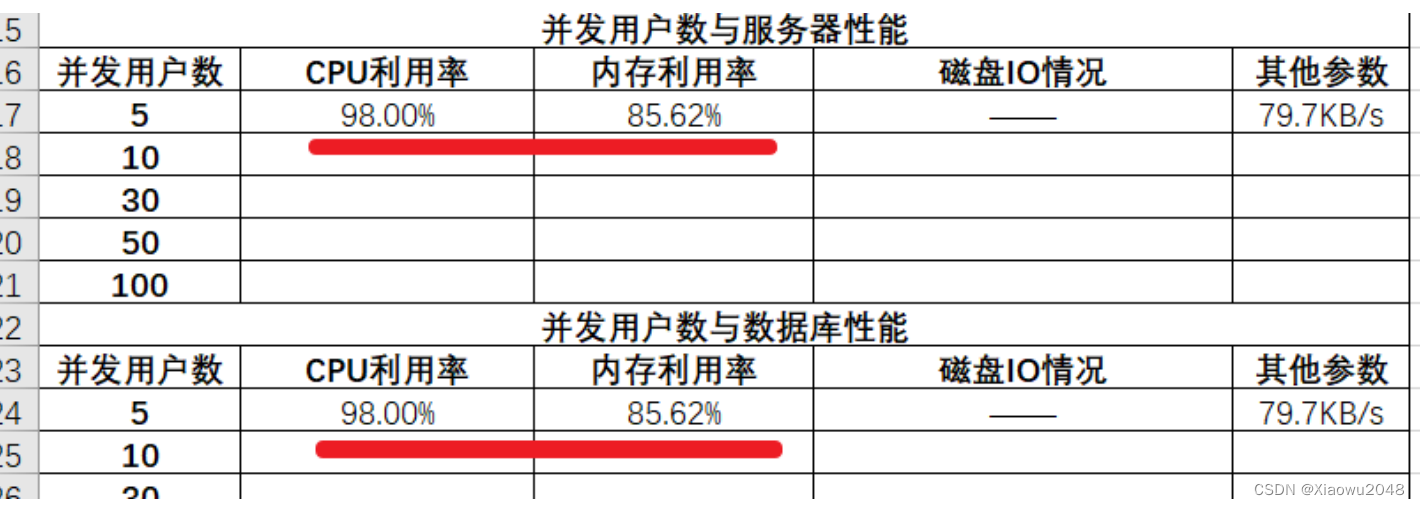
进⼊⾸⻚脚本:
模拟5个并发:
实际TPS未达到要求TPS100,实际响应时间(1)未超过要求实际5s,⽆法证明是否存在bug,需
要进⼀步增加负载量
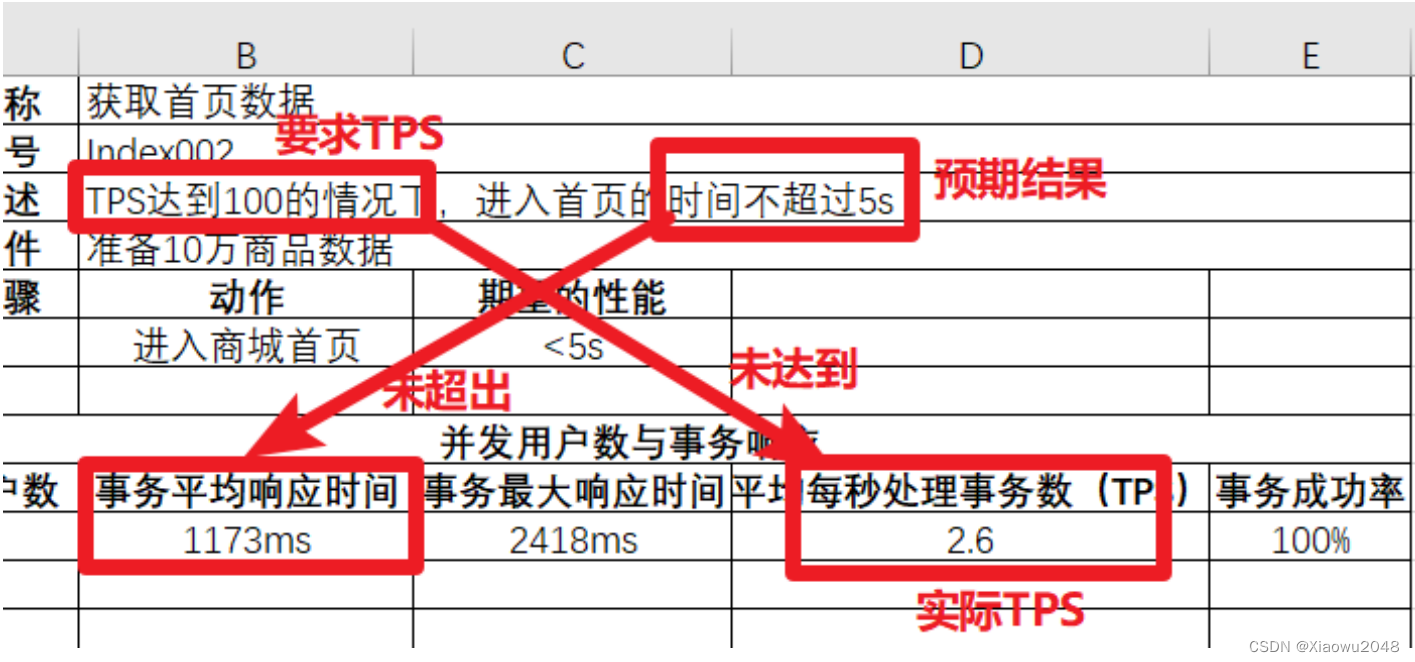
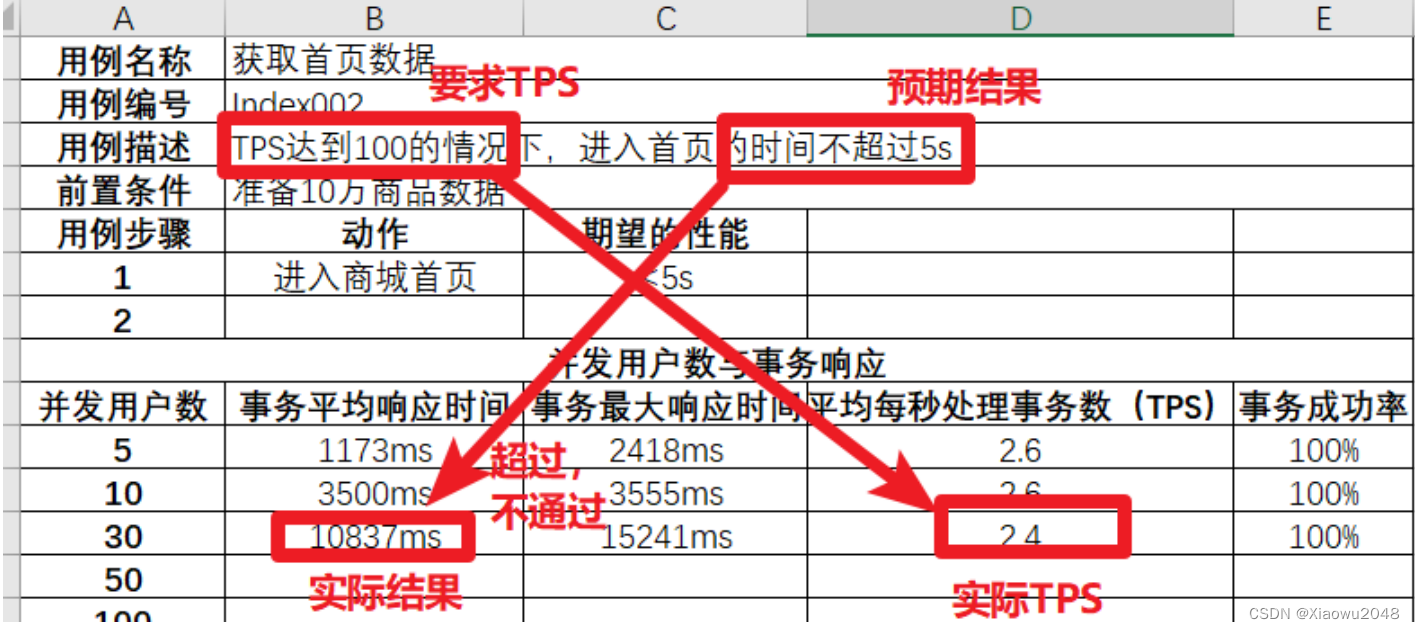
模拟30个⽤户并发:
实际TPS未达到要求TPS100,实际响应时间(10s)未超过要求实际5s,说明⽤例测试不通过,需
要提交bug
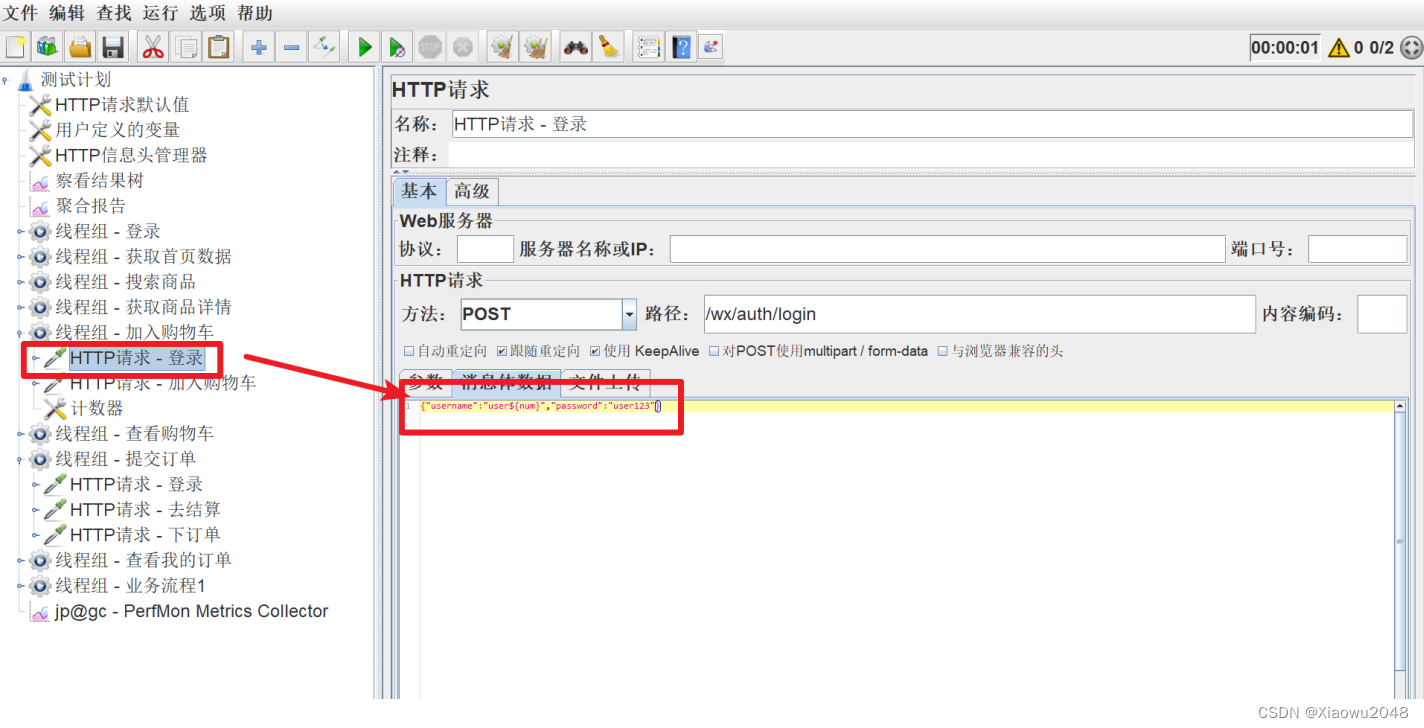
添加购物⻋—查看购物⻋—商品结算—下订单—查看订单脚本:
加⼊购物⻋脚本:
1、数据准备⼯作:
(1)修改待添加的商品库存为⾜够⼤,避免在性能测试过程把商品库存耗尽导致脚本失败
UPDATE litemall_goods_product SET number = '1000000000' where id =2;
2、脚本修改:
(1)可以使⽤随机⽤户登录,并添加购物⻋吗?
3、运⾏并分析结果:
UPDATE litemall_goods_product SET number = ‘1000000000’ where id =2;
模拟5个⽤户并发:
实际TPS41.9达到要求TPS20,实际响应时间59ms未超过要求响应时间3s,⽤例测试通过
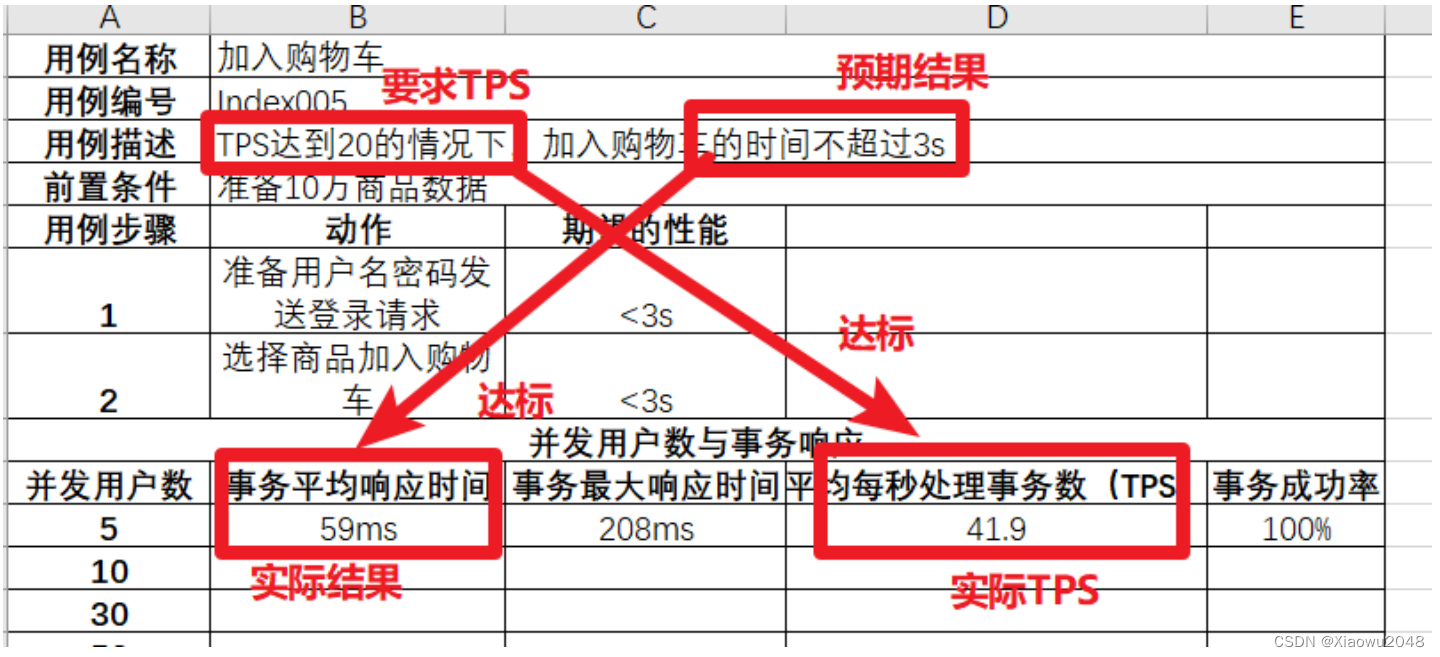
结算并下订单脚本:
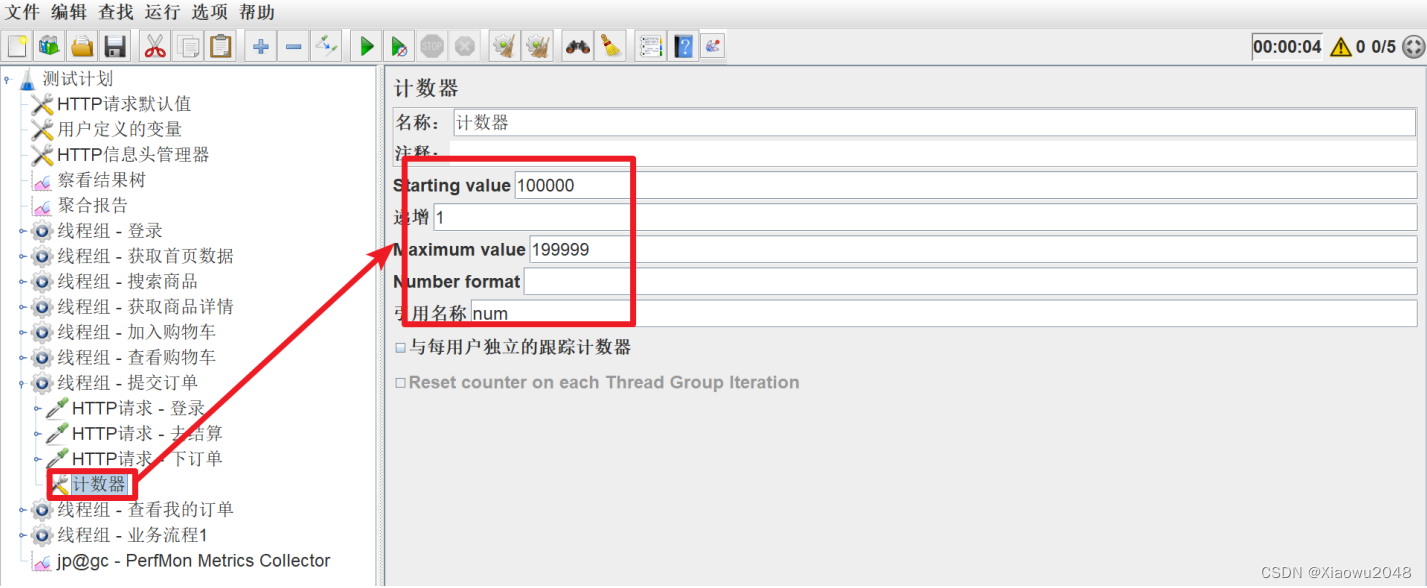
修改测试脚本:
设置计数器
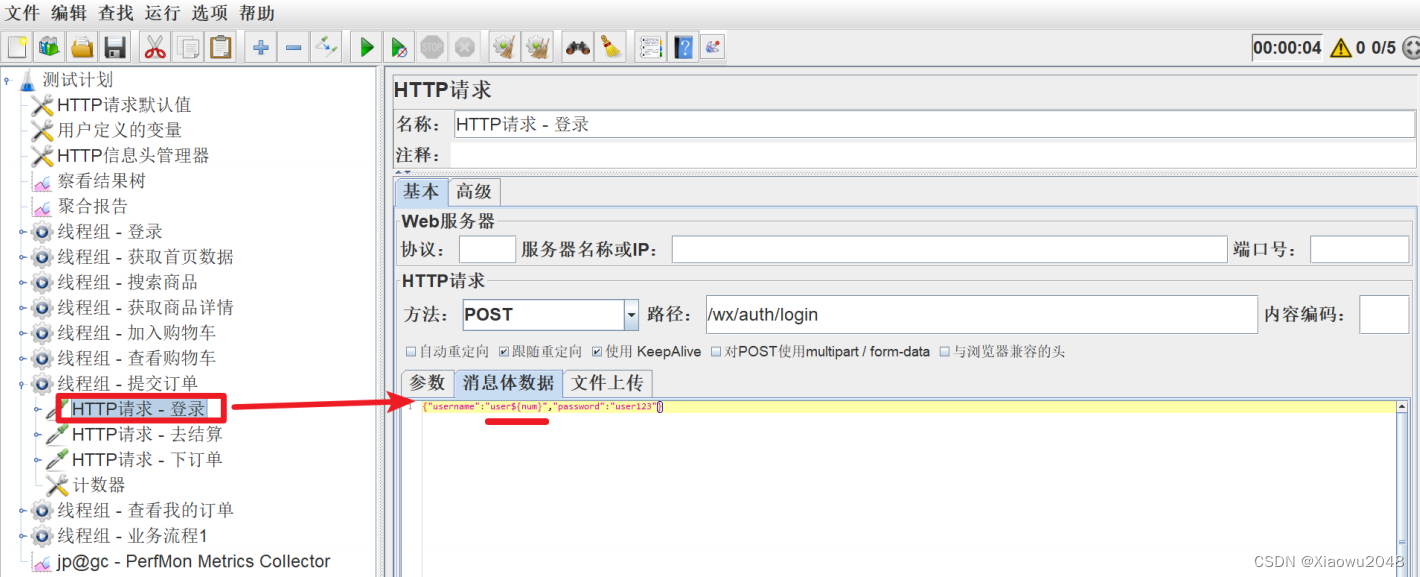
修改HTTP请求 - 登录
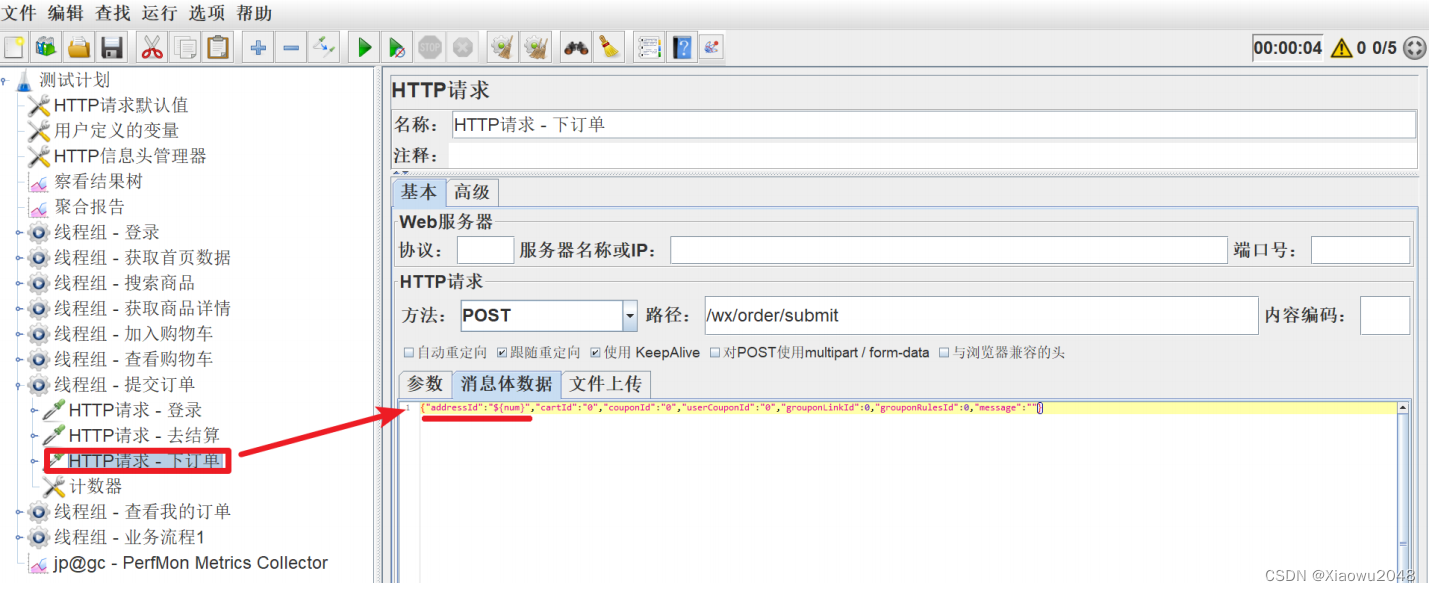
修改HTTP请求 - 下订单
执⾏测试脚本:
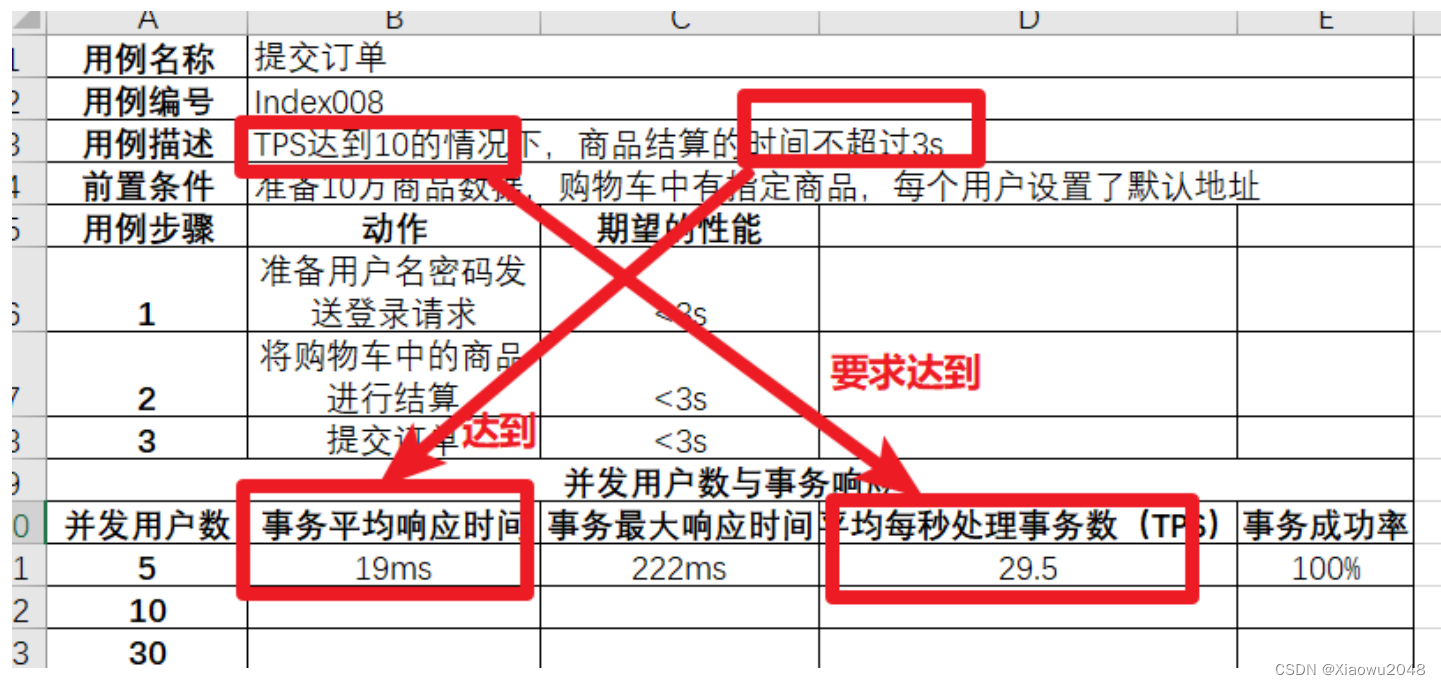
模拟5个⽤户并发:
实际TPS为29.5达到要求TPS10,实际响应时间为19ms(不超过要求3s),⽤例测试通过
业务流程的测试:
步骤:
准备测试数据
修改脚本
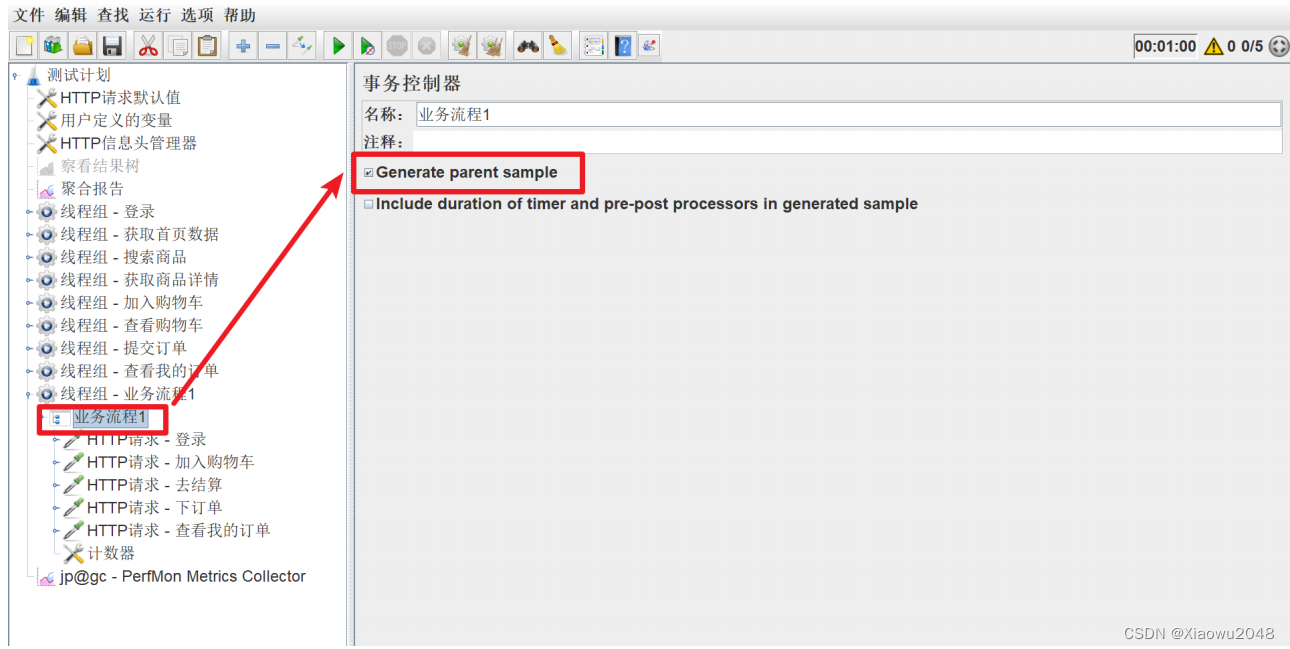
添加事务控制器,并把所有的脚本都放⼊到事务控制器中
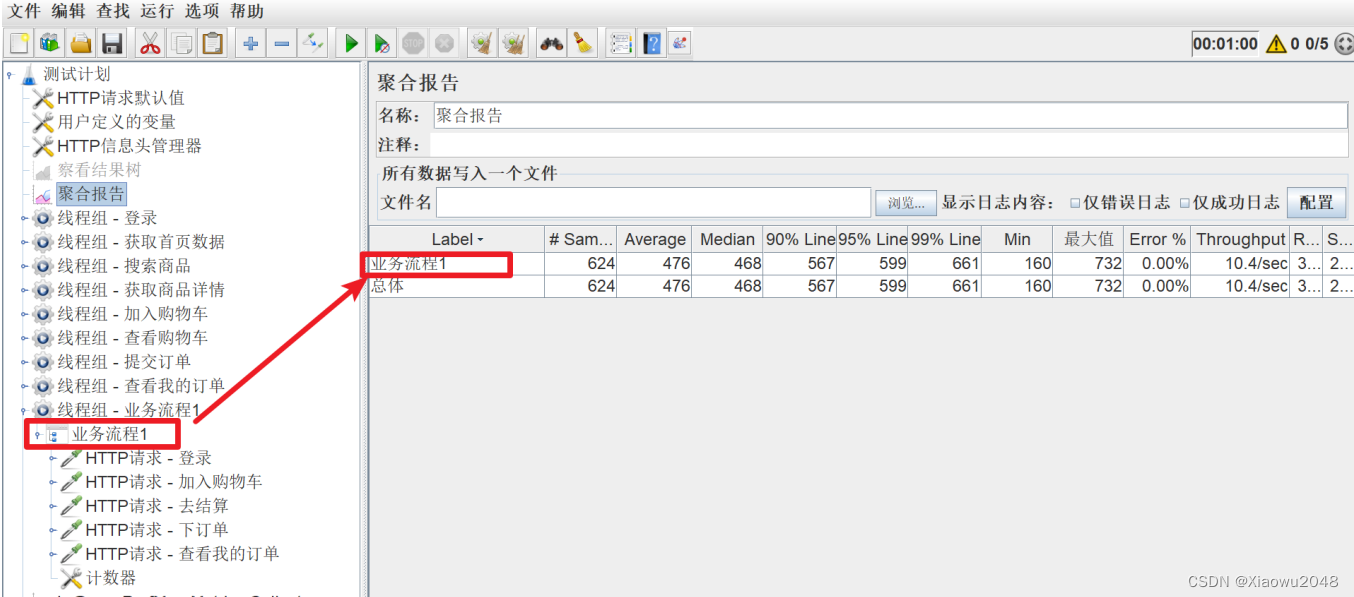
添加性能监控
并发执⾏并分析结果
注意:
在进⾏业务流程的脚本性能测试时,前提必须保证该业务流程中所有的单接⼝性能测试结果都达标
稳定性测试:
稳定性⽤例设计:
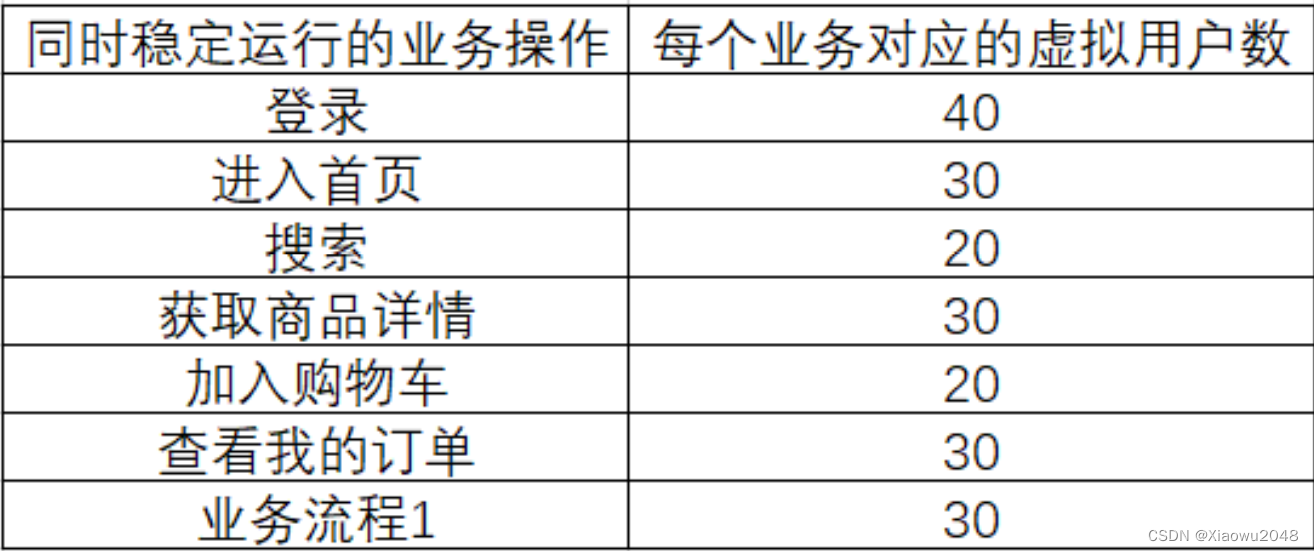
确定出稳定运⾏的所有业务操作:(同时运⾏)
根据运营数据,分析出每个业务操作对应的虚拟⽤户数
稳定性测试执⾏:
所有的脚本同时执⾏(解除前后依赖)
每个脚本都是⼀个事务/业务 —— 事务控制器
按照要求设置虚拟⽤户数和运⾏时间
执⾏稳定性测试并监控
补充:
如果单个接⼝/业务流程还存在性能bug,需要再修复性能bug,再进⾏稳定性测试
性能测试分析和调优:
步骤:
确定问题。根据性能测试的结果来分析确定bug —— 测试⼈员职责
分析原因。分析问题产⽣的原因 —— 开发⼈员职责
给出解决⽅案。可以是修改软件配置、增加硬件资源配置、修改代码等 —— 开发⼈员职责
验证解决⽅案。—— 测试⼈员回归测试
分析验证结果 —— 既要保证有问题的指标得到解决,⼜要保证其他指标没有出现新问题
注意:
性能分析和调优需要经过很多轮,才能最终解决问题
性能测试监控关键指标:
性能问题可以产⽣的 原因:
服务器的资源 —— 影响应⽤服务器和数据库服务器处理的速率 和 ⽹络传输速率
JVM瓶颈分析 —— JAVA程序运⾏的环境
数据库瓶颈分析 —— 数据库程序运⾏环境分析
程序内部实现机制 —— 开发⼈员编写的代码分析
压测机 —— 影响性能结果
硬件服务器资源指标
1、服务器的硬件
CPU、内存、磁盘、外设(键盘、⿏标、显示器、散热器、机箱)
运⾏速度从快到慢:CPU >> 内存 >> 磁盘
存储空间从⼤到⼩:磁盘 >> 内存 >> CPU
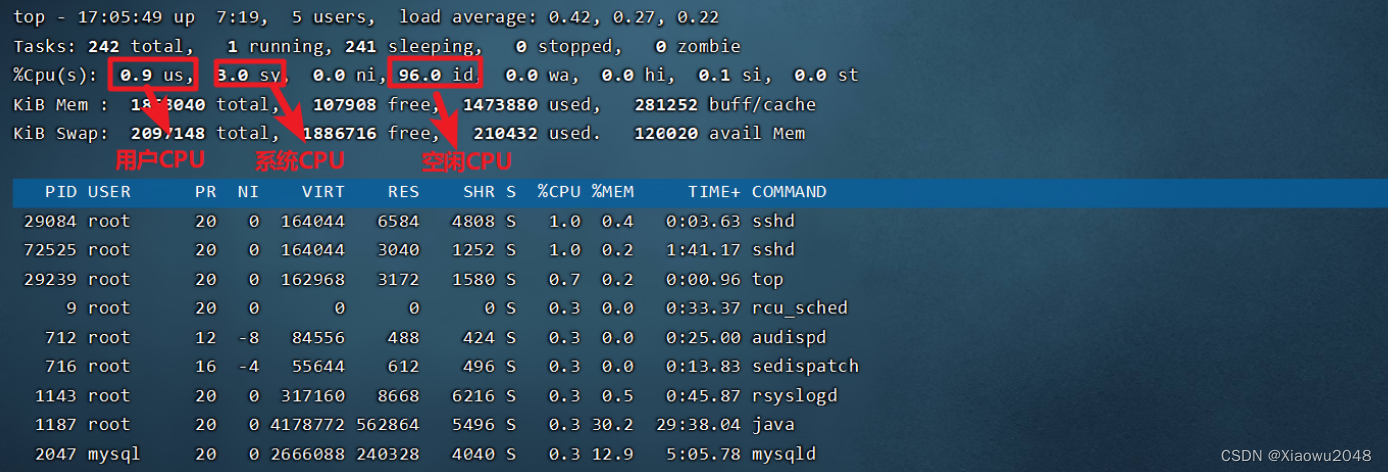
2、CPU时间的介绍
CPU:单位HZ,
将CPU划分为若⼲个时间⽚,为每个程序分配对应的时间⽚,保证所有的程序占⽤时间⽚来串⾏执
⾏
CPU使⽤率 = 已使⽤的时间⽚ / 总时间⽚ * 100%
已使⽤的时间⽚ = ⽤户CPU + 系统CPU
总时间⽚ = ⽤户CPU + 系统CPU + 空闲CPU
⽤户CPU:所有应⽤程序运⾏时消耗的CPU
系统CPU:操作系统运⾏消耗的CPU
CPU监控命令:top
测试的关注点:
CPU⾼时,需要确认是⽤户CPU⾼还是系统CPU⾼
如果是⽤户CPU⾼,需要进⼀步分析对应的应⽤程序的执⾏效率是否有问题
如果是系统CPU⾼,需要进⼀步观察其他的资源(内存、磁盘、⽹络等)是否存在问题
3、内存和虚拟内存:
内存:实际内存/物理内存,机器实际的内存空间,所有的程序运⾏都必须加载到内存中才能运⾏
虚拟内存:⼀种虚拟化的技术。当内存空间不⾜时,从磁盘中读⼊数据,处理完成后写回磁盘,以此进
⾏交换,保证在内存不⾜时,程序也能够运⾏。
注意:
由于虚拟内存,实际上完成了数据在磁盘和内存之间的读写过程,磁盘的速度要远慢于内存时,因
此当使⽤虚拟内存时,说明内存已经不⾜,可能存在问题
命令:
查看总量:top
查看虚拟内存的使⽤量:vmstat

测试关注点:
实际内存:查看内存使⽤百分⽐,检查是否超过80%
虚拟内存:查看swap的si和so是否为0,如果不为0,说明内存可能不⾜
4、磁盘IO:
关注是磁盘读⼊和写出的速度,不是磁盘⼤⼩。
命令:iostat -x 1 1
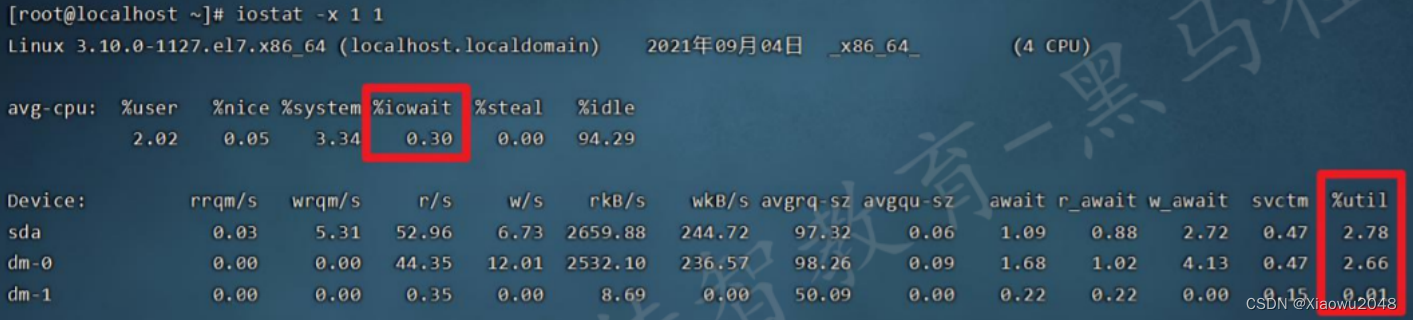
测试关注点:
%util⾼,说明磁盘⻓时间占⽤CPU在发送数据,说明磁盘传输速度不⾜,存在瓶颈
%iowait⾼,说明磁盘IO传输数据的任务很多,在等待,说明磁盘传输速度不⾜,存在瓶颈
5、⽹络
关注是⽹络传输数据的速度
命令:sar -n DEV 1 2
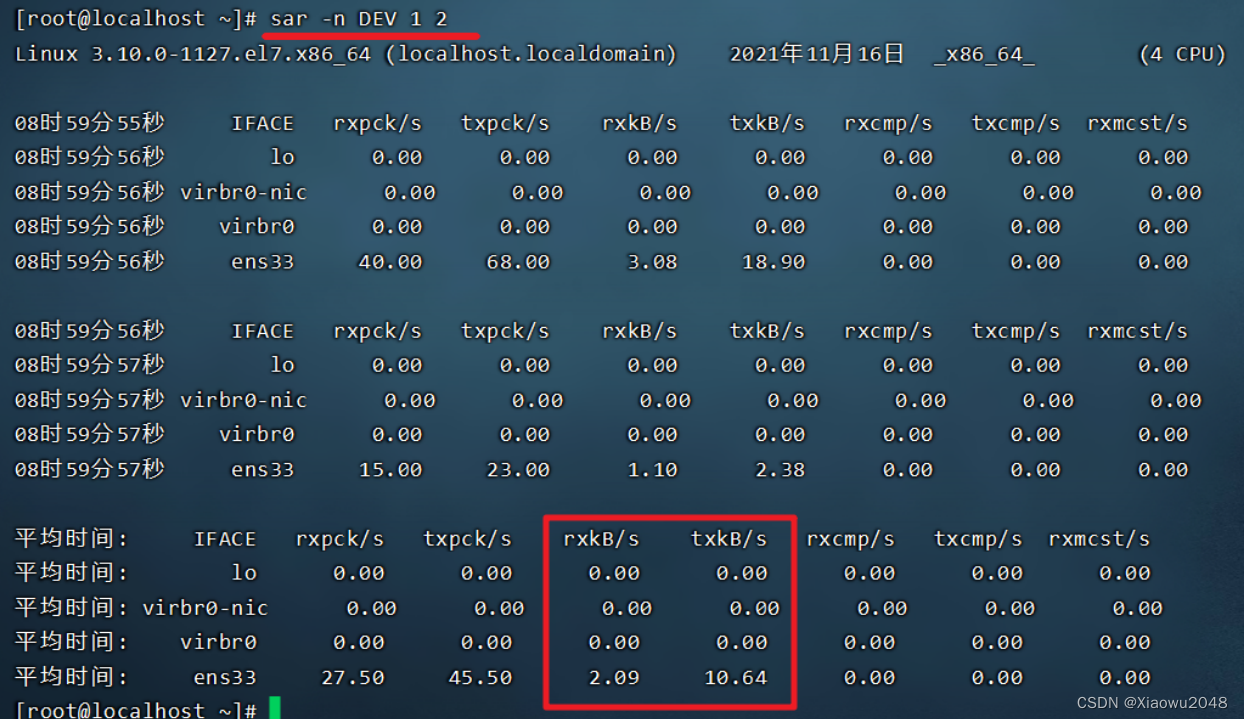
测试关注点:
实际统计的发送速率和接收速率,与⽹络的总带宽进⾏对⽐,查看使⽤的百分⽐(如果⽆限接近
100%,说明存在⽹络性能瓶颈)
补充介绍:
宽带:⽤户(业务)维度来描述⽹络速率的⽅式。例如:20M宽带、100M宽带、1000M宽带
速率单位:b(bit)/s
带宽:数据在⽹络中传输的速率,在技术中都是通过带宽来描述速率
速率单位:B(Byte)/s
1B = 8bit
实际情况:1000M宽带 —— 对应着的带宽速率为 1000/8 = 125M
locust测试脚本—定义任务
性能测试分析和调优:
数据库监控:
1、慢查询
概念:找出查询速度慢的sql语句,
慢:查询时间超过设置的阈值
慢查询的相关参数:
slow_query_long:慢查询开关
slow_query_log_file:慢查询日志存放位置
long_query_time: 慢查询时间阈值
查询慢查询的相关参数:show variables like “”
设置慢查询的相关参数:set global 参数名 = 值
设置完成,并运行脚本抓取到慢查询的日志信息为:

测试关注点:
基于当前记录下来的慢查询sql进行进一步的分析,判断是否存在问题,需要修改
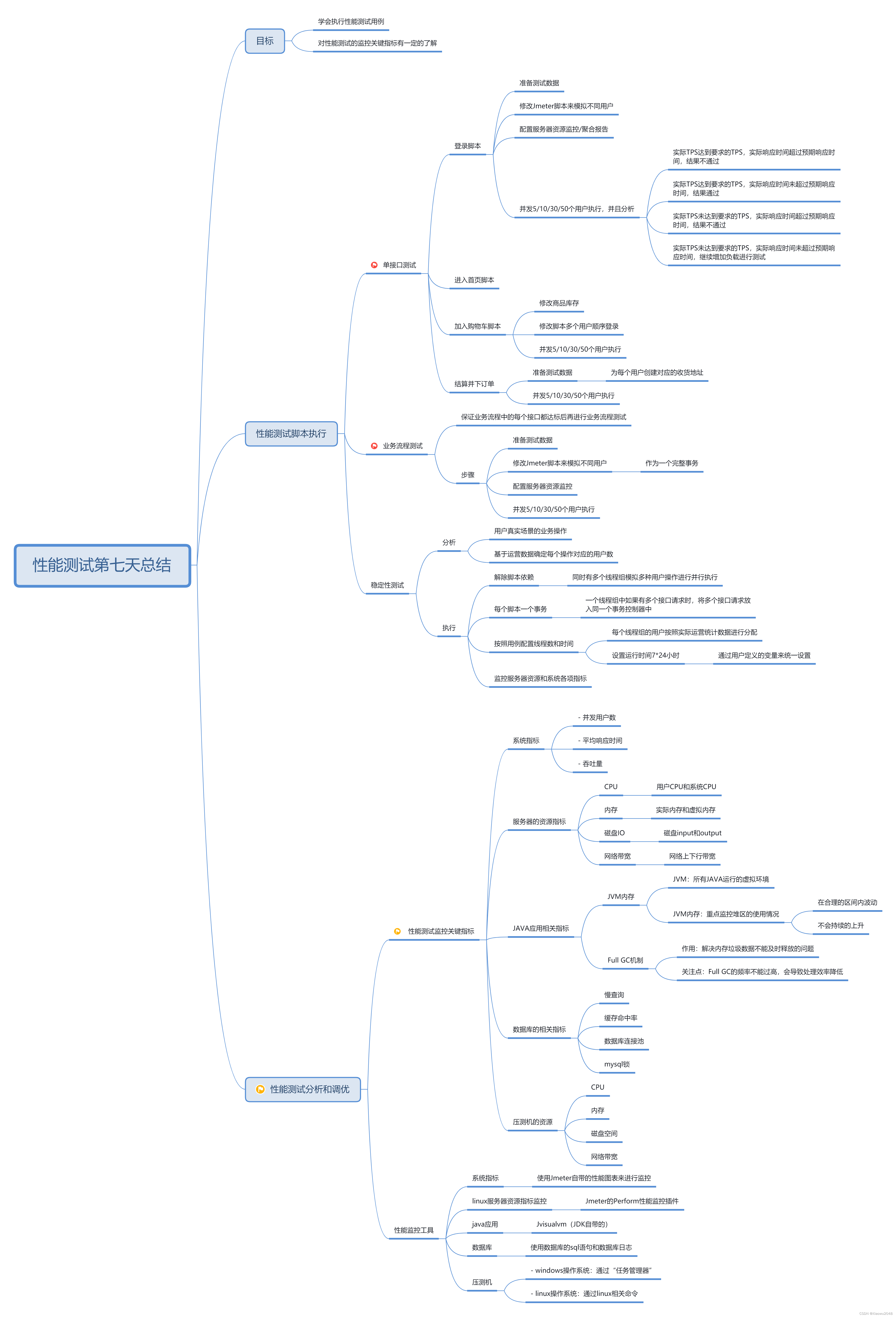
2、数据库连接池
数据库连接池:事先建立好连接,当程序请求sql执行时,直接分配空闲连接,使用完成后释放连接。节
省了SQL语句执行前后连接的建立和关闭的时间。
工作原理:
查看方法:
最大连接数:show variables like “max_connections”
当前使用的连接数:show status like “threads_connected”
测试点关注点:
关注:利用率 = 当前使用的连接数/最大连接数 ,建议:85%左右
如果利用率超过85%,连接池可能会被占满
如果利用率过低,说明资源存在浪费,可能会影响其他性能指标
3、mysql锁
锁的介绍:
一个用户修改数据时,对该数据进行加锁操作,其他用户不能进行修改
只有当第一个用户修改完成后,其他用户才能修改
数据库中锁:
行锁:效率高,但是安全性低(会出现死锁)
表锁:效率低,但是安全性高(不会出现死锁)
死锁:
两个进程同时使用资源时,出现的相互争抢的现象
死锁后需要等待很长的时间,要么有程序校验机制来释放,要么手动释放
数据库中锁的介绍:
行锁:
转账功能: 第一步 第二步
A给B转500元。 ———— A记录余额减少500, B记录余额增加500
B给A转600元。 ———— B记录余额减少600, A记录金额增加600
测试关注点:
show open tables where in_use>=1: 查看当前正在使用的表(可能是锁定的表)
show pricesslist :查看执行时间长的线程,找到对应的sql
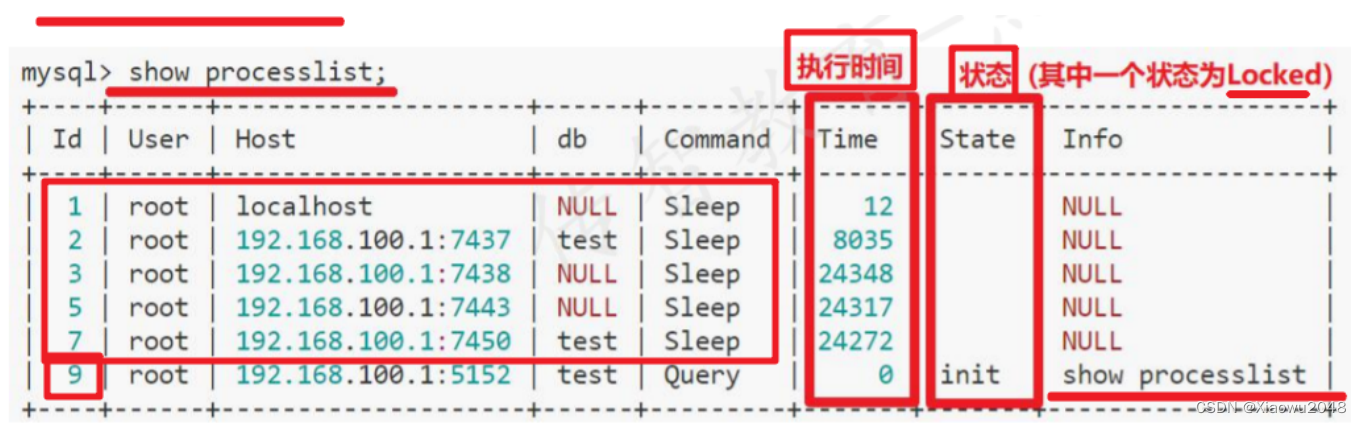
kill pid:如果锁死,先手动杀死死锁的连接,
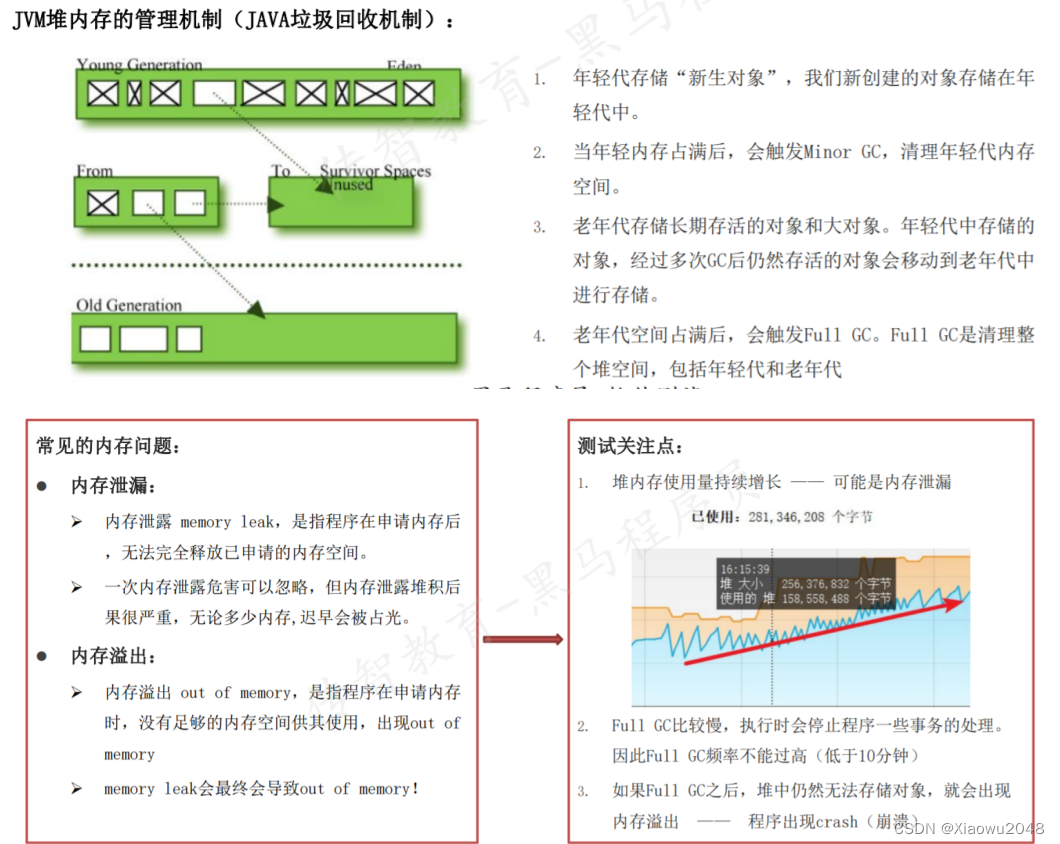
JVM内存
(JAVA Virtual Machine)JAVA虚拟机管理JAVA程序运行时,所管理的内存
堆内存:存储动态数据,创建对象时申请的空间。给程序员使用
非堆内存:存储静态数据。供JVM运行使用
JAVA应用:
JVM监控—Jvisualvm.exe
1、在JAVA程序启动时,添加启动参数
-Dcom.sun.management.jmxremote
-Djava.rmi.server.hostname=182.92.81.159
-Dcom.sun.management.jmxremote.port=10086
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
2、进入JDK的bin目录下,选择“Jvisualvm.exe”
3、点击远程,右键选择“添加远程主机”,并设置服务器IP
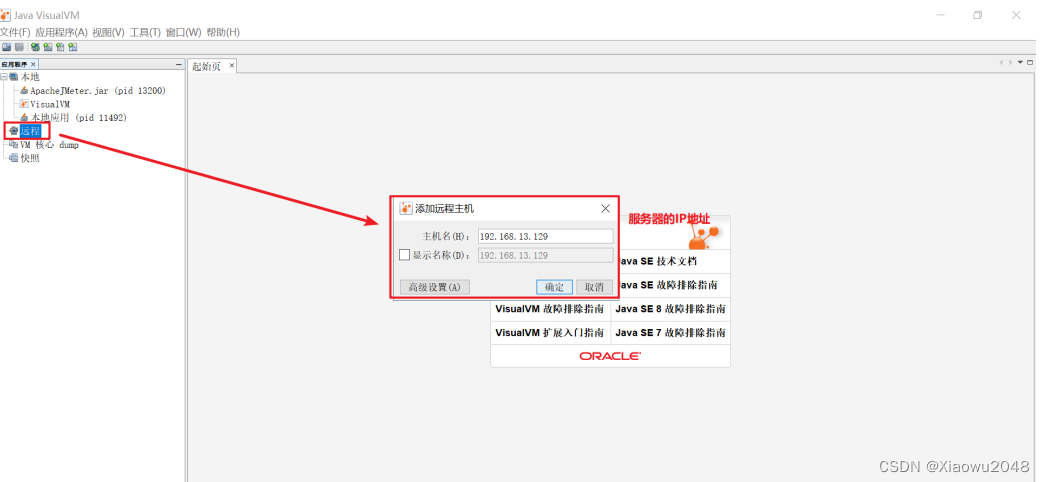
4、点击主机IP,右键点击“添加JMX连接”,并设置JVM监控的端口

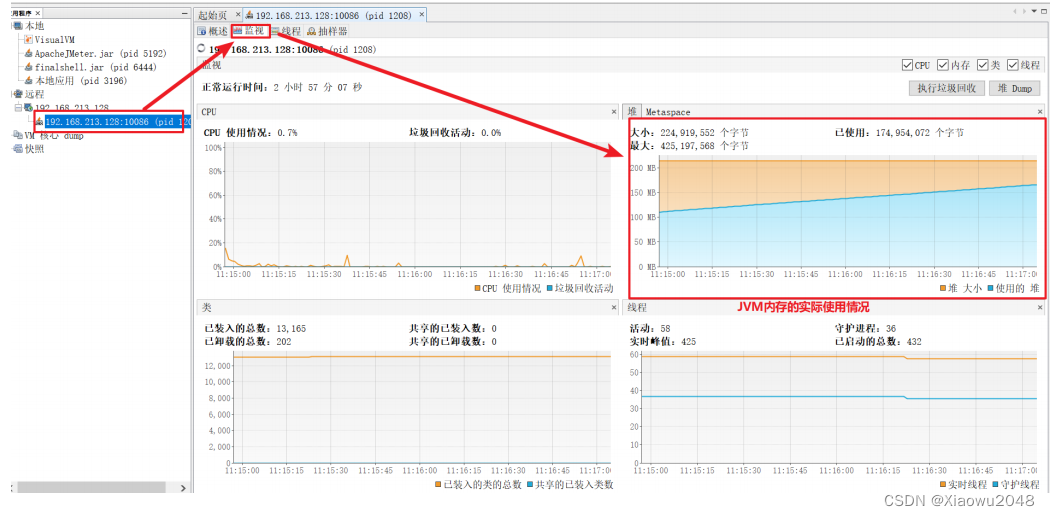
5、点击 IP + port,右边选择“监视”,可以查看JVM内存的实际使用情况
压测机:
原因:JMeter单机负载能力有限,如果需要模拟的用户请求数超过其负载极限,也会导致TPS压不
上去
监控的方法:
windows压测机 —— 任务管理器
linux压测机 —— PerFMon 或者 top命令
解决方法:
添加资源
添加多台压测机,进行分布式测试
性能调优案例:
案例
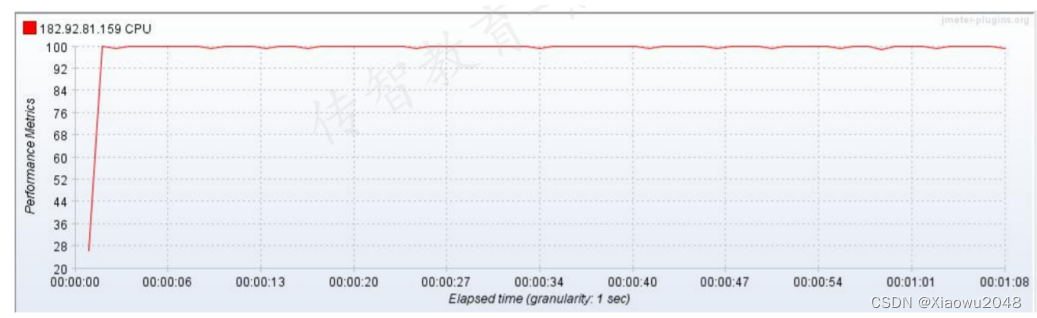
分析过程:
进入首页后,加载首页的相关数据,包括:轮播图、频道、优惠券、团购专区、品牌商直供、新品
首发、热卖商品、专题精选 等数据
没发送一个HTTP请求,需要查询27个SQL语句。当TPS为100时,每秒要处理2700个SQL语句
解决方案:
增加CPU
通过分批次、异步加载的方式,第一次进入首页时只加载第一屏的内容,下拉时再加载后续的数据
案例2(网络):
问题分析:
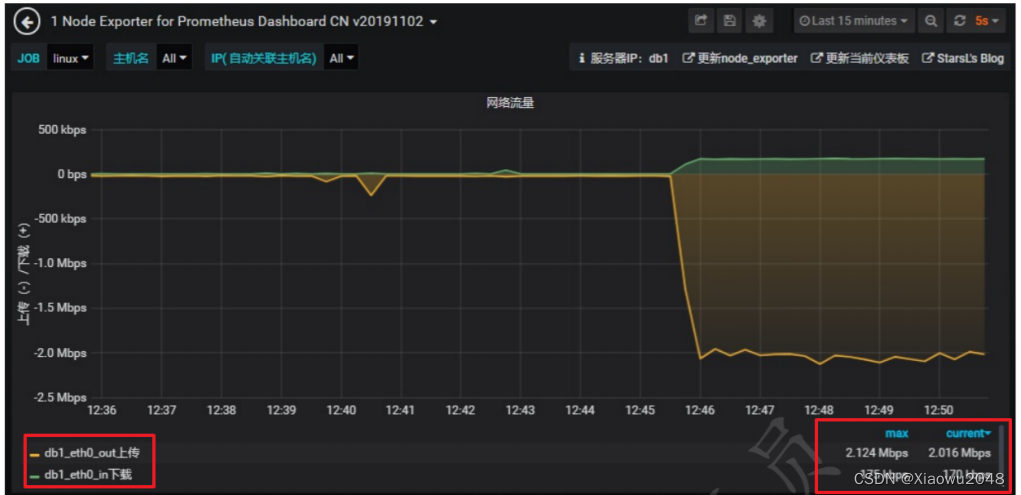
原因:
已使用的网络带宽已经接近于总带宽
解决方案:
增加网络带宽
减少进入商品详情页面时的数据请求量
案例3(慢查询):
案例:
当搜索商品时,慢查询日志中记录了一个查询SQL比较慢,该SQL为获取商品类别信息的SQL
select id,
name, keywords,desc, pid, icon_url, pic_url,level,
sort_order, add_time, update_time, deleted from litemall_
category WHERE ( id in (1008009, 1008009, 1008008, 1008008, 1015000, 1015000,
1008009, 1008009, 1008009, 1008008, 1036000) and
level= ‘L2’ and deleted = 0);
分析步骤:
当搜索关键字匹配到大量的商品时,第3条SQL语句会返回大量重复数据
第4条SQL语句中的in查询条件中同样包含大量重复的商品分类id
因此:第4条SQL会出现查询时间较长,是由于第3条SQL返回的ID有大量重复

案例4(JVM内存泄漏):
问题分析:
测试接口:/wx/index/oom
执行时会出现内存泄漏:
现象
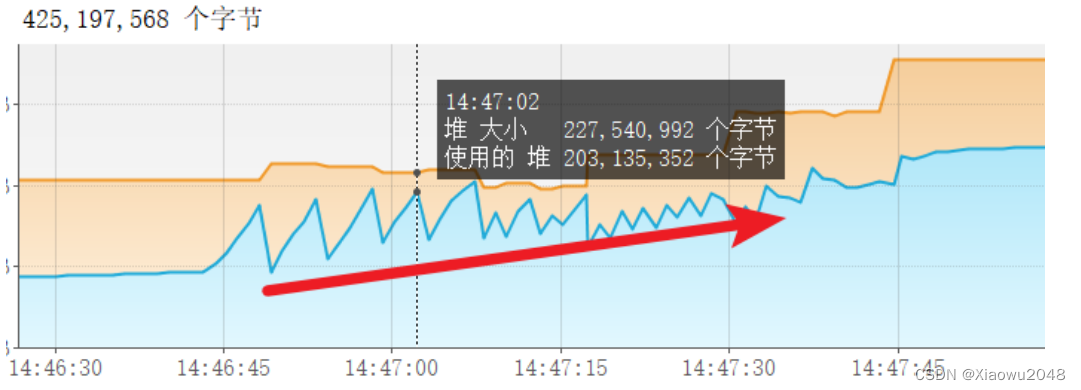
解决方案:
开发定位出泄漏的点,修改代码
性能测试的报告:
过程的回顾
问题的分析
测试结论
经验和教训
locust
简介:
特点:
是一个python的第三方库,专门用来进行性能并发测试
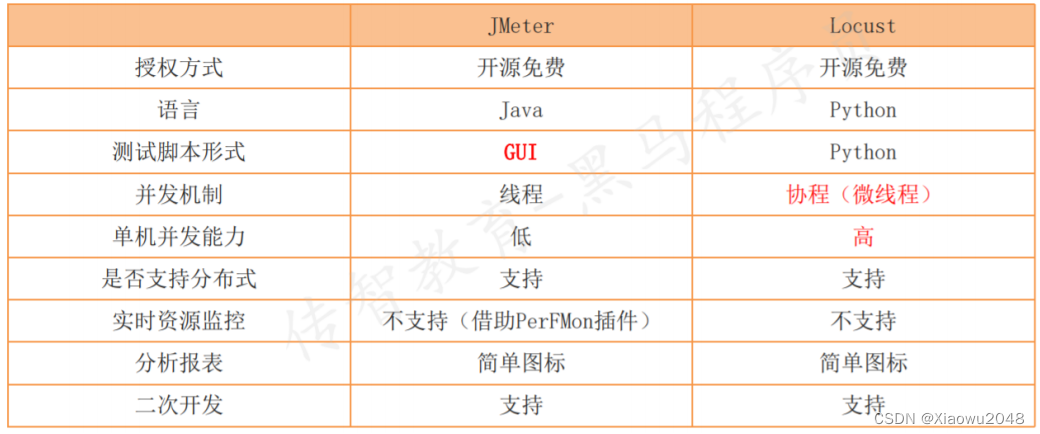
与JMeter对比:
安装:
pip install locustio==0.12.2
编写测试脚本的步骤:

定义任务:
定义接口请求(使用requests库)

# 定义任务
# 登录请求
def login(l):
l.client.post("/bms/login",data={"username":"admin","password":"123456"})
# 首页
def index(l):
l.client.get("/bms/index")
# 获取用户信息
def profile(l):
l.client.get("/bms/profile")
# 退出
def logout(l):
l.client.post("/bms/logout")
定义任务集(用户行为):
模拟用户行为,将多个任务(HTTP请求)按照指定的比例组合在一起进行发送


from locust import TaskSet
#定义任务集
# 定义任务集
class UserBehavior(TaskSet):
tasks = {index:1,profile:3}
def on_start(self):
login(self)
def on_stop(self):
logout(self)
定义locust类:
用户类,通过用户来执行定义好的任务集
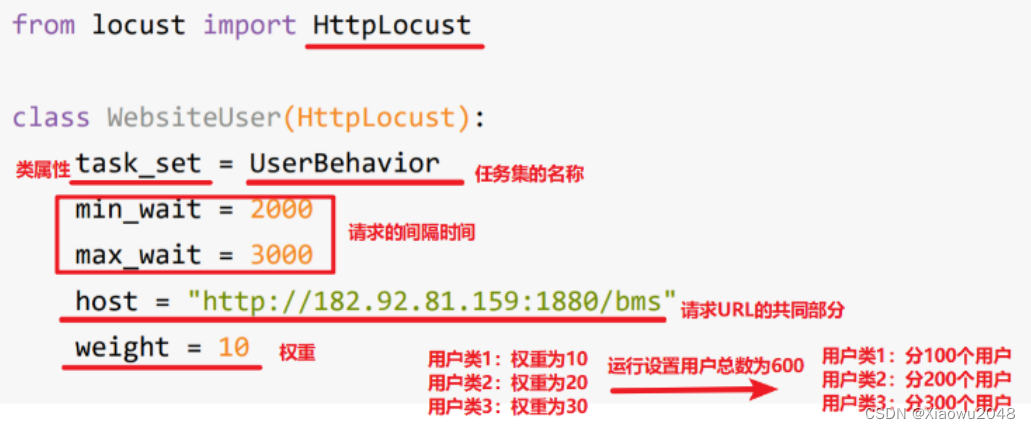
#定义用户类
class UserWebsite(HttpLocust):
task_set = UserBehaiver
min_wait = 1000
max_wait = 1500
host = "http://bms-test.itheima.net/bms"
weight = 10
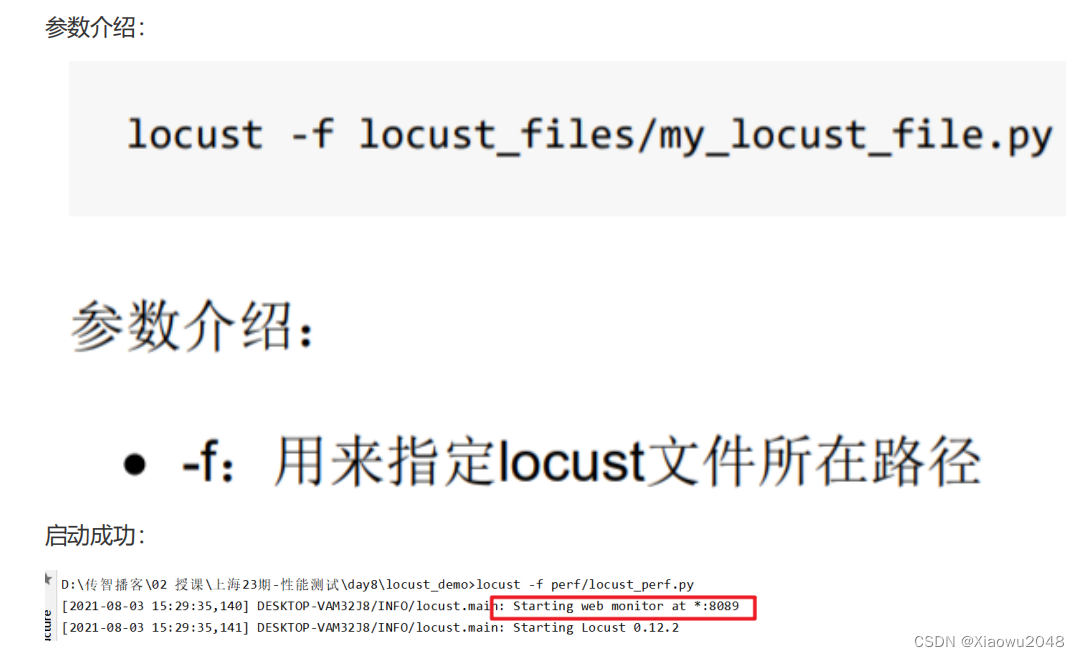
运行Locust:
参数介绍:
性能测试执行的界面:

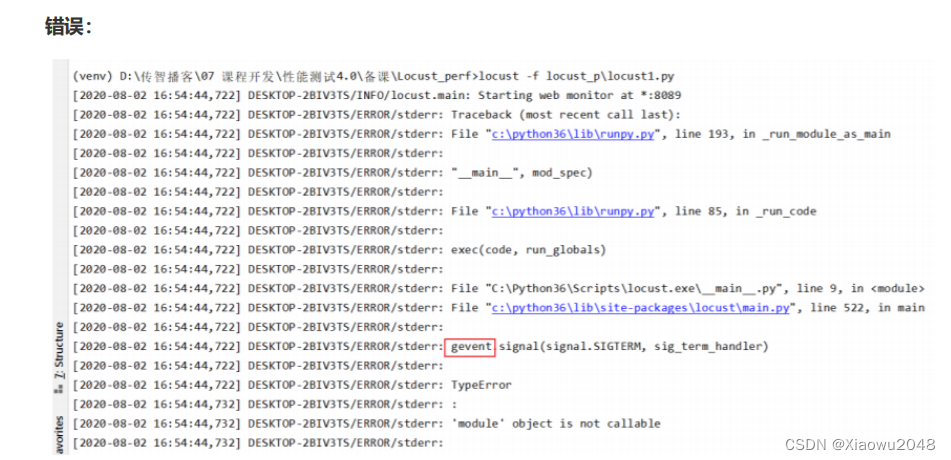
解决错误:
1、重新安装gevent包的版本
pip install gevent==1.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
2、重新执行运行locust脚本
locust -f locust_p\locust1.py
启动成功显示为:

启动压测执行:
Locust执行测试时系统指标的监控
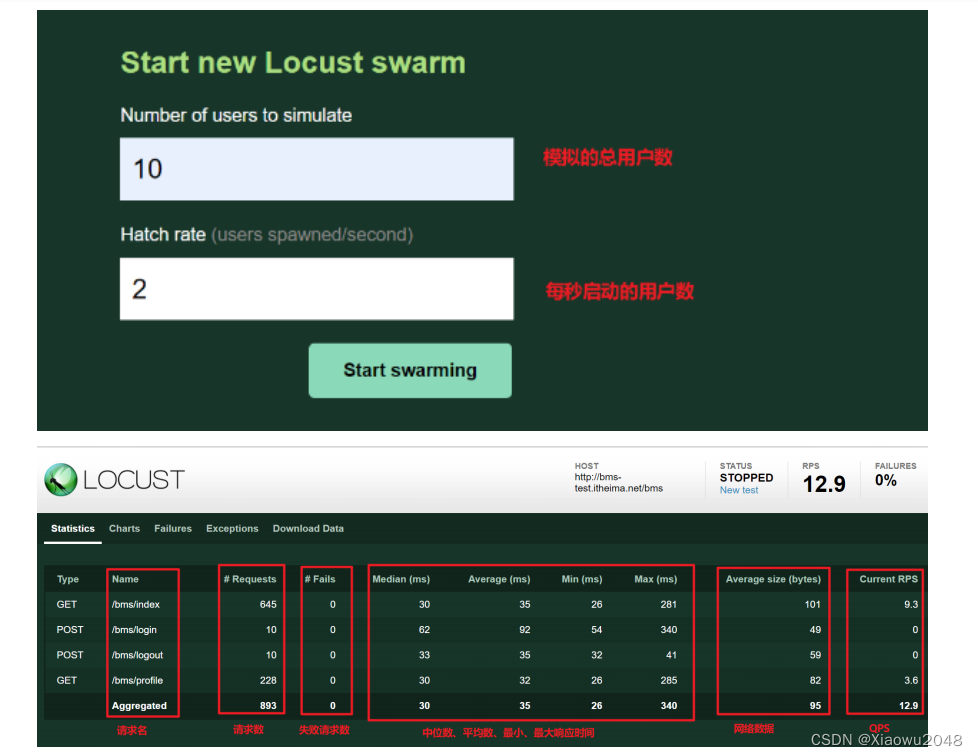
其他的资源监控界面:
charts:记录吞吐量QPS、响应时间、并发数,按照时间的统计情况
Failures:性能测试脚本在执行失败后的记录(断言失败)
Exceptions:脚本出现异常
Download Data:提供下载前面各个部分的性能指标数据















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









